Strategi pemulihan bencana untuk aplikasi menggunakan kumpulan elastis Azure SQL Database
Berlaku untuk: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database menyediakan beberapa kemampuan untuk menyediakan kelangsungan bisnis aplikasi Anda ketika insiden bencana terjadi. Kumpulan elastis dan database tunggal mendukung jenis kemampuan pemulihan bencana (DR) yang sama. Artikel ini menjelaskan beberapa strategi DR untuk kumpulan elastis yang memanfaatkan fitur kelangsungan bisnis Azure SQL Database ini.
Artikel ini menggunakan pola aplikasi ISV SaaS kanonis berikut:
Aplikasi web berbasis cloud modern menyediakan satu database untuk setiap pengguna akhir. ISV memiliki banyak pelanggan dan karenanya menggunakan banyak database, yang dikenal sebagai database penyewa. Karena database penyewa biasanya memiliki pola aktivitas yang tidak dapat diprediksi, ISV menggunakan kumpulan elastis untuk membuat biaya database sangat dapat diprediksi selama jangka waktu yang lama. Kumpulan elastis juga menyederhanakan manajemen performa saat aktivitas pengguna melonjak. Selain database penyewa, aplikasi juga menggunakan beberapa database untuk mengelola profil pengguna, keamanan, mengumpulkan pola penggunaan, dll. Ketersediaan penyewa individu tidak berdampak pada ketersediaan aplikasi secara keseluruhan. Namun, ketersediaan dan performa database manajemen sangat penting untuk fungsi aplikasi dan jika database manajemen offline, seluruh aplikasi offline.
Artikel ini membahas strategi DR yang mencakup berbagai skenario mulai dari aplikasi startup sensitif biaya hingga yang memiliki persyaratan ketersediaan yang ketat.
Catatan
Jika Anda menggunakan database Premium atau Business Critical dan kumpulan elastis, Anda dapat membuatnya tahan terhadap penonaktifan regional dengan mengonversinya ke konfigurasi penyebaran berlebihan zona. Lihat Database yang berlebihan terhadap zona.
Skenario 1. Startup yang menghitungkan biaya dengan matang
Saya adalah seorang bisnis startup dan sangat mempertimbangkan biaya dengan matang. Saya ingin menyederhanakan penyebaran dan manajemen aplikasi dan saya dapat memiliki SLA terbatas untuk pelanggan individu. Tapi saya ingin memastikan aplikasi secara keseluruhan tidak pernah offline.
Untuk memenuhi persyaratan kesederhanaan, sebarkan semua database penyewa ke dalam satu kumpulan elastis di wilayah Azure pilihan Anda dan sebarkan database manajemen sebagai database tunggal yang direplikasi geografis. Untuk pemulihan bencana penyewa, gunakan replikasi geografis, yang tidak dikenakan biaya tambahan. Untuk memastikan ketersediaan database manajemen, replikasi secara geografis ke wilayah lain menggunakan grup failover (langkah 1). Biaya berkelanjutan dari konfigurasi pemulihan bencana dalam skenario ini sama dengan total biaya database sekunder. Konfigurasi ini diilustrasikan pada diagram berikutnya.
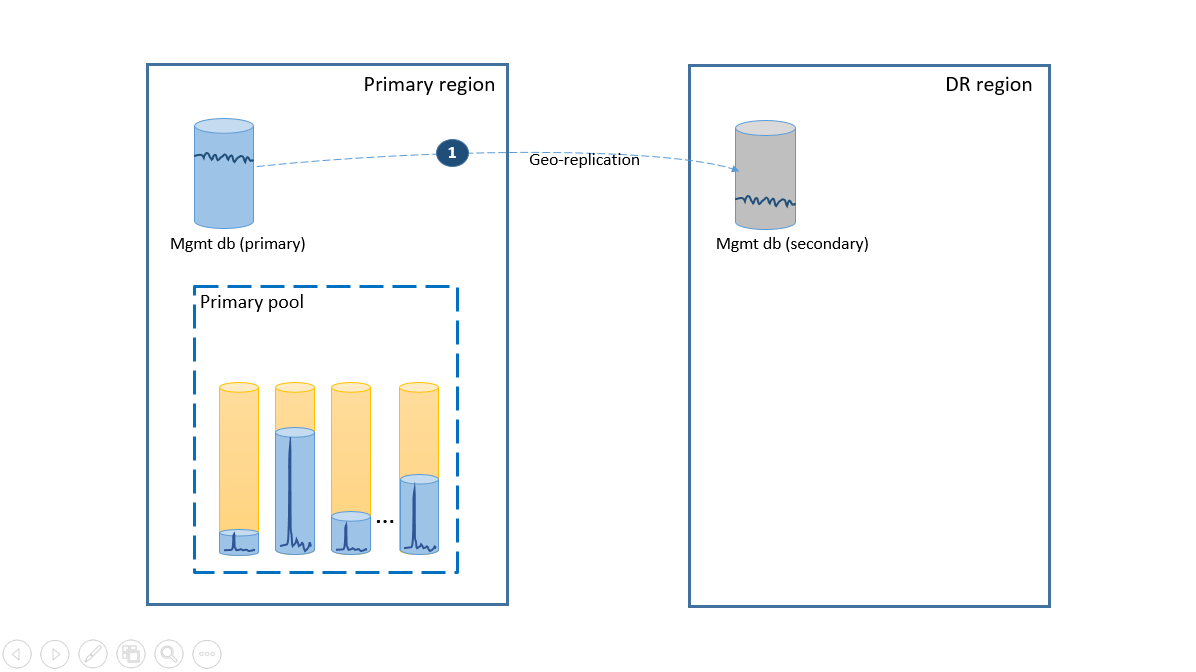
Jika penonaktifan terjadi di wilayah utama, langkah-langkah pemulihan untuk membawa aplikasi Anda online diilustrasikan oleh diagram berikutnya.
- Grup failover memulai failover otomatis database manajemen ke wilayah DR. Aplikasi ini secara otomatis terhubung kembali ke database utama dan semua akun dan penyewa baru yang baru dibuat di wilayah DR. Pelanggan yang ada melihat data mereka untuk sementara waktu tidak tersedia.
- Buat kumpulan elastis dengan konfigurasi yang sama dengan kumpulan asli (2).
- Gunakan pemulihan geografis untuk membuat salinan database penyewa (3). Anda dapat mempertimbangkan untuk memicu pemulihan individu oleh koneksi pengguna akhir atau menggunakan beberapa skema prioritas khusus aplikasi lainnya.
Pada titik ini aplikasi Anda kembali online di wilayah DR, tetapi beberapa pelanggan mengalami keterlambatan saat mengakses data mereka.
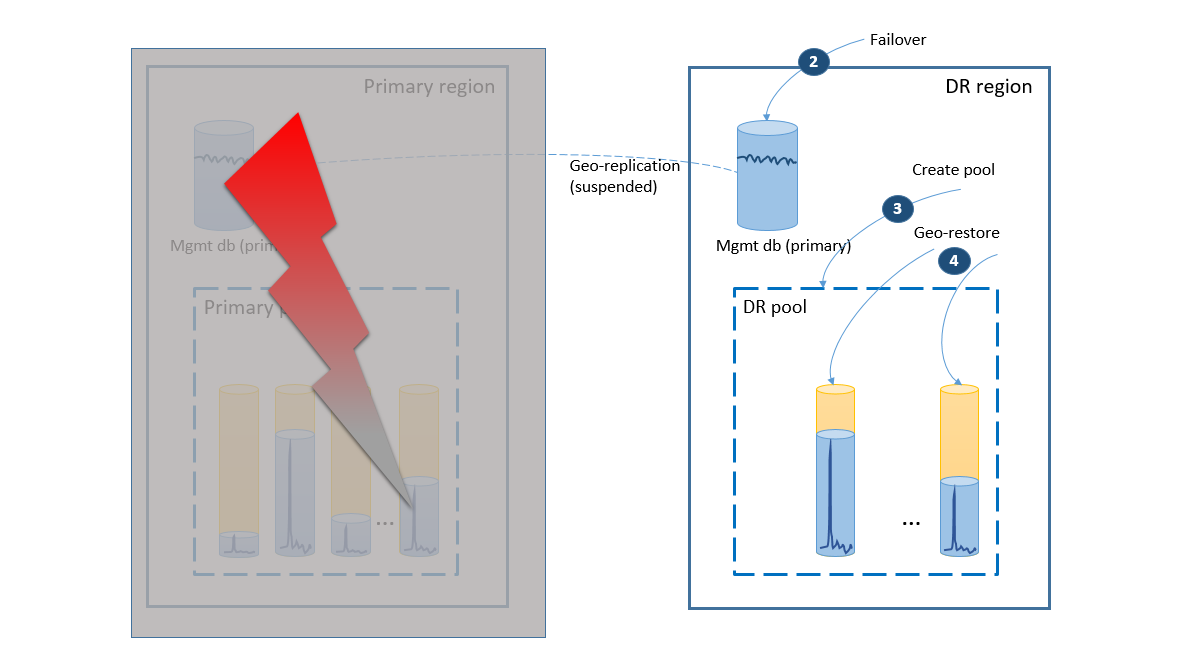
Jika penonaktifan bersifat sementara, ada kemungkinan wilayah utama dipulihkan oleh Azure sebelum semua pemulihan database selesai di wilayah DR. Dalam hal ini, orkestrasi memindahkan aplikasi kembali ke wilayah utama. Proses ini mengambil langkah-langkah yang diilustrasikan pada diagram berikutnya.
- Batalkan semua permintaan pemulihan geografis yang luar biasa.
- Gagal atas database manajemen ke wilayah utama (5). Setelah pemulihan wilayah, primer lama secara otomatis menjadi sekunder. Sekarang mereka beralih peran lagi.
- Ubah string koneksi aplikasi untuk mengarahkan kembali ke wilayah utama. Sekarang semua akun baru dan database penyewa dibuat di wilayah utama. Pelanggan yang ada melihat data mereka untuk sementara waktu tidak tersedia.
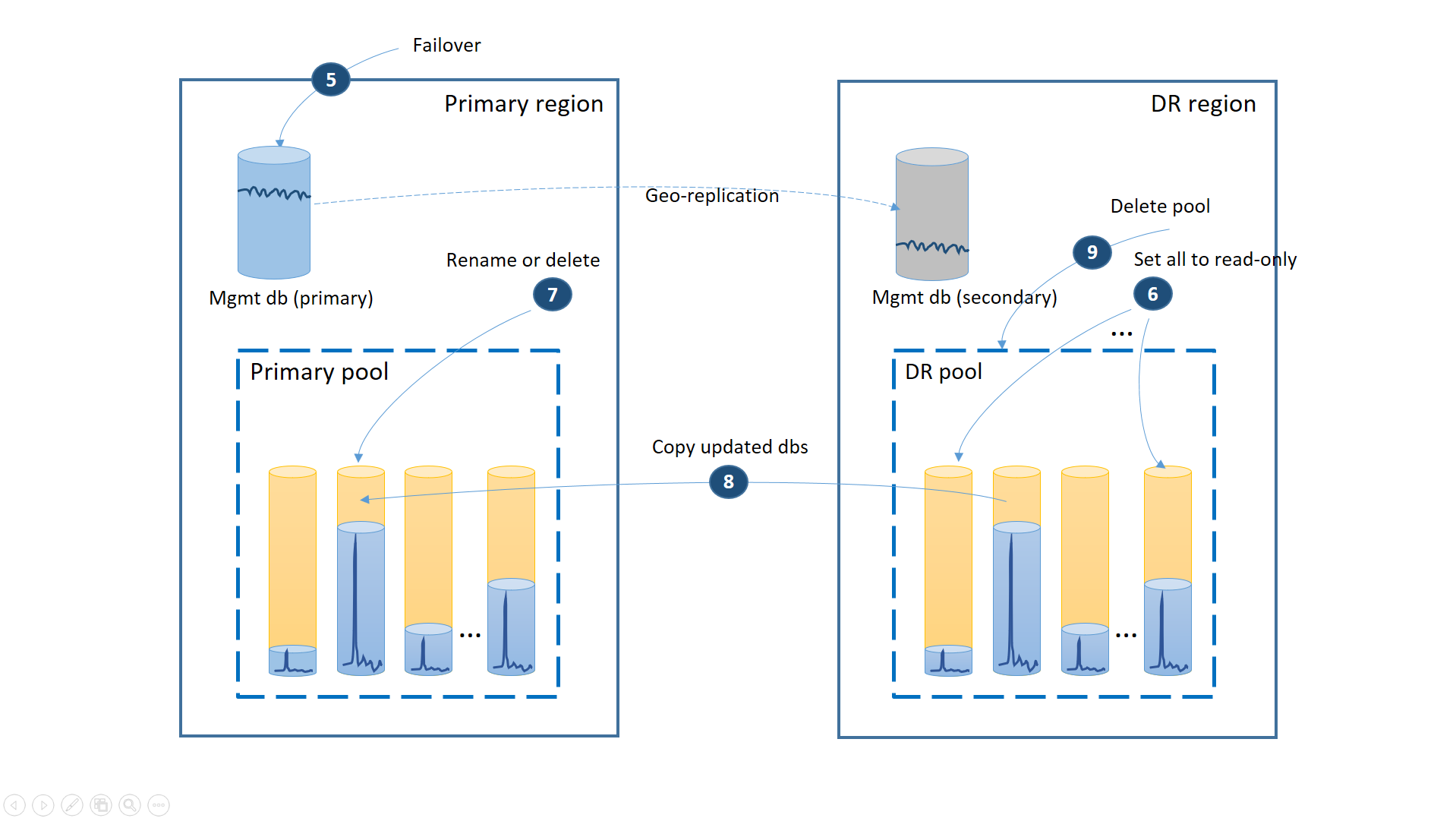
- Atur semua database di kumpulan DR ke baca-saja untuk memastikan database tidak dapat diubah di wilayah DR (6).
- Untuk setiap database di kumpulan DR yang telah berubah sejak pemulihan, ganti nama atau hapus database yang sesuai di kumpulan utama (7).
- Salin database yang diperbarui dari kumpulan DR ke kumpulan utama (8).
- Hapus kumpulan DR (9)
Pada titik ini aplikasi Anda sedang online di wilayah utama dengan semua database penyewa tersedia di kumpulan utama.
Keuntungan
Manfaat utama dari strategi ini adalah biaya berkelanjutan yang rendah untuk redundansi tingkat data. Azure SQL Database secara otomatis mencadangkan database tanpa regenerasi aplikasi tanpa biaya tambahan. Biaya hanya dikeluarkan ketika database elastis dipulihkan.
Konsekuensi
Konsekuensi adalah bahwa pemulihan lengkap semua database penyewa membutuhkan waktu yang signifikan. Lamanya waktu tergantung pada jumlah total pemulihan yang Anda mulai di wilayah DR dan ukuran keseluruhan database penyewa. Bahkan jika Anda memprioritaskan beberapa pemulihan penyewa daripada yang lain, Anda bersaing dengan semua pemulihan lain yang dimulai di wilayah yang sama dengan arbitrase layanan dan pembatasan untuk meminimalkan dampak keseluruhan pada database pelanggan yang ada. Selain itu, pemulihan database penyewa tidak dapat dimulai sampai kumpulan elastis baru di wilayah DR dibuat.
Skenario 2. Aplikasi matang dengan layanan bertingkat
Saya adalah aplikasi SaaS yang matang dengan penawaran layanan berjenjang dan SLA yang berbeda untuk pelanggan uji coba dan untuk pelanggan yang membayar. Untuk pelanggan uji coba, saya harus mengurangi biaya sebanyak mungkin. Pelanggan uji coba dapat mengalami waktu henti tetapi saya ingin mengurangi kemungkinannya. Bagi pelanggan yang membayar, waktu henti apa pun adalah risiko penerbangan. Jadi saya ingin memastikan bahwa pelanggan yang membayar selalu dapat mengakses data mereka.
Untuk mendukung skenario ini, pisahkan penyewa uji coba dari penyewa berbayar dengan memasukkannya ke dalam kumpulan elastis terpisah. Pelanggan uji coba memiliki eDTU atau vCores yang lebih rendah per penyewa dan SLA yang lebih rendah dengan waktu pemulihan yang lebih lama. Pelanggan yang membayar berada di kumpulan dengan eDTU atau vCores yang lebih tinggi per penyewa dan SLA yang lebih tinggi. Untuk menjamin waktu pemulihan terendah, database penyewa pelanggan yang membayar direplikasi secara geografis. Konfigurasi ini diilustrasikan pada diagram berikutnya.
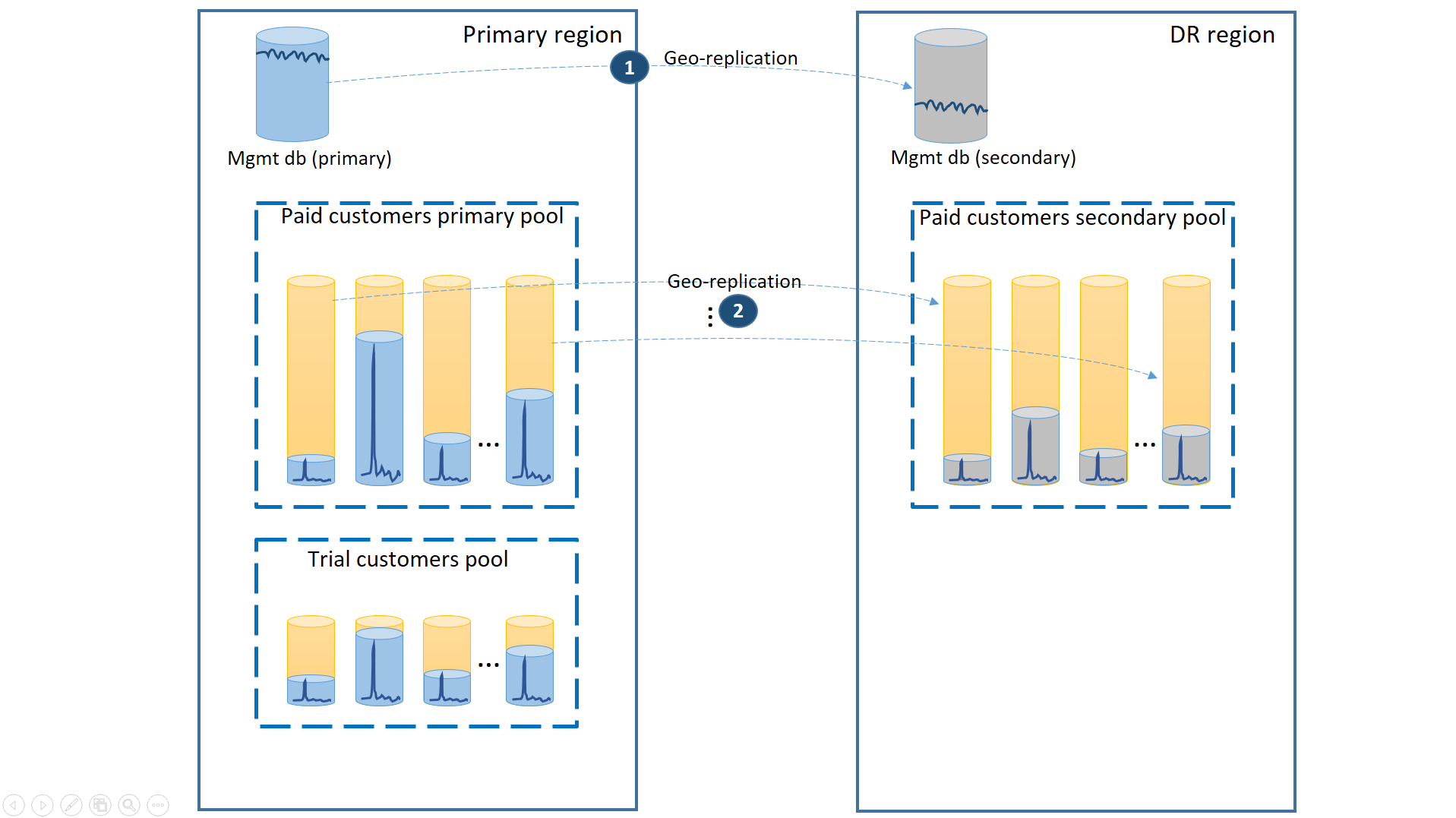
Seperti dalam skenario pertama, database manajemen cukup aktif sehingga Anda menggunakan satu database yang direplikasi secara geografis untuknya (1). Ini memastikan performa yang dapat diprediksi untuk langganan pelanggan baru, pembaruan profil, dan operasi manajemen lainnya. Wilayah di mana database manajemen utama berada adalah wilayah utama dan wilayah di mana database manajemen sekunder berada adalah wilayah DR.
Database penyewa pelanggan yang membayar memiliki database aktif di kumpulan berbayar yang disediakan di wilayah utama. Menyediakan kumpulan sekunder dengan nama yang sama di wilayah DR. Setiap penyewa direplikasi secara geografis ke kumpulan sekunder (2). Ini memungkinkan pemulihan cepat semua database penyewa menggunakan failover.
Jika penonaktifan terjadi di wilayah utama, langkah-langkah pemulihan untuk membawa aplikasi Anda online diilustrasikan oleh diagram berikutnya:
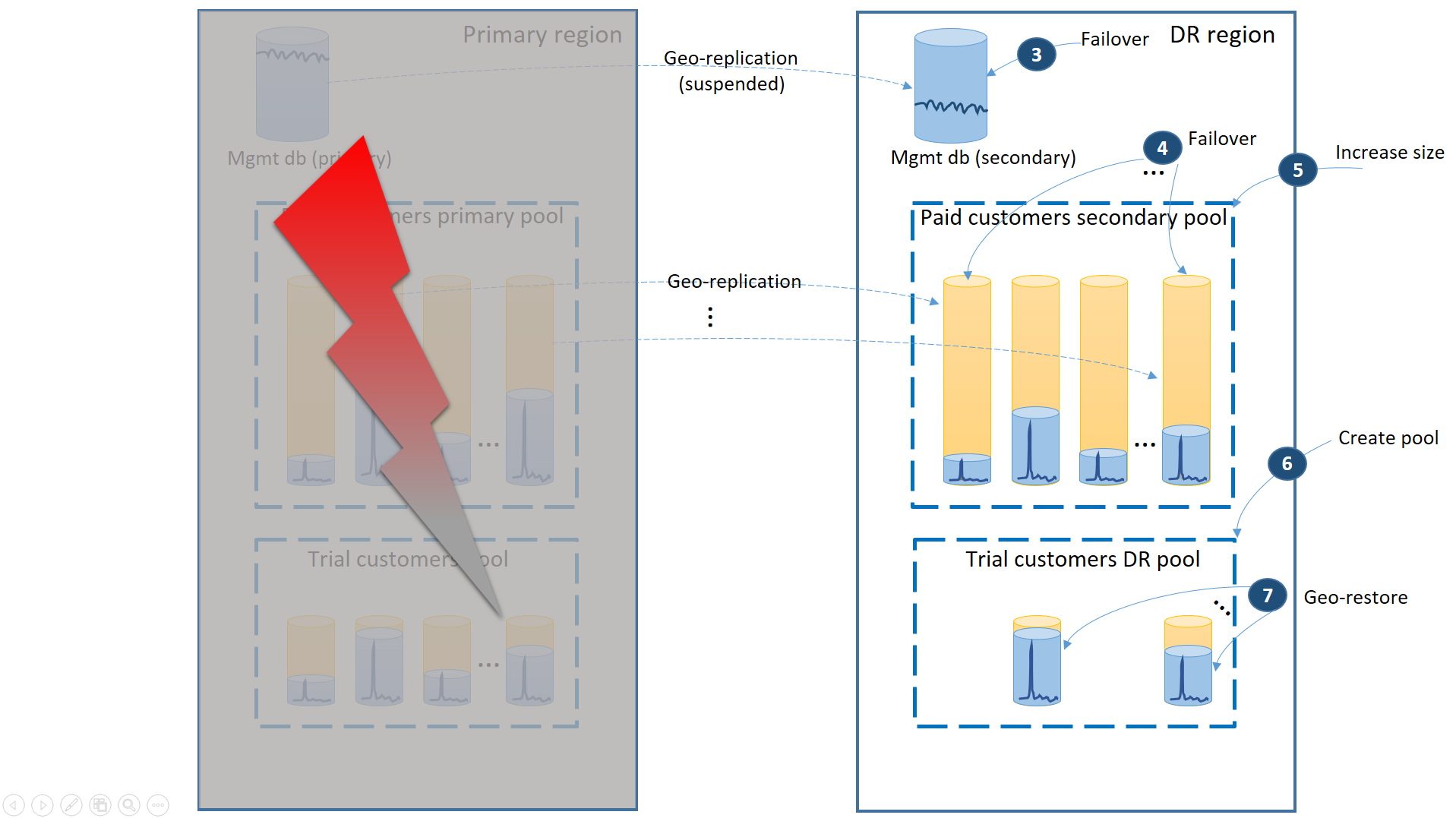
- Gagal dengan segera atas database manajemen ke wilayah DR (3).
- Ubah string koneksi aplikasi untuk menunjuk ke wilayah DR. Sekarang semua akun baru dan database penyewa dibuat di wilayah DR. Pelanggan yang ada melihat data mereka untuk sementara waktu tidak tersedia.
- Gagal atas database penyewa berbayar ke kumpulan di wilayah DR untuk segera memulihkan ketersediaannya (4). Karena failover adalah perubahan tingkat metadata cepat, pertimbangkan pengoptimalan di mana failover individu dipicu sesuai permintaan oleh koneksi pengguna akhir.
- Jika ukuran eDTU kumpulan sekunder atau nilai vCore Anda lebih rendah dari yang utama karena database sekunder hanya memerlukan kapasitas untuk memproses log perubahan saat mereka berada di sekunder, segera tingkatkan kapasitas kumpulan sekarang untuk mengakomodasi beban kerja penuh semua penyewa (5).
- Buat kumpulan elastis baru dengan nama yang sama dan konfigurasi yang sama di wilayah DR untuk database pelanggan uji coba (6).
- Setelah kumpulan pelanggan uji coba dibuat, gunakan pemulihan geografis untuk memulihkan database penyewa uji coba individual ke kumpulan baru (7). Anda dapat mempertimbangkan untuk memicu pemulihan individu oleh koneksi pengguna akhir atau menggunakan beberapa skema prioritas khusus aplikasi lainnya.
Pada titik ini aplikasi Anda kembali online di wilayah DR. Semua pelanggan yang membayar memiliki akses ke data mereka sementara pelanggan uji coba mengalami keterlambatan saat mengakses data mereka.
Saat wilayah utama dipulihkan oleh Azure setelah Anda memulihkan aplikasi di wilayah DR, Anda dapat terus menjalankan aplikasi di wilayah tersebut atau Anda dapat memutuskan untuk gagal kembali ke wilayah utama. Jika wilayah utama dipulihkan sebelum proses failover selesai, pertimbangkan untuk segera gagal kembali. Failback mengambil langkah-langkah yang diilustrasikan dalam diagram berikutnya:
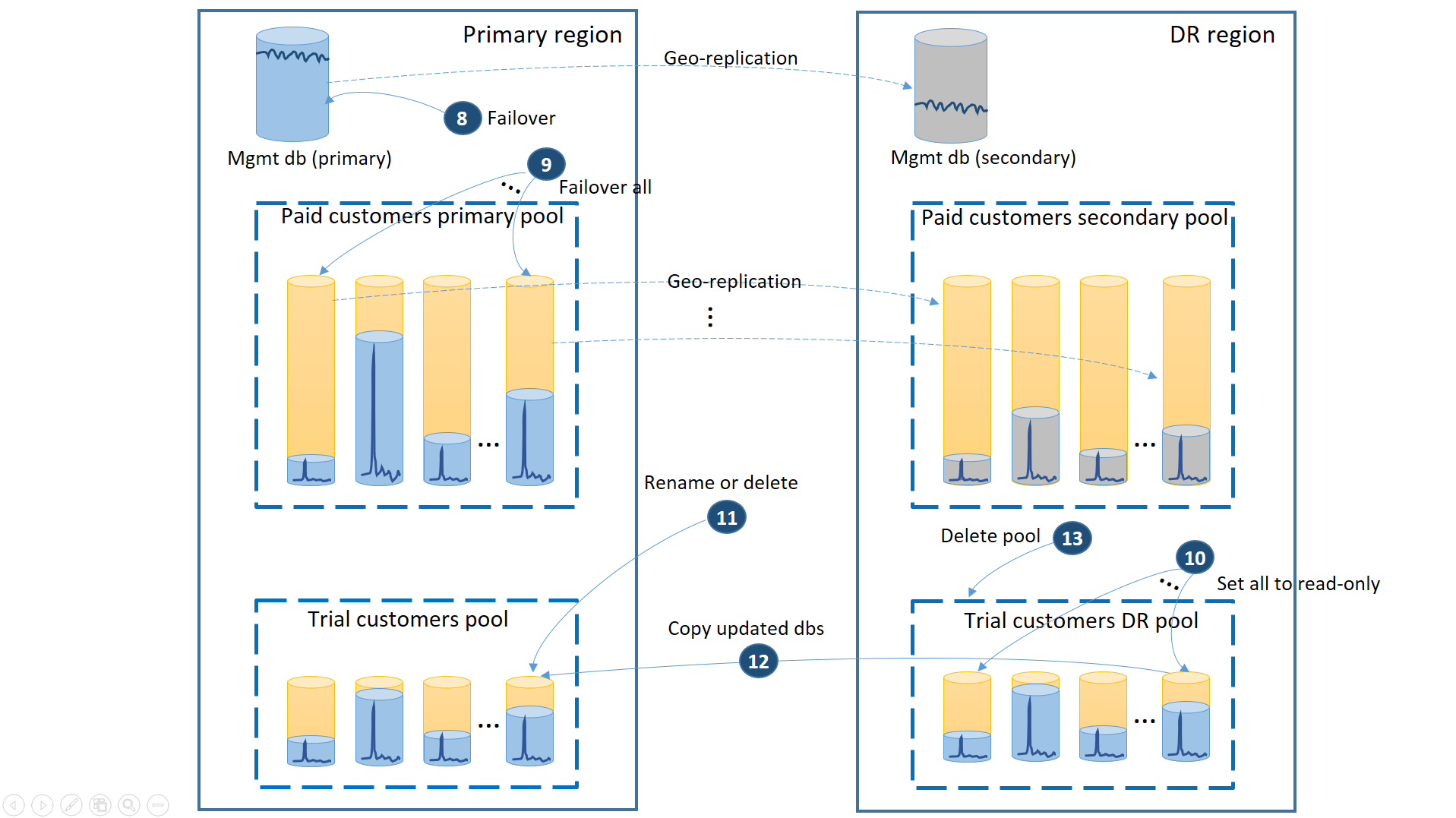
- Batalkan semua permintaan pemulihan geografis yang luar biasa.
- Memindahkan database manajemen (8). Setelah pemulihan wilayah, primer lama secara otomatis menjadi sekunder. Sekarang menjadi wilayah utama lagi.
- Gagal atas database manajemen (9). Demikian pula, setelah pemulihan wilayah, utama lama secara otomatis menjadi sekunder. Sekarang mereka menjadi wilayah utama lagi.
- Set database uji coba yang dipulihkan yang telah berubah di wilayah DR menjadi baca-saja (10).
- Untuk setiap database dalam kumpulan DR pelanggan uji coba yang berubah sejak pemulihan, ganti nama atau hapus database yang sesuai di kumpulan utama pelanggan uji coba (11).
- Salin database yang diperbarui dari kumpulan DR ke kumpulan utama (12).
- Hapus kumpulan DR (13).
Catatan
Operasi failover adalah asinkron. Untuk meminimalkan waktu pemulihan, penting bagi Anda untuk menjalankan perintah failover database penyewa dalam batch setidaknya 20 database.
Keuntungan
Manfaat utama dari strategi ini adalah menyediakan SLA tertinggi bagi pelanggan yang membayar. Ini juga menjamin bahwa uji coba baru tidak diblokir segera setalah kumpulan DR percobaan dibuat.
Konsekuensi
Konsekuensi adalah bahwa pengaturan ini meningkatkan total biaya database penyewa dengan biaya kumpulan DR sekunder untuk pelanggan berbayar. Selain itu, jika kolam sekunder memiliki ukuran yang berbeda, pelanggan yang membayar mengalami performa yang lebih rendah setelah failover sampai peningkatan kumpulan di wilayah DR selesai.
Skenario 3. Aplikasi yang didistribusikan secara geografis dengan layanan bertingkat
Saya memiliki aplikasi SaaS yang matang dengan penawaran layanan bertingkat. Saya ingin menawarkan SLA yang sangat agresif kepada pelanggan berbayar saya dan meminimalkan risiko dampak ketika penonaktifan terjadi karena gangguan singkat pun dapat menyebabkan ketidakpuasan pelanggan. Sangat penting bahwa pelanggan yang membayar selalu dapat mengakses data mereka. Uji coba gratis dan SLA tidak ditawarkan selama masa percobaan.
Untuk mendukung skenario ini, gunakan tiga kumpulan elastis terpisah. Penyediaan dua kumpulan ukuran yang sama dengan eDTUs tinggi atau vCores per database di dua wilayah berbeda untuk berisi database penyewa pelanggan berbayar. Kumpulan ketiga yang berisi penyewa uji coba dapat memiliki eDTUs atau vCores per database yang lebih rendah dan disediakan di salah satu dari dua wilayah.
Untuk menjamin waktu pemulihan terendah selama pemadaman, database penyewa pelanggan yang membayar direplikasi secara geografis dengan 50% database utama di masing-masing dari dua wilayah. Demikian pula, setiap wilayah memiliki 50% database sekunder. Dengan cara ini, jika suatu wilayah offline, hanya 50% dari database pelanggan berbayar yang terkena dampak dan harus gagal. Database lainnya tetap utuh. Konfigurasi ini diilustrasikan dalam diagram berikut:
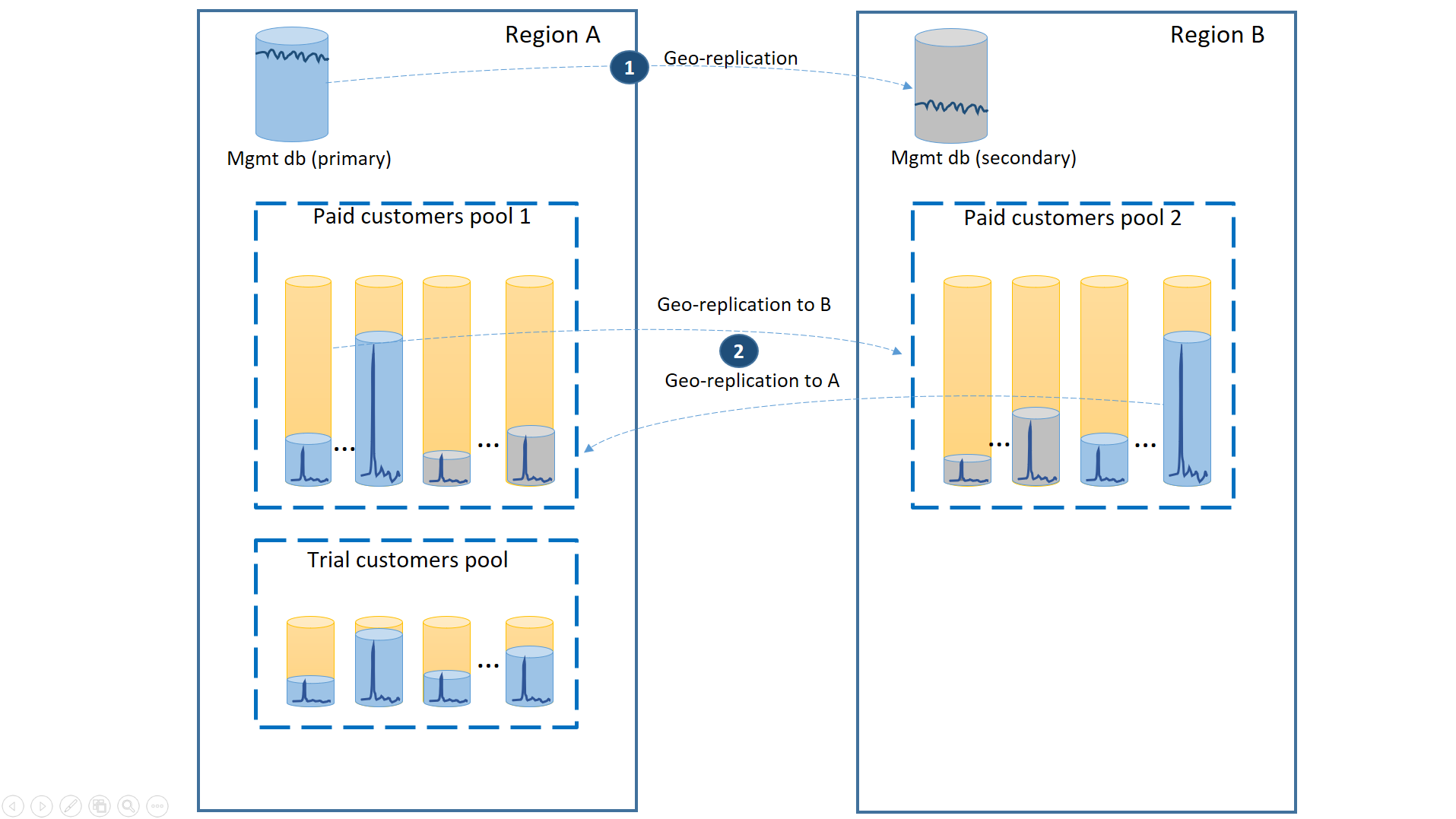
Seperti dalam skenario sebelumnya, database manajemen cukup aktif sehingga mengonfigurasinya sebagai database replikasi geografis tunggal (1). Ini memastikan performa yang dapat diprediksi untuk langganan pelanggan baru, pembaruan profil, dan operasi manajemen lainnya. Wilayah A adalah wilayah utama untuk database manajemen dan wilayah B digunakan untuk pemulihan database manajemen.
Database penyewa pelanggan yang membayar juga direplikasi secara geografis tetapi dengan utama dan sekunder dibagi antara wilayah A dan wilayah B (2). Dengan cara ini, database utama penyewa yang terkena dampak penonaktifan dapat gagal ke wilayah lain dan menjadi tersedia. Setengah dari database penyewa lainnya tidak terpengaruh sama sekali.
Diagram berikutnya mengilustrasikan langkah pemulihan yang harus diambil jika penonaktifan terjadi di wilayah A.
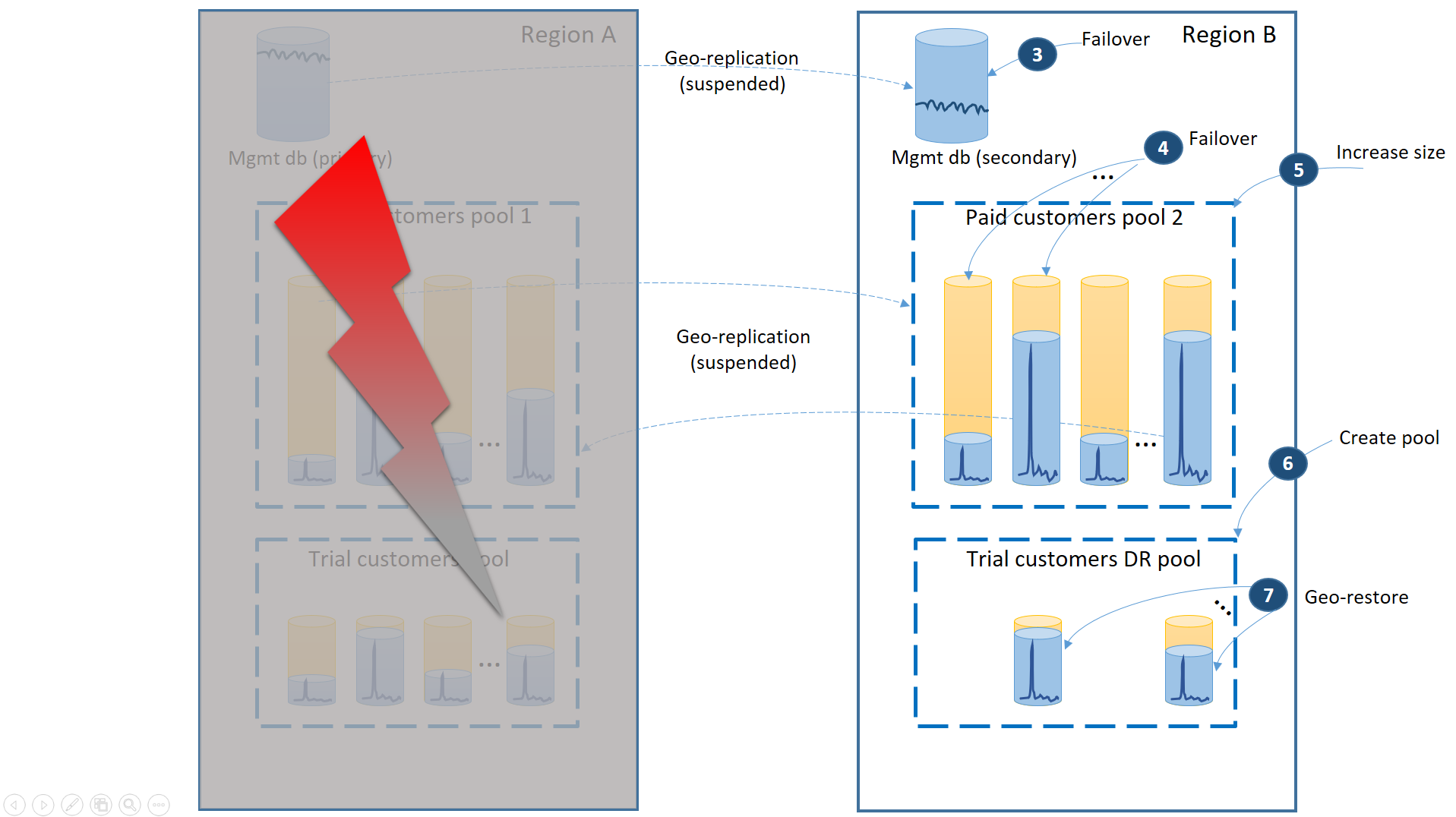
- Gagal dengan segera atas database manajemen ke wilayah B (3).
- Ubah string koneksi aplikasi untuk menunjuk ke database manajemen di wilayah B. Ubah database manajemen untuk memastikan akun baru dan database penyewa dibuat di wilayah B dan database penyewa yang ada juga ditemukan di sana. Pelanggan yang ada melihat data mereka untuk sementara waktu tidak tersedia.
- Gagal atas database penyewa berbayar ke kumpulan 2 di wilayah B untuk segera memulihkan ketersediaannya (4). Karena failover adalah perubahan tingkat metadata cepat, pertimbangkan pengoptimalan di mana failover individu dipicu sesuai permintaan oleh koneksi pengguna akhir.
- Karena sekarang kumpulan 2 hanya berisi database utama, total beban kerja di kumpulan meningkat dan dapat segera meningkatkan ukuran eDTU (5) atau jumlah vCores.
- Buat kumpulan elastis baru dengan nama yang sama dan konfigurasi yang sama di wilayah B untuk database pelanggan uji coba (6).
- Setelah kumpulan dibuat, gunakan pemulihan geografis untuk memulihkan database penyewa uji coba individual ke dalam kumpulan (7). Anda dapat mempertimbangkan untuk memicu pemulihan individu oleh koneksi pengguna akhir atau menggunakan beberapa skema prioritas khusus aplikasi lainnya.
Catatan
Operasi failover adalah asinkron. Untuk meminimalkan waktu pemulihan, penting bagi Anda untuk menjalankan perintah failover database penyewa dalam batch setidaknya 20 database.
Pada titik ini aplikasi Anda kembali online di wilayah B. Semua pelanggan yang membayar memiliki akses ke data mereka sementara pelanggan uji coba mengalami keterlambatan saat mengakses data mereka.
Ketika wilayah A dipulihkan, Anda perlu memutuskan apakah Anda ingin menggunakan wilayah B untuk pelanggan uji coba atau failback menggunakan kumpulan pelanggan uji coba di wilayah A. Salah satu kriteria bisa menjadi % database penyewa uji coba yang diubah sejak pemulihan. Terlepas dari keputusan itu, Anda perlu menyeimbangkan kembali penyewa berbayar di antara dua kumpulan. Diagram berikutnya mengilustrasikan proses saat database penyewa uji coba gagal kembali ke wilayah A.
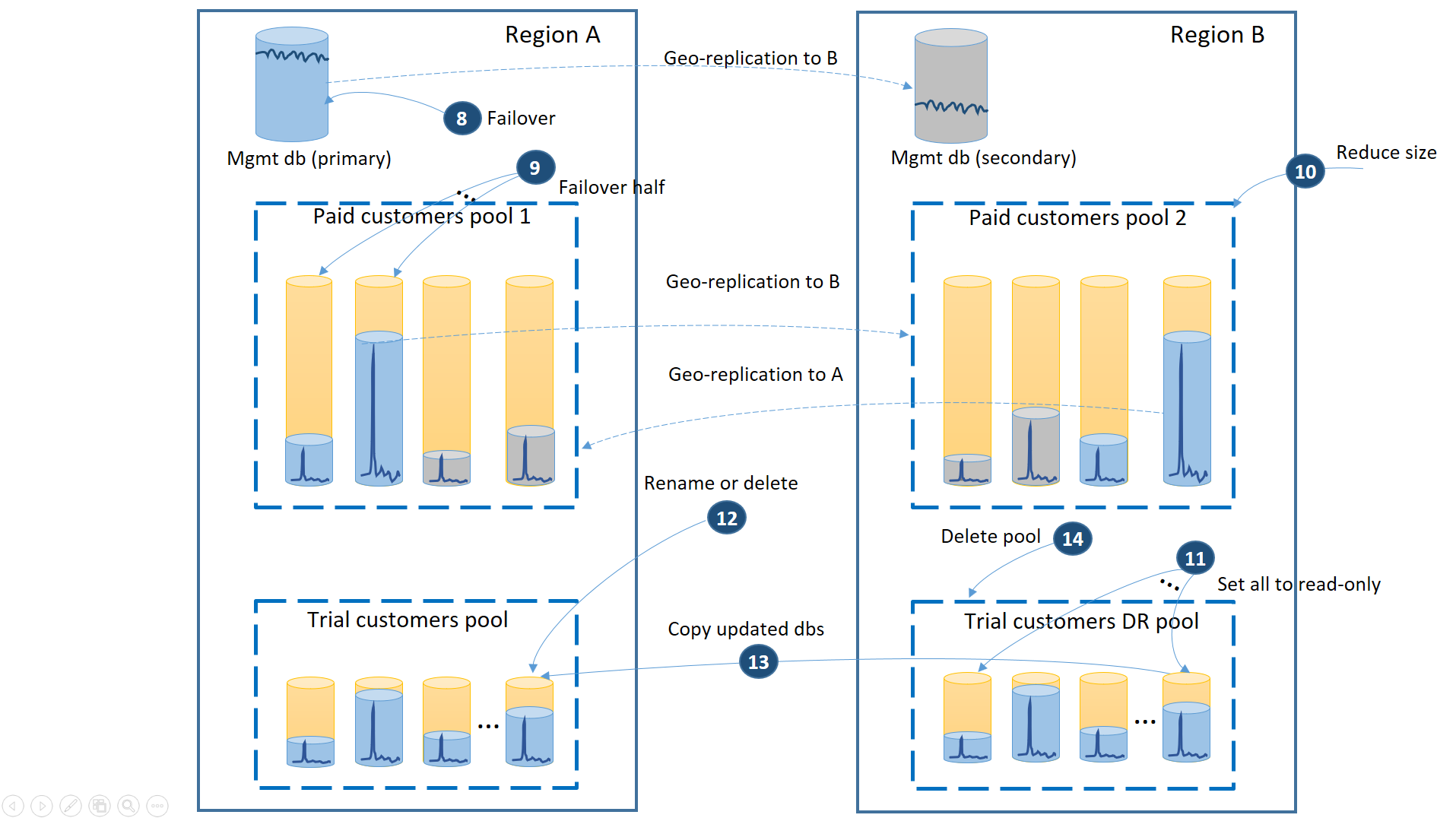
- Batalkan semua permintaan pemulihan geografis yang beredar untuk menguji coba kumpulan DR.
- Memindahkan database manajemen (8). Setelah pemulihan wilayah, primer lama secara otomatis menjadi sekunder. Sekarang menjadi wilayah utama lagi.
- Pilih database penyewa berbayar mana yang dipindahkan kembali ke kumpulan 1 dan mulai failover ke sekunder mereka (9). Setelah pemulihan wilayah, semua database di kumpulan 1 secara otomatis menjadi sekunder. Sekarang 50% dari mereka menjadi wilayah utama lagi.
- Kurangi ukuran kumpulan 2 ke eDTU asli (10) atau jumlah vCores.
- Atur semua database uji coba yang dipulihkan di wilayah B menjadi baca-saja (11).
- Untuk setiap database di kumpulan DR yang telah berubah sejak pemulihan, ganti nama atau hapus database yang sesuai di kumpulan utama (12).
- Salin database yang diperbarui dari kumpulan DR ke kumpulan utama (13).
- Hapus kumpulan DR (14).
Keuntungan
Keuntungan utama dari strategi ini adalah:
- Ini mendukung SLA paling agresif untuk pelanggan yang membayar karena memastikan bahwa penonaktifan tidak dapat berdampak pada lebih dari 50% database penyewa.
- Ini juga menjamin bahwa uji coba baru tidak diblokir segera setelah uji coba kumpulan DR dibuat selama pemulihan.
- Ini memungkinkan penggunaan kapasitas kumpulan yang lebih efisien karena 50% database sekunder di kumpulan 1 dan kumpulan 2 dijamin kurang aktif daripada database utama.
Konsekuensi
Konsekuensi utama adalah:
- Operasi CRUD terhadap database manajemen memiliki latensi yang lebih rendah untuk pengguna akhir yang terhubung ke wilayah A daripada untuk pengguna akhir yang terhubung ke wilayah B saat dijalankan terhadap basis data manajemen utama.
- Ini membutuhkan desain yang lebih kompleks dari database manajemen. Misalnya, setiap baris penyewa memiliki tag lokasi yang perlu diubah selama failover dan failback kembali.
- Pelanggan yang membayar mungkin mengalami performa yang lebih rendah dari biasanya sampai peningkatan kumpulan di wilayah B selesai.
Ringkasan
Artikel ini berfokus pada strategi pemulihan bencana untuk tingkat database yang digunakan oleh aplikasi multipenyewa SaaS ISV. Strategi yang Anda pilih didasarkan pada kebutuhan aplikasi, seperti model bisnis, SLA yang ingin Anda tawarkan kepada pelanggan Anda, kendala anggaran, dll. Masing-masing strategi yang dijelaskan mendeskripsikan keuntungan dan konsekuensi sehingga Anda dapat membuat keputusan berdasarkan informasi. Selain itu, aplikasi spesifik Anda mungkin menyertakan komponen Azure lainnya. Jadi Anda mengulas panduan kelangsungan bisnis mereka dan mengatur pemulihan tingkat database dengan mereka. Untuk mempelajari selengkapnya tentang mengelola pemulihan aplikasi database di Azure, lihat Mendesain solusi cloud untuk pemulihan bencana.
Langkah berikutnya
- Untuk mempelajari tentang pencadangan otomatis Azure SQL Database, lihat Pencadangan otomatis Azure SQL Database.
- Untuk gambaran umum dan skenario kelangsungan bisnis, lihat Gambaran umum kelangsungan bisnis.
- Untuk mempelajari tentang menggunakan pencadangan otomatis untuk pemulihan, lihat memulihkan database dari cadangan yang dimulai layanan.
- Untuk mempelajari tentang opsi pemulihan yang lebih cepat, lihat Replikasi geografis aktif dan grup Failover.
- Untuk mempelajari tentang menggunakan pencadangan otomatis untuk pengarsipan, lihat salinan database.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk