Merancang layanan yang tersedia secara global menggunakan Azure SQL Database
Berlaku untuk: ![]() Azure SQL Database
Azure SQL Database
Saat membangun dan menyebarkan layanan cloud dengan Azure SQL Database, Anda menggunakan replikasi geografis aktif atau grup failover untuk memberikan ketahanan terhadap pemadaman regional dan kegagalan bencana. Fitur yang sama memungkinkan Anda membuat aplikasi terdistribusi secara global yang dioptimalkan untuk akses lokal ke data. Artikel ini membahas pola aplikasi umum, termasuk manfaat dan trade-off dari setiap opsi.
Catatan
Jika Anda menggunakan database Premium atau Business Critical dan kumpulan elastis, Anda dapat membuatnya tahan terhadap penonaktifan regional dengan mengonversinya ke konfigurasi penyebaran berlebihan zona. Lihat Database yang berlebihan terhadap zona.
Skenario 1: Menggunakan dua wilayah Azure untuk kelangsungan bisnis dengan downtime minimal
Dalam skenario ini, aplikasi memiliki karakteristik berikut:
- Aplikasi aktif dalam satu wilayah Azure
- Semua sesi database memerlukan akses baca dan tulis (RW) ke data
- Tingkat web dan tingkat data harus dikolokasi untuk mengurangi latensi dan biaya lalu lintas
- Pada dasarnya, downtime adalah risiko bisnis yang lebih tinggi untuk aplikasi ini daripada kehilangan data
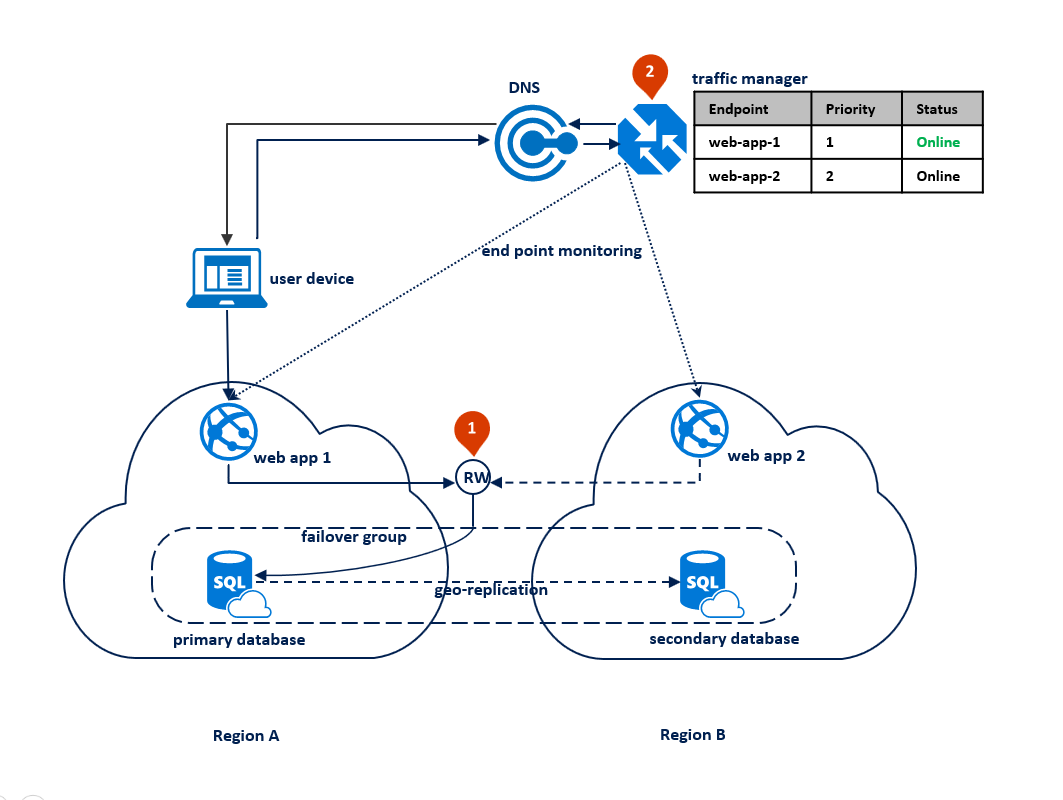
Dalam hal ini, topologi penyebaran aplikasi dioptimalkan untuk menangani bencana regional ketika semua komponen aplikasi perlu gagal bersama-sama. Diagram di bawah ini menunjukkan topologi ini. Untuk redundansi geografis, sumber daya aplikasi disebarkan ke Wilayah A dan B. Namun, sumber daya di Wilayah B tidak digunakan sampai Wilayah A gagal. Grup kegagalan dikonfigurasi antara kedua wilayah untuk mengelola konektivitas, replikasi, dan kegagalan database. Layanan web di kedua wilayah dikonfigurasi untuk mengakses database melalui read-write listener <failover-group-name >.database.windows.net (1). Azure Traffic Manager disiapkan untuk menggunakan metode perutean prioritas (2).
Catatan
Azure Traffic Manager digunakan di seluruh artikel ini hanya untuk tujuan ilustrasi. Anda dapat menggunakan solusi penyeimbang beban apa pun yang mendukung metode perutean prioritas.
Diagram berikut menunjukkan konfigurasi ini sebelum pemadaman:
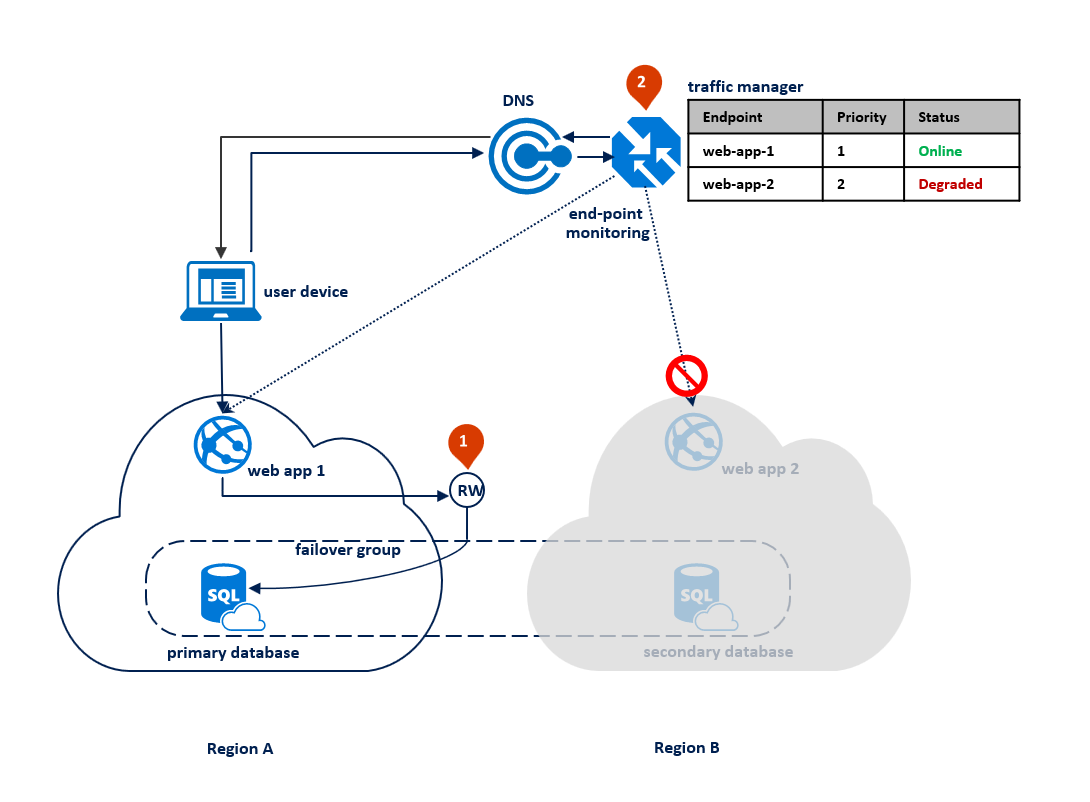
Setelah pemadaman di wilayah utama, SQL Database mendeteksi bahwa database utama tidak dapat diakses dan memicu kegagalan ke wilayah sekunder berdasarkan parameter kebijakan kegagalan otomatis (1). Tergantung pada SLA aplikasi Anda, Anda dapat mengonfigurasi masa tenggang yang mengontrol waktu antara deteksi pemadaman dan kegagalan itu sendiri. Ada kemungkinan bahwa Azure Traffic Manager memulai kegagalan titik akhir sebelum grup kegagalan memicu kegagalan database. Dalam hal ini aplikasi web tidak dapat segera terhubung kembali ke database. Tetapi rekoneksi akan secara otomatis berhasil segera setelah kegagalan database selesai. Ketika wilayah yang gagal dipulihkan dan kembali online, primer lama secara otomatis terhubung kembali sebagai sekunder baru. Diagram di bawah ini mengilustrasikan konfigurasi setelah kegagalan.
Catatan
Semua transaksi yang dilakukan setelah kegagalan hilang selama rekoneksi. Setelah kegagalan selesai, aplikasi di wilayah B dapat menyambung kembali dan memulai ulang pemrosesan permintaan pengguna. Baik aplikasi web maupun database utama kini berada di wilayah B dan tetap berada di lokasi yang sama.
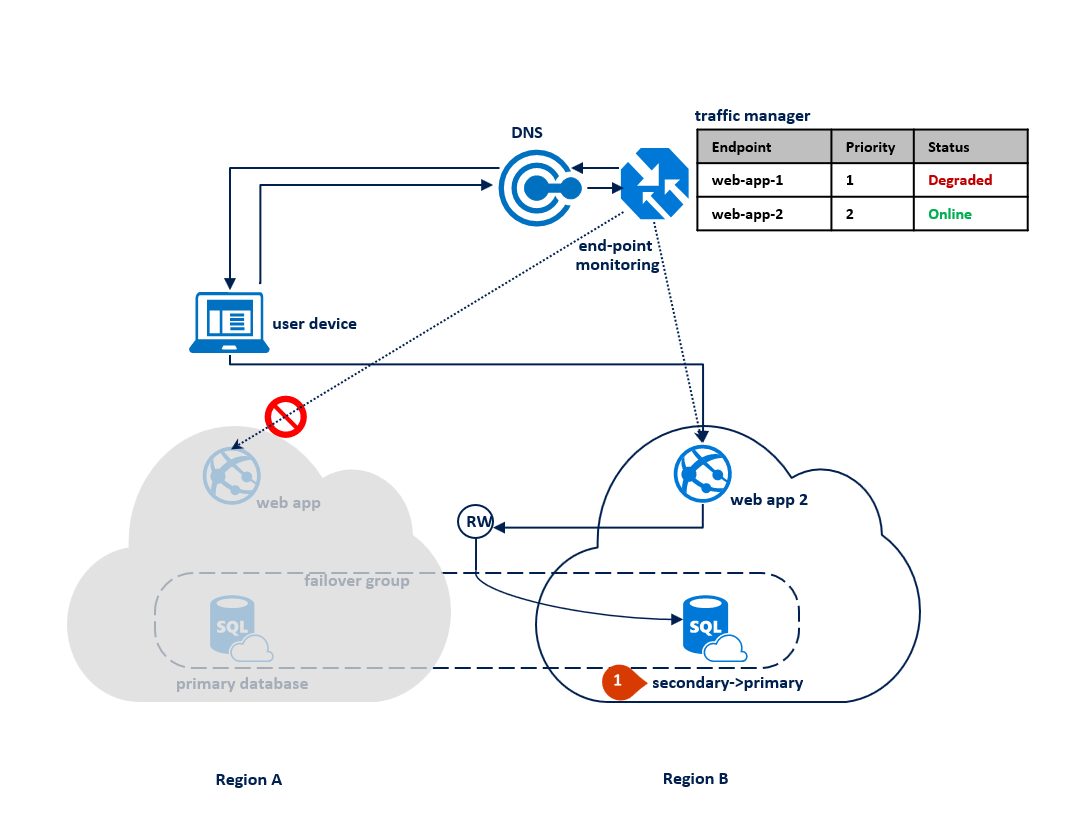
Jika pemadaman terjadi di wilayah B, proses replikasi antara database primer dan sekunder ditangguhkan tetapi hubungan antara keduanya tetap utuh (1). Traffic Manager mendeteksi bahwa konektivitas ke Wilayah B rusak dan menandai aplikasi web endpoint 2 sebagai Terdegradasi (2). Kinerja aplikasi tidak terpengaruh dalam hal ini, tetapi database menjadi terekspos dan oleh karena itu berisiko lebih tinggi kehilangan data jika wilayah A gagal berturut-turut.
Catatan
Untuk pemulihan bencana, kami merekomendasikan konfigurasi dengan penyebaran aplikasi terbatas pada dua wilayah. Ini karena sebagian besar geografi Azure hanya memiliki dua wilayah. Konfigurasi ini tidak melindungi aplikasi Anda dari kegagalan bencana simultan kedua wilayah. Jika terjadi kegagalan seperti itu, Anda dapat memulihkan database Anda di wilayah ketiga menggunakan operasi pemulihan geografis. Untuk informasi selengkapnya, lihat Panduan pemulihan bencana Azure SQL Database.
Setelah pemadaman dimitigasi, database sekunder secara otomatis disinkronkan kembali dengan primer. Selama sinkronisasi, kinerja primer dapat terpengaruh. Dampak spesifik tergantung pada jumlah data yang diperoleh primer baru sejak kegagalan.
Catatan
Setelah pemadaman dimitigasi, Traffic Manager akan mulai merutekan koneksi ke aplikasi di Wilayah A sebagai titik akhir dengan prioritas yang lebih tinggi. Jika Anda ingin menyimpan primer di Wilayah B untuk sementara waktu, Anda harus mengubah tabel prioritas di profil Traffic Manager yang sesuai.
Diagram berikut mengilustrasikan pemadaman di wilayah sekunder:
Keuntungan utama dari pola desain ini adalah:
- Aplikasi web yang sama disebarkan ke kedua wilayah tanpa konfigurasi khusus wilayah dan tidak memerlukan logika tambahan untuk mengelola failover.
- Kinerja aplikasi tidak terpengaruh oleh kegagalan karena aplikasi web dan database selalu berlokasi bersama.
Tradeoff utama adalah bahwa sumber daya aplikasi di Wilayah B kurang digunakan sebagian besar waktu.
Skenario 2: Wilayah Azure untuk kelangsungan bisnis dengan pelestarian data maksimum
Opsi ini paling cocok untuk aplikasi dengan karakteristik berikut:
- Setiap kehilangan data adalah risiko bisnis yang tinggi. Kegagalan database hanya dapat digunakan sebagai upaya terakhir jika pemadaman disebabkan oleh kegagalan besar.
- Aplikasi ini mendukung mode operasi baca-saja dan baca-tulis dan dapat beroperasi dalam "mode baca-saja" untuk jangka waktu tertentu.
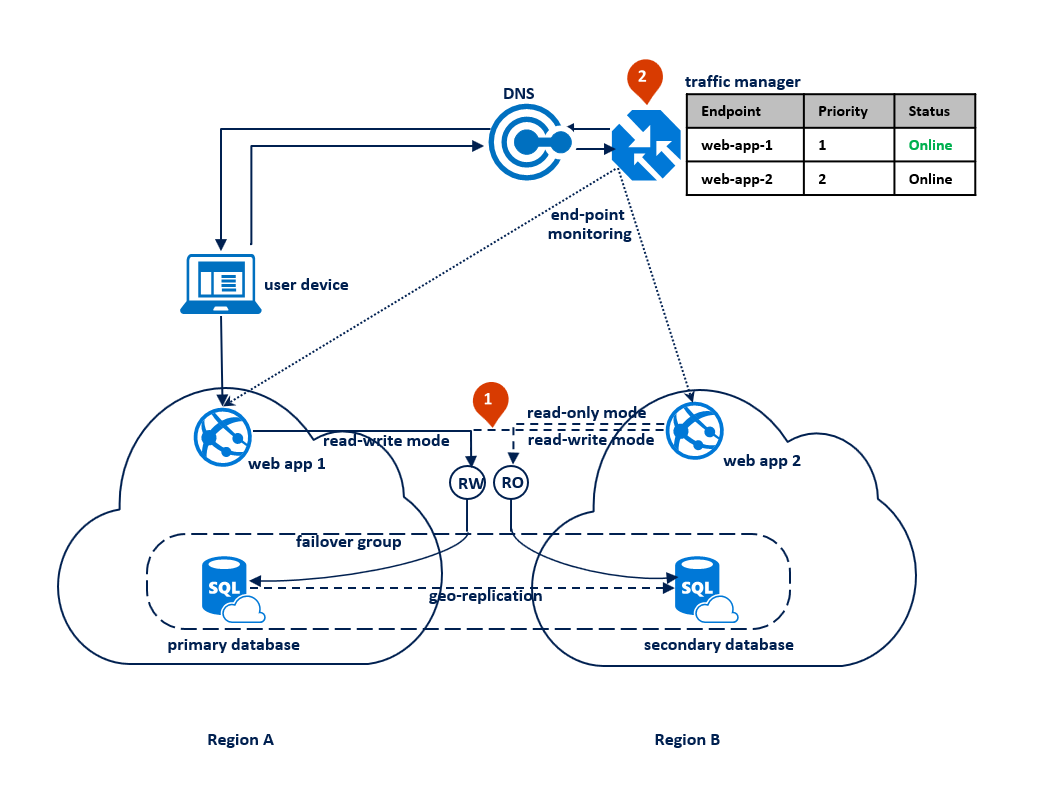
Dalam pola ini, aplikasi beralih ke mode baca-saja ketika koneksi baca-tulis mulai mendapatkan kesalahan waktu habis. Aplikasi web disebarkan ke kedua wilayah dan mencakup koneksi ke titik akhir pendengar baca-tulis dan koneksi yang berbeda ke titik akhir pendengar baca-saja (1). Profil Microsoft Azure Traffic Manager harus menggunakan perutean prioritas. Pemantauan titik akhir harus diaktifkan untuk titik akhir aplikasi di setiap wilayah (2).
Diagram berikut mengilustrasikan konfigurasi ini sebelum pemadaman:
Ketika Traffic Manager mendeteksi kegagalan konektivitas ke wilayah A, secara otomatis mengalihkan lalu lintas pengguna ke instans aplikasi di wilayah B. Dengan pola ini, penting bagi Anda untuk mengatur masa tenggang dengan kehilangan data ke nilai yang cukup tinggi, misalnya 24 jam. Ini memastikan bahwa kehilangan data dicegah jika pemadaman dimitigasi dalam waktu tersebut. Ketika aplikasi web di wilayah B diaktifkan operasi baca-tulis mulai gagal. Pada saat itu, ia harus beralih ke mode baca-saja (1). Dalam mode ini, permintaan secara otomatis dirutekan ke database sekunder. Jika pemadaman disebabkan oleh kegagalan bencana, kemungkinan besar itu tidak dapat dimitigasi dalam masa tenggang. Ketika kedaluwarsa grup kegagalan memicu kegagalan. Setelah itu pendengar baca-tulis menjadi tersedia dan koneksi ke sana berhenti gagal (2). Diagram berikut mengilustrasikan dua tahap proses pemulihan.
Catatan
Jika pemadaman di wilayah utama dimitigasi dalam masa tenggang, Traffic Manager mendeteksi pemulihan konektivitas di wilayah utama dan mengalihkan lalu lintas pengguna kembali ke instans aplikasi di wilayah A. Instans aplikasi tersebut dilanjutkan dan beroperasi dalam mode baca-tulis menggunakan database utama di wilayah A seperti yang diilustrasikan oleh diagram sebelumnya.
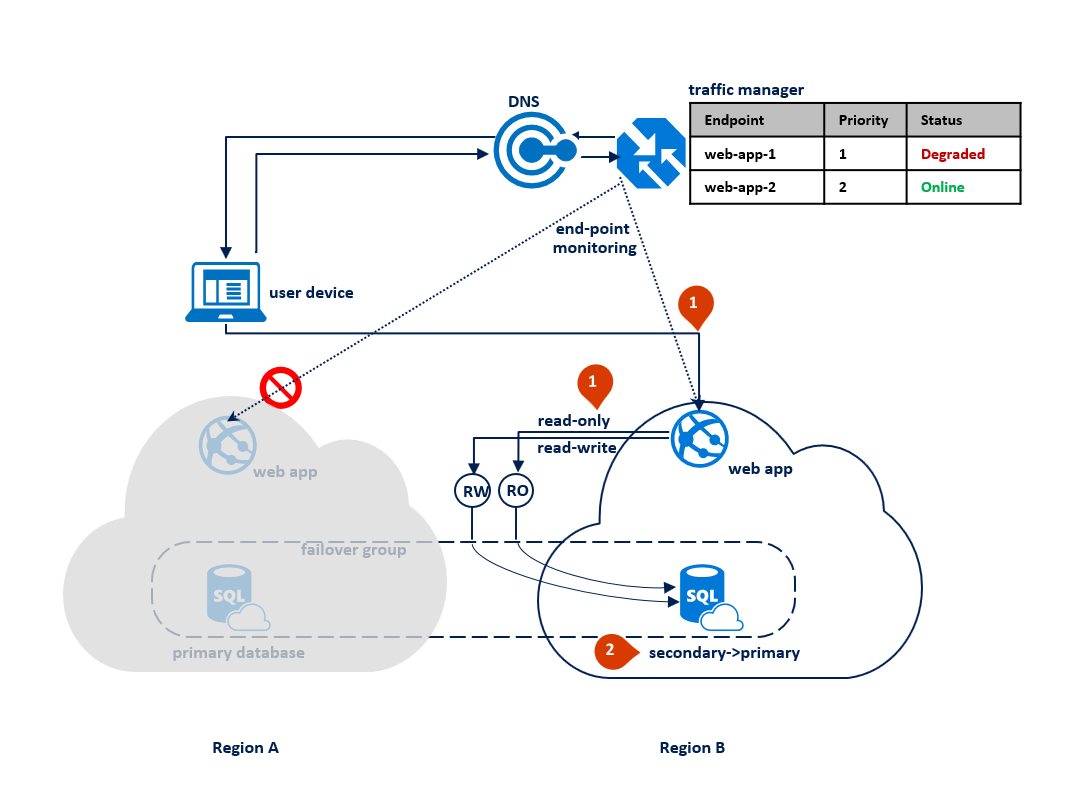
Jika pemadaman terjadi di wilayah B, Traffic Manager mendeteksi kegagalan titik akhir web-app-2 di wilayah B dan menandainya terdegradasi (1). Sementara itu, grup kegagalan mengalihkan pendengar baca-saja ke wilayah A (2). Pemadaman ini tidak berdampak pada pengalaman pengguna akhir tetapi database utama diekspos selama pemadaman. Diagram berikut mengilustrasikan kegagalan di wilayah sekunder:
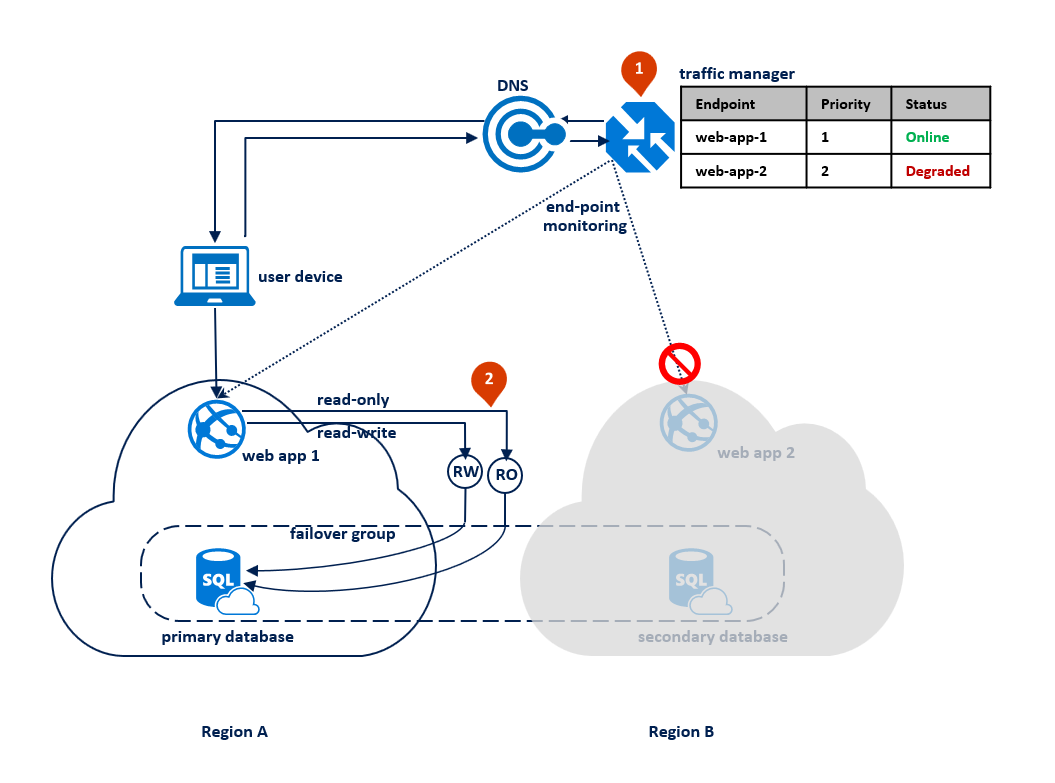
Setelah pemadaman dimitigasi, database sekunder segera disinkronkan dengan primer dan pendengar baca-saja dialihkan kembali ke database sekunder di wilayah B. Selama kinerja sinkronisasi primer dapat sedikit terpengaruh tergantung pada jumlah data yang perlu disinkronkan.
Pola desain ini memiliki beberapa keunggulan:
- Ini menghindari kehilangan data selama pemadaman sementara.
- Waktu henti hanya tergantung pada seberapa cepat Microsoft Azure Traffic Manager mendeteksi kegagalan konektivitas, yang dapat dikonfigurasi.
Tradeoff adalah bahwa aplikasi harus dapat beroperasi dalam mode baca-saja.
Perencanaan kelangsungan bisnis: Pilih desain aplikasi untuk pemulihan bencana cloud
Strategi pemulihan bencana cloud spesifik Anda dapat menggabungkan atau memperluas pola desain ini untuk memenuhi kebutuhan aplikasi Anda dengan sebaik-baiknya. Seperti disebutkan sebelumnya, strategi yang Anda pilih didasarkan pada SLA yang ingin Anda tawarkan kepada pelanggan Anda dan topologi penyebaran aplikasi. Untuk membantu memandu keputusan Anda, tabel berikut membandingkan pilihan berdasarkan tujuan titik pemulihan (RPO) dan estimasi waktu pemulihan (ERT).
| Pola | RPO | ERT |
|---|---|---|
| Penyebaran aktif pasif untuk pemulihan bencana dengan akses database yang terletak bersama | Akses baca-tulis < 5 dtk | Waktu deteksi kegagalan + DNS TTL |
| Penyebaran aktif untuk penyeimbangan beban aplikasi | Akses baca-tulis < 5 dtk | Waktu deteksi kegagalan + DNS TTL |
| Penyebaran aktif pasif untuk penjagaan data | Akses baca-saja < 5 dtk | Akses baca-saja = 0 |
| Akses baca-tulis = nol | Akses baca-tulis = Waktu deteksi kegagalan + masa tenggang dengan kehilangan data |
Langkah berikutnya
- Untuk gambaran umum dan skenario kelangsungan bisnis, lihat Gambaran umum kelangsungan bisnis
- Untuk mempelajari tentang replikasi lokasi geografis aktif, lihat Replikasi lokasi geografis aktif.
- Untuk mempelajari tentang grup failover, lihat Grup failover.
- Untuk informasi tentang replikasi geografis aktif dengan kumpulan elastis, lihat Strategi pemulihan bencana kumpulan elastis.