Gambaran umum grup failover & praktik terbaik (Azure SQL Database)
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database
Fitur grup failover memungkinkan Anda mengelola replikasi dan failover beberapa atau semua database di server logis ke server logis di wilayah lain. Artikel ini memberikan gambaran umum tentang fitur grup failover dengan praktik terbaik dan rekomendasi untuk menggunakannya dengan Azure SQL Database.
Untuk mulai menggunakan fitur ini, tinjau Mengonfigurasi grup failover.
Catatan
Artikel ini membahas grup failover untuk Azure SQL Database. Untuk Azure SQL Managed Instance, lihat Grup failover di Azure SQL Managed Instance.
Untuk mempelajari selengkapnya tentang pemulihan bencana Azure SQL Database, tonton video ini:
Gambaran Umum
Fitur grup failover memungkinkan Anda mengelola replikasi dan failover database ke wilayah Azure lain. Anda dapat memilih semua, atau subset, database pengguna di server logis untuk direplikasi ke server logis lain. Ini adalah abstraksi deklaratif di atas fitur replikasi geografis aktif, yang dirancang untuk menyederhanakan penyebaran dan manajemen database yang direplikasi secara geografis dalam skala besar.
Untuk RPO geo-failover dan RTO, lihat gambaran umum kelangsungan bisnis.
Pengalihan titik akhir
Grup failover menyediakan titik akhir pendengar baca-tulis dan baca-saja yang tetap tidak berubah selama geo-failover. Anda tidak perlu mengubah string koneksi untuk aplikasi Anda setelah failover geografis, karena koneksi secara otomatis dirutekan ke primer saat ini. Geo-failover mengalihkan semua database sekunder dalam grup ke peran utama. Setelah geo-failover selesai, catatan DNS secara otomatis diperbarui untuk mengalihkan titik akhir ke wilayah baru.
Membongkar beban kerja baca-saja
Untuk mengurangi lalu lintas ke database utama Anda, Anda juga dapat menggunakan database sekunder dalam grup failover untuk membongkar beban kerja baca-saja. Gunakan pendengar baca-saja untuk mengarahkan lalu lintas baca-saja ke database sekunder yang dapat dibaca.
Memulihkan aplikasi
Untuk mencapai kelangsungan bisnis penuh, menambahkan redundansi basis data regional hanyalah bagian dari solusi. Memulihkan aplikasi (layanan) secara ujung-ke-ujung setelah kegagalan besar membutuhkan pemulihan semua komponen yang membentuk layanan dan layanan yang bergantung. Contoh komponen ini termasuk perangkat lunak klien (misalnya, browser dengan JavaScript khusus), front end web, penyimpanan, dan DNS. Sangat penting bahwa semua komponen tahan terhadap kegagalan yang sama dan tersedia dalam tujuan waktu pemulihan (RTO) aplikasi Anda. Oleh karena itu, Anda perlu mengidentifikasi semua layanan yang bergantung dan memahami jaminan dan kemampuan yang diberikan layanan tersebut. Kemudian, Anda harus mengambil langkah-langkah yang memadai untuk memastikan bahwa layanan Anda berfungsi selama failover layanan yang bergantung padanya.
Kebijakan failover
Grup failover mendukung dua kebijakan failover:
- Dikelola pelanggan (disarankan) - Pelanggan dapat melakukan failover suatu grup ketika mereka melihat ada pemadaman tak terduga yang berdampak pada satu atau beberapa database dalam grup failover. Saat menggunakan alat baris perintah seperti PowerShell, Azure CLI, atau Rest API, nilai kebijakan failover untuk dikelola pelanggan adalah
manual. - Dikelola Microsoft - Jika terjadi pemadaman yang meluas yang berdampak pada wilayah utama, Microsoft memulai failover semua grup failover yang terkena dampak yang kebijakan failover-nya dikonfigurasi agar dikelola Microsoft. Failover yang dikelola Microsoft tidak akan dimulai untuk grup failover individual atau subset grup failover di suatu wilayah. Saat menggunakan alat baris perintah seperti PowerShell, Azure CLI, atau Rest API, nilai kebijakan failover untuk dikelola Microsoft adalah
automatic.
Setiap kebijakan failover memiliki serangkaian kasus penggunaan yang unik dan ekspektasi yang sesuai pada cakupan failover dan kehilangan data, seperti yang dirangkum tabel berikut:
| Kebijakan failover | Cakupan failover | Gunakan huruf besar | Potensi kehilangan data |
|---|---|---|---|
| Dikelola pelanggan (Disarankan) |
Grup failover | Satu atau beberapa database dalam grup failover terpengaruh oleh pemadaman dan menjadi tidak tersedia. Anda dapat memilih untuk melakukan failover. | Ya |
| Dikelola Microsoft | Semua grup failover di wilayah | Pemadaman luas di pusat data, zona ketersediaan, atau wilayah menyebabkan tidak tersedianya database dan tim layanan Microsoft Azure SQL memutuskan untuk memicu failover paksa. Gunakan opsi ini hanya ketika Anda ingin mendelegasikan tanggung jawab pemulihan bencana kepada Microsoft dan aplikasi ini toleran terhadap RTO (waktu henti) setidaknya satu jam atau lebih. |
Ya |
Dikelola pelanggan
Pada kesempatan yang jarang terjadi, ketersediaan bawaan atau ketersediaan tinggi tidak cukup untuk mengurangi pemadaman, dan database Anda dalam grup failover mungkin tidak tersedia selama durasi yang tidak dapat diterima oleh perjanjian tingkat layanan (SLA) aplikasi menggunakan database. Database dapat tidak tersedia karena masalah yang dilokalkan hanya berdampak pada beberapa database, atau bisa berada di pusat data, zona ketersediaan, atau tingkat wilayah. Dalam salah satu kasus ini, untuk memulihkan kelangsungan bisnis, Anda dapat memulai failover paksa.
Mengatur kebijakan failover Anda ke yang dikelola pelanggan sangat disarankan, karena membuat Anda terkendali kapan harus memulai failover dan memulihkan kelangsungan bisnis. Anda dapat memulai failover saat melihat pemadaman tak terduga yang berdampak pada satu atau beberapa database dalam grup failover.
Dikelola Microsoft
Dengan kebijakan failover terkelola Microsoft, tanggung jawab pemulihan bencana didelegasikan ke layanan Azure SQL. Agar layanan Azure SQL memulai failover paksa, kondisi berikut harus dipenuhi:
- Pusat data, zona ketersediaan, atau pemadaman tingkat wilayah yang disebabkan oleh peristiwa bencana alam, perubahan konfigurasi, bug perangkat lunak atau kegagalan komponen perangkat keras dan banyak database di wilayah tersebut terpengaruh.
- Masa tenggang kedaluwarsa. Karena memverifikasi skala, dan mengurangi, pemadaman tergantung pada tindakan manusia, masa tenggang tidak dapat diatur di bawah satu jam.
Ketika kondisi ini terpenuhi, layanan Azure SQL memulai failover paksa untuk semua grup failover di wilayah yang memiliki kebijakan failover yang diatur ke dikelola Microsoft.
Atur kebijakan failover ke Microsoft yang dikelola hanya saat:
- Anda ingin mendelegasikan tanggung jawab pemulihan bencana ke layanan Azure SQL.
- Aplikasi ini toleran terhadap database Anda yang tidak tersedia setidaknya selama satu jam atau lebih.
- Dapat diterima untuk memicu failover paksa beberapa waktu setelah masa tenggang berakhir karena waktu aktual untuk failover paksa dapat bervariasi secara signifikan.
- Dapat diterima bahwa semua database dalam grup failover gagal, terlepas dari konfigurasi redundansi zona atau status ketersediaannya. Meskipun database yang dikonfigurasi untuk redundansi zona tahan terhadap kegagalan zonal dan mungkin tidak terpengaruh oleh pemadaman, database tersebut masih akan gagal jika merupakan bagian dari grup failover dengan kebijakan failover terkelola Microsoft.
- Dapat diterima untuk memaksa failover database dalam grup failover tanpa mempertimbangkan dependensi aplikasi pada layanan atau komponen Azure lainnya yang digunakan oleh aplikasi, yang dapat menyebabkan penurunan performa atau tidak tersedianya aplikasi.
- Dapat diterima untuk menimbulkan jumlah kehilangan data yang tidak diketahui, karena waktu yang tepat dari failover paksa tidak dapat dikontrol, dan mengabaikan status sinkronisasi database sekunder.
- Semua database utama dan sekunder dalam grup failover dan hubungan replisiasi geografis apa pun memiliki tingkat layanan, tingkat komputasi yang sama (disediakan atau tanpa server) & ukuran komputasi (DTU atau vCore). Jika tujuan tingkat layanan (SLO) dari semua database tidak cocok, maka kebijakan failover pada akhirnya akan diperbarui dari layanan Microsoft Managed to Customer Managed by Azure SQL.
Saat failover dipicu oleh Microsoft, entri untuk nama operasi Failover Grup failover Azure SQL ditambahkan ke log aktivitas Azure Monitor. Entri menyertakan nama grup failover di bawah Sumber Daya, dan Peristiwa yang dimulai dengan menampilkan satu tanda hubung (-) untuk menunjukkan failover dimulai oleh Microsoft. Informasi ini juga dapat ditemukan di halaman Log aktivitas server utama atau instans baru di portal Azure.
Terminologi dan kemampuan
Grup failover (FOG)
Grup failover adalah grup database bernama yang dikelola oleh satu server logis di Azure yang dapat gagal sebagai unit ke wilayah Azure lain jika semua atau beberapa database utama menjadi tidak tersedia karena pemadaman di wilayah utama.
Penting
Nama grup failover harus unik secara global dalam domain
.database.windows.net.Server
Beberapa atau semua database pengguna pada server logis dapat ditempatkan di grup failover. Selain itu, server mendukung beberapa grup failover pada satu server.
Primer
Server logis yang menghosting database utama dalam grup failover.
Sekunder
Server logis yang menghosting database sekunder dalam grup failover. Sekunder tidak boleh berada di wilayah Azure yang sama dengan yang utama.
Failover (tidak ada kehilangan data)
Failover melakukan sinkronisasi data penuh antara database primer dan sekunder sebelum sekunder beralih ke peran utama. Hal ini menjamin tidak ada data yang hilang. Failover hanya dimungkinkan ketika primer dapat diakses. Failover digunakan dalam skenario berikut:
- Melakukan latihan pemulihan bencana (DR) dalam produksi saat kehilangan data tidak dapat diterima
- Merelokasi beban kerja ke wilayah lain
- Mengembalikan beban kerja ke wilayah utama setelah pemadaman dimitigasi (failback)
Failover paksa (potensi kehilangan data)
Failover paksa segera mengalihkan sekunder ke peran utama tanpa menunggu perubahan terbaru untuk disebarluaskan dari primer. Operasi ini dapat mengakibatkan potensi kehilangan data. Failover paksa digunakan sebagai metode pemulihan selama pemadaman saat primer tidak dapat diakses. Ketika pemadaman dikurangi, primer lama akan secara otomatis terhubung kembali dan menjadi sekunder baru. Failover dapat dieksekusi untuk melakukan failback, mengembalikan replika ke peran utama dan sekunder aslinya.
Masa tenggang dengan kehilangan data
Karena data direplikasi ke sekunder menggunakan replikasi asinkron, failover paksa grup dengan kebijakan failover terkelola Microsoft dapat mengakibatkan kehilangan data. Anda dapat menyesuaikan kebijakan failover untuk mencerminkan toleransi aplikasi Anda terhadap kehilangan data. Dengan mengonfigurasi
GracePeriodWithDataLossHours, Anda dapat mengontrol berapa lama layanan Azure SQL menunggu sebelum memulai failover paksa, yang dapat mengakibatkan kehilangan data.
Menambahkan database tunggal ke grup failover
Anda dapat menempatkan beberapa database tunggal di server logis yang sama ke dalam grup failover yang sama. Jika Anda menambahkan database tunggal ke grup failover, database sekunder secara otomatis membuat database sekunder menggunakan edisi dan ukuran komputasi yang sama di server sekunder yang Anda tentukan saat grup failover dibuat. Jika Anda menambahkan database yang sudah memiliki database sekunder di server sekunder, tautan geo-replikasi tersebut diwarisi oleh grup. Saat Anda menambahkan database yang sudah memiliki database sekunder di server yang bukan bagian dari grup failover, database sekunder baru dibuat di server sekunder.
Penting
- Pastikan server logis sekunder tidak memiliki database dengan nama yang sama kecuali itu adalah database sekunder yang sudah ada.
- Jika database berisi objek OLTP dalam memori, database utama dan database geo-replika sekunder harus memiliki tingkat layanan yang cocok, karena objek OLTP dalam memori berada di memori. Tingkat layanan yang lebih rendah pada database geo-replika dapat mengakibatkan masalah di luar memori. Jika ini terjadi, replika geografis mungkin gagal memulihkan database, menyebabkan tidak tersedianya database sekunder bersama dengan objek OLTP dalam memori pada geo-sekunder. Ini, pada gilirannya, dapat menyebabkan failover juga tidak berhasil. Untuk menghindari hal ini, pastikan bahwa tingkat layanan database geo-sekunder cocok dengan database utama. Peningkatan tingkat layanan dapat berupa operasi ukuran data dan mungkin perlu waktu cukup lama untuk diselesaikan.
Menambahkan database dalam kumpulan elastis ke grup failover
Anda dapat memasukkan semua atau beberapa database dalam kumpulan elastis ke dalam grup failover yang sama. Jika database utama berada dalam kumpulan elastis, database sekunder secara otomatis dibuat di kumpulan elastis dengan nama yang sama (kumpulan sekunder). Anda harus memastikan bahwa server sekunder berisi kumpulan elastis dengan nama yang sama persis dan memiliki kapasitas bebas yang cukup untuk menghosting database sekunder yang akan dibuat oleh grup failover. Jika Anda menambahkan database di kumpulan yang sudah memiliki database sekunder di kumpulan sekunder, tautan geo-replikasi tersebut diwarisi oleh grup. Saat Anda menambahkan database yang sudah memiliki database sekunder di server yang bukan bagian dari grup failover, database sekunder baru dibuat di kumpulan sekunder.
Pendengar baca-tulis grup failover
Data CNAME DNS yang menunjuk ke URL utama saat ini. Ini dibuat secara otomatis ketika grup failover dibuat dan memungkinkan beban kerja baca-tulis untuk terhubung kembali secara transparan ke primer ketika primer berubah setelah failover. Ketika grup failover dibuat di server, data CNAME DNS untuk URL pendengar dibentuk sebagai
<fog-name>.database.windows.net. Setelah failover, catatan DNS secara otomatis diperbarui untuk mengalihkan pendengar ke primer baru.Pendengar baca-saja grup failover
Data CNAME DNS yang menunjuk ke URL utama saat ini. Ini dibuat secara otomatis ketika grup failover dibuat dan memungkinkan beban kerja SQL baca-saja untuk terhubung secara transparan ke sekunder ketika sekunder berubah setelah failover. Ketika grup failover dibuat di server, data CNAME DNS untuk URL pendengar dibentuk sebagai
<fog-name>.secondary.database.windows.net. Secara default, failover pendengar baca-saja dinonaktifkan karena memastikan performa primer tidak terpengaruh saat sekunder offline. Namun, itu juga berarti sesi baca-saja tidak akan dapat terhubung sampai sekunder dipulihkan. Jika Anda tidak dapat mentolerir waktu henti untuk sesi baca-saja dan dapat menggunakan yang utama untuk lalu lintas baca-saja dan baca-tulis dengan mengorbankan potensi penurunan performa primer, Anda dapat mengaktifkan failover untuk pendengar baca-saja dengan mengonfigurasiAllowReadOnlyFailoverToPrimaryproperti. Dalam hal ini, lalu lintas baca-saja secara otomatis dialihkan ke primer jika sekunder tidak tersedia.Catatan
Properti
AllowReadOnlyFailoverToPrimaryhanya berpengaruh jika kebijakan failover terkelola Microsoft diaktifkan dan failover paksa telah dipicu. Dalam hal ini, jika properti diatur ke Benar, primer baru akan melayani sesi baca-tulis dan baca-saja.Beberapa grup failover
Anda dapat mengonfigurasi beberapa grup failover untuk pasangan server yang sama guna mengontrol cakupan failover. Setiap kelompok melakukan failover secara independen. Jika aplikasi penyewa per database Anda digunakan di beberapa wilayah dan menggunakan kumpulan elastis, Anda dapat menggunakan kemampuan ini untuk mencampur database primer dan sekunder di setiap kumpulan. Dengan cara ini Anda mungkin dapat mengurangi dampak pemadaman hanya untuk beberapa database penyewa.
Arsitektur grup failover
Grup failover di Azure SQL Database dapat mencakup satu atau beberapa database, biasanya digunakan oleh aplikasi yang sama. Grup failover harus dikonfigurasi di server utama, yang menghubungkannya ke server sekunder di wilayah Azure yang berbeda. Grup failover dapat menyertakan semua atau beberapa database di server utama. Diagram berikut mengilustrasikan konfigurasi umum aplikasi cloud geo-redundan menggunakan beberapa database dalam grup failover:
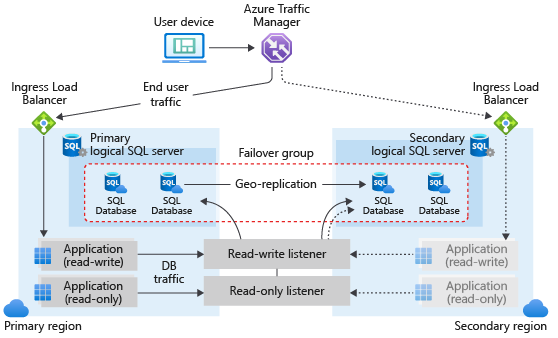
Saat mendesain layanan dengan mempertimbangkan kelangsungan bisnis, ikuti panduan umum dan praktik terbaik yang diuraikan dalam artikel ini. Saat mengonfigurasi grup failover, pastikan bahwa autentikasi dan akses jaringan pada sekunder diatur agar berfungsi dengan benar setelah geo-failover, ketika geo-sekunder menjadi primer baru. Untuk mengetahui detailnya, lihat Keamanan SQL Database setelah pemulihan bencana. Untuk informasi selengkapnya, lihat Merancang solusi cloud untuk pemulihan bencana.
Gunakan wilayah berpasangan
Saat membuat grup failover Antara server utama dan sekunder, gunakan wilayah berpasangan karena grup failover di wilayah berpasangan memiliki performa yang lebih baik dibandingkan dengan wilayah yang tidak berpasangan.
Mengikuti praktik penyebaran yang aman, Azure SQL Database umumnya tidak memperbarui wilayah yang dipasangkan secara bersamaan. Namun, tidak dimungkinkan untuk memprediksi wilayah mana yang akan ditingkatkan terlebih dahulu, sehingga urutan penyebaran tidak dijamin. Terkadang, server utama Anda ditingkatkan terlebih dahulu, dan terkadang ditingkatkan kedua.
Jika Anda memiliki grup replikasi geografis atau failover yang dikonfigurasi untuk database yang tidak selaras dengan pemasangan wilayah Azure, gunakan jadwal jendela pemeliharaan yang berbeda untuk database utama dan sekunder Anda. Misalnya, Anda dapat memilih Jendela pemeliharaan hari kerja untuk database sekunder dan jendela pemeliharaan Akhir Pekan untuk database utama Anda.
Seeding awal
Saat menambahkan database atau kumpulan elastis ke grup failover, ada fase seeding awal sebelum replikasi data dimulai. Fase seeding awal adalah operasi terpanjang dan termahal. Setelah seeding awal selesai, data disinkronkan, dan hanya perubahan data berikutnya yang akan direplikasi. Waktu yang diperlukan agar penyemaian awal selesai tergantung pada ukuran data Anda, jumlah database yang direplikasi, beban pada database utama, dan kecepatan tautan jaringan antara database utama dan sekunder. Dalam keadaan normal, kemungkinan kecepatan seeding mencapai 500 GB per jam untuk SQL Database. Seeding dilakukan untuk semua database secara paralel.
Menggunakan beberapa grup failover untuk melakukan failover pada beberapa database
Satu atau banyak grup failover dapat dibuat antara dua server di wilayah berbeda (server utama dan sekunder). Setiap grup dapat menyertakan satu atau beberapa database yang dipulihkan sebagai pelajaran jika semua atau beberapa database utama menjadi tidak tersedia karena pemadaman di wilayah utama. Grup failover membuat database geo-sekunder dengan tujuan layanan yang sama dengan yang primer. Jika Anda menambahkan hubungan geo-replikasi yang ada ke grup failover, pastikan geo-sekunder dikonfigurasi dengan tingkat layanan dan ukuran komputasi yang sama dengan primer.
Gunakan pendengar baca-tulis (utama)
Untuk beban kerja baca-tulis, gunakan <fog-name>.database.windows.net sebagai nama server dalam string koneksi. Koneksi secara otomatis diarahkan ke primer. Nama ini tidak berubah setelah failover. Perhatikan bahwa failover melibatkan pembaruan catatan DNS sehingga koneksi klien dialihkan ke primer baru hanya setelah tembolok DNS klien direfresh. Waktu untuk hidup (TTL) dari catatan DNS pendengar primer dan sekunder adalah 30 detik.
Gunakan pendengar baca-saja (sekunder)
Jika Anda memiliki beban kerja baca-saja yang terisolasi secara logis yang toleran terhadap latensi data, Anda dapat menjalankannya di geo-sekunder. Untuk beban kerja baca-tulis, gunakan <fog-name>.secondary.database.windows.net sebagai nama server dalam string koneksi. Koneksi secara otomatis diarahkan ke geo-sekunder. Disarankan juga agar Anda menunjukkan niat baca di string koneksi dengan menggunakan ApplicationIntent=ReadOnly.
Di tingkat layanan Premium, Business Critical, dan Hyperscale, SQL Database mendukung penggunaan replika baca-saja untuk membongkar beban kerja kueri baca-saja, menggunakan ApplicationIntent=ReadOnly parameter dalam string koneksi. Ketika Anda telah mengonfigurasi geo-sekunder, Anda dapat menggunakan kemampuan ini untuk menyambungkan ke replika baca-saja di lokasi utama atau di lokasi geo-sekunder:
Untuk terhubung ke replika baca-saja di lokasi sekunder, gunakan ApplicationIntent=ReadOnly dan <fog-name>.secondary.database.windows.net.
Potensi penurunan kinerja setelah failover
Aplikasi Azure yang khas menggunakan beberapa layanan Azure dan terdiri dari beberapa komponen. Failover grup dipicu berdasarkan status Azure SQL Database saja. Layanan Azure lainnya di wilayah utama mungkin tidak terpengaruh oleh pemadaman dan komponennya mungkin masih tersedia di wilayah tersebut. Setelah database utama beralih ke wilayah sekunder (DR), latensi antar komponen dependen dapat meningkat. Untuk menghindari dampak latensi yang lebih tinggi pada kinerja aplikasi, pastikan redundansi semua komponen aplikasi di wilayah DR, ikuti pedoman keamanan jaringanini, dan atur geo-failover komponen aplikasi yang relevan bersama dengan database.
Potensi kehilangan data setelah failover paksa
Jika pemadaman terjadi di wilayah utama, transaksi terbaru mungkin belum direplikasi ke geo-sekunder dan mungkin ada kehilangan data jika failover paksa dilakukan.
Penting
Kumpulan elastis dengan 800 atau lebih sedikit DTU atau 8 atau lebih sedikit vCore, dan lebih dari 250 database dapat mengalami masalah termasuk geo-failover yang direncanakan lebih lama dan performa yang terdegradasi. Masalah ini lebih mungkin terjadi untuk menulis beban kerja intensif ketika replika geografi dipisahkan secara luas oleh geografi, atau ketika beberapa replika geografi sekunder digunakan untuk setiap database. Gejala dari masalah ini adalah peningkatan lag geo-replikasi dari waktu ke waktu, berpotensi menyebabkan kehilangan data yang lebih luas dalam pemadaman. Jeda ini dapat dipantau menggunakan sys.dm_geo_replication_link_status. Jika masalah ini terjadi, maka mitigasi termasuk meningkatkan kumpulan untuk memiliki lebih banyak DCU atau vCores, atau mengurangi jumlah database geo-replikasi di kumpulan.
Gagal kembali
Ketika grup failover dikonfigurasi dengan kebijakan failover yang dikelola Microsoft, maka failover paksa ke server geo-sekunder dimulai selama skenario bencana sesuai masa tenggang yang ditentukan. Failback ke primer lama harus dimulai secara manual.
Izin dan batasan
Tinjau panduan grup failover konfigurasi untuk daftar izin dan batasan.
Mengelola grup failover secara terprogram
Grup failover juga dapat dikelola secara terprogram menggunakan Azure PowerShell, Azure CLI, dan REST API. Untuk informasi selengkapnya, tinjau Mengonfigurasi grup failover.
Konten terkait
- Untuk contoh skrip, lihat:
- Untuk gambaran umum dan skenario kelangsungan bisnis, lihat Gambaran umum kelangsungan bisnis
- Untuk mempelajari pencadangan otomatis Azure SQL Database, lihat Pencadangan otomatis Azure SQL Database.
- Untuk mempelajari cara menggunakan pencadangan otomatis untuk pemulihan, lihat Memulihkan database dari cadangan yang dimulai layanan.
- Untuk mempelajari tentang persyaratan autentikasi untuk server dan database utama baru, lihat Keamanan SQL Database setelah pemulihan bencana.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk