Mengelola ruang file untuk database di Azure SQL Managed Instance
Berlaku untuk: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Artikel ini membahas cara memantau dan mengelola file dalam database di Azure SQL Managed Instance. Kami meninjau cara memantau ukuran file database, menyusutkan log transaksi, memperbesar file log transaksi, dan mengontrol pertumbuhan file log transaksi.
Artikel ini berlaku untuk Azure SQL Managed Instance. Meskipun sangat mirip, untuk informasi tentang mengelola ukuran file log transaksi di SQL Server, lihat Mengelola ukuran file log transaksi.
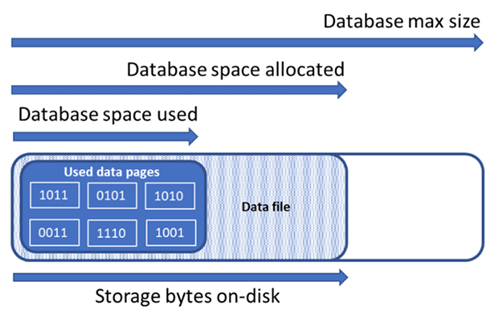
Memahami jenis ruang penyimpanan untuk database
Memahami jumlah ruang penyimpanan berikut ini penting untuk mengelola ruang file database.
| Kuantitas database | Definisi | Komentar |
|---|---|---|
| Ruang data yang digunakan | Jumlah ruang yang digunakan untuk menyimpan data database. | Umumnya, ruang yang digunakan meningkat (berkurang) pada sisipan (penghapusan). Dalam beberapa kasus, ruang yang digunakan tidak berubah pada sisipan atau penghapusan tergantung pada jumlah dan pola data yang terlibat dalam operasi dan fragmentasi apa pun. Misalnya, menghapus satu baris dari setiap halaman data tidak selalu mengurangi ruang yang digunakan. |
| Ruang data dialokasikan | Jumlah ruang file yang diformat disediakan untuk menyimpan data database. | Jumlah ruang yang dialokasikan tumbuh secara otomatis, tetapi tidak pernah berkurang setelah penghapusan. Perilaku ini memastikan bahwa sisipan di masa depan lebih cepat karena ruang tidak perlu diformat ulang. |
| Ruang data dialokasikan tetapi tidak digunakan | Perbedaan antara jumlah ruang data yang dialokasikan dan ruang data yang digunakan. | Kuantitas ini menunjukkan jumlah maksimum ruang kosong yang dapat direklamasi dengan menyusutkan file data database. |
| Ukuran maksimal data | Jumlah ruang maksimum yang dapat digunakan untuk menyimpan data database. | Jumlah ruang data yang dialokasikan tidak dapat tumbuh melebihi ukuran maksimal data. |
Diagram berikut ini mengilustrasikan hubungan antara berbagai jenis ruang penyimpanan untuk database.
Mengkueri database tunggal untuk informasi ruang file
Gunakan kueri berikut pada sys.database_files untuk mengembalikan jumlah ruang file database yang dialokasikan dan jumlah ruang yang tidak digunakan yang dialokasikan. Unit hasil kueri dalam MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Memantau penggunaan ruang log
Pantau penggunaan ruang log dengan menggunakan sys.dm_db_log_space_usage. DMV ini mengembalikan informasi tentang jumlah ruang log yang saat ini digunakan, dan menunjukkan kapan log transaksi membutuhkan pemotongan.
Untuk informasi tentang ukuran file log saat ini, ukuran maksimumnya, dan opsi autogrow untuk file, Anda juga dapat menggunakan kolom , , max_sizedan untuk file log tersebut sizedi sys.database_filesgrowth.
Metrik ruang penyimpanan yang ditampilkan di API metrik berbasis Azure Resource Manager hanya mengukur ukuran halaman data yang digunakan. Misalnya, lihat Get-metrics PowerShell.
Menyusutkan ukuran file log
Untuk mengurangi ukuran fisik file log fisik dengan menghapus ruang yang tidak digunakan, susutkan file log. Penyusutan hanya membuat perbedaan ketika file log transaksi berisi ruang yang tidak digunakan. Jika file log penuh, kemungkinan karena transaksi terbuka, selidiki apa yang mencegah pemotongan log transaksi.
Perhatian
Operasi penyusutan tidak boleh dianggap sebagai operasi pemeliharaan rutin. File data dan log yang bertambah karena operasi bisnis yang teratur dan berulang tidak memerlukan operasi penyusutan. Perintah penyusutan berdampak pada performa database saat berjalan, dan jika memungkinkan harus dijalankan selama periode penggunaan rendah. Tidak disarankan untuk menyusutkan file data jika beban kerja aplikasi reguler akan menyebabkan file membesar lagi ke ukuran yang sama yang dialokasikan.
Waspadai potensi dampak performa negatif dari menyusutnya file database, lihat Pemeliharaan indeks setelah menyusut. Dalam kasus yang jarang terjadi, operasi penyusutan dapat dipengaruhi oleh pencadangan database otomatis. Jika perlu, coba lagi operasi penyusutan.
Sebelum menyusutkan log transaksi, ingatlah Faktor-faktor yang dapat menunda pemotongan log. Jika ruang penyimpanan diperlukan lagi setelah log menyusut, log transaksi akan tumbuh lagi dan dengan melakukan itu, memperkenalkan overhead performa selama operasi pertumbuhan log. Untuk informasi selengkapnya, lihat Rekomendasi.
Anda hanya dapat menyusutkan file log saat database online, dan setidaknya satu file log virtual (VLF) gratis. Dalam beberapa kasus, menyusutkan log mungkin tidak dimungkinkan sampai setelah pemotongan log berikutnya.
Faktor-faktor, seperti transaksi yang berjalan lama, dapat menjaga VLF tetap aktif untuk jangka waktu yang lama, dapat membatasi penyusutan log, atau bahkan mencegah log menyusut sama sekali. Untuk informasi, lihat Faktor-faktor yang dapat menunda pemotongan log.
Menyusutkan file log akan menghapus satu atau beberapa VLF yang tidak memiliki bagian dari log logis (yaitu, VLF yang tidak aktif). Saat Anda menyusutkan file log transaksi, VLF yang tidak aktif dihapus dari akhir file log untuk mengurangi log menjadi sekitar ukuran target.
Untuk informasi selengkapnya tentang operasi penyusutan, tinjau hal berikut:
Menyusutkan file log (tanpa menyusutkan file database)
Memantau peristiwa penyusutan file log
- Kelas Peristiwa Penyusutan Otomatis File Log.
Memantau ruang log
sys.database_files (Transact-SQL) (Lihat
sizekolom , ,max_sizedangrowthuntuk file log atau file.)
Pemeliharaan indeks setelah penyusutan
Setelah operasi penyusutan selesai terhadap file data, indeks dapat menjadi terfragmentasi. Hal ini mengurangi efektivitas optimisasi performa untuk beban kerja tertentu, seperti kueri yang menggunakan pemindaian berukuran besar. Jika penurunan performa terjadi setelah operasi penyusutan selesai, pertimbangkan pemeliharaan indeks untuk membangun kembali indeks. Perlu diingat bahwa pembangunan kembali indeks memerlukan ruang kosong dalam database, dan karenanya dapat menyebabkan ruang yang dialokasikan meningkat, menangkal efek penyusutan.
Untuk informasi lebih lanjut terkait pemeliharaan indeks, lihat Mengoptimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya.
Mengevaluasi kerapatan halaman indeks
Jika memotong file data tidak menghasilkan pengurangan ruang yang cukup dalam ruang yang dialokasikan, Anda mungkin memutuskan untuk menyusutkan file data database untuk mengklaim kembali ruang yang tidak digunakan dari file-file tersebut. Namun, sebagai langkah opsional tetapi disarankan, Anda harus menentukan rata-rata kerapatan halaman untuk indeks dalam database terlebih dahulu. Untuk data dalam jumlah sama, penyusutan akan lebih cepat selesai jika kerapatan halaman tinggi, karena harus memindahkan lebih sedikit halaman. Jika kerapatan halaman rendah untuk beberapa indeks, pertimbangkan untuk melakukan pemeliharaan pada indeks ini guna meningkatkan kepadatan halaman sebelum menyusutkan file data. Hal ini juga akan membuat penyusutan menghasilkan pengurangan yang lebih dalam di ruang penyimpanan yang dialokasikan.
Untuk menentukan kerapatan halaman untuk semua indeks dalam database, gunakan kueri berikut. Kerapatan halaman dilaporkan dalam kolom avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Jika ada indeks dengan jumlah halaman tinggi yang memiliki kerapatan halaman yang lebih rendah dari 60-70%, pertimbangkan untuk menyusun ulang atau menata ulang indeks ini sebelum menyusutkan file data.
Catatan
Untuk database yang lebih besar, kueri untuk menentukan kepadatan halaman dapat memakan waktu lama (jam) untuk diselesaikan. Selain itu, menyusun ulang atau menata ulang indeks yang besar juga memerlukan waktu dan penggunaan sumber daya yang signifikan. Terdapat pertukaran kondisi antara menghabiskan waktu tambahan untuk meningkatkan kepadatan halaman di satu sisi, dan mengurangi durasi penyusutan serta mencapai penghematan ruang yang lebih tinggi di sisi yang lain.
Jika ada beberapa indeks dengan kepadatan halaman rendah, Anda mungkin dapat membangunnya kembali secara paralel pada beberapa sesi database untuk mempercepat proses. Namun, pastikan Anda tidak mendekati batas sumber daya database dengan melakukannya, dan meninggalkan headroom sumber daya yang memadai untuk beban kerja aplikasi. Pantau konsumsi sumber daya (CPU, Data IO, Log IO) di portal Microsoft Azure atau gunakan tampilan sys.dm_db_resource_stats dan mulai penyusunan ulang paralel tambahan hanya jika penggunaan sumber daya pada setiap dimensi ini tetap lebih rendah dari 100%. Jika pemanfaatan CPU, IO Data, atau IO Log berada di 100%, Anda dapat meningkatkan skala database untuk memiliki lebih banyak inti CPU dan meningkatkan throughput IO, memungkinkan pembangunan kembali paralel tambahan untuk menyelesaikan proses lebih cepat.
Contoh perintah pembangunan ulang indeks
Berikut ini adalah contoh perintah untuk membangun kembali indeks dan meningkatkan kepadatan halamannya, menggunakan pernyataan ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Perintah ini memulai penyusunan ulang indeks yang dapat dilanjutkan dan bersifat online. Langkah ini memungkinkan beban kerja bersama terus menggunakan tabel tersebut saat penyusunan ulang sedang berlangsung, dan memungkinkan Anda melanjutkan penyusunan ulang jika terganggu karena alasan apa pun. Namun, jenis penyusunan ulang ini lebih lambat daripada menyusun ulang secara offline, yang memblokir akses ke tabel. Jika tidak ada beban kerja lain yang perlu mengakses tabel selama penyusunan ulang, atur opsi ONLINE dan RESUMABLE ke OFF serta hapus klausul WAIT_AT_LOW_PRIORITY.
Untuk informasi lebih lanjut terkait pemeliharaan indeks, lihat Mengoptimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya.
Menyusutkan beberapa file data
Seperti yang disebutkan sebelumnya, penyusutan dengan pergerakan data merupakan proses yang berjalan lama. Jika database memiliki beberapa file data, Anda dapat mempercepat prosesnya dengan menyusutkan beberapa file data secara paralel. Anda melakukan ini dengan membuka beberapa sesi database, dan menggunakan DBCC SHRINKFILE di setiap sesi dengan nilai file_id yang berbeda. Sama dengan menyusun ulang indeks sebelumnya, pastikan Anda memiliki headroom sumber daya yang memadai (CPU, Data IO, Log IO) sebelum memulai setiap perintah penyusutan paralel baru.
Contoh perintah berikut menyusutkan file data dengan file_id 4, mencoba mengurangi ukuran yang dialokasikan menjadi 52.000 MB dengan memindahkan halaman dalam file:
DBCC SHRINKFILE (4, 52000);
Jika Anda ingin mengurangi ruang yang dialokasikan untuk file ke ukuran paling minimum, jalankan pernyataan tanpa menentukan ukuran target:
DBCC SHRINKFILE (4);
Jika beban kerja berjalan bersamaan dengan penyusutan, beban kerja mungkin mulai menggunakan ruang penyimpanan yang dikosongkan dengan menyusut sebelum penyusutan selesai dan memotong file. Dalam hal ini, penyusutan tidak akan dapat mengurangi ruang yang dialokasikan ke target yang ditentukan.
Anda dapat menguranginya dengan menyusutkan setiap file dalam langkah-langkah yang lebih kecil. Ini berarti bahwa dalam DBCC SHRINKFILE perintah, Anda menetapkan target yang sedikit lebih kecil dari ruang yang dialokasikan saat ini untuk file. Misalnya, jika ruang yang dialokasikan untuk file dengan file_id 4 adalah 200.000 MB, dan Anda ingin menyusutkannya menjadi 100.000 MB, Anda dapat terlebih dahulu menetapkan target ke 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Setelah perintah selesai, file akan terpotong dan mengurangi ukuran yang dialokasikan menjadi 170.000 MB. Lalu Anda dapat mengulangi perintah ini, mengatur target menjadi 140.000 MB terlebih dahulu, lalu ke 110.000 MB, dst., hingga file menyusut ke ukuran yang diinginkan. Jika perintah selesai tetapi file tidak terpotong, gunakan langkah-langkah yang lebih kecil, misalnya 15.000 MB daripada 30.000 MB.
Untuk memantau kemajuan penyusutan untuk semua sesi penyusutan yang berjalan bersamaan, Anda dapat menggunakan kueri berikut:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Catatan
Kemajuan penyusutan dapat bersifat non-linier, dan nilai dalam percent_complete kolom mungkin tetap tidak berubah untuk jangka waktu yang lama, meskipun penyusutan masih berlangsung.
Setelah penyusutan selesai untuk semua file data, gunakan kueri penggunaan ruang untuk menentukan pengurangan yang dihasilkan dalam ukuran penyimpanan yang dialokasikan. Jika masih ada perbedaan besar antara ruang yang digunakan dan ruang yang dialokasikan, Anda dapat membangun kembali indeks. Ini untuk sementara dapat meningkatkan ruang yang dialokasikan lebih lanjut, namun menyusutkan file data lagi setelah membangun kembali indeks akan mengakibatkan pengurangan ruang yang lebih dalam dalam dalam ruang yang dialokasikan.
Memperbesar file log
Di Azure SQL Managed Instance, tambahkan ruang ke file log dengan memperbesar file log yang ada (jika ruang disk mengizinkan). Menambahkan file log ke database tidak didukung. Satu file log transaksi cukup kecuali ruang log kehabisan, dan ruang disk juga kehabisan volume yang menyimpan file log.
Untuk memperbesar file log, gunakan MODIFY FILE klausa ALTER DATABASE pernyataan, menentukan SIZE sintaks dan MAXSIZE . Untuk informasi selengkapnya, lihat opsi ALTER DATABASE (Transact-SQL) File dan Grup File.
Untuk informasi selengkapnya, lihat Rekomendasi.
Mengontrol pertumbuhan file log transaksi
Gunakan pernyataan opsi AlTER DATABASE (Transact-SQL) dan Filegroup untuk mengelola pertumbuhan file log transaksi. Berikut hal-hal yang perlu diketahui:
- Untuk mengubah ukuran file saat ini di unit KB, MB, GB, dan TB, gunakan opsi .
SIZE - Untuk mengubah kenaikan pertumbuhan, gunakan
FILEGROWTHopsi . Nilai 0 menunjukkan bahwa pertumbuhan otomatis diatur ke nonaktif dan tidak ada ruang tambahan yang diizinkan. - Untuk mengontrol ukuran maksimum file log di unit KB, MB, GB, dan TB atau untuk mengatur pertumbuhan ke UNLIMITED, gunakan opsi .
MAXSIZE
Rekomendasi
Berikut ini adalah beberapa rekomendasi umum saat Anda bekerja dengan file log transaksi:
Peningkatan pertumbuhan otomatis (autogrow) dari log transaksi, seperti yang ditetapkan oleh
FILEGROWTHopsi, harus cukup besar untuk tetap di depan kebutuhan transaksi beban kerja. Kenaikan pertumbuhan file pada file log harus cukup besar untuk menghindari ekspansi yang sering. Pointer yang baik untuk mengukur log transaksi dengan benar memantau jumlah log yang ditempati selama:- Waktu yang diperlukan untuk menjalankan pencadangan penuh, karena pencadangan log tidak dapat terjadi sampai selesai.
- Waktu yang diperlukan untuk operasi pemeliharaan indeks terbesar.
- Waktu yang diperlukan untuk menjalankan batch terbesar dalam database.
Saat mengatur pertumbuhan otomatis untuk data dan file log menggunakan
FILEGROWTHopsi , mungkin lebih disukai untuk mengaturnya alih-alihsizepercentage, untuk memungkinkan kontrol yang lebih baik pada rasio pertumbuhan, karena persentase adalah jumlah yang terus bertambah.- Di Azure SQL Managed Instance, inisialisasi file instan dapat menguntungkan peristiwa pertumbuhan log transaksi hingga 64 MB. Kenaikan ukuran pertumbuhan otomatis default untuk database baru adalah 64 MB. Peristiwa pertumbuhan otomatis file log transaksi yang lebih besar dari 64 MB tidak dapat memperoleh manfaat dari inisialisasi file instan.
- Sebagai praktik terbaik, jangan atur
FILEGROWTHnilai opsi di atas 1.024 MB untuk log transaksi.
Kenaikan pertumbuhan otomatis kecil dapat menghasilkan terlalu banyak VLF kecil dan dapat mengurangi performa. Untuk menentukan distribusi VLF optimal untuk ukuran log transaksi saat ini dari semua database dalam instans tertentu, dan kenaikan pertumbuhan yang diperlukan untuk mencapai ukuran yang diperlukan, lihat skrip ini untuk menganalisis dan memperbaiki VLF, yang disediakan oleh Tim SQL Tiger.
Kenaikan pertumbuhan otomatis yang besar dapat menyebabkan dua masalah:
- Kenaikan pertumbuhan otomatis yang besar dapat menyebabkan database dijeda saat ruang baru dialokasikan, berpotensi menyebabkan batas waktu kueri.
- Kenaikan pertumbuhan otomatis yang besar dapat menghasilkan terlalu sedikit VLF dan besar dan juga dapat memengaruhi performa. Untuk menentukan distribusi VLF optimal untuk ukuran log transaksi saat ini dari semua database dalam instans tertentu, dan kenaikan pertumbuhan yang diperlukan untuk mencapai ukuran yang diperlukan, lihat skrip ini untuk menganalisis dan memperbaiki VLF, yang disediakan oleh Tim SQL Tiger.
Bahkan dengan autogrow diaktifkan, Anda dapat menerima pesan bahwa log transaksi penuh, jika tidak dapat tumbuh cukup cepat untuk memenuhi kebutuhan kueri Anda. Untuk informasi selengkapnya tentang mengubah kenaikan pertumbuhan, lihat opsi ALTER DATABASE (Transact-SQL) File dan Filegroup.
File log dapat diatur untuk menyusut secara otomatis. Namun ini tidak disarankan, dan properti database auto_shrink diatur ke FALSE secara default. Jika auto_shrink diatur ke TRUE, penyusutan otomatis mengurangi ukuran file hanya ketika lebih dari 25 persen ruangnya tidak digunakan.
- File disusutkan baik ke ukuran di mana hanya 25 persen dari file yang tidak digunakan ruang atau ke ukuran asli file, mana yang lebih besar.
- Untuk informasi tentang mengubah pengaturan properti auto_shrink , lihat Menampilkan atau Mengubah Properti Database dan Mengubah Opsi SET DATABASE (Transact-SQL).