Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database
Artikel ini memberikan gambaran umum tentang manajemen sumber daya di Azure SQL Database. Artikel ini memberikan informasi tentang apa yang terjadi ketika batas sumber daya tercapai, dan menjelaskan mekanisme tata kelola sumber daya yang digunakan untuk menegakkan batas-batas ini.
Untuk batas sumber daya tertentu per tingkat harga untuk database tunggal, lihat:
Untuk batas sumber daya kumpulan elastis, lihat:
Untuk batas kumpulan SQL khusus Azure Synapse Analytics, lihat:
Batas langganan vCore per wilayah
Mulai Maret 2024, langganan memiliki batas vCore berikut per wilayah per langganan:
| Jenis langganan | Batas vCore default |
|---|---|
| Perjanjian Enterprise (EA) | 2000 |
| Coba gratis | 10 |
| Microsoft untuk startup | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure untuk Siswa | 40 |
| Bayar sesuai penggunaan (PAYG) | 150 |
Pertimbangkan hal berikut:
- Batas ini berlaku untuk langganan baru dan yang sudah ada.
- Database dan kumpulan elastis yang disediakan dengan model pembelian DTU dihitung terhadap kuota vCore, dan sebaliknya. Setiap vCore yang digunakan dianggap setara dengan 100 DTU yang digunakan untuk kuota tingkat server.
- Batas default termasuk vCore yang dikonfigurasi untuk database komputasi /kumpulan elastis yang disediakan, dan vCore maks
dikonfigurasi untuk database tanpa server . - Anda dapat menggunakan panggilan Penggunaan Langganan - Dapatkan REST API untuk menentukan penggunaan vCore Anda saat ini untuk langganan Anda.
- Untuk meminta kuota vCore yang lebih tinggi dari default, kirimkan permintaan dukungan baru di portal Azure. Untuk informasi selengkapnya, lihat Meminta peningkatan kuota untuk Azure SQL Database dan SQL Managed Instance.
Batas server logis
| Sumber daya | Batasan |
|---|---|
| Database per server logis | lima ribu |
| Jumlah default server logis per langganan dalam suatu wilayah | 250 |
| Jumlah maksimum server logis per langganan dalam suatu wilayah | 250 |
| Kumpulan elastis maksimum per server logis | Dibatasi oleh jumlah DTU atau vCores. Misalnya, jika setiap kumpulan adalah 1000 DTU, maka server dapat mendukung 54 kumpulan. |
Penting
Saat jumlah database mendekati batas per server logis, hal berikut ini dapat terjadi:
- Meningkatkan latensi dalam menjalankan kueri terhadap
masterdatabase. Ini termasuk tampilan statistik pemanfaatan sumber daya sepertisys.resource_stats. - Meningkatkan latensi dalam operasi manajemen dan penyajian sudut pandang portal yang melibatkan enumerasi database di server.
Apa yang terjadi ketika batas sumber daya database tercapai
Komputasi CPU
Ketika pemanfaatan CPU komputasi database menjadi tinggi, latensi kueri meningkat, dan kueri bahkan dapat kehabisan waktu. Dalam kondisi ini, kueri mungkin diantrekan oleh layanan dan disediakan sumber daya untuk eksekusi saat sumber daya menjadi gratis.
Jika Anda mengamati pemanfaatan komputasi tinggi, opsi mitigasi meliputi:
- Meningkatkan ukuran komputasi database atau kumpulan elastis untuk menyediakan database dengan sumber daya komputasi yang lebih banyak. Lihat Menskalakan sumber daya database tunggal dan Menskalakan sumber daya kumpulan elastis.
- Mengoptimalkan kueri untuk mengurangi pemanfaatan sumber daya CPU dari setiap kueri. Untuk informasi lebih lanjut, lihat Penyetelan/Petunjuk Kueri.
Penyimpanan
Ketika ruang data yang digunakan mencapai batas ukuran data maksimum, baik di tingkat database atau di tingkat kumpulan elastis, menyisipkan dan memperbarui yang meningkatkan ukuran data gagal, dan klien menerima pesan kesalahan . Pernyataan PILIH dan HAPUS tetap tidak terpengaruh.
Di tingkat layanan Premium dan Penting Bagi Bisnis, klien juga menerima pesan kesalahan jika penggunaan penyimpanan gabungan berdasarkan data, log transaksi, dan tempdb untuk database tunggal atau kumpulan elastis melebihi ukuran penyimpanan lokal maksimum. Untuk informasi selengkapnya, lihat Pemerintahan ruang Storage.
Jika Anda mengamati pemanfaatan ruang penyimpanan yang tinggi, opsi mitigasi meliputi:
- Tingkatkan ukuran data maksimum database atau kumpulan elastis, atau skalakan ke tujuan layanan dengan batas ukuran data maksimum yang lebih tinggi. Lihat Menskalakan sumber daya database tunggal dan Menskalakan sumber daya kumpulan elastis.
- Jika database berada dalam kumpulan elastis, database dapat dipindahkan ke luar, sehingga ruang penyimpanannya tidak dibagikan dengan database lain.
- Kecilkan database untuk mendapatkan kembali ruang yang tidak digunakan. Untuk informasi selengkapnya, lihat Mengelola ruang file untuk database.
- Dalam kumpulan elastis, menyusutkan database menyediakan lebih banyak penyimpanan untuk database lain di kumpulan.
- Periksa apakah pemanfaatan ruang tinggi disebabkan oleh lonjakan ukuran Persistent Version Store (PVS). PVS adalah bagian dari setiap database, dan digunakan untuk mengimplementasikan pemulihan database Dipercepat. Untuk menentukan ukuran PVS saat ini, lihat Memecahkan masalah pemulihan database yang dipercepat. Alasan umum untuk ukuran PVS besar adalah transaksi yang terbuka untuk waktu yang lama (jam), mencegah pembersihan baris versi lama dalam PVS.
- Untuk database dan kumpulan elastis di tingkat layanan Premium dan Business Critical yang menggunakan penyimpanan dalam jumlah besar, Anda mungkin menerima kesalahan di luar ruang meskipun ruang yang digunakan dalam database atau kumpulan elastis berada di bawah batas ukuran data maksimumnya. Ini dapat terjadi jika
tempdbatau file log transaksi menggunakan sejumlah besar penyimpanan menuju batas penyimpanan lokal maksimum. Alihkan database atau kumpulan elastis untuk mengatur ulangtempdbke ukuran awal yang lebih kecil, atau menyusutkan log transaksi untuk mengurangi penggunaan penyimpanan lokal.
Sesi, pekerja, dan permintaan
Sesi, pekerja, dan permintaan ditentukan sebagai berikut:
- Sebuah sesi mewakili proses yang tersambung ke mesin database.
- Permintaan adalah representasi logis dari kueri atau batch. Permintaan diterbitkan oleh klien yang tersambung ke sebuah sesi. Seiring waktu, beberapa permintaan dapat dikeluarkan pada sesi yang sama.
- Utas pekerja, juga dikenal sebagai pekerja atau utas, adalah representasi logis dari utas sistem operasi. Permintaan dapat memiliki banyak pekerja saat dijalankan dengan rencana eksekusi kueri paralel, atau satu pekerja saat dijalankan dengan rencana eksekusi serial (satu utas). Pekerja juga diperlukan untuk mendukung aktivitas di luar permintaan: misalnya, pekerja diperlukan untuk memproses permintaan masuk saat sesi tersambung.
Untuk informasi selengkapnya tentang konsep-konsep ini, lihat panduan Alur dan arsitektur tugas.
Jumlah maksimum pekerja ditentukan oleh tingkat layanan dan ukuran komputasi. Permintaan baru ditolak saat batas sesi atau worker tercapai, dan klien menerima pesan kesalahan. Meskipun jumlah koneksi dapat dikontrol oleh aplikasi, jumlah pekerja bersamaan sering lebih sulit untuk diperkirakan dan dikontrol. Hal ini terutama berlaku selama periode beban puncak ketika batas sumber daya database tercapai dan worker menumpuk karena kueri yang berjalan lebih lama, rantai pemblokiran besar, atau paralelisme kueri yang berlebihan.
Catatan
Penawaran awal kueri Azure SQL Database hanya mendukung kueri utas tunggal. Pada saat itu, jumlah permintaan selalu sama dengan jumlah pekerja. Pesan kesalahan 10928 di Azure SQL Database berisi kata-kata The request limit for the database is *N* and has been reached hanya untuk tujuan kompatibilitas mundur. Batas yang tercapai sebenarnya adalah jumlah pekerja.
Jika pengaturan tingkat paralelisme maksimum (MAXDOP) Anda sama dengan nol atau lebih besar dari satu, jumlah pekerja bisa jauh lebih tinggi daripada jumlah permintaan, dan batasnya mungkin tercapai jauh lebih cepat daripada ketika MAXDOP sama dengan satu.
- Pelajari selengkapnya tentang kesalahan 10928 dalam Kesalahan pemerintahan sumber daya.
- Pelajari selengkapnya tentang kelelahan batas permintaan dalam Kesalahan 10928 dan 10936.
Anda dapat mengurangi kemungkinan mendekati atau mencapai batas pegawai atau sesi dengan cara:
- Meningkatkan tingkat layanan atau ukuran komputasi database atau kumpulan elastis. Lihat Menskalakan sumber daya database tunggal dan Menskalakan sumber daya kumpulan elastis.
- Mengoptimalkan kueri untuk mengurangi penggunaan sumber daya jika bertambahnya pekerja disebabkan oleh perdebatan sumber daya komputasi. Untuk informasi lebih lanjut, lihat Penyetelan/Petunjuk Kueri.
- Mengoptimalkan beban kerja kueri untuk mengurangi jumlah kemunculan dan durasi pemblokiran kueri. Untuk informasi selengkapnya, lihat Memahami dan mengatasi masalah pemblokiran.
- Mengurangi pengaturan MAXDOP saat diperlukan.
Menemukan batas pekerja dan sesi untuk Azure SQL Database menurut tingkat layanan dan ukuran komputasi:
- Batas sumber daya untuk database tunggal yang menggunakan model pembelian vCore
- Batas sumber daya untuk kumpulan elastis menggunakan model pembelian vCore
- Batas sumber daya untuk database tunggal menggunakan model pembelian berbasis DTU
- Batas sumber daya untuk kumpulan elastis menggunakan model pembelian DTU
Pelajari lebih lanjut terkait pemecahan masalah kesalahan tertentu untuk batasan sesi atau pekerja dalam Kesalahan pemerintahan sumber daya.
Koneksi eksternal
Jumlah koneksi bersamaan ke titik akhir eksternal yang dilakukan melalui sp_invoke_external_rest_endpoint dibatasi hingga 10% utas pekerja, dengan batas keras maksimal 150 pekerja.
Memori
Tidak seperti sumber daya lain (CPU, pekerja, penyimpanan), mencapai batas memori tidak berdampak negatif pada performa kueri, dan tidak menyebabkan kesalahan dan kegagalan. Seperti yang dijelaskan secara rinci dalam panduan arsitektur manajemen memori , mesin database sering menggunakan semua memori yang tersedia, berdasarkan desain. Memori digunakan terutama untuk penembolokan data, untuk menghindari akses penyimpanan yang lebih lambat. Dengan demikian, penggunaan memori yang lebih tinggi biasanya meningkatkan kinerja kueri karena pembacaan dari memori yang lebih cepat daripada pembacaan yang lebih lambat dari penyimpanan.
Setelah mesin database diaktifkan, saat beban kerja mulai membaca data dari penyimpanan, mesin database secara agresif menyimpan data dalam memori. Setelah periode peningkatan awal ini, umum dan diharapkan untuk melihat avg_memory_usage_percent kolom dan avg_instance_memory_percent di sys.dm_db_resource_stats, dan sql_instance_memory_percent metrik Azure Monitor mendekati 100%, terutama untuk database yang tidak menganggur, dan tidak sepenuhnya pas dalam memori.
Catatan
sql_instance_memory_percent Metrik mencerminkan total konsumsi memori oleh mesin database. Metrik ini mungkin tidak mencapai 100% bahkan ketika beban kerja intensitas tinggi berjalan. Ini karena sebagian kecil memori yang tersedia dicadangkan untuk alokasi memori penting selain cache data, seperti tumpukan utas dan modul yang dapat dieksekusi.
Selain cache data, memori digunakan dalam komponen lain dari mesin database. Ketika ada permintaan memori dan semua memori yang tersedia telah digunakan oleh cache data, mesin database mengurangi ukuran cache data untuk membuat memori tersedia untuk komponen lain, dan secara dinamis menumbuhkan cache data ketika komponen lain melepaskan memori.
Dalam kasus yang jarang terjadi, beban kerja yang cukup menuntut dapat menyebabkan kondisi memori yang tidak mencukupi, yang menyebabkan kesalahan kehabisan memori. Kesalahan kehabisan memori dapat terjadi pada tingkat pemanfaatan memori apa pun antara 0% dan 100%. Kesalahan di luar memori lebih mungkin terjadi pada ukuran komputasi yang lebih kecil yang memiliki batas memori yang proporsional lebih kecil, dan / atau dengan beban kerja menggunakan lebih banyak memori untuk pemrosesan kueri, seperti di kumpulan elastis yang padat.
Jika Anda mendapatkan kesalahan di luar memori, opsi mitigasi meliputi:
- Tinjau detail kondisi OOM di sys.dm_os_out_of_memory_events.
- Meningkatkan tingkat layanan atau ukuran komputasi database atau kumpulan elastis. Lihat Menskalakan sumber daya database tunggal dan Menskalakan sumber daya kumpulan elastis.
- Mengoptimalkan kueri dan konfigurasi untuk mengurangi penggunaan memori. Solusi umum dijelaskan dalam tabel berikut ini.
| Solusi | Deskripsi |
|---|---|
| Mengurangi ukuran peruntukan memori | Untuk informasi selengkapnya tentang pemberian memori, lihat posting blog Memahami memori SQL Server yang diberikan. Solusi umum untuk menghindari pemberian memori yang terlalu besar adalah dengan menjaga statistik terbaru. Ini menghasilkan perkiraan konsumsi memori yang lebih akurat oleh mesin kueri, menghindari pemberian memori besar. Secara default, dalam database yang menggunakan tingkat kompatibilitas 140 ke atas, mesin database dapat secara otomatis menyesuaikan ukuran pemberian memori menggunakan umpan balik pemberian memori mode Batch. Dalam database yang menggunakan tingkat kompatibilitas 150 ke atas, mesin database juga menggunakan Umpan balik pemberian memori mode Baris, untuk kueri mode baris yang lebih umum. Fungsionalitas bawaan ini membantu menghindari kesalahan di luar memori karena peruntukan memori yang besar. |
| Mengurangi ukuran cache rencana kueri | Mesin database menyimpan rencana kueri di dalam memori untuk menghindari penyusunan rencana kueri untuk setiap eksekusi kueri. Untuk menghindari cache rencana kueri membengkak yang disebabkan oleh rencana pembuatan cache yang hanya digunakan sekali, pastikan untuk menggunakan kueri parameter, dan pertimbangkan untuk mengaktifkan konfigurasi yang tercakup database OPTIMIZE_FOR_AD_HOC_WORKLOADS. |
| Mengurangi ukuran memori kunci | Mesin database menggunakan memori untuk kunci. Jika memungkinkan, hindari transaksi besar yang mungkin memperoleh sejumlah besar kunci dan menyebabkan konsumsi memori kunci tinggi. |
Konsumsi sumber daya berdasarkan beban kerja pengguna dan proses internal
Azure SQL Database memerlukan sumber daya komputasi untuk menerapkan fitur layanan inti seperti ketersediaan tinggi dan pemulihan bencana, pencadangan dan pemulihan database, pemantauan, Penyimpanan Kueri, Penyetelan otomatis, dll. Sistem ini menyisihkan sebagian terbatas dari keseluruhan sumber daya untuk proses internal ini menggunakan mekanisme tata kelola sumber daya, membuat sisa sumber daya tersedia untuk beban kerja pengguna. Pada saat proses internal tidak menggunakan sumber daya komputasi, sistem membuatnya tersedia untuk beban kerja pengguna.
Total konsumsi CPU dan memori berdasarkan beban kerja pengguna dan proses internal di setiap database dilaporkan dalam tampilan sys.dm_db_resource_stats dan sys.resource_stats, di kolom avg_instance_cpu_percent dan avg_instance_memory_percent. Data ini juga dilaporkan melalui metrik sql_instance_cpu_percent dan sql_instance_memory_percentAzure Monitor, untuk database tunggal dan kumpulan elastis di tingkat kumpulan.
Catatan
sql_instance_cpu_percent Metrik Azure Monitor dan sql_instance_memory_percent tersedia sejak Juli 2023. Metrik tersebut sepenuhnya setara dengan metrik dan sqlserver_process_core_percent yang tersedia sqlserver_process_memory_percent sebelumnya. Dua metrik terakhir tetap tersedia, tetapi akan dihapus di masa mendatang. Untuk menghindari gangguan dalam pemantauan database, jangan gunakan metrik yang lebih lama.
Metrik ini tidak tersedia untuk database menggunakan tujuan layanan Dasar, S1, dan S2. Data yang sama tersedia dalam tampilan manajemen dinamis berikut.
Konsumsi CPU dan memori berdasarkan beban kerja pengguna di setiap database dilaporkan dalam tampilan sys.dm_db_resource_stats dan sys.resource_stats tampilan, di kolom avg_cpu_percent dan avg_memory_usage_percent. Untuk kumpulan elastis, konsumsi sumber daya tingkat kumpulan dilaporkan dalam tampilan sys.elastic_pool_resource_stats (untuk skenario pelaporan historis) dan dalam sys.dm_elastic_pool_resource_stats untuk pemantauan real time. Konsumsi CPU beban kerja pengguna juga dilaporkan melalui metrik cpu_percent Azure Monitor, untuk database tunggal dan kumpulan elastis di tingkat kumpulan.
Perincian yang lebih rinci tentang konsumsi sumber daya terbaru oleh beban kerja pengguna dan proses internal dilaporkan dalam tampilan sys.dm_resource_governor_resource_pools_history_ex dan sys.dm_resource_governor_workload_groups_history_ex. Untuk detail tentang kumpulan sumber daya dan grup beban kerja yang dirujuk dalam tampilan ini, lihat Tata kelola sumber daya. Tampilan ini melaporkan pemanfaatan sumber daya oleh beban kerja pengguna dan proses internal tertentu di dalam kumpulan sumber daya terkait dan grup beban kerja.
Petunjuk / Saran
Saat memantau atau memecahkan masalah performa beban kerja, penting untuk mempertimbangkan konsumsi CPU pengguna (avg_cpu_percent, cpu_percent), dan total konsumsi CPU oleh beban kerja pengguna dan proses internal (avg_instance_cpu_percent,sql_instance_cpu_percent). Performa mungkin terpengaruh secara nyata jika salah satu metrik ini berada dalam rentang 70-100%.
Konsumsi CPU pengguna didefinisikan sebagai persentase terhadap batas CPU beban kerja pengguna di setiap tujuan layanan. Demikian juga, total konsumsi CPU didefinisikan sebagai persentase terhadap batas CPU untuk semua beban kerja. Karena kedua batas tersebut berbeda, konsumsi CPU pengguna dan total diukur pada skala yang berbeda, dan tidak secara langsung sebanding satu sama lain.
Jika konsumsi CPU pengguna mencapai 100%, itu berarti bahwa beban kerja pengguna sepenuhnya menggunakan kapasitas CPU yang tersedia untuknya dalam tujuan layanan yang dipilih, bahkan jika total konsumsi CPU tetap di bawah 100%.
Ketika total konsumsi CPU mencapai rentang 70-100%, dimungkinkan untuk melihat throughput beban kerja pengguna meratakan dan latensi kueri meningkat, bahkan jika konsumsi CPU pengguna tetap secara signifikan di bawah 100%. Hal ini lebih mungkin terjadi ketika menggunakan tujuan layanan yang lebih kecil dengan alokasi sumber daya komputasi yang moderat, tetapi beban kerja pengguna yang relatif intens, seperti pada kumpulan elastis yang padat. Ini juga dapat terjadi dengan tujuan layanan yang lebih kecil ketika proses internal untuk sementara memerlukan lebih banyak sumber daya, misalnya saat membuat replika database baru, atau mencadangkan database.
Demikian juga, ketika konsumsi CPU pengguna mencapai rentang 70-100%, throughput beban kerja pengguna merata dan latensi kueri meningkat, bahkan jika total konsumsi CPU jauh di bawah batasnya.
Ketika konsumsi CPU pengguna atau konsumsi CPU total tinggi, opsi mitigasi sama seperti yang disebutkan di bagian Komputasi CPU, dan menyertakan peningkatan tujuan layanan dan/atau pengoptimalan beban kerja pengguna.
Catatan
Bahkan pada database yang benar-benar menganggur atau kumpulan elastis, total konsumsi CPU tidak pernah nol karena aktivitas mesin database latar belakang. Ini dapat berfluktuasi dalam berbagai macam tergantung pada aktivitas latar belakang tertentu, ukuran komputasi, dan beban kerja pengguna sebelumnya.
Tata kelola sumber daya
Untuk menerapkan batasan sumber daya, Azure SQL Database menggunakan implementasi tata kelola sumber daya yang didasarkan pada Resource Governor SQL Server, yang dimodifikasi dan diperluas untuk dijalankan di cloud. Dalam Microsoft Azure SQL Database, beberapa kumpulan sumber dayadan grup beban kerja, dengan batas sumber daya yang ditetapkan di tingkat kumpulan dan grup, memberikan Database-as-a-Service yang seimbang. Beban kerja pengguna dan beban kerja internal diklasifikasikan ke dalam kumpulan sumber daya dan grup beban kerja yang terpisah. Beban kerja pengguna pada replika primer dan sekunder yang dapat dibaca, termasuk geo-replika, diklasifikasikan ke dalam pusat sumber daya SloSharedPool1 dan grup beban kerja UserPrimaryGroup.DBId[N], di mana [N] adalah singkatan dari nilai ID database. Selain itu, ada beberapa kumpulan sumber daya dan beban kerja untuk berbagai beban kerja internal.
Selain menggunakan Resource Governor untuk mengatur sumber daya dalam mesin database, Azure SQL Database juga menggunakan Objek Pekerjaan Windows untuk tata kelola sumber daya tingkat proses, dan File Server Resource Manager (FSRM) Windows untuk manajemen kuota penyimpanan.
Tata kelola sumber daya Azure SQL Database bersifat hierarkis. Dari atas ke bawah, batas diberlakukan di tingkat OS dan di tingkat volume penyimpanan menggunakan mekanisme tata kelola sumber daya sistem operasi dan Resource Governor, kemudian di tingkat kumpulan sumber daya menggunakan dan di tingkat kelompok beban kerja juga menggunakan Resource Governor. Batas tata kelola sumber daya yang berlaku untuk database saat ini atau kumpulan elastis dilaporkan dalam tampilan sys.dm_user_db_resource_governance.
Tata kelola I/O data
Tata kelola I/O Data adalah proses dalam Azure SQL Database yang digunakan untuk membatasi I/O membaca dan menulis secara fisik terhadap file data database. Batas IOPS diatur untuk setiap tingkat layanan untuk meminimalkan efek "tetangga yang bising", untuk memberikan keadilan alokasi sumber daya dalam layanan multipenyewa, dan untuk tetap berada dalam kemampuan perangkat keras dan penyimpanan yang mendasar.
Untuk database tunggal, batas grup beban kerja diterapkan ke semua I/O penyimpanan terhadap database. Untuk kumpulan elastis, batas grup beban kerja berlaku untuk setiap database di kumpulan. Selain itu, batas pusat sumber daya juga berlaku untuk I/O kumulatif kumpulan elastis. Dalam tempdb, I/O tunduk pada batas grup beban kerja, kecuali untuk tingkat layanan Dasar, Standar, dan Tujuan Umum, di mana batas I/O yang lebih tinggi tempdb berlaku. Secara umum, batas kumpulan sumber daya mungkin tidak dapat dicapai oleh beban kerja terhadap database (baik tunggal atau terkumpul), karena batas grup beban kerja lebih rendah dari batas kumpulan sumber daya dan membatasi IOPS/throughput lebih cepat. Namun, batas kumpulan dapat dicapai oleh beban kerja gabungan terhadap beberapa database di kumpulan yang sama.
Misalnya, jika kueri menghasilkan 1000 IOPS tanpa tata kelola sumber daya I/O apa pun, tetapi batas IOPS maksimum grup beban kerja diatur ke 900 IOPS, kueri tidak dapat menghasilkan lebih dari 900 IOPS. Namun, jika batas IOPS maksimum kumpulan sumber daya diatur ke 1500 IOPS, dan total I/O dari semua grup beban kerja yang terkait dengan kumpulan sumber daya melebihi 1500 IOPS, maka I/O dari kueri yang sama mungkin berkurang di bawah batas grup kerja 900 IOPS.
Nilai IOPS dan throughput maksimum yang ditampilkan oleh tampilan sys.dm_user_db_resource_governance bertindak sebagai batas/tutup, bukan sebagai jaminan. Selain itu, tata kelola sumber daya tidak menjamin latensi penyimpanan tertentu. Latensi, IOPS, dan throughput terbaik yang dapat dicapai untuk beban kerja pengguna tertentu tidak hanya tergantung pada batas tata kelola sumber daya I/O, tetapi juga pada campuran ukuran I/O yang digunakan, dan pada kemampuan penyimpanan yang mendasarinya. SQL Database menggunakan operasi I/O yang bervariasi dalam ukuran antara 512 byte dan 4 MB. Untuk tujuan memberlakukan batas IOPS, setiap I/O diperhitungkan terlepas dari ukurannya, kecuali untuk database dengan file data di Azure Storage. Dalam hal ini, I/O yang lebih besar dari 256 KB diperhitungkan sebagai beberapa I/Os 256-KB, untuk menyelaraskan dengan akuntansi I/O Azure Storage.
Untuk database Dasar, Standar, dan Tujuan Umum, yang menggunakan file data di Azure Storage, primary_group_max_io nilai mungkin tidak dapat dicapai jika database tidak memiliki cukup file data untuk secara kumulatif menyediakan jumlah IOPS ini, atau jika data tidak didistribusikan secara merata di seluruh file, atau jika tingkat performa blob yang mendasar membatasi IOPS/throughput di bawah batas tata kelola sumber daya. Demikian pula, dengan operasi I/O log kecil yang dihasilkan oleh penerapan transaksi yang sering, primary_max_log_rate nilainya mungkin tidak dapat dicapai oleh beban kerja karena batas IOPS pada blob Azure Storage yang mendasar. Untuk database yang menggunakan Azure Premium Storage, Azure SQL Database menggunakan gumpalan penyimpanan yang cukup besar untuk mendapatkan IOPS/throughput yang diperlukan, terlepas dari ukuran database. Untuk database yang lebih besar, beberapa file data dibuat untuk meningkatkan kapasitas IOPS/throughput total.
Nilai pemanfaatan sumber daya seperti avg_data_io_percent dan avg_log_write_percent, yang dilaporkan dalam tampilan sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats, dan sys.elastic_pool_resource_stats , dihitung sebagai persentase batas tata kelola sumber daya maksimum. Oleh karena itu, ketika faktor-faktor selain tata kelola sumber daya membatasi IOPS/throughput, mungkin IOPS/throughput terlihat rata dan laten meningkat ketika beban kerja meningkat, meskipun pemanfaatan sumber daya yang dilaporkan tetap di bawah 100%.
Untuk memantau IOPS baca dan tulis, throughput, dan latensi per file database, gunakan fungsi sys.dm_io_virtual_file_stats(). Fungsi ini memunculkan semua I/O terhadap database, termasuk I/O latar belakang yang tidak diperhitungkan terhadap avg_data_io_percent, tetapi menggunakan IOPS dan throughput penyimpanan yang mendasar, dan dapat memengaruhi latensi penyimpanan yang diamati. Fungsi melaporkan latensi tambahan yang dapat diperkenalkan oleh tata kelola sumber daya I/O untuk baca dan tulis, di io_stall_queued_read_ms kolom dan io_stall_queued_write_ms masing-masing.
Tata kelola tingkat log transaksi
Tata kelola tingkat log transaksi adalah proses dalam Azure SQL Database yang digunakan untuk membatasi tingkat menelan tinggi untuk beban kerja seperti sisipan massal, PILIH KE DALAM, dan build indeks. Batas ini dilacak dan diberlakukan pada tingkat subdetik ke tingkat pembuatan rekaman log, membatasi throughput terlepas dari berapa banyak IO yang dapat dikeluarkan terhadap file data. Tingkat pembuatan log transaksi saat ini diskalakan secara linier hingga titik yang bergantung pada perangkat keras dan bergantung pada tingkat layanan.
Laju log diatur sedemikian rugi sehingga dapat dicapai dan dipertahankan dalam berbagai skenario, sementara sistem keseluruhan dapat mempertahankan fungsionalitasnya dengan dampak yang diminimalkan ke beban pengguna. Tata kelola log rate memastikan bahwa pencadangan log transaksi tetap berada dalam SLA pemulihan yang dipublikasikan. Tata kelola ini juga mencegah backlog yang berlebihan pada replika sekunder yang dapat menyebabkan waktu henti yang lebih lama dari yang diharapkan selama failover.
IO fisik aktual untuk file log transaksi tidak diatur atau dibatasi. Ketika catatan log dihasilkan, setiap operasi dievaluasi dan dinilai untuk apakah itu harus ditunda untuk mempertahankan laju log maksimum yang diinginkan (MB/s per detik). Penundaan tidak ditambahkan ketika catatan log dipindahkan ke penyimpanan, melainkan tata kelola laju log diterapkan selama pembuatan laju log itu sendiri.
Tingkat pembuatan log aktual yang diberlakukan pada run time juga dipengaruhi oleh mekanisme umpan balik, untuk sementara mengurangi tingkat log yang diizinkan sehingga sistem dapat stabil. Manajemen ruang file log, menghindari kehabisan kondisi ruang log dan mekanisme replikasi data untuk sementara dapat mengurangi batas sistem secara keseluruhan.
Pembentukan lalu lintas pengatur dimunculkan melalui jenis tunggu berikut (ditampilkan dalam tampilan sys.dm_exec_requestsdan sys.dm_os_wait_stats):
| Jenis Tunggu | Catatan |
|---|---|
LOG_RATE_GOVERNOR |
Pembatasan database |
POOL_LOG_RATE_GOVERNOR |
Pembatasan kumpulan |
INSTANCE_LOG_RATE_GOVERNOR |
Pembatasan tingkat instans |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Kontrol umpan balik, replikasi fisik grup ketersediaan di Premium/Bisnis Kritis tidak mengikuti |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Kontrol umpan balik, membatasi tingkat untuk menghindari kondisi ruang log keluar |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Kontrol umpan balik lokasi geografis, membatasi laju log untuk menghindari latensi data yang tinggi dan tidak tersedianya geo-sekunder |
Saat menemukan batas kecepatan log yang menghambat skalabilitas yang diinginkan, pertimbangkan opsi berikut:
- Tingkatkan skala ke tingkat layanan yang lebih tinggi untuk mendapatkan tingkat log dari tingkat layanan maksimum, atau beralih ke tingkat layanan yang berbeda.
- Untuk perangkat keras yang dioptimalkan memori seri premium dan seri premium, tingkat layanan yang disediakan Hyperscale menyediakan laju log 150 MiB/dtk per database dan 150 MiB/dtk per kumpulan elastis.
- Untuk seri perangkat keras lainnya, tingkat layanan Hyperscale menyediakan laju log 100 MiB/dtk per database dan 125 MiB/dtk per kumpulan elastis.
- Jika data yang dimuat bersifat sementara, seperti data penahapan dalam proses ETL, data tersebut dapat dimuat ke
tempdb(yang dicatat secara minimal). - Untuk skenario analitik, muat ke dalam tabel columnstore dalam kluster, atau tabel dengan indeks yang menggunakan pemadatan data. Hal tersebut untuk mengurangi laju log yang diperlukan. Teknik ini memang meningkatkan pemanfaatan CPU dan hanya berlaku untuk himpunan data yang mendapatkan keuntungan dari indeks penyimpan kolom dalam kluster atau pemadatan data.
Tata kelola ruang penyimpanan
Di tingkat layanan Premium dan Bisnis Penting, data pelanggan termasuk file data, file log transaksi, dan tempdb file, disimpan di penyimpanan SSD lokal komputer yang menghosting database atau kumpulan elastis. Penyimpanan SSD lokal memberikan throughput dan IOPS tinggi, serta latensi I/O yang rendah. Selain data pelanggan, penyimpanan lokal digunakan untuk sistem operasi, perangkat lunak manajemen, data pemantauan dan log, dan file lain yang diperlukan untuk operasi sistem.
Ukuran penyimpanan lokal terbatas dan tergantung pada kemampuan perangkat keras, yang menentukan batas penyimpanan lokal maksimum, atau set penyimpanan lokal yang disisihkan untuk data pelanggan. Batas ini diatur untuk memaksimalkan penyimpanan data pelanggan, sekaligus memastikan pengoperasian sistem yang aman dan andal. Untuk menemukan nilai penyimpanan lokal maksimum untuk setiap tujuan layanan, lihat dokumentasi batas sumber daya untuk database tunggal dan kumpulan elastis.
Anda juga dapat menemukan nilai ini, dan jumlah penyimpanan lokal yang saat ini digunakan oleh database atau kumpulan elastis tertentu, menggunakan kueri berikut:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Kolom | Deskripsi |
|---|---|
server_name |
Nama server logika |
database_name |
Nama database |
slo_name |
Nama tujuan layanan, termasuk pembuatan perangkat keras |
user_data_directory_space_quota_mb |
Penyimpanan lokal maksimum,dalam MB |
user_data_directory_space_usage_mb |
Penggunaan penyimpanan lokal saat ini berdasarkan file data, file log transaksi, dan file tempdb, dalam MB. Diperbarui setiap lima menit. |
Kueri ini harus dijalankan dalam database pengguna, bukan di master database. Untuk kumpulan elastis, kueri dapat dieksekusi dalam database apa pun di kumpulan. Nilai yang dilaporkan berlaku untuk seluruh kumpulan.
Penting
Di tingkat layanan Premium dan Penting Bagi Bisnis, jika beban kerja mencoba meningkatkan penggunaan penyimpanan lokal gabungan oleh file data, file log transaksi, dan file tempdb melebihi batas penyimpanan lokal maksimum, kesalahan kehabisan ruang akan terjadi. Ini akan terjadi bahkan jika ruang yang digunakan dalam file database belum mencapai ukuran maksimum file.
Penyimpanan SSD lokal juga digunakan oleh database di tingkat layanan selain Premium dan Business Critical untuk tempdb database dan cache Hyperscale RBPEX. Saat database dibuat, dihapus, dan bertambah atau berkurang ukurannya, total penggunaan penyimpanan lokal pada mesin berfluktuasi dari waktu ke waktu. Jika sistem mendeteksi bahwa penyimpanan lokal yang tersedia pada komputer rendah, dan database atau kumpulan elastis berisiko kehabisan ruang, itu memindahkan database atau kumpulan elastis ke komputer yang berbeda dengan penyimpanan lokal yang memadai yang tersedia.
Langkah ini terjadi dengan cara online, mirip dengan operasi penskalaan database, dan memiliki dampak yang sama, termasuk kegagalan singkat (detik) di akhir operasi. Failover ini mengakhiri koneksi terbuka dan mengembalikan transaksi, yang berpotensi memengaruhi aplikasi menggunakan database pada saat itu.
Karena semua data disalin ke volume penyimpanan lokal pada komputer yang berbeda, memindahkan database yang lebih besar di tingkat layanan Premium dan Business Critical dapat memerlukan waktu yang cukup lama. Selama waktu tersebut, jika penggunaan ruang lokal oleh database atau kumpulan elastis, atau oleh database tempdb tumbuh dengan cepat, risiko kehabisan ruang meningkat. Sistem tersebut memulai pergerakan database dengan cara yang seimbang untuk mengecilkan kesalahan di luar ruang saat menghindari kegagalan yang tidak diperlukan.
tempdb Ukuran
Batas ukuran untuk tempdb di Azure SQL Database bergantung pada model pembelian dan penyebaran.
Untuk mempelajari selengkapnya, tinjau batas ukuran tempdb untuk:
- model pembelian vCore: database tunggal, database kumpulan
- model pembelian DTU: database tunggal, database kumpulan.
Perangkat keras yang tersedia sebelumnya
Bagian ini mencakup detail tentang perangkat keras yang tersedia sebelumnya.
- Perangkat keras Gen4 telah dihentikan dan tidak tersedia untuk provisi, peningkatan, atau penurunan skala. Migrasikan database Anda ke pembuatan perangkat keras yang didukung untuk berbagai vCore dan skalabilitas penyimpanan yang lebih luas, jaringan terakselerasi, performa IO terbaik, dan latensi minimal. Untuk informasi selengkapnya, lihat Dukungan telah berakhir untuk perangkat keras Gen 4 di Azure SQL Database.
Anda dapat menggunakan Azure Resource Graph Explorer untuk mengidentifikasi semua sumber daya Azure SQL Database yang saat ini menggunakan perangkat keras Gen4, atau Anda dapat memeriksa perangkat keras yang digunakan oleh sumber daya untuk server logis tertentu di portal Azure.
Anda harus memiliki setidaknya read izin ke objek Azure atau grup objek untuk melihat hasil di Azure Resource Graph Explorer.
Untuk menggunakan Resource Graph Explorer untuk mengidentifikasi sumber daya Azure SQL yang masih menggunakan perangkat keras Gen4, ikuti langkah-langkah berikut:
Buka portal Azure.
Cari
Resource graphdi kotak pencarian, dan pilih layanan Resource Graph Explorer dari hasil pencarian.Di jendela kueri, ketik kueri berikut lalu pilih Jalankan kueri:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Panel Hasil menampilkan semua sumber daya yang saat ini disebarkan di Azure yang menggunakan perangkat keras Gen4.
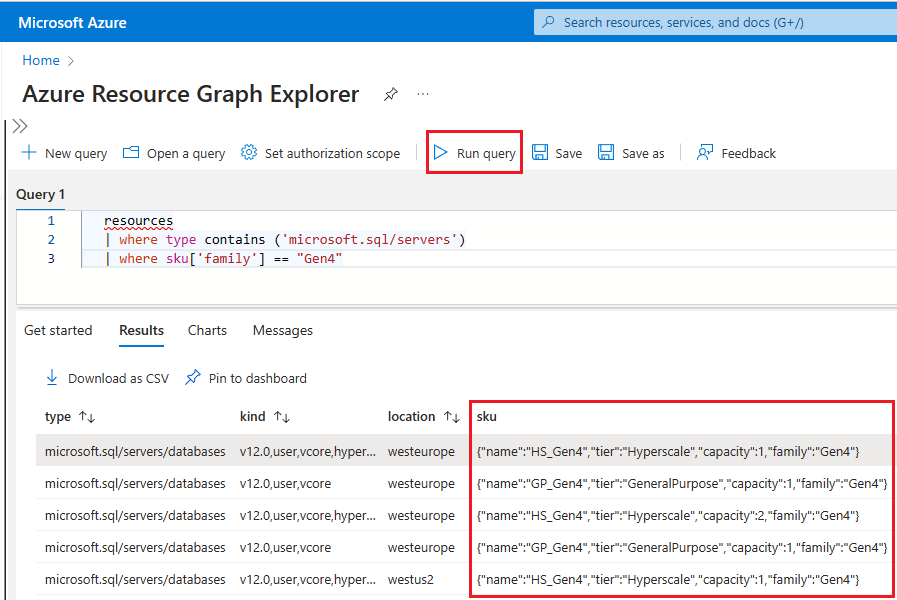
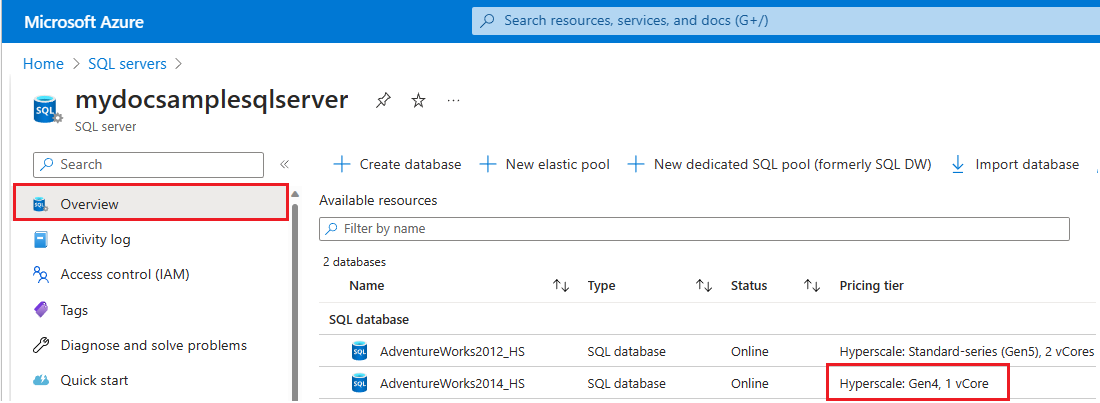
Untuk memeriksa perangkat keras yang digunakan oleh sumber daya untuk server logis tertentu di Azure, ikuti langkah-langkah berikut:
- Buka portal Azure.
- Cari
SQL serversdi kotak pencarian dan pilih server SQL dari hasil pencarian untuk membuka halaman server SQL dan menampilkan semua server untuk langganan yang dipilih. - Pilih server yang menarik untuk membuka halaman Gambaran Umum untuk server.
- Gulir ke bawah ke sumber daya yang tersedia dan periksa kolom Tingkat harga untuk sumber daya yang menggunakan perangkat keras gen4.
Untuk memigrasikan sumber daya ke perangkat keras seri standar, tinjau Mengubah perangkat keras.
Konten terkait
- Untuk informasi selengkapnya tentang batasan Azure umum, lihat Langganan Azure dan batas layanan, kuota, dan hambatan.
- Untuk informasi selengkapnya tentang DTU dan eDTU, lihat Apa yang dimaksud DTU dan eDTU?.
- Untuk informasi tentang batas ukuran
tempdb, lihat database vCore tunggal, database vCore yang dikumpulkan, database DTU tunggal, dan database DTU yang dikumpulkan.