Gambaran umum kelangsungan bisnis dengan Azure SQL Managed Instance
Berlaku untuk: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Artikel ini memberikan gambaran umum tentang kemampuan kelangsungan bisnis dan pemulihan bencana Azure SQL Managed Instance, yang menjelaskan opsi dan rekomendasi untuk memulihkan dari peristiwa mengganggu yang dapat menyebabkan kehilangan data atau menyebabkan instans dan aplikasi Anda menjadi tidak tersedia. Pelajari apa yang harus dilakukan saat kesalahan pengguna atau aplikasi memengaruhi integritas data, zona atau wilayah ketersediaan Azure mengalami pemadaman, atau aplikasi Anda memerlukan pemeliharaan.
Gambaran Umum
Kelangsungan bisnis di Azure SQL Managed Instance mengacu pada mekanisme, kebijakan, dan prosedur yang memungkinkan bisnis Anda untuk terus beroperasi dalam menghadapi gangguan dengan menyediakan ketersediaan, ketersediaan tinggi, dan pemulihan bencana.
Dalam kebanyakan kasus, SQL Managed Instance menangani peristiwa mengganggu yang mungkin terjadi di lingkungan cloud dan menjaga aplikasi dan proses bisnis Anda tetap berjalan. Namun, ada beberapa peristiwa mengganggu di mana mitigasi mungkin memakan waktu, seperti:
- Pengguna secara tidak sengaja menghapus atau memperbarui baris dalam tabel.
- Penyerang berbahaya berhasil menghapus data atau menghilangkan database.
- Peristiwa bencana alam bencana menghancurkan pusat data atau zona ketersediaan atau wilayah.
- Pusat data langka, zona ketersediaan, atau pemadaman di seluruh wilayah yang disebabkan oleh perubahan konfigurasi, bug perangkat lunak, atau kegagalan komponen perangkat keras.
Ketersediaan
Azure SQL Managed Instance dilengkapi dengan janji ketahanan dan keandalan inti yang melindunginya dari kegagalan perangkat lunak atau perangkat keras. Pencadangan database diotomatisasi untuk melindungi data Anda dari kerusakan atau penghapusan yang tidak disengaja. Sebagai Platform-as-a-service (PaaS), layanan Azure SQL Managed Instance menyediakan ketersediaan sebagai fitur off-the-shelf dengan SLA ketersediaan terkemuka di industri sebesar 99,99%.
Ketersediaan Tinggi
Untuk mencapai ketersediaan tinggi di lingkungan cloud Azure, aktifkan redundansi zona sehingga instans menggunakan zona ketersediaan untuk memastikan ketahanan terhadap kegagalan zonal. Banyak wilayah Azure menyediakan zona ketersediaan, yang merupakan grup pusat data yang dipisahkan dalam wilayah yang memiliki infrastruktur daya, pendinginan, dan jaringan independen. Zona ketersediaan dirancang untuk menyediakan layanan regional, kapasitas, dan ketersediaan tinggi di zona yang tersisa jika satu zona mengalami pemadaman. Dengan mengaktifkan redundansi zona, instans tahan terhadap kegagalan perangkat keras dan perangkat lunak zonal dan pemulihannya transparan terhadap aplikasi. Ketika ketersediaan tinggi diaktifkan, layanan Azure SQL Managed Instance dapat memberikan SLA ketersediaan yang lebih tinggi sebesar 99,99%.
Pemulihan dari bencana
Untuk mencapai ketersediaan dan redundansi yang lebih tinggi di seluruh wilayah, Anda dapat memungkinkan kemampuan pemulihan bencana untuk memulihkan instans dengan cepat dari kegagalan regional bencana. Opsi untuk pemulihan bencana dengan Azure SQL Managed Instance adalah:
- Grup failover memungkinkan sinkronisasi berkelanjutan antara instans primer dan sekunder. Grup failover menyediakan titik akhir pendengar baca-tulis dan baca-saja yang tetap tidak berubah sehingga memperbarui string koneksi aplikasi setelah failover tidak diperlukan.
- Pemulihan geografis memungkinkan Anda memulihkan dari pemadaman regional dengan memulihkan dari cadangan yang direplikasi secara geografis saat Anda tidak dapat mengakses database Anda di wilayah utama dengan membuat database baru pada instans yang ada di wilayah Azure mana pun.
Fitur yang memberikan kelangsungan bisnis
Misalnya, ada empat skenario gangguan potensial utama. Tabel berikut mencantumkan fitur kelangsungan bisnis SQL Managed Instance yang dapat Anda gunakan untuk mengurangi skenario potensi gangguan bisnis:
| Skenario gangguan bisnis | Fitur kelangsungan bisnis |
|---|---|
| Kegagalan perangkat keras atau perangkat lunak lokal yang memengaruhi simpul database. | Untuk mengurangi kegagalan perangkat keras dan perangkat lunak lokal, SQL Managed Instance mencakup arsitektur ketersediaan, yang menjamin pemulihan otomatis dari kegagalan ini dengan SLA ketersediaan hingga 99,99%. |
| Kerusakan atau penghapusan data biasanya disebabkan oleh bug aplikasi atau kesalahan manusia. Kegagalan tersebut khusus aplikasi dan biasanya tidak dapat dideteksi oleh layanan. | Untuk melindungi bisnis Anda dari kehilangan data, SQL Managed Instance secara otomatis membuat cadangan database lengkap setiap minggu, cadangan database diferensial setiap 12 atau 24 jam, dan pencadangan log transaksi setiap 5 - 10 menit. Secara default, cadangan disimpan dalam penyimpanan geo-redundan selama tujuh hari, dan mendukung periode retensi cadangan yang dapat dikonfigurasi untuk pemulihan titik waktu hingga 35 hari. Anda dapat memulihkan database yang dihapus ke titik saat database dihapus jika instans belum dihapus, atau jika Anda telah mengonfigurasi retensi jangka panjang. |
| Pemadaman pusat data atau zona ketersediaan yang jarang terjadi, mungkin disebabkan oleh peristiwa bencana alam, perubahan konfigurasi, bug perangkat lunak, atau kegagalan komponen perangkat keras. | Untuk mengurangi pemadaman tingkat pusat data atau zona ketersediaan, aktifkan redundansi zona untuk SQL Managed Instance untuk menggunakan Zona Ketersediaan Azure dan berikan redundansi di beberapa zona fisik dalam wilayah Azure. Mengaktifkan redundansi zona memastikan instans terkelola tahan terhadap kegagalan zonal dengan SLA ketersediaan tinggi hingga 99,99%. |
| Pemadaman wilayah langka berdampak pada semua zona ketersediaan dan pusat data yang terdiri darinya, mungkin disebabkan oleh peristiwa bencana alam bencana. | Untuk mengurangi pemadaman di seluruh wilayah, aktifkan pemulihan bencana menggunakan salah satu opsi: - Sinkronisasi data berkelanjutan dengan grup failover ke replika di wilayah sekunder yang digunakan untuk failover. - Mengatur redundansi penyimpanan cadangan ke penyimpanan cadangan geo-redundan untuk menggunakan pemulihan geografis. |
RTO dan RPO
Saat Anda mengembangkan rencana kelangsungan bisnis Anda, pahami waktu maksimum yang dapat diterima sebelum aplikasi sepenuhnya pulih setelah peristiwa yang mengganggu. Waktu yang diperlukan aplikasi untuk sepenuhnya pulih dikenal sebagai Tujuan Waktu Pemulihan (RTO). Pahami juga periode maksimum pembaruan data terbaru (interval waktu) aplikasi dapat mentolerir kehilangan saat pulih dari peristiwa disruptif yang tidak diencana. Potensi kehilangan data dikenal sebagai Tujuan Titik Pemulihan (RPO).
Tabel berikut membandingkan RPO dan RTO dari setiap opsi kelangsungan bisnis:
| Opsi kelangsungan bisnis | RTO (waktu henti) | RPO (kehilangan data) |
|---|---|---|
| Ketersediaan Tinggi (Mengaktifkan redundansi zona) |
Biasanya kurang dari 30 detik | 0 |
| Pemulihan Bencana (Mengaktifkan grup failover) |
1 jam | 5 detik (Tergantung pada perubahan data sebelum peristiwa gangguan yang belum direplikasi) |
| Pemulihan Bencana (Menggunakan pemulihan geografis) |
12 jam | 1 jam |
Daftar periksa kelangsungan bisnis
Untuk rekomendasi preskriptif guna memaksimalkan ketersediaan dan mencapai kelangsungan bisnis yang lebih tinggi, lihat:
Memulihkan database dalam wilayah Azure yang sama
Anda bisa menggunakan pencadangan database otomatis untuk memulihkan database ke titik waktu di masa lalu. Dengan cara ini Anda dapat memulihkan dari kerusakan data yang disebabkan oleh kesalahan manusia. Pemulihan titik waktu (PITR) memungkinkan Anda membuat database baru ke instans yang sama, atau instans yang berbeda, yang mewakili status data sebelum peristiwa yang rusak. Operasi pemulihan adalah ukuran operasi data yang juga bergantung pada beban kerja instans target saat ini. Mungkin perlu waktu lebih lama untuk memulihkan database yang sangat besar atau sangat aktif. Untuk informasi selengkapnya tentang waktu pemulihan, lihat waktu pemulihan database.
Jika periode retensi cadangan maksimum yang didukung untuk pemulihan titik waktu (PITR) tidak cukup untuk aplikasi Anda, Anda dapat memperluasnya dengan mengonfigurasi kebijakan retensi jangka panjang (LTR) untuk database. Untuk mengetahui informasi selengkapnya, lihat Retensi cadangan jangka panjang.
Memulihkan database ke instans yang sudah ada
Meskipun jarang, pusat data Azure dapat mengalami pemadaman. Ketika pemadaman terjadi, itu menyebabkan gangguan bisnis yang mungkin hanya berlangsung beberapa menit atau mungkin berlangsung selama berjam-jam.
- Salah satu opsinya adalah menunggu instans Anda kembali online ketika pemadaman pusat data berakhir. Ini berfungsi untuk aplikasi yang mampu membuat database mereka offline. Misalnya, proyek pengembangan atau uji coba gratis yang tidak perlu Anda kerjakan terus-menerus. Ketika pusat data mengalami pemadaman, Anda tidak tahu berapa lama pemadaman mungkin berlangsung, jadi opsi ini hanya berfungsi jika Anda tidak memerlukan database Anda untuk beberapa waktu.
- Jika Anda menggunakan penyimpanan geo-redundan (GRS), atau geo-zone-redundant (GZRS), opsi lain adalah memulihkan database ke instans terkelola SQL apa pun di wilayah Azure mana pun menggunakan cadangan database geo-redundan (pemulihan geografis ). Pemulihan geografis menggunakan cadangan geo-redundan sebagai sumbernya dan dapat digunakan untuk memulihkan database ke titik waktu terakhir yang tersedia, bahkan jika database atau pusat data tidak dapat diakses karena pemadaman. Cadangan yang tersedia dapat ditemukan di wilayah yang dipasangkan.
- Terakhir, Anda dapat dengan cepat pulih dari pemadaman jika Anda telah mengonfigurasi geo-sekunder menggunakan grup failover untuk instans Anda, menggunakan pelanggan (disarankan) atau failover yang dikelola Microsoft. Meskipun failover itu sendiri hanya membutuhkan waktu beberapa detik, layanan membutuhkan waktu setidaknya 1 jam untuk mengaktifkan geo-failover yang dikelola Microsoft, jika dikonfigurasi. Ini diperlukan untuk memastikan failover dibenarkan oleh skala pemadaman. Selain itu, failover dapat mengakibatkan hilangnya data yang baru saja berubah karena sifat replikasi asinkron antara wilayah yang dipasangkan.
Saat Anda mengembangkan rencana kelangsungan bisnis, Anda perlu memahami waktu maksimum yang dapat diterima sebelum aplikasi sepenuhnya pulih setelah peristiwa yang mengganggu. Waktu yang diperlukan aplikasi untuk sepenuhnya pulih dikenal sebagai Tujuan Waktu Pemulihan (RTO). Anda juga perlu memahami periode maksimum pembaruan data terbaru (interval waktu) yang dapat ditoleransi oleh aplikasi saat memulihkan dari peristiwa mengganggu yang tidak direncanakan. Potensi kehilangan data dikenal sebagai Tujuan Titik Pemulihan (RPO).
Metode pemulihan yang berbeda menawarkan tingkat RPO dan RTO yang berbeda. Anda dapat memilih metode pemulihan tertentu, atau menggunakan kombinasi metode untuk mencapai pemulihan aplikasi penuh.
Gunakan grup failover jika aplikasi Anda memenuhi salah satu kriteria berikut:
- Merupakan misi penting.
- Memiliki perjanjian tingkat layanan (SLA) yang tidak memungkinkan selama 12 jam atau lebih waktu henti.
- Waktu henti dapat mengakibatkan tanggung jawab keuangan.
- Memiliki tingkat perubahan data yang tinggi dan kehilangan data 1 jam tidak dapat diterima.
- Biaya tambahan geo-replikasi aktif lebih rendah daripada potensi kewajiban finansial dan kerugian terkait bisnis.
Anda dapat memilih untuk menggunakan kombinasi pencadangan database dan grup failover tergantung pada persyaratan aplikasi Anda.
Bagian berikut ini memberikan gambaran umum tentang langkah-langkah untuk memulihkan menggunakan pencadangan database atau grup failover.
Bersiap untuk pemadaman
Terlepas dari fitur kelangsungan bisnis yang Anda gunakan, Anda harus:
- Identifikasi dan siapkan instans target, termasuk aturan firewall IP jaringan, login, dan
masterizin tingkat database. - Menentukan cara mengalihkan klien dan aplikasi klien ke instans baru
- Mendokumentasikan dependensi lain, seperti pengaturan dan pemberitahuan pengauditan
Jika Anda tidak mempersiapkan dengan benar, membuat aplikasi Anda online setelah failover atau pemulihan database membutuhkan waktu tambahan, dan kemungkinan juga memerlukan pemecahan masalah pada saat stres - kombinasi yang buruk.
Failover ke instans sekunder yang direplikasi secara geografis
Jika Anda menggunakan grup failover sebagai mekanisme pemulihan, Anda dapat mengonfigurasi kebijakan failover otomatis. Setelah dimulai, failover menyebabkan instans sekunder menjadi primer baru, siap untuk merekam transaksi baru dan menanggapi kueri - dengan kehilangan data minimal untuk data yang belum direplikasi.
Catatan
Ketika pusat data kembali online, primer lama secara otomatis terhubung kembali ke primer baru untuk menjadi instans sekunder. Jika Anda perlu memindahkan kembali database primer ke wilayah asal, Anda dapat memulai kegagalan yang direncanakan secara manual (failback).
Melakukan pemulihan geografis
Jika Anda menggunakan cadangan otomatis dengan penyimpanan geo-redundan (opsi penyimpanan default saat membuat instans), Anda dapat memulihkan database menggunakan pemulihan geografis. Pemulihan biasanya berlangsung dalam 12 jam - dengan kehilangan data hingga satu jam ditentukan oleh ketika cadangan log terakhir diambil dan direplikasi. Hingga pemulihan selesai, database tidak dapat mencatat transaksi apa pun atau menanggapi kueri apa pun. Catatan, geo-pemulihan hanya memulihkan database ke titik waktu terakhir yang tersedia.
Catatan
Jika pusat data kembali online sebelum Anda mengalihkan aplikasi Anda ke database yang dipulihkan, Anda dapat membatalkan pemulihan.
Melakukan tugas pascakegagalan/pemulihan
Setelah pemulihan dari salah satu mekanisme pemulihan, Anda harus melakukan tugas tambahan berikut sebelum pengguna dan aplikasi Anda dicadangkan dan dijalankan:
- Alihkan klien dan aplikasi klien ke instans baru dan database yang telah dipulihkan.
- Pastikan aturan firewall IP jaringan yang sesuai tersedia untuk disambungkan oleh pengguna.
- Pastikan login dan
masterizin tingkat database yang sesuai ada (atau gunakan pengguna mandiri). - Konfigurasikan pengauditan, sebagaimana mestinya.
- Konfigurasikan pemberitahuan, sebagaimana mestinya.
Catatan
Jika Anda menggunakan grup failover dan terhubung ke instans menggunakan pendengar baca-tulis, pengalihan setelah failover akan terjadi secara otomatis dan transparan ke aplikasi.
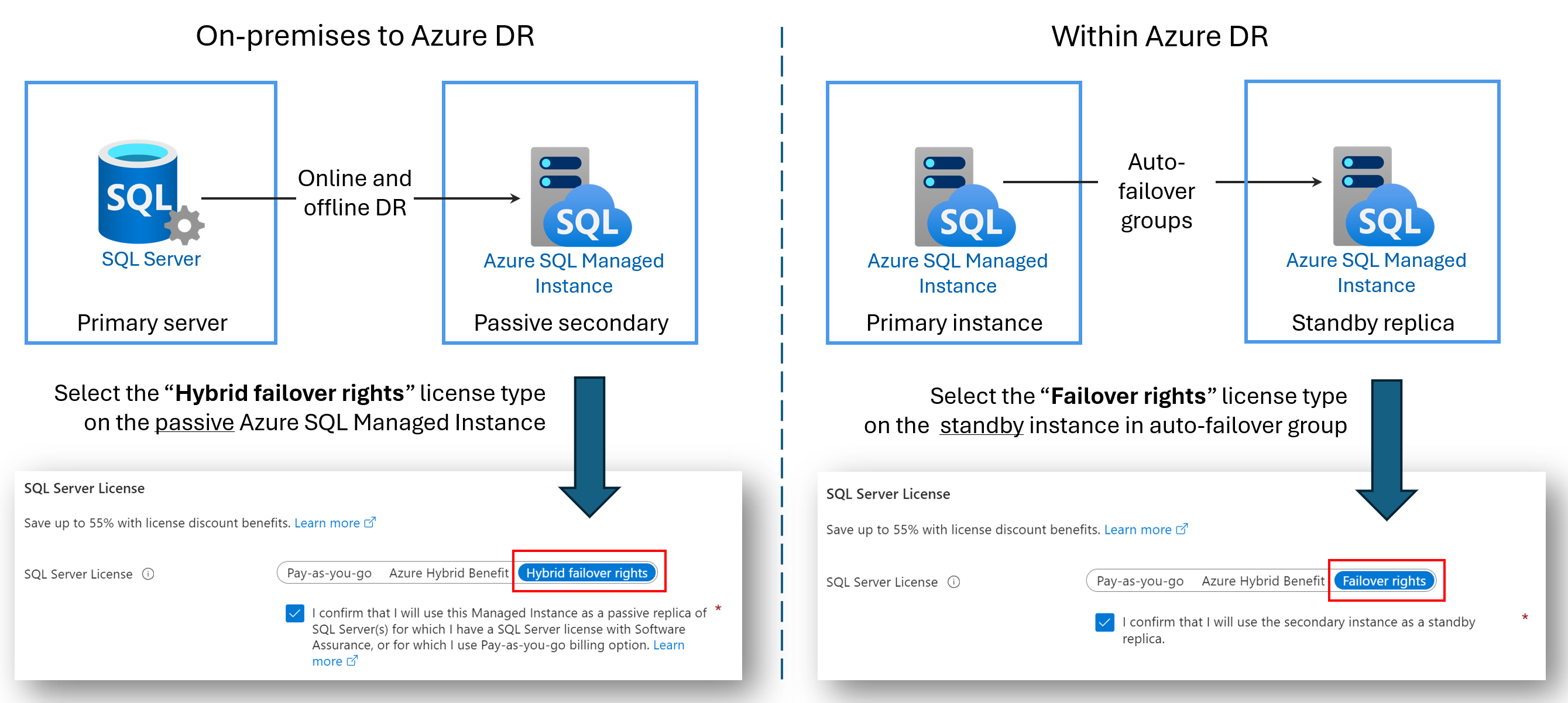
Replika DR bebas lisensi
Anda dapat menghemat biaya lisensi dengan mengonfigurasi Azure SQL Managed Instance sekunder hanya untuk pemulihan bencana (DR). Manfaat ini tersedia jika Anda menggunakan grup failover antara dua instans terkelola SQL, atau Anda telah mengonfigurasi tautan hibrid antara SQL Server dan Azure SQL Managed Instance. Selama instans sekunder tidak memiliki beban kerja baca atau tulis di atasnya dan hanya siaga DR pasif, Anda tidak dikenakan biaya lisensi vCore yang digunakan oleh instans sekunder.
Saat Anda menunjuk instans sekunder hanya untuk pemulihan bencana, dan tidak ada beban kerja baca atau tulis yang berjalan pada instans, Microsoft memberi Anda jumlah vCore yang dilisensikan ke instans utama tanpa biaya tambahan di bawah manfaat hak failover. Anda masih ditagih untuk komputasi dan penyimpanan yang digunakan instans sekunder. Untuk syarat dan ketentuan yang tepat dari manfaat hak failover Hibrid, lihat ketentuan lisensi SQL Server secara online di bagian "SQL Server – Fail-over Rights" .
Nama untuk manfaat tergantung pada skenario Anda:
- Hak failover hibrid untuk replika pasif: Saat Mengonfigurasi tautan antara SQL Server dan Azure SQL Managed Instance, Anda dapat menggunakan manfaat hak failover Hibrid untuk menghemat biaya lisensi vCore untuk replika sekunder pasif.
- Hak failover untuk replika siaga: Saat Mengonfigurasi grup failover antara dua instans terkelola, Anda dapat menggunakan manfaat Hak failover untuk menghemat biaya lisensi vCore untuk replika sekunder siaga.
Diagram berikut menunjukkan manfaat untuk setiap skenario:
Langkah berikutnya
Untuk mempelajari selengkapnya tentang fitur kelangsungan bisnis, lihat Pencadangan otomatis, dan grup failover. Untuk pemulihan bencana, lihat memulihkan database dan mengaktifkan redundansi zona untuk Azure SQL Managed Instance.