Memantau performa Azure SQL Database menggunakan tampilan manajemen dinamis
Berlaku untuk: ![]() Azure SQL Database
Azure SQL Database
Anda dapat menggunakan tampilan manajemen dinamis (DMV) untuk memantau performa beban kerja dan mendiagnosis masalah performa, yang mungkin disebabkan oleh kueri yang diblokir atau berjalan lama, penyempitan sumber daya, rencana kueri suboptimal, dan banyak lagi.
Artikel ini menyediakan informasi tentang cara mendeteksi masalah performa umum dengan mengkueri tampilan manajemen dinamis melalui T-SQL. Anda bisa menggunakan alat kueri apa pun, seperti:
Izin
Di Azure SQL Database, tergantung pada ukuran komputasi, opsi penyebaran, dan data di DMV, mengkueri DMV mungkin memerlukan VIEW DATABASE STATEizin , atau VIEW SERVER PERFORMANCE STATE, atau VIEW SERVER SECURITY STATE . Dua izin terakhir disertakan VIEW SERVER STATE dalam izin. Lihat izin status server diberikan melalui keanggotaan dalam peran server yang sesuai. Untuk menentukan izin mana yang diperlukan untuk mengkueri DMV tertentu, lihat Tampilan manajemen dinamis dan temukan artikel yang menjelaskan DMV.
Untuk memberikan VIEW DATABASE STATE izin kepada pengguna database, jalankan kueri berikut, ganti database_user dengan nama prinsipal pengguna dalam database:
GRANT VIEW DATABASE STATE TO [database_user];
Untuk memberikan keanggotaan dalam ##MS_ServerStateReader## peran server ke login bernama login_name di server logis, sambungkan master ke database, lalu jalankan kueri berikut sebagai contoh:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Mungkin perlu waktu beberapa menit agar pemberian izin berlaku. Untuk informasi selengkapnya, lihat Batasan peran tingkat server.
Memantau penggunaan sumber daya
Anda dapat memantau penggunaan sumber daya di tingkat database menggunakan tampilan berikut. Tampilan ini berlaku untuk database mandiri, dan database dalam kumpulan elastis.
Anda dapat memantau penggunaan sumber daya di tingkat kumpulan elastis menggunakan tampilan berikut:
Anda dapat memantau penggunaan sumber daya di tingkat kueri dengan menggunakan Wawasan Performa Kueri SQL Database di portal Azure, atau melalui Penyimpanan Kueri.
sys.dm_db_sumberdaya_stats
Anda bisa menggunakan tampilan sys.dm_db_resource_stats di setiap database. sys.dm_db_resource_stats Tampilan menunjukkan data penggunaan sumber daya terbaru relatif terhadap batas ukuran komputasi. Persentase CPU, I/O data, penulisan log, utas pekerja, dan penggunaan memori terhadap batas dicatat untuk setiap interval 15 detik dan dipertahankan selama sekitar satu jam.
Karena tampilan ini menyediakan data penggunaan sumber daya terperinci, gunakan sys.dm_db_resource_stats terlebih dahulu untuk analisis atau pemecahan masalah status saat ini. Misalnya, kueri ini memperlihatkan penggunaan sumber daya rata-rata dan maksimum untuk database saat ini selama satu jam terakhir:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Untuk kueri lain, lihat contoh dalam sys.dm_db_resource_stats.
sys.sumberdaya_stats
Tampilan sys.resource_stats di database master memiliki informasi tambahan yang dapat membantu Anda memantau performa database pada tingkat layanan dan ukuran komputasi spesifiknya. Data dikumpulkan setiap 5 menit dan dipertahankan selama sekitar 14 hari. Tampilan ini berguna untuk analisis historis jangka panjang tentang bagaimana database Anda menggunakan sumber daya.
Grafik berikut menunjukkan penggunaan sumber daya CPU untuk database Premium dengan ukuran komputasi P2 untuk setiap jam dalam seminggu. Grafik ini dimulai pada hari Senin, menunjukkan lima hari kerja, dan kemudian menunjukkan akhir pekan, ketika jauh lebih sedikit terjadi dalam aplikasi.
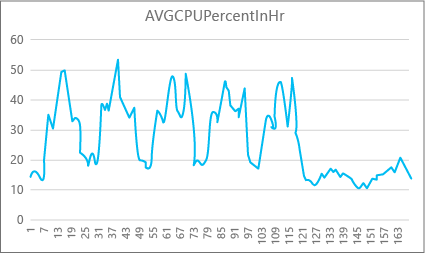
Dari data tersebut, database ini saat ini memiliki beban CPU puncak hanya lebih dari 50 persen penggunaan CPU relatif terhadap ukuran komputasi P2 (tengah hari pada hari Selasa). Jika CPU adalah faktor dominan dalam profil sumber daya aplikasi, maka Anda dapat memutuskan bahwa P2 adalah ukuran komputasi yang tepat untuk menjamin bahwa beban kerja selalu pas. Jika Anda mengharapkan aplikasi tumbuh dari waktu ke waktu, ada baiknya Anda memiliki buffer sumber daya tambahan sehingga aplikasi tidak mencapai batas tingkat performa. Jika Anda meningkatkan ukuran komputasi, Anda dapat membantu menghindari kesalahan yang terlihat pelanggan yang mungkin terjadi ketika database tidak memiliki cukup daya untuk memproses permintaan secara efektif, terutama di lingkungan yang sensitif terhadap latensi.
Untuk jenis aplikasi lain, Anda mungkin menginterpretasikan grafik yang sama secara berbeda. Misalnya, jika aplikasi mencoba memproses data penggajian setiap hari dan memiliki bagan yang sama, model "pekerjaan batch" semacam ini mungkin bisa berfungsi dengan baik pada ukuran komputasi P1. Ukuran komputasi P1 memiliki 100 DTU dibandingkan dengan 200 DTU pada ukuran komputasi P2. Ukuran komputasi P1 memberikan setengah performa ukuran komputasi P2. Jadi, 50 persen penggunaan CPU pada P2 sama dengan penggunaan CPU 100 persen dalam P1. Jika aplikasi tidak memiliki waktu habis, mungkin tidak masalah jika pekerjaan membutuhkan waktu 2 jam atau 2,5 jam untuk menyelesaikannya, jika selesai hari ini. Aplikasi dalam kategori ini mungkin dapat menggunakan ukuran komputasi P1. Anda dapat memanfaatkan adanya periode waktu di siang hari ketika penggunaan sumber daya lebih rendah, sehingga setiap "puncak besar" mungkin meluap ke salah satu palung di kemudian hari. Ukuran komputasi P1 mungkin baik untuk aplikasi semacam itu (dan menghemat uang), selama pekerjaan dapat selesai tepat waktu setiap hari.
Mesin database mengekspos informasi sumber daya yang digunakan untuk setiap database aktif dalam sys.resource_stats tampilan master database di setiap server logis. Data dalam tampilan diagregasi oleh interval 5 menit. Dibutuhkan beberapa menit agar data ini muncul dalam tabel, jadi sys.resource_stats lebih berguna untuk analisis historis daripada analisis mendekati real-time. sys.resource_stats Kueri tampilan untuk melihat riwayat database terbaru dan memvalidasi apakah ukuran komputasi yang Anda pilih memberikan performa yang Anda inginkan saat diperlukan.
Catatan
Anda harus tersambung ke master database untuk mengkueri sys.resource_stats dalam contoh berikut.
Contoh ini menunjukkan data di sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
Contoh berikutnya memperlihatkan kepada Anda berbagai cara untuk menggunakan sys.resource_stats tampilan katalog untuk mendapatkan informasi tentang cara database Anda menggunakan sumber daya:
Untuk melihat penggunaan sumber daya minggu lalu untuk database
userdb1pengguna , Anda bisa menjalankan kueri ini, mengganti nama database Anda sendiri:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Untuk mengevaluasi seberapa baik beban kerja Anda sesuai dengan ukuran komputasi, Anda perlu menelusuri paling detail setiap aspek metrik sumber daya: CPU, I/O data, penulisan log, jumlah pekerja, dan jumlah sesi. Berikut adalah kueri yang direvisi menggunakan
sys.resource_statsuntuk melaporkan nilai rata-rata dan maksimum metrik sumber daya ini, untuk setiap ukuran komputasi database telah disediakan untuk:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Dengan informasi ini tentang nilai rata-rata dan maksimum setiap metrik sumber daya, Anda dapat menilai seberapa baik beban kerja Anda sesuai dengan ukuran komputasi yang Anda pilih. Biasanya, nilai rata-rata dari
sys.resource_statsmemberi Anda garis besar yang baik untuk digunakan terhadap ukuran target.Untuk database model pembelian DTU:
Misalnya, Anda mungkin menggunakan tingkat layanan Standar dengan ukuran komputasi S2. Persentase penggunaan rata-rata untuk pembacaan dan penulisan CPU dan I/O di bawah 40 persen, jumlah rata-rata pekerja di bawah 50, dan jumlah rata-rata sesi di bawah 200. Beban kerja Anda mungkin sesuai dengan ukuran komputasi S1. Sangat mudah untuk melihat apakah database Anda cocok dengan batas pekerja dan sesi. Untuk melihat apakah database cocok dengan ukuran komputasi yang lebih rendah, bagi jumlah DTU dari ukuran komputasi yang lebih rendah dengan jumlah DTU ukuran komputasi Anda saat ini, lalu kalikan hasilnya dengan 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Hasilnya adalah perbedaan performa relatif antara dua ukuran komputasi dalam persentase. Jika penggunaan sumber daya Anda tidak melebihi persentase ini, beban kerja Anda mungkin sesuai dengan ukuran komputasi yang lebih rendah. Namun, Anda perlu melihat semua rentang nilai penggunaan sumber daya, dan menentukan, berdasarkan persentase, seberapa sering beban kerja database Anda akan masuk ke ukuran komputasi yang lebih rendah. Kueri berikut menghasilkan persentase kecocokan per dimensi sumber daya, berdasarkan ambang 40 persen yang kami hitung dalam contoh ini:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Berdasarkan tingkat layanan database, Anda dapat memutuskan apakah beban kerja Anda sesuai dengan ukuran komputasi yang lebih rendah. Jika tujuan beban kerja database Anda adalah 99,9 persen dan kueri sebelumnya mengembalikan nilai yang lebih besar dari 99,9 persen untuk ketiga dimensi sumber daya, beban kerja Anda kemungkinan cocok dengan ukuran komputasi yang lebih rendah.
Melihat persentase kecocokan juga memberi Anda wawasan tentang apakah Anda harus pindah ke ukuran komputasi yang lebih tinggi berikutnya untuk memenuhi tujuan Anda. Misalnya, penggunaan CPU untuk database sampel selama seminggu terakhir:
Persentase CPU rata-rata Persentase CPU maksimum 24,5 100.00 CPU rata-rata adalah sekitar seperempat dari batas ukuran komputasi, yang akan cocok dengan ukuran komputasi database.
Untuk model pembelian DTU dan database model pembelian vCore:
Nilai maksimum menunjukkan bahwa database mencapai batas ukuran komputasi. Apakah Anda perlu pindah ke ukuran komputasi yang lebih tinggi berikutnya? Lihatlah berapa kali beban kerja Anda mencapai 100 persen, lalu bandingkan dengan tujuan beban kerja database Anda.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Persentase ini adalah jumlah sampel yang sesuai dengan beban kerja Anda di bawah ukuran komputasi saat ini. Jika kueri ini mengembalikan nilai kurang dari 99,9 persen untuk salah satu dari tiga dimensi sumber daya, beban kerja rata-rata sampel Anda melebihi batas. Pertimbangkan untuk pindah ke ukuran komputasi yang lebih tinggi berikutnya atau gunakan teknik penyetelan aplikasi untuk mengurangi beban pada database.
sys.dm_elastic_pool_resource_stats
Demikian pula dengan sys.dm_db_resource_stats, sys.dm_elastic_pool_resource_stats menyediakan data penggunaan sumber daya terbaru dan terperinci untuk kumpulan elastis. Tampilan dapat dikueri dalam database apa pun dalam kumpulan elastis untuk menyediakan data penggunaan sumber daya untuk seluruh kumpulan, bukan database tertentu. Nilai persentase yang dilaporkan oleh DMV ini adalah terhadap batas kumpulan elastis, yang mungkin lebih tinggi dari batas untuk database di kumpulan.
Contoh ini menunjukkan data penggunaan sumber daya yang dirangkum untuk kumpulan elastis saat ini dalam 15 menit terakhir:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Jika Anda menemukan bahwa penggunaan sumber daya mendekati 100% untuk jangka waktu yang signifikan, Anda mungkin perlu meninjau penggunaan sumber daya untuk database individual di kumpulan elastis yang sama untuk menentukan berapa banyak setiap database berkontribusi pada penggunaan sumber daya tingkat kumpulan.
sys.elastic_pool_resource_stats
Demikian sys.resource_statspula dengan , sys.elastic_pool_resource_stats dalam master database menyediakan data penggunaan sumber daya historis untuk semua kumpulan elastis di server logis. Anda dapat menggunakan sys.elastic_pool_resource_stats untuk pemantauan historis selama 14 hari terakhir, termasuk analisis tren penggunaan.
Contoh ini menunjukkan data penggunaan sumber daya yang dirangkum dalam tujuh hari terakhir untuk semua kumpulan elastis di server logis saat ini. Jalankan kueri dalam master database.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Permintaan bersamaan
Untuk melihat jumlah permintaan bersamaan saat ini, jalankan kueri ini di database pengguna Anda:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Ini hanya rekam jepret pada satu titik waktu. Untuk lebih memahami tentang beban kerja dan persyaratan permintaan bersamaan, Anda harus mengumpulkan banyak sampel dari waktu ke waktu.
Tingkat permintaan rata-rata
Contoh ini menunjukkan cara menemukan tingkat permintaan rata-rata untuk database, atau untuk database dalam kumpulan elastis, selama periode waktu tertentu. Dalam contoh ini, periode waktu diatur ke 30 detik. Anda dapat menyesuaikannya dengan memodifikasi WAITFOR DELAY pernyataan. Jalankan kueri ini di database pengguna Anda. Jika database berada dalam kumpulan elastis dan jika Anda memiliki izin yang memadai, hasilnya menyertakan database lain dalam kumpulan elastis.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Sesi saat ini
Untuk melihat jumlah sesi aktif saat ini, jalankan kueri ini di database Anda:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Kueri ini mengembalikan jumlah titik waktu. Jika Anda mengumpulkan beberapa sampel dari waktu ke waktu, Anda akan memiliki pemahaman terbaik tentang penggunaan sesi Anda.
Riwayat permintaan, sesi, dan pekerja terbaru
Contoh ini mengembalikan penggunaan historis permintaan, sesi, dan utas pekerja baru-baru ini untuk database, atau untuk database dalam kumpulan elastis. Setiap baris mewakili rekam jepret penggunaan sumber daya pada titik waktu untuk database. Kolom requests_per_second adalah tingkat permintaan rata-rata selama interval waktu yang berakhir pada snapshot_time. Jika database berada dalam kumpulan elastis dan jika Anda memiliki izin yang memadai, hasilnya menyertakan database lain dalam kumpulan elastis.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Menghitung ukuran database dan objek
Kueri berikut mengembalikan ukuran data dalam database Anda (dalam megabyte):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Kueri berikut mengembalikan ukuran objek individual (dalam megabyte) di database Anda:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Mengidentifikasi masalah performa CPU
Bagian ini membantu Anda mengidentifikasi kueri individual yang merupakan konsumen CPU teratas.
Jika konsumsi CPU di atas 80% untuk jangka waktu yang lama, pertimbangkan langkah-langkah pemecahan masalah berikut apakah masalah CPU terjadi sekarang atau telah terjadi di masa lalu. Anda juga dapat mengikuti langkah-langkah di bagian ini untuk secara proaktif mengidentifikasi kueri penggunaan CPU teratas dan menyetelnya. Dalam beberapa kasus, mengurangi konsumsi CPU mungkin memungkinkan Anda menurunkan skala database dan kumpulan elastis dan menghemat biaya.
Langkah-langkah pemecahan masalah sama untuk database dan database mandiri di kumpulan elastis. Jalankan semua kueri dalam database pengguna.
Masalah CPU sedang terjadi sekarang
Jika masalah terjadi saat ini, ada dua skenario yang mungkin:
Banyak kueri individu yang secara kumulatif penggunaan CPUnya tinggi
Gunakan kueri berikut untuk mengidentifikasi kueri teratas menurut hash kueri:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Kueri yang berjalan lama yang menggunakan CPU masih berjalan
Gunakan kueri berikut untuk mengidentifikasi kueri ini:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
Jika masalah CPU terjadi di masa lalu
Jika masalah terjadi di masa lalu dan Anda ingin melakukan analisis akar penyebab, gunakan Query Store. Pengguna dengan akses database bisa menggunakan T-SQL untuk mengkueri data Query Store. Secara default, Penyimpanan Kueri mengambil statistik kueri agregat untuk interval satu jam.
Gunakan kueri berikut untuk melihat aktivitas untuk kueri penggunaan CPUnya tinggi. Kueri ini mengembalikan 15 kueri teratas yang memakan CPU. Ingatlah untuk mengubah
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()untuk melihat periode waktu selain dua jam terakhir:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Setelah Anda mengidentifikasi kueri yang bermasalah, saatnya untuk menyetel kueri tersebut untuk mengurangi pemanfaatan CPU. Atau, Anda dapat memilih untuk meningkatkan ukuran komputasi database atau kumpulan elastis untuk mengatasi masalah ini.
Untuk informasi selengkapnya tentang menangani masalah performa CPU di Azure SQL Database, lihat Mendiagnosis dan memecahkan masalah CPU tinggi di Azure SQL Database.
Mengidentifikasi masalah performa I/O
Saat mengidentifikasi masalah performa input/output penyimpanan (I/O), jenis tunggu teratas adalah:
PAGEIOLATCH_*Untuk masalah I/O file data (termasuk
PAGEIOLATCH_SH, ,PAGEIOLATCH_UPPAGEIOLATCH_EX). Jika nama jenis tunggu memiliki IO di dalamnya, itu menunjuk ke masalah I/O. Jika tidak ada IO di nama tunggu kait halaman, itu menunjuk ke jenis masalah yang berbeda yang tidak terkait dengan performa penyimpanan (misalnya,tempdbpertikaian).WRITE_LOGUntuk masalah I/O log transaksi.
Jika masalah I/O terjadi sekarang
Gunakan sys.dm_exec_requests atau sys.dm_os_waiting_tasks untuk melihat wait_type dan wait_time.
Mengidentifikasi data dan penggunaan I/O log
Gunakan kueri berikut untuk mengidentifikasi data dan penggunaan I/O log.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Untuk contoh selengkapnya menggunakan sys.dm_db_resource_stats, lihat bagian Memantau penggunaan sumber daya nanti di artikel ini.
Jika batas I/O telah tercapai, Anda memiliki dua opsi:
- Meningkatkan ukuran komputasi atau tingkat layanan
- Identifikasi dan sesuaikan kueri yang paling banyak menggunakan I/O.
Menampilkan I/O terkait buffer menggunakan Penyimpanan Kueri
Untuk mengidentifikasi kueri teratas berdasarkan tunggu terkait I/O, Anda bisa menggunakan kueri Penyimpanan Kueri berikut untuk menampilkan dua jam terakhir aktivitas terlacak:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Anda juga dapat menggunakan tampilan sys.query_store_runtime_stats , berfokus pada kueri dengan nilai besar di avg_physical_io_reads kolom dan avg_num_physical_io_reads .
Lihat total log I/O untuk writelog menunggu
Jika jenis tunggu adalah WRITELOG, gunakan kueri berikut untuk menampilkan total I/O log menurut pernyataan:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Mengidentifikasi masalah performa tempdb
Jenis tunggu umum yang terkait dengan tempdb masalah adalah PAGELATCH_* (bukan PAGEIOLATCH_*). Namun, PAGELATCH_* menunggu tidak selalu berarti Anda memiliki ketidakcocokan tempdb. Waktu tunggu ini juga dapat berarti bahwa Anda memiliki ketidakcocokan halaman data objek pengguna karena permintaan bersamaan yang menargetkan halaman data yang sama. Untuk mengonfirmasi tempdb ketidakcocokan lebih lanjut, gunakan sys.dm_exec_requests untuk mengonfirmasi bahwa wait_resource nilai dimulai dengan 2:x:y di mana 2 adalah tempdb ID database, x adalah ID file, dan y merupakan ID halaman.
Untuk tempdb ketidakcocokan, metode umum adalah mengurangi atau menulis ulang kode aplikasi yang bergantung pada tempdb. Area penggunaan tempdb umum meliputi:
- Tabel sementara
- Variabel tabel
- Parameter bernilai tabel
- Kueri yang memiliki rencana kueri yang menggunakan pengurutan, gabungan hash, dan tampungan
Untuk informasi selengkapnya, lihat tempdb di Azure SQL.
Semua database dalam kumpulan elastis berbagi database yang sama tempdb . Pemanfaatan ruang tinggi tempdb oleh satu database mungkin memengaruhi database lain dalam kumpulan elastis yang sama.
Kueri teratas yang menggunakan variabel tabel dan tabel sementara
Anda dapat menggunakan kueri berikut untuk mengidentifikasi kueri teratas yang menggunakan variabel tabel dan tabel sementara:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Mengidentifikasi transaksi yang berjalan lama
Gunakan kueri berikut untuk mengidentifikasi transaksi yang berjalan lama. Transaksi yang berjalan lama mencegah pembersihan penyimpanan versi persisten (PVS). Untuk informasi selengkapnya, lihat Memecahkan masalah pemulihan database yang dipercepat.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Mengidentifikasi masalah performa tunggu peruntukan memori
Jika jenis tunggu teratas Anda adalah RESOURCE_SEMAPHORE, Anda mungkin memiliki masalah tunggu pemberian memori di mana kueri tidak dapat mulai dijalankan sampai mereka mendapatkan pemberian memori yang cukup besar.
Menentukan apakah tunggu RESOURCE_SEMAPHORE adalah tunggu atas
Gunakan kueri berikut untuk menentukan apakah RESOURCE_SEMAPHORE tunggu adalah tunggu teratas. Juga indikasi akan menjadi naiknya pangkat RESOURCE_SEMAPHORE waktu tunggu dalam sejarah baru-baru ini. Untuk informasi selengkapnya tentang pemecahan masalah tunggu pemberian memori, lihat Memecahkan masalah performa lambat atau memori rendah yang disebabkan oleh pemberian memori di SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Mengidentifikasi pernyataan yang penggunaan memorinya tinggi
Jika Anda menemukan kesalahan kehabisan memori di Azure SQL Database, tinjau sys.dm_os_out_of_memory_events. Untuk informasi selengkapnya, lihat Memecahkan masalah kesalahan kehabisan memori dengan Azure SQL Database.
Pertama, ubah skrip berikut untuk memperbarui nilai yang relevan dari start_time dan end_time. Kemudian, jalankan kueri berikut untuk mengidentifikasi pernyataan yang memakan memori tinggi:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Mengidentifikasi 10 peruntukan memori aktif teratas
Gunakan kueri berikut untuk mengidentifikasi 10 hibah memori aktif teratas:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Memantau koneksi
Anda dapat menggunakan tampilan sys.dm_exec_connections untuk mengambil informasi tentang koneksi yang dibuat ke database tertentu dan detail setiap koneksi. Jika database berada dalam kumpulan elastis dan Anda memiliki izin yang memadai, tampilan mengembalikan kumpulan koneksi untuk semua database di kumpulan elastis. Selain itu, tampilan sys.dm_exec_sessions sangat membantu saat mengambil informasi tentang semua koneksi pengguna aktif dan tugas internal.
Lihat sesi saat ini
Kueri berikut mengambil informasi untuk koneksi dan sesi Anda saat ini. Untuk melihat semua koneksi dan sesi, hapus WHERE klausa.
Anda melihat semua sesi eksekusi pada database hanya jika Anda memiliki VIEW DATABASE STATE izin pada database saat menjalankan sys.dm_exec_requests tampilan dan sys.dm_exec_sessions . Jika tidak, Anda hanya melihat sesi saat ini.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Memantau performa kueri
Kueri yang berjalan lambat atau lama penggunaan sumber daya sistemnya bersifat signifikan. Bagian ini menunjukkan cara menggunakan tampilan manajemen dinamis untuk mendeteksi beberapa masalah performa kueri umum menggunakan tampilan manajemen dinamis sys.dm_exec_query_stats . Tampilan berisi satu baris per pernyataan kueri dalam paket yang di-cache, dan masa pakai baris terikat dengan rencana itu sendiri. Saat paket dihapus dari cache, baris terkait dihilangkan dari tampilan ini. Jika kueri tidak memiliki paket cache, misalnya karena OPTION (RECOMPILE) digunakan, kueri tidak ada dalam hasil dari tampilan ini.
Menemukan kueri teratas menurut waktu CPU
Contoh berikut mengembalikan informasi tentang 15 kueri teratas yang diberi peringkat berdasarkan waktu CPU rata-rata per eksekusi. Contoh ini mengagregasi kueri sesuai dengan hash kuerinya, sehingga kueri yang setara secara logis dikelompokkan menurut penggunaan sumber daya kumulatifnya.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Memantau rencana kueri untuk waktu CPU kumulatif
Rencana kueri yang tidak efisien juga dapat meningkatkan penggunaan CPU. Contoh berikut menentukan kueri mana yang menggunakan CPU paling kumulatif dalam riwayat terbaru.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Memantau kueri yang diblokir
Kueri yang berjalan lambat atau lama dapat menyebabkan penggunaan sumber daya yang berlebihan dan berakibat kueri diblokir. Penyebab pemblokiran bisa karena desain aplikasi yang buruk, rencana kueri yang buruk, kurangnya indeks yang berguna, dan sebagainya.
Anda bisa menggunakan sys.dm_tran_locks tampilan untuk mendapatkan informasi tentang aktivitas penguncian saat ini dalam database. Untuk contoh kode, lihat sys.dm_tran_locks. Untuk informasi selengkapnya tentang pemblokiran pemecahan masalah, lihat Memahami dan mengatasi masalah pemblokiran Azure SQL.
Memantau kebuntuan
Dalam beberapa kasus, dua atau beberapa kueri mungkin memblokir satu dengan yang lain, yang mengakibatkan kebuntuan.
Anda dapat membuat jejak Kejadian yang Diperluas untuk menangkap peristiwa kebuntuan, lalu menemukan kueri terkait dan rencana eksekusinya di Penyimpanan Kueri. Pelajari selengkapnya di Menganalisis dan mencegah kebuntuan di Azure SQL Database, termasuk lab untuk Menyebabkan kebuntuan di AdventureWorksLT. Pelajari selengkapnya tentang jenis sumber daya yang dapat membuat kebuntuan.
Konten terkait
- Pengenalan Azure SQL Database dan Azure SQL Managed Instance
- Mendiagnosis dan memecahkan masalah CPU tinggi di Azure SQL Database
- Menyetel aplikasi dan database untuk performa di Azure SQL Database
- Memahami dan mengatasi masalah pemblokiran Azure SQL Database
- Menganalisis dan mencegah kebuntuan di Azure SQL Database
- Memantau beban kerja Azure SQL dengan pengamat database (pratinjau)
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk