Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database![]() Database SQL di Fabric
Database SQL di Fabric
Artikel ini menjelaskan arsitektur Azure SQL Database dan database SQL di Fabric yang mencapai ketersediaan melalui redundansi lokal, dan ketersediaan tinggi melalui redundansi zona.
Overview
Azure SQL Database dan database SQL di Fabric keduanya berjalan pada versi stabil terbaru SQL Server Database Engine pada sistem operasi Windows dengan semua patch yang berlaku. SQL Database secara otomatis menangani tugas layanan penting, seperti patching, pencadangan, peningkatan mesin Windows dan SQL, dan peristiwa yang tidak diencana seperti perangkat keras, perangkat lunak, atau kegagalan jaringan yang mendasarinya. Saat database atau kumpulan elastis di SQL Database diperbarui atau mengalami kegagalan, waktu henti tidak berdampak jika Anda menggunakan logika coba lagi di aplikasi Anda. SQL Database dapat dengan cepat pulih bahkan dalam keadaan paling penting, memastikan bahwa data Anda selalu tersedia. Sebagian besar pengguna tidak melihat bahwa peningkatan dilakukan terus menerus.
Secara default, Azure SQL Database mencapai ketersediaan melalui redundansi lokal, memastikan database Anda menangani gangguan seperti:
- Operasi manajemen yang dilakukan oleh pelanggan yang mengakibatkan gangguan singkat.
- Operasi pemeliharaan layanan
- Masalah dengan:
- rak tempat mesin yang mendukung layanan Anda berjalan
- komputer fisik yang menghosting mesin database SQL
- Masalah lain dengan mesin database SQL
- Potensi pemadaman lokal yang tidak direncanakan
Solusi ketersediaan default dirancang untuk memastikan bahwa data yang diterapkan tidak pernah hilang karena kegagalan, bahwa operasi pemeliharaan memiliki dampak minimal pada beban kerja Anda, dan bahwa database bukan satu titik kegagalan dalam arsitektur perangkat lunak Anda.
Namun, untuk meminimalkan dampak pada data Anda jika terjadi pemadaman ke seluruh zona, Anda dapat mencapai ketersediaan tinggi dengan mengaktifkan redundansi zona. Tanpa redundansi zona, failover terjadi secara lokal di dalam pusat data yang sama, yang mungkin mengakibatkan database Anda tidak tersedia sampai pemadaman diselesaikan - satu-satunya cara untuk memulihkan adalah melalui solusi pemulihan bencana, seperti failover geografis melalui geo-replikasi aktif, grup failover, atau pemulihan geo dari cadangan geo-redundan. Untuk mempelajari lebih lanjut, tinjau gambaran umum kelangsungan bisnis.
Ada tiga model arsitektur ketersediaan:
- Model penyimpanan jarak jauh yang didasarkan pada pemisahan komputasi dan penyimpanan. Model penyimpanan jarak jauh bergantung pada ketersediaan dan keandalan tingkat penyimpanan jarak jauh. Arsitektur ini menargetkan aplikasi bisnis berorientasi anggaran yang dapat menoleransi beberapa penurunan performa selama aktivitas pemeliharaan.
- Model penyimpanan lokal yang didasarkan pada kluster proses mesin database. Model penyimpanan lokal bergantung pada fakta bahwa selalu ada kuorum simpul mesin database yang tersedia. Arsitektur ini menargetkan aplikasi penting misi dengan performa IO tinggi, tingkat transaksi tinggi, dan menjamin dampak performa minimal pada beban kerja Anda selama aktivitas pemeliharaan.
- Model Hyperscale yang menggunakan sistem terdistribusi dari komponen yang sangat tersedia seperti simpul komputasi, server halaman, layanan log, dan penyimpanan persisten. Setiap komponen yang mendukung database Hyperscale memberikan redundansi dan ketahanannya sendiri terhadap kegagalan. Simpul komputasi, layanan server halaman, dan layanan log berjalan di Azure Service Fabric, yang mengontrol kesehatan setiap komponen dan melakukan failover ke simpul sehat yang tersedia jika diperlukan. Penyimpanan persisten menggunakan Azure Storage dengan kemampuan ketersediaan tinggi dan redundansi aslinya. Untuk mempelajari lebih lanjut, lihat Arsitektur Hyperscale.
Dalam masing-masing dari tiga model ketersediaan, SQL Database mendukung opsi redundansi lokal dan redundansi zona. Redundansi lokal memberikan ketahanan dalam pusat data, sementara redundansi zona meningkatkan ketahanan lebih lanjut dengan melindungi dari pemadaman zona ketersediaan dalam suatu wilayah.
Tabel berikut ini memperlihatkan opsi ketersediaan berdasarkan tingkat layanan:
| Tingkat layanan | Model ketersediaan tinggi | Ketersediaan berlebihan lokal | Ketersediaan yang redundan antar zona |
|---|---|---|---|
| Tujuan Umum (vCore) | Penyimpanan jarak jauh | Yes | Yes |
| Kritis Bisnis (vCore) | Penyimpanan lokal | Yes | Yes |
| Hyperscale (vCore) | Hyperscale | Yes | Yes |
| Dasar (DTU) | Penyimpanan jarak jauh | Yes | No |
| Standar (DTU) | Penyimpanan jarak jauh | Yes | No |
| Premium (DTU) | Penyimpanan lokal | Yes | Yes |
Untuk informasi selengkapnya mengenai SLA tertentu untuk tingkat layanan yang berbeda, tinjau SLA untuk Azure SQL Database.
Ketersediaan melalui redundansi lokal
Ketersediaan redundan lokal didasarkan pada penyimpanan database Anda ke penyimpanan redundan lokal (LRS) yang menyalin data Anda tiga kali dalam satu pusat data di wilayah utama dan melindungi data Anda jika terjadi kegagalan lokal, seperti jaringan skala kecil atau kegagalan daya. LRS adalah opsi redundansi berbiaya terendah dan menawarkan durabilitas paling rendah dibandingkan dengan opsi lain. Jika bencana skala besar seperti kebakaran atau banjir terjadi dalam suatu wilayah, semua replika akun penyimpanan yang menggunakan LRS mungkin hilang atau tidak dapat dipulihkan. Dengan demikian, untuk melindungi data Anda lebih lanjut saat menggunakan opsi ketersediaan redundan secara lokal, pertimbangkan untuk menggunakan opsi penyimpanan yang lebih tangguh untuk cadangan database Anda. Ini tidak berlaku untuk database Hyperscale, di mana penyimpanan yang sama digunakan untuk file data dan cadangan.
Ketersediaan redundan lokal tersedia untuk semua database di semua tingkat layanan dan Tujuan Titik Pemulihan (RPO) yang menunjukkan jumlah kehilangan data adalah nol.
Tingkat layanan Dasar, Standar, dan Tujuan Umum
Tingkat layanan Dasar, dan Standar dari gambaran umum model pembelian berbasis DTU, dan tingkat layanan Tujuan Umum dari model pembelian berbasis vCore menggunakan model ketersediaan penyimpanan jarak jauh untuk komputasi tanpa server dan yang disediakan. Diagram berikut menunjukkan simpul dengan lapisan komputasi dan penyimpanan yang dipisahkan.
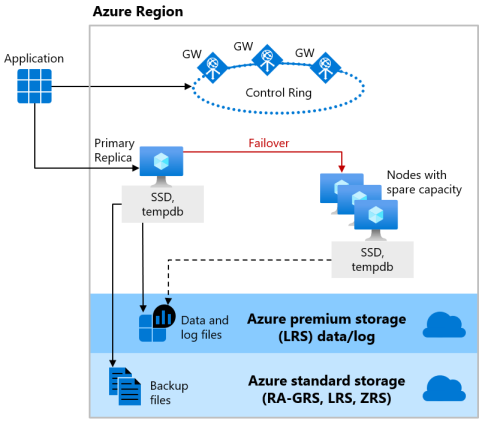
Model ketersediaan penyimpanan jarak jauh mencakup dua lapisan:
Lapisan komputasi tanpa status yang menjalankan proses mesin database dan hanya berisi data sementara dan cache, seperti database
tempdbdanmodelpada SSD yang terpasang, serta cache rencana, pool buffer, dan pool kolom dalam memori. Simpul stateless ini dioperasikan oleh Azure Service Fabric yang menginisialisasi mesin database, mengontrol kesehatan simpul, dan melakukan failover ke simpul lain jika perlu.Lapisan data yang bersifat stateful dengan file database (
.mdfdan.ldf) yang disimpan di Azure Blob Storage. Azure Blob Storage memiliki ketersediaan data bawaan dan fitur redundansi. Ini menjamin bahwa setiap rekaman dalam file log atau halaman dalam file data akan dipertahankan bahkan jika proses mesin database crash.
Setiap kali mesin database atau sistem operasi ditingkatkan, atau kegagalan terdeteksi, Azure Service Fabric memindahkan proses mesin database stateless ke simpul komputasi stateless lain dengan kapasitas bebas yang memadai. Data di penyimpanan Azure Blob tidak terpengaruh oleh pemindahan, dan file data/log dilampirkan ke proses mesin database yang baru diinisialisasi. Proses ini menjamin ketersediaan tinggi, tetapi beban kerja yang berat mungkin mengalami beberapa penurunan performa selama transisi karena proses mesin database baru dimulai dengan cache dingin.
Tingkat layanan Premium dan Bisnis Penting
Tingkat layanan Premium dari model pembelian berbasis DTU dan tingkat layanan Business Critical dari model pembelian berbasis vCore menggunakan model ketersediaan penyimpanan lokal, yang mengintegrasikan sumber daya komputasi (proses mesin database) dan penyimpanan (SSD yang terpasang secara lokal) pada satu simpul. Ketersediaan tinggi dicapai dengan mereplikasi komputasi dan penyimpanan ke simpul tambahan.
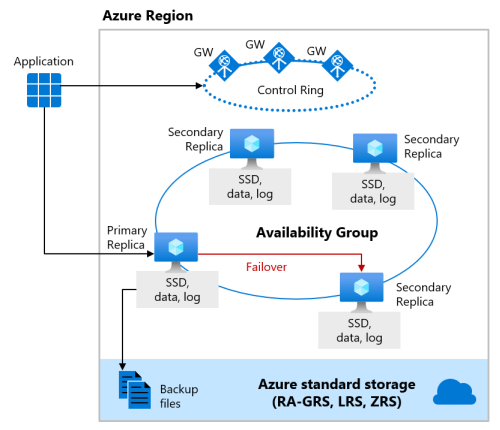
File database utama (file .mdf/.ldf) ditempatkan pada penyimpanan SSD terlampir untuk menyediakan IO dengan latensi sangat rendah bagi beban kerja Anda. Ketersediaan tinggi diimplementasikan menggunakan teknologi yang mirip dengan grup ketersediaan AlwaysOn SQL Server. Kluster ini mencakup satu replika utama yang dapat diakses untuk beban kerja pelanggan baca-tulis, dan hingga tiga replika sekunder (komputasi dan penyimpanan) yang berisi salinan data. Replika utama terus-menerus mendorong perubahan pada replika sekunder secara berurutan dan memastikan bahwa data disimpan pada jumlah replika sekunder yang memadai sebelum melakukan setiap transaksi. Proses ini menjamin bahwa jika replika utama atau replika sekunder yang dapat dibaca mengalami crash karena alasan apa pun, selalu ada replika yang sepenuhnya disinkronkan untuk proses failover. Kegagalan dimulai oleh Azure Service Fabric. Setelah replika sekunder menjadi replika utama baru, replika sekunder lainnya dibuat untuk memastikan kluster memiliki jumlah replika yang memadai untuk mempertahankan kuorum. Setelah failover selesai, koneksi Azure SQL secara otomatis dialihkan ke replika utama baru atau replika sekunder yang dapat dibaca.
Sebagai manfaat tambahan, model ketersediaan penyimpanan lokal mencakup kemampuan untuk mengalihkan koneksi Azure SQL baca-saja ke salah satu replika sekunder. Fitur ini disebut Read Scale-Out. Ini menyediakan 100% kapasitas komputasi tambahan tanpa biaya tambahan untuk memindahkan operasi baca-saja, seperti beban kerja analitik, dari replika utama.
Tingkat layanan Hyperscale
Arsitektur tingkat layanan Hyperscale dijelaskan dalam arsitektur Fungsi terdistribusi, yang memiliki diagram terperinci.
Model ketersediaan di Hyperscale mencakup empat lapisan:
Lapisan komputasi stateless yang menjalankan proses mesin database dan hanya berisi data sementara dan cache, seperti cache RBPEX noncovering,
tempdbdanmodeldatabase, dll. pada SSD yang terpasang, dan merencanakan cache, kumpulan buffer, dan kumpulan penyimpanan kolom dalam memori. Lapisan stateless ini mencakup replika komputasi utama, dan secara opsional sejumlah replika komputasi sekunder, yang dapat berfungsi sebagai target failover.Lapisan penyimpanan nirstatus yang terbentuk oleh server halaman. Lapisan ini adalah mesin penyimpanan terdistribusi untuk proses mesin database yang berjalan pada replika komputasi. Setiap server halaman hanya berisi data sementara dan data yang di-cache, seperti cache RBPEX pada SSD yang dilampirkan, dan halaman data yang disimpan dalam cache di memori. Setiap server halaman memiliki server halaman yang dipasangkan dalam konfigurasi aktif-aktif untuk memberikan keseimbangan beban, redundansi, dan ketersediaan tinggi.
Lapisan penyimpanan log transaksi berstatus yang dibentuk oleh node komputasi yang menjalankan proses layanan Log, zona landasan log transaksi, dan penyimpanan jangka panjang log transaksi. Zona pendaratan dan penyimpanan jangka panjang menggunakan Azure Storage, yang menyediakan ketersediaan dan redundansi untuk log transaksi, memastikan durabilitas data untuk transaksi yang dilakukan.
Lapisan penyimpanan data yang bersifat stateful dengan file database (.mdf/.ndf) yang disimpan di Azure Storage dan diperbarui oleh server halaman. Lapisan ini menggunakan fitur ketersediaan data dan redundansi Azure Storage. Ini menjamin bahwa setiap halaman dalam file data akan dipertahankan bahkan jika proses di lapisan lain dari arsitektur Hyperscale mengalami crash, atau jika node komputasi gagal.
Node komputasi di semua lapisan Hyperscale berjalan pada Azure Service Fabric, yang memantau kesehatan setiap node dan melakukan alih tugas ke node sehat yang tersedia jika diperlukan.
Untuk informasi selengkapnya tentang ketersediaan tinggi di Hyperscale, lihat Ketersediaan Tinggi Database di Hyperscale.
Ketersediaan tinggi melalui redundansi zona
Untuk penyebaran zona-redundan, Azure SQL Database menggunakan jumlah zona ketersediaan Azure di wilayah tertentu, dua atau lebih biasanya tiga. Komponen komputasi dan penyimpanan mencakup dua atau tiga zona, seperti yang dipilih oleh Azure SQL untuk ketahanan optimal, di lokasi fisik terpisah dengan daya, pendinginan, dan jaringan independen. Azure SQL secara otomatis memilih jumlah zona berdasarkan ketersediaan regional dan pengoptimalan layanan. Penyebaran Anda tidak akan menggunakan jumlah zona yang lebih sedikit daripada yang diperlukan untuk ketahanan.
Ketersediaan redundansi zona tersedia untuk database di tingkat layanan Business Critical, General Purpose, dan Hyperscale dari model pembelian berbasis vCore, dan hanya tingkat layanan Premium dari model pembelian berbasis DTU - tingkat layanan Dasar dan Standar tidak mendukung redundansi zona.
Meskipun setiap tingkat layanan menerapkan redundansi zona secara berbeda, semua implementasi memastikan Tujuan Titik Pemulihan (RPO) dengan nol kehilangan data yang telah diterapkan saat terjadinya failover jika satu zona ketersediaan dalam wilayah Azure tidak tersedia.
Azure SQL secara otomatis mengoptimalkan penempatan zona untuk penyebaran Anda. Semua konfigurasi zona ketersediaan, menggunakan dua atau tiga zona, memberikan SLA ketersediaan tinggi dan jaminan ketahanan yang sama.
Tingkat layanan Tujuan Umum
Konfigurasi redundansi antar zona untuk tingkat layanan General Purpose ditawarkan untuk komputasi tanpa server dan komputasi terprovisi pada database dalam model pembelian vCore. Konfigurasi ini menggunakan Zona Ketersediaan Azure untuk mereplikasi database di beberapa lokasi fisik dalam wilayah Azure. Dengan memilih redundansi zona, Anda dapat membuat database tunggal tanpa server dan General Purpose yang diprovisikan, serta kumpulan elastis yang baru dan yang sudah ada, lebih tahan terhadap rentang kegagalan yang jauh lebih besar, termasuk pemadaman pusat data besar-besaran, tanpa perubahan pada logika aplikasi.
Konfigurasi zona-redundan untuk tingkat Tujuan Umum memiliki dua lapisan:
- Lapisan data stateful dengan file database (.mdf/.ldf) yang disimpan di ZRS (penyimpanan zona redundan). Menggunakan ZRS, data dan file log disalin secara sinkron di beberapa zona ketersediaan Azure di wilayah utama. Ini berada di dua atau tiga zona, seperti yang dipilih oleh Azure SQL untuk ketahanan optimal.
- Lapisan komputasi stateless yang menjalankan proses sqlservr.exe dan hanya berisi data sementara dan cache, seperti database
tempdbdanmodelpada SSD terlampir, serta cache rencana, kumpulan buffer, dan kumpulan penyimpanan kolom dalam memori. Node tanpa status ini dioperasikan oleh Azure Service Fabric yang menginisialisasi sqlservr.exe, memantau kesehatan node, dan melakukan pemindahan ke node lain jika diperlukan. Untuk database Keperluan Umum yang tanpa server dan tersediakan dengan redundansi zona, simpul dengan kapasitas cadangan siap tersedia di Zona Ketersediaan lain untuk failover.
Versi zona redundan dari arsitektur ketersediaan tinggi untuk tingkat layanan Tujuan Umum diilustrasikan oleh diagram berikut, baik di wilayah dua zona atau tiga zona:
| Wilayah dua zona | Wilayah tiga zona |
|---|---|

|

|
Saat proses komputasi dipersiapkan di dua zona ketersediaan:
- Pencadangan dan penyimpanan masih disinkronkan di tiga zona ketersediaan di wilayah tersebut.
- Penyimpanan zona redundan, seperti biasa, disinkronkan di tiga zona ketersediaan.
Saat sumber daya komputasi dialokasikan di tiga zona ketersediaan:
- Pencadangan dan penyimpanan disinkronkan di tiga zona ketersediaan di wilayah tersebut.
Semua wilayah Azure yang memiliki dukungan zona Ketersediaan mendukung database Umum yang redundan zona.
Untuk ketersediaan zona redundan, memilih jendela pemeliharaan selain default saat ini tersedia di wilayah tertentu. Untuk informasi selengkapnya, lihat Ketersediaan jendela pemeliharaan menurut wilayah untuk Azure SQL Database.
Redundansi zona tidak tersedia untuk tingkat layanan Dasar dan Standar dalam model pembelian DTU.
Tingkat layanan Premium dan Kritis untuk Bisnis
Ketika Redundansi Zona diaktifkan untuk tingkat layanan Premium atau Bisnis Penting, replika ditempatkan di zona ketersediaan yang berbeda di wilayah yang sama. Untuk menghilangkan titik kegagalan tunggal, ring kontrol juga diduplikasi di beberapa zona menjadi tiga ring gateway (GW). Perutean ke cincin gateway tertentu dikontrol oleh Azure Traffic Manager. Karena konfigurasi zona-redundan di tingkat layanan Premium atau Business Critical menggunakan replika yang ada untuk ditempatkan di zona ketersediaan yang berbeda, Anda dapat mengaktifkannya tanpa biaya tambahan. Dengan memilih konfigurasi zona-redundan, Anda dapat membuat database Premium atau Business Critical dan kumpulan elastis tahan terhadap serangkaian kegagalan yang jauh lebih besar, termasuk pemadaman pusat data bencana, tanpa perubahan apa pun pada logika aplikasi. Anda juga dapat mengonversi database Premium atau Business Critical atau kumpulan elastis yang ada ke konfigurasi zona redundan.
Versi zona redundan dari arsitektur ketersediaan tinggi untuk tingkat layanan Business Critical diilustrasikan oleh diagram berikut, baik di wilayah dua zona atau tiga zona:
| Wilayah dua zona | Wilayah tiga zona |
|---|---|

|

|
Saat sumber daya komputasi dialokasikan di dua zona ketersediaan:
- Untuk penyimpanan Bisnis Penting, penyimpanan ketersediaan redundan secara lokal untuk data dan file log disinkronkan di dua zona ketersediaan.
- Untuk tingkatan lainnya, pencadangan dan penyimpanan disinkronkan di tiga zona ketersediaan di wilayah tersebut.
- Penyimpanan zona redundan, seperti biasa, disinkronkan di tiga zona ketersediaan.
Saat sumber daya komputasi diatur di tiga zona ketersediaan:
- Untuk penyimpanan Bisnis Penting, penyimpanan ketersediaan redundan lokal untuk data dan file log disinkronkan di tiga zona ketersediaan.
- Untuk lapis lainnya, pencadangan dan penyimpanan disinkronkan di tiga zona ketersediaan di wilayah tersebut.
Pertimbangkan hal berikut saat mengonfigurasi database Premium atau Bisnis Penting Anda dengan redundansi zona:
- Semua wilayah Azure yang memiliki dukungan zona Ketersediaan mendukung database zona redundan Premium dan Kritis Bisnis.
- Untuk ketersediaan zona redundan, memilih jendela pemeliharaan selain default saat ini tersedia di wilayah tertentu. Untuk informasi selengkapnya, lihat Ketersediaan jendela pemeliharaan menurut wilayah untuk Azure SQL Database.
Tingkat layanan Hyperscale
Dimungkinkan untuk mengonfigurasi redundansi zona untuk database di tingkat layanan Hyperscale. Untuk mempelajari lebih lanjut, tinjau Membuat database zona-redundan Hyperscale.
Aktivasi konfigurasi ini memastikan ketahanan tingkat zona melalui replikasi di seluruh Zona Ketersediaan untuk semua lapisan Hyperscale. Dengan memilih zona-redundansi, Anda dapat membuat database Hyperscale Anda tahan terhadap serangkaian kegagalan yang jauh lebih besar, termasuk pemadaman pusat data yang fatal, tanpa perubahan apa pun pada logika aplikasi.
Dukungan ketersediaan redundansi zona terdapat pada database Hyperscale yang berdiri sendiri dan juga pada kumpulan elastis Hyperscale. Untuk informasi selengkapnya, lihat Gambaran umum kumpulan elastis Hyperscale di Azure SQL Database.
Diagram berikut mendemonstrasikan infrastruktur mendasari untuk database Hyperscale yang memiliki redundansi zona, baik dalam konfigurasi dua zona maupun tiga zona.
| Wilayah dua zona | Wilayah tiga zona |
|---|---|

|

|
Saat sumber daya komputasi disediakan di dua zona ketersediaan:
- Pencadangan dan penyimpanan disinkronkan di tiga zona ketersediaan di wilayah tersebut.
- Penyimpanan zona redundan, seperti biasa, disinkronkan di tiga zona ketersediaan.
Ketika sumber daya komputasi disediakan di seluruh tiga zona ketersediaan:
- Pencadangan dan penyimpanan disinkronkan di tiga zona ketersediaan di wilayah tersebut.
Pertimbangkan batasan berikut:
Semua wilayah Azure yang memiliki dukungan zona Ketersediaan, mendukung database Hyperscale redundan zona.
- Untuk seri premium Hyperscale dan perangkat keras seri premium yang dioptimalkan memori, redundansi zona tersedia di wilayah tertentu. Untuk informasi selengkapnya, lihat Ketersediaan seri premium Hyperscale menurut wilayah untuk Azure SQL Database.
Konfigurasi redundan zona hanya dapat ditentukan selama pembuatan database. Pengaturan ini tidak dapat dimodifikasi setelah sumber daya disediakan. Gunakan Salinan database, pemulihan point-in-time, atau buat replika geografis untuk memperbarui konfigurasi redundan zona untuk database Hyperscale yang ada. Saat menggunakan salah satu opsi pembaruan ini, jika database target berada di wilayah yang berbeda dari sumbernya atau jika redundansi penyimpanan cadangan database dari target berbeda dari database sumber, operasi salin akan menjadi ukuran operasi data.
Untuk ketersediaan zona redundan, memilih jendela pemeliharaan selain default saat ini tersedia di wilayah tertentu. Untuk informasi selengkapnya, lihat Ketersediaan jendela pemeliharaan menurut wilayah untuk Azure SQL Database.
Saat ini tidak ada opsi untuk menentukan redundansi zona saat memigrasikan database ke Hyperscale menggunakan portal Azure. Namun, redundansi zona dapat ditentukan menggunakan Azure PowerShell, Azure CLI, atau REST API saat memigrasikan database yang ada dari tingkat layanan Azure SQL Database lain ke Hyperscale. Berikut adalah contoh dengan Azure CLI:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Setidaknya satu replika komputasi ketersediaan tinggi dan penggunaan penyimpanan cadangan zona-redundan atau geo-zona-redundan diperlukan untuk mengaktifkan konfigurasi zona redundan untuk Hyperscale.
Keberadaan redundansi zona basis data
Di Azure SQL Database, server adalah konstruksi logis yang bertindak sebagai titik administratif pusat untuk kumpulan database. Di tingkat server, Anda dapat mengelola login, metode autentikasi, aturan firewall, aturan audit, kebijakan deteksi ancaman, dan grup failover. Data yang terkait dengan beberapa fitur ini, seperti login dan aturan firewall, disimpan dalam master database. Demikian pula, data untuk beberapa DMV, misalnya sys.resource_stats, juga disimpan dalam master database.
Ketika database dengan konfigurasi zona-redundan dibuat di server logis, master database yang terkait dengan server juga secara otomatis dibuat zona-redundan. Ini memastikan bahwa dalam pemadaman zona, aplikasi yang menggunakan database tetap tidak terpengaruh karena fitur tergantung pada master database, seperti login dan aturan firewall, masih tersedia.
master Membuat database menjadi zona-redundan adalah proses asinkron yang akan memerlukan waktu untuk diselesaikan secara latar belakang.
Ketika tidak ada database di server yang zona-redundan, atau ketika Anda membuat server kosong, database yang terkait dengan server tidak zona-redundan. Untuk memigrasikan Azure SQL Database Anda untuk menggunakan redundansi zona, ikuti langkah-langkah dalam Memigrasikan Azure SQL Database ke dukungan zona ketersediaan.
Untuk memeriksa ZoneRedundant properti master database, gunakan Azure PowerShell atau Azure CLI atau langkah-langkah REST API di Memvalidasi status zona ketersediaan Azure SQL Database.
Menguji ketahanan kesalahan aplikasi
Ketersediaan tinggi adalah bagian mendasar dari platform SQL Database yang berfungsi secara transparan untuk aplikasi database Anda. Namun, kami menyadari bahwa Anda mungkin ingin menguji bagaimana operasi failover otomatis yang dimulai selama peristiwa yang direncanakan atau tidak direncanakan akan memengaruhi aplikasi sebelum Anda menyebarkannya ke produksi. Anda dapat memicu failover secara manual dengan memanggil API khusus untuk memulai ulang database, atau kumpulan elastis. Dalam kasus database atau kumpulan elastis General Purpose tanpa server atau diprovisikan yang bersifat redundan zona, panggilan API akan mengalihkan koneksi klien ke primer baru di Zona Ketersediaan yang berbeda dari Zona Ketersediaan primer lama. Jadi, selain menguji dampak kegagalan pada sesi database yang ada, Anda juga dapat memverifikasi apakah itu mengubah kinerja menyeluruh karena adanya perubahan latensi jaringan. Karena operasi restart bersifat intrusif dan sejumlah besar dari mereka dapat membebani platform, hanya satu panggilan failover yang diizinkan setiap 15 menit untuk setiap database atau kumpulan elastis.
Untuk informasi selengkapnya tentang ketersediaan tinggi dan pemulihan bencana Azure SQL Database, tinjau Daftar periksa Ketersediaan tinggi dan pemulihan bencana - Azure SQL Database.
Failover dapat dipicu menggunakan PowerShell, REST API, atau Azure CLI.
| Jenis penyebaran | PowerShell | REST API | Azure CLI | Portal (Pratinjau) |
|---|---|---|---|---|
| Database | Invoke-AzSqlDatabaseFailover | Failover database | az rest mungkin digunakan untuk memanggil panggilan REST API dari Azure CLI | Pengaturan > Pemeliharaan > Hidupkan Ulang |
| Kolam elastis | Invoke-AzSqlElasticPoolFailover | Kegagalan kumpulan elastis | az rest mungkin digunakan untuk memanggil panggilan REST API dari Azure CLI | Pengaturan > Pemeliharaan > Hidupkan Ulang |
Important
Perintah Failover tidak tersedia untuk replika sekunder database Hyperscale yang dapat dibaca.
Conclusion
Azure SQL Database memiliki solusi ketersediaan tinggi bawaan yang terintegrasi secara mendalam dengan platform Azure. Ini tergantung pada Service Fabric untuk deteksi dan pemulihan kegagalan, pada penyimpanan Azure Blob untuk perlindungan data, dan pada Zona Ketersediaan untuk toleransi kesalahan yang lebih tinggi. Selain itu, SQL Database menggunakan teknologi grup ketersediaan AlwaysOn dari SQL Server untuk sinkronisasi dan failover data. Kombinasi teknologi ini memungkinkan aplikasi untuk sepenuhnya mewujudkan manfaat model penyimpanan campuran dan mendukung SLA yang paling menuntut.