Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database
Artikel ini menjelaskan berbagai jenis ruang penyimpanan untuk database di Azure SQL Database. Meskipun jarang, artikel ini menyertakan langkah-langkah yang dapat diambil ketika ruang file yang dialokasikan perlu dikelola secara eksplisit.
Gambaran Umum
Dengan Azure SQL Database, ada pola beban kerja di mana alokasi file data yang mendasar untuk database dapat menjadi lebih besar dari jumlah halaman data yang digunakan. Kondisi ini dapat terjadi ketika ruang yang digunakan meningkat dan data kemudian dihapus. Hal ini dikarenakan ruang file yang dialokasikan tidak diklaim kembali secara otomatis ketika data dihapus.
Memantau penggunaan ruang file dan menyusutkan file data mungkin diperlukan dalam skenario berikut:
- Memungkinkan pertumbuhan data dalam kumpulan elastis saat ruang file yang dialokasikan untuk databasenya mencapai ukuran kumpulan maksimum.
- Izinkan penurunan ukuran maksimum database tunggal atau kumpulan elastis.
- Izinkan mengubah database tunggal atau kumpulan elastis ke tingkat layanan atau tingkat performa yang berbeda dengan ukuran maksimal yang lebih rendah.
Catatan
Operasi penyusutan tidak boleh dianggap sebagai operasi pemeliharaan rutin. File data dan log yang bertambah karena operasi bisnis yang teratur dan berulang tidak memerlukan operasi penyusutan.
Memantau penggunaan ruang file
Sebagian besar metrik ruang penyimpanan ditampilkan di API berikut ini hanya mengukur ukuran halaman data yang digunakan:
- API metrik yang berbasis pada Azure Resource Manager termasuk PowerShell get-metrics
Namun, API berikut juga mengukur ukuran ruang yang dialokasikan untuk database dan kumpulan elastis:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
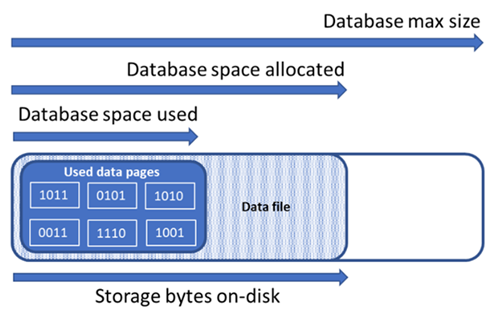
Memahami jenis ruang penyimpanan untuk database
Memahami jumlah ruang penyimpanan berikut ini penting untuk mengelola ruang file database.
| Jumlah database | Definisi | Komentar |
|---|---|---|
| Ruang data yang digunakan | Jumlah ruang yang digunakan untuk menyimpan data database. | Umumnya, ruang yang digunakan meningkat (berkurang) saat memasukkan (menghapus) data. Dalam beberapa kasus, ruang yang digunakan tidak berubah pada sisipan atau penghapusan tergantung pada jumlah dan pola data yang terlibat dalam operasi dan setiap fragmentasi. Misalnya, menghapus satu baris dari setiap halaman data tidak selalu mengurangi ruang yang digunakan. |
| Ruang data dialokasikan | Jumlah ruang file yang diformat disediakan untuk menyimpan data database. | Jumlah ruang yang dialokasikan tumbuh secara otomatis, tetapi tidak pernah berkurang setelah penghapusan. Perilaku ini memastikan bahwa penyisipan di masa depan lebih cepat karena ruang yang sudah diformat tidak perlu diubah lagi. |
| Ruang data dialokasikan tetapi tidak digunakan | Perbedaan antara jumlah ruang data yang dialokasikan dan ruang data yang digunakan. | Kuantitas ini menunjukkan jumlah maksimum ruang kosong yang dapat direklamasi dengan menyusutkan file data database. |
| Ukuran data maksimal | Jumlah ruang maksimum yang dapat digunakan untuk menyimpan data database. | Jumlah ruang data yang dialokasikan tidak dapat tumbuh melebihi ukuran maksimal data. |
Diagram berikut ini mengilustrasikan hubungan antara berbagai jenis ruang penyimpanan untuk database.
Mengkueri database tunggal untuk informasi ruang file
Gunakan kueri berikut pada sys.database_files untuk mengembalikan jumlah ruang file database yang dialokasikan dan jumlah ruang yang tidak digunakan yang dialokasikan. Unit hasil kueri adalah dalam MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Memahami jenis ruang penyimpanan untuk kumpulan elastis
Memahami jumlah ruang penyimpanan berikut ini penting untuk mengelola ruang file kumpulan elastis.
| Kuantitas kumpulan elastis | Definisi | Komentar |
|---|---|---|
| Ruang data yang digunakan | Penjumlahan ruang data yang digunakan oleh semua database dalam kumpulan elastis. | |
| Ruang data dialokasikan | Penjumlahan ruang data yang dialokasikan oleh semua database dalam kumpulan elastis. | |
| Ruang data dialokasikan tetapi tidak digunakan | Perbedaan antara jumlah ruang data yang dialokasikan dan ruang data yang digunakan oleh semua database dalam kumpulan elastis. | Kuantitas ini menunjukkan jumlah ruang maksimum yang dialokasikan untuk kumpulan elastis yang dapat direklamasi dengan menyusutkan file data database. |
| Ukuran data maksimal | Jumlah maksimum ruang data yang digunakan oleh pool elastis untuk semua basis datanya. | Ruang yang dialokasikan untuk kumpulan elastis tidak boleh melebihi ukuran maksimum kumpulan elastis. Jika kondisi ini terjadi, maka ruang yang dialokasikan yang tidak digunakan dapat direklamasi dengan menyusutkan file data database. |
Catatan
Pesan kesalahan "Kumpulan elastis telah mencapai batas penyimpanannya" menunjukkan bahwa objek database menggunakan ruang yang cukup untuk memenuhi batas penyimpanan kumpulan elastis. Pertimbangkan untuk meningkatkan batas penyimpanan, atau sebagai solusi jangka pendek, mengosongkan ruang data menggunakan sampel di Merebut kembali ruang yang dialokasikan yang tidak digunakan. Anda juga harus mengetahui potensi dampak performa negatif dari penyusutan file database. Lihat pemeliharaan Indeks setelah menyusutkan.
Mengkueri kumpulan elastis untuk informasi ruang penyimpanan
Kueri berikut dapat digunakan untuk menentukan jumlah ruang penyimpanan untuk kumpulan elastis.
Ruang data kumpulan elastis yang digunakan
Ubah kueri berikut untuk mengembalikan jumlah ruang data kumpulan elastis yang digunakan. Unit hasil kueri adalah dalam MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Ruang data kumpulan elastis yang dialokasikan dan ruang dialokasikan yang tidak terpakai
Ubah contoh berikut untuk mengembalikan tabel yang mencantumkan total ruang yang dialokasikan dan ruang yang tidak digunakan untuk setiap database dalam kumpulan elastis. Tabel mengurutkan database berdasarkan jumlah ruang yang tidak digunakan, dari yang terbesar ke yang terkecil. Unit hasil kueri adalah dalam MB.
Tambahkan hasil kueri untuk setiap database di kumpulan untuk menentukan total ruang yang dialokasikan untuk kumpulan elastis. Ruang yang dialokasikan untuk kumpulan elastis tidak boleh melebihi ukuran maksimum kumpulan elastis.
Penting
Modul PowerShell Azure Resource Manager (AzureRM) tidak digunakan lagi pada 29 Februari 2024. Semua pengembangan di masa mendatang harus menggunakan modul Az.Sql. Pengguna disarankan untuk bermigrasi dari AzureRM ke modul Az PowerShell untuk memastikan dukungan dan pembaruan yang berkelanjutan. Modul AzureRM tidak lagi dipertahankan atau didukung. Argumen untuk perintah dalam modul Az PowerShell dan dalam modul AzureRM secara substansial identik. Untuk informasi selengkapnya tentang kompatibilitasnya, lihat Memperkenalkan modul Az PowerShell baru.
Skrip PowerShell memerlukan modul PowerShell SQL Server. Untuk informasi selengkapnya, lihat modul PowerShell SQL Server.
Skrip PowerShell berikut menyelesaikan langkah-langkah berikut:
- Deklarasikan variabel. Ganti nilai-nilai ini dengan nilai Anda.
- Dapatkan daftar database di pool elastis.
- Untuk setiap database di kumpulan elastis, dapatkan total ruang yang dialokasikan dalam MB dan ruang yang dialokasikan namun tidak terpakai dalam MB.
- Tampilkan database dalam urutan turun dari ruang yang dialokasikan yang tidak digunakan.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get the total allocated space in MB and the allocated but unused space in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of unused allocated space
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Cuplikan layar berikut adalah contoh output skrip:

Ukuran maksimum data kumpulan elastis
Ubah kueri T-SQL berikut untuk mengembalikan ukuran maksimal data kumpulan elastis yang terakhir direkam. Unit hasil kueri adalah dalam MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Klaim kembali ruang yang dialokasikan dan tidak digunakan
Penting
Perintah penyusutan berdampak pada performa database saat berjalan, dan jika memungkinkan harus dijalankan selama periode penggunaan rendah.
Menyusutkan file data
Azure SQL Database tidak secara otomatis menyusutkan file data karena mungkin berdampak pada performa database. Namun, pelanggan dapat mengecilkan ukuran file data melalui layanan mandiri pada waktu yang mereka tentukan. Penyusutan tidak boleh menjadi operasi yang dijadwalkan secara teratur, melainkan, sebuah acara tunggal sebagai respons terhadap pengurangan besar dalam penggunaan ruang file data.
Tip
Jangan buang waktu menyusutkan file data jika beban kerja aplikasi reguler menyebabkan file tumbuh ke ukuran yang sama yang dialokasikan lagi. Peristiwa pertumbuhan file dapat berdampak negatif pada performa aplikasi.
Di Azure SQL Database, untuk menyusutkan file, Anda dapat menggunakan perintah DBCC SHRINKDATABASE atau DBCC SHRINKFILE:
-
DBCC SHRINKDATABASEmenyusutkan semua data dan file log dalam database menggunakan satu perintah. Perintah ini akan menyusutkan satu file data dalam satu waktu, yang dapat memakan waktu lama untuk database yang lebih besar. Perintah ini juga menyusutkan file log, yang biasanya tidak diperlukan karena Azure SQL Database menyusutkan file log secara otomatis jika diperlukan. -
DBCC SHRINKFILEperintah mendukung skenario yang lebih canggih:- Fungsi ini dapat memproses file individual sesuai kebutuhan, bukan mengurangi ukuran semua file dalam database.
- Setiap perintah
DBCC SHRINKFILEdapat berjalan secara paralel dengan perintahDBCC SHRINKFILEyang lainnya untuk menyusutkan beberapa file dalam satu waktu dan mengurangi jumlah waktu penyusutan, dengan mengorbankan penggunaan sumber daya yang lebih tinggi dan peluang yang lebih tinggi untuk memblokir kueri pengguna, jika pengguna melakukan eksekusi selama penyusutan.- Menyusutkan beberapa file data secara bersamaan memungkinkan Anda menyelesaikan operasi penyusutan lebih cepat. Jika Anda menggunakan pengurangan file data secara bersamaan, Anda mungkin mengamati terjadinya pemblokiran sementara dari satu permintaan pengurangan oleh permintaan lainnya.
- Jika ekor file tidak berisi data, file dapat mengurangi ukuran file yang dialokasikan lebih cepat dengan menentukan argumen
TRUNCATEONLY.TRUNCATEONLYtidak memerlukan pergerakan data dalam file.
- Untuk informasi lebih lanjut terkait perintah penyusutan ini, lihat DBCC SHRINKDATABASE dan DBCC SHRINKFILE.
Contoh berikut harus dijalankan saat tersambung ke database pengguna target, bukan database master.
Untuk menggunakan DBCC SHRINKDATABASE guna menyusutkan semua file data dan file log dalam database yang diberikan:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Di Azure SQL Database, database mungkin memiliki satu atau beberapa file data, yang dibuat secara otomatis saat data bertambah. Untuk menentukan tata letak file database Anda, termasuk ukuran yang digunakan dan dialokasikan dari setiap file, kueri tampilan katalog sys.database_files menggunakan skrip sampel berikut:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Anda dapat menjalankan penyusutan hanya terhadap satu file melalui perintah DBCC SHRINKFILE, misalnya:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Waspadai potensi dampak performa negatif dari menyusutnya file database. Untuk informasi selengkapnya, lihat pemeliharaan Indeks setelah menyusutkan.
Mengurangi ukuran file log transaksi
Tidak seperti file data, Azure SQL Database secara otomatis menyusutkan file log transaksi untuk menghindari penggunaan ruang berlebihan yang dapat menyebabkan kesalahan kehabisan ruang. Dalam kebanyakan kasus, Anda tidak perlu menyusutkan file log transaksi.
Di tingkat layanan Premium dan Bisnis Penting, jika log transaksi menjadi besar, mungkin secara signifikan berkontribusi pada konsumsi penyimpanan lokal menuju batas penyimpanan lokal maksimum. Jika konsumsi penyimpanan lokal mendekati batas, pelanggan mungkin memilih untuk menyusutkan log transaksi menggunakan perintah DBCC SHRINKFILE seperti yang ditunjukkan dalam contoh berikut. Ini melepaskan penyimpanan lokal segera setelah perintah selesai, tanpa menunggu operasi penyusutan otomatis berkala.
Contoh berikut harus dijalankan saat tersambung ke database pengguna target, bukan master database.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Penyusutan otomatis
Sebagai alternatif dari menyusutkan file data secara manual, penyusutan otomatis dapat diaktifkan untuk database. Namun, penyusutan otomatis dapat kurang efektif dalam mereklamasi ruang file daripada DBCC SHRINKDATABASE dan DBCC SHRINKFILE.
Secara default, penyusutan otomatis dinonaktifkan seperti yang direkomendasikan untuk sebagian besar database. Jika perlu mengaktifkan penyusutan otomatis, disarankan untuk menonaktifkannya setelah tujuan manajemen ruang tercapai, alih-alih mengaktifkannya secara permanen. Untuk informasi selengkapnya, lihat Pertimbangan untuk AUTO_SHRINK.
Misalnya, penyusutan otomatis dapat membantu jika kumpulan elastis berisi banyak database yang mengalami pertumbuhan dan pengurangan ruang yang digunakan yang signifikan, menyebabkan kumpulan mendekati batas ukuran maksimumnya. Skenario ini tidak umum.
Untuk mengaktifkan penyusutan otomatis, jalankan perintah berikut saat tersambung ke database Anda (bukan master database).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Untuk informasi selengkapnya tentang perintah ini, lihat opsi DATABASE SET.
Pemeliharaan indeks setelah penyusutan
Setelah operasi penyusutan selesai terhadap file data, indeks mungkin menjadi terfragmentasi. Fragmentasi mengurangi throughput I/O baca untuk beban kerja tertentu, seperti kueri yang menggunakan pemindaian berskala besar. Jika penurunan performa terjadi setelah operasi penyusutan selesai, pertimbangkan pemeliharaan indeks untuk membangun kembali indeks. Perlu diingat bahwa pembangunan ulang indeks memerlukan ruang kosong dalam database, dan karenanya dapat menyebabkan ruang yang dialokasikan meningkat, menangkal efek penyusutan.
Untuk informasi lebih lanjut terkait pemeliharaan indeks, lihat Mengoptimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya.
Menyusutkan database besar
Ketika ruang yang dialokasikan database dalam ratusan gigabyte atau lebih tinggi, penyusutan mungkin memerlukan waktu yang signifikan untuk diselesaikan, sering diukur dalam jam, atau hari untuk database multi-terabyte. Terdapat optimisasi proses dan praktik terbaik yang dapat Anda gunakan untuk membuat proses ini lebih efisien dan tidak berpengaruh ke beban kerja aplikasi.
Merekam garis besar penggunaan ruang
Sebelum memulai penyusutan, rekam ruang yang saat ini digunakan dan dialokasikan dalam setiap file database dengan menjalankan kueri penggunaan ruang berikut:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Setelah penyusutan telah selesai, Anda dapat menjalankan lagi kueri ini dan membandingkan hasilnya dengan garis besar awal.
Memangkas file data
Disarankan untuk menjalankan penyusutan terlebih dahulu untuk setiap file data dengan parameter TRUNCATEONLY. Dengan cara ini, jika ada ruang yang dialokasikan tetapi tidak digunakan di akhir file, itu dihapus dengan cepat dan tanpa pergerakan data. Contoh perintah berikut ini memotong file data dengan file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Setelah perintah ini dijalankan untuk setiap file data, Anda dapat menjalankan kembali kueri penggunaan ruang untuk melihat pengurangan dalam ruang yang dialokasikan, jika ada. Anda juga dapat menampilkan ruang yang dialokasikan untuk database di portal Microsoft Azure.
Mengevaluasi kerapatan halaman indeks
Jika memotong file data tidak menghasilkan pengurangan ruang yang cukup, Anda perlu menyusutkan file data. Namun, sebagai langkah opsional tetapi disarankan, Anda harus menentukan rata-rata kerapatan halaman untuk indeks dalam database terlebih dahulu. Untuk jumlah data yang sama, operasi penyusutan selesai lebih cepat jika kepadatan halaman tinggi, karena harus memindahkan lebih sedikit halaman. Jika kerapatan halaman rendah untuk beberapa indeks, pertimbangkan untuk melakukan pemeliharaan pada indeks ini guna meningkatkan kepadatan halaman sebelum menyusutkan file data. Kepadatan halaman yang lebih tinggi memungkinkan proses penyusutan mencapai pengurangan ruang penyimpanan yang dialokasikan lebih signifikan.
Untuk menentukan kerapatan halaman untuk semua indeks dalam database, gunakan kueri berikut. Kerapatan halaman dilaporkan dalam kolom avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Jika ada indeks dengan jumlah halaman tinggi yang memiliki kerapatan halaman yang lebih rendah dari 60-70%, pertimbangkan untuk menyusun ulang atau menata ulang indeks ini sebelum menyusutkan file data.
Untuk database yang lebih besar, kueri untuk menentukan kepadatan halaman mungkin membutuhkan waktu lama untuk diselesaikan. Membangun kembali atau mengatur ulang indeks besar juga memerlukan waktu dan penggunaan sumber daya yang substansial. Namun, pemeliharaan indeks sebelum menyusut dapat mengurangi durasi penyusutan dan mencapai penghematan ruang yang lebih tinggi.
Jika ada beberapa indeks dengan kepadatan halaman rendah, Anda mungkin dapat membangunnya kembali secara paralel pada beberapa sesi database untuk mempercepat proses. Namun, pastikan Anda tidak mendekati batas sumber daya database dengan melakukannya. Pastikan ada ruang lingkup sumber daya yang cukup untuk beban kerja aplikasi yang mungkin berjalan. Pantau konsumsi sumber daya (CPU, IO Data, Log IO) di portal Microsoft Azure atau menggunakan tampilan sys.dm_db_resource_stats. Mulai pembangunan kembali paralel tambahan hanya jika pemanfaatan sumber daya pada masing-masing dimensi ini tetap jauh lebih rendah dari 100%. Jika penggunaan CPU, Data IO, atau Log IO adalah 100%, Anda dapat meningkatkan skala database agar memiliki lebih banyak inti CPU dan meningkatkan throughput IO.
Contoh perintah pembangunan ulang indeks
Berikut ini adalah contoh perintah untuk membangun kembali indeks dan meningkatkan kepadatan halamannya, menggunakan pernyataan ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Perintah ini memulai penyusunan ulang indeks yang dapat dilanjutkan dan bersifat online. Operasi ini memungkinkan beban kerja bersamaan terus menggunakan tabel saat rekonstruksi sedang berlangsung, dan memungkinkan Anda melanjutkan rekonstruksi jika ada gangguan karena alasan apa pun. Namun, jenis penyusunan ulang ini lebih lambat daripada menyusun ulang secara offline, yang memblokir akses ke tabel. Jika tidak ada beban kerja lain yang perlu mengakses tabel selama penyusunan ulang, atur opsi ONLINE dan RESUMABLE ke OFF serta hapus klausul WAIT_AT_LOW_PRIORITY.
Untuk informasi lebih lanjut terkait pemeliharaan indeks, lihat Mengoptimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya.
Kompres data LOB sebelum pengurangan ukuran
Penyusutan dapat memakan waktu lebih lama jika database berisi:
- Jenis data LOB seperti varchar(max), nvarchar(max), varbinary(max), xml, atau jenis data serupa yang disimpan di
LOB_DATAunit alokasi. -
Baris besar disimpan dalam
ROW_OVERFLOW_DATAunit alokasi. - Indeks penyimpanan kolom.
Untuk membuat penyusutan berjalan lebih cepat dan melepaskan lebih banyak ruang, selesaikan reorganisasi indeks dengan pemadatan LOB terlebih dahulu. Pemadatan LOB sebelum penyusutan direkomendasikan untuk semua indeks yang berisi kolom LOB atau baris besar. Contohnya:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REORGANIZE WITH (LOB_COMPACTION = ON);
Mengatur ulang atau membangun kembali indeks penyimpan kolom sebelum penyusutan juga dapat meningkatkan kecepatan dan efektivitas penyusutan.
Memperkecil beberapa berkas data
Seperti yang disebutkan sebelumnya, pengecilan dengan pergerakan data merupakan proses yang memakan waktu lama. Jika database memiliki beberapa file data, Anda dapat mempercepat prosesnya dengan menyusutkan beberapa file data secara paralel. Buka beberapa sesi database, dan gunakan DBCC SHRINKFILE pada setiap sesi dengan nilai yang berbeda file_id . Sama dengan menyusun ulang indeks sebelumnya, pastikan Anda memiliki headroom sumber daya yang memadai (CPU, Data IO, Log IO) sebelum memulai setiap perintah penyusutan paralel baru.
Contoh perintah berikut menyusutkan file data dengan file_id 4, mencoba mengurangi ukuran yang dialokasikan menjadi 52.000 MB dengan memindahkan halaman dalam file:
DBCC SHRINKFILE (4, 52000);
Jika Anda ingin mengurangi ruang yang dialokasikan untuk file ke ukuran paling minimum, jalankan pernyataan tanpa menentukan ukuran target:
DBCC SHRINKFILE (4);
Jika beban kerja tersebut berjalan bersamaan dengan operasi penyusutan, beban kerja tersebut mungkin akan mulai memanfaatkan ruang penyimpanan yang dibebaskan oleh operasi penyusutan sebelum operasi penyusutan selesai dan memotong file. Dalam hal ini, penyusutan tidak dapat mengurangi ruang yang dialokasikan ke target yang ditentukan.
Untuk menghindari masalah ini, susutkan setiap file dalam langkah yang lebih kecil.
DBCC SHRINKFILE Dalam perintah , atur target yang sedikit lebih kecil dari ruang yang dialokasikan saat ini untuk file, seperti yang terlihat dalam hasil kueri penggunaan ruang dasar. Misalnya, jika ruang yang dialokasikan untuk file dengan file_id 4 adalah 200.000 MB, dan Anda ingin menyusutkannya menjadi 100.000 MB, Anda dapat terlebih dahulu menetapkan target ke 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Perintah ini memotong file dan mengurangi ukuran yang dialokasikan menjadi 170.000 MB. Anda kemudian dapat mengulangi perintah ini, mengatur target terlebih dahulu ke 140.000 MB, lalu ke 110.000 MB, dan sebagainya, sampai file diciutkan ke ukuran yang diinginkan. Jika perintah selesai tetapi file tidak terpotong, gunakan langkah-langkah yang lebih kecil, misalnya 15.000 MB daripada 30.000 MB.
Untuk memantau kemajuan penyusutan untuk semua sesi penyusutan yang berjalan bersamaan, Anda dapat menggunakan kueri berikut:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Catatan
Kemajuan penyusutan bisa nonlinear, dan nilai di kolom percent_complete mungkin tetap tidak berubah untuk jangka waktu yang lama, meskipun penyusutan masih berlangsung.
Setelah penyusutan selesai untuk semua file data, jalankan ulang kueri penggunaan ruang (atau periksa di portal Microsoft Azure) untuk menentukan pengurangan yang dihasilkan dalam ukuran penyimpanan yang dialokasikan. Jika masih ada perbedaan besar antara ruang yang digunakan dan ruang yang dialokasikan, membangun kembali indeks. Pembangunan kembali indeks dapat meningkatkan ruang yang dialokasikan lebih lanjut untuk sementara. Namun, menyusutkan file data lagi setelah membangun kembali indeks akan mengakibatkan pengurangan ruang yang lebih dalam.
Kesalahan sementara selama pengurangan
Terkadang, perintah penyusutan dapat gagal dengan berbagai kesalahan seperti waktu habis dan kebuntuan. Secara umum, kesalahan ini hanya sementara, dan tidak terjadi lagi jika perintah yang sama diulang. Jika proses pengecilan menghasilkan kesalahan, kemajuan sejauh ini tetap dipertahankan. Jalankan perintah penyusutan yang sama lagi untuk terus menyusutkan file.
Contoh skrip berikut menunjukkan bagaimana Anda dapat menjalankan pengurangan dalam pengulangan percobaan. Perulangan secara otomatis mencoba kembali operasi hingga beberapa kali yang dapat dikonfigurasi ketika kesalahan waktu habis atau kesalahan kebuntuan terjadi. Pendekatan coba lagi ini berlaku untuk banyak kesalahan lain yang mungkin terjadi selama pengecilan.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Selain batas waktu dan deadlock, proses pengecilan mungkin mengalami kesalahan akibat beberapa masalah yang sudah diketahui.
Berikut adalah kesalahan yang ditampilkan dan langkah mitigasinya:
- Nomor kesalahan: 49503, pesan kesalahan: %.*ls: Halaman %d:%d tidak dapat dipindahkan karena halaman tersebut adalah halaman penyimpanan versi persisten luar baris. Alasan penahanan halaman: %ls. Stempel waktu penahanan halaman: %I64d.
Kesalahan ini terjadi ketika ada transaksi aktif jangka panjang yang menghasilkan versi baris di penyimpanan versi persisten (PVS). Susutkan tidak dapat memindahkan halaman yang berisi versi baris.
Untuk mengurangi, Anda harus menunggu hingga transaksi jangka panjang selesai. Atau, Anda dapat mengidentifikasi dan mengakhiri transaksi jangka panjang, tetapi ini dapat memengaruhi aplikasi Anda jika tidak menangani kegagalan transaksi dengan anggun. Salah satu cara untuk menemukan transaksi yang berjalan lama adalah dengan menjalankan kueri berikut dalam database tempat Anda menjalankan perintah penyusutan:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Anda dapat mengakhiri transaksi menggunakan perintah KILL dan menentukan nilai session_id terkait dari hasil kueri:
KILL 4242; -- replace 4242 with the session_id value from query results
Perhatian
Mengakhiri transaksi dapat berdampak negatif pada beban kerja.
Setelah transaksi yang berlangsung lama selesai, tugas latar belakang internal kemudian membersihkan versi baris yang sudah tidak diperlukan lagi. Anda dapat memantau ukuran PVS untuk mengukur kemajuan pembersihan, menggunakan kueri berikut. Jalankan kueri dalam database tempat Anda menjalankan perintah penyusutan:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Setelah ukuran PVS yang dilaporkan dalam kolom persistent_version_store_size_gb berkurang secara signifikan dibandingkan dengan ukuran aslinya, menjalankan kembali perintah pengecilan seharusnya berhasil.
- Nomor kesalahan: 5223, pesan kesalahan: %.*ls: Halaman kosong %d:%d tidak dapat dialokasi.
Kesalahan ini dapat terjadi jika ada operasi pemeliharaan indeks yang sedang berlangsung seperti ALTER INDEX. Coba lagi perintah penyusutan setelah operasi ini selesai.
Jika kesalahan ini tetap ada, indeks yang terkait mungkin harus disusun ulang. Untuk menemukan indeks yang akan disusun ulang, jalankan kueri berikut ini dalam database yang sama tempat Anda menjalankan perintah penyusutan:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Sebelum menjalankan kueri ini, ganti placeholder <file_id> dan <page_id> dengan nilai sebenarnya dari pesan kesalahan yang Anda dapatkan. Misalnya, jika pesan berisi Halaman kosong 1:62669 tidak dapat dialokasi, maka <file_id> adalah 1 dan <page_id> adalah 62669.
Susun ulang indeks yang diidentifikasi oleh kueri, lalu coba lagi perintah penyusutan.
- Nomor kesalahan: 5201, pesan kesalahan: DBCC SHRINKDATABASE: ID File %d dari ID database %d telah dilewati karena file tidak memiliki cukup ruang kosong untuk mengklaim kembali.
Kesalahan ini berarti file data tidak dapat menyusut lebih lanjut. Anda dapat melanjutkan ke file data berikutnya.
Konten terkait
Untuk informasi tentang ukuran maksimal database, lihat:
- Batas model pembelian berbasis vCore Azure SQL Database untuk satu database
- Batas sumber daya untuk database tunggal menggunakan model pembelian berbasis DTU
- Batas model pembelian berbasis vCore Azure SQL Database untuk kumpulan elastis
- Batas sumber daya untuk kumpulan elastis menggunakan model pembelian berbasis DTU