Menyetel aplikasi dan database untuk performa di Azure SQL Managed Instance
Berlaku untuk:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Setelah Anda mengidentifikasi masalah performa yang Anda hadapi dengan Azure SQL Managed Instance, artikel ini dirancang untuk membantu Anda:
- Menyetel aplikasi Anda dan menerapkan beberapa praktik terbaik yang dapat meningkatkan performa.
- Menyetel database dengan mengubah indeks dan kueri agar bekerja dengan data secara lebih efisien.
Artikel ini mengasumsikan bahwa Anda telah meninjau gambaran umum pemantauan dan penyetelan dan Memantau performa dengan menggunakan Penyimpanan Kueri. Selain itu, artikel ini mengasumsikan bahwa Anda tidak memiliki masalah performa yang terkait dengan pemanfaatan sumber daya CPU yang dapat diselesaikan dengan meningkatkan ukuran komputasi atau tingkat layanan untuk menyediakan lebih banyak sumber daya ke instans terkelola SQL Anda.
Catatan
Untuk panduan serupa di Azure SQL Database, lihat Menyetel aplikasi dan database untuk performa di Azure SQL Database.
Menyetel aplikasi Anda
Pada SQL Server lokal tradisional, proses perencanaan kapasitas awal sering dipisahkan dari proses menjalankan sebuah aplikasi dalam produksi. Lisensi perangkat keras dan produk dibeli terlebih dahulu, dan penyetelan performa dilakukan setelahnya. Ketika Anda menggunakan Azure SQL, ada baiknya untuk mengadakan proses menjalankan aplikasi dan menyetelnya. Dengan model membayar kapasitas sesuai permintaan, Anda dapat menyetel aplikasi Anda untuk menggunakan sumber daya minimum yang diperlukan sekarang, alih-alih menyediakan perangkat keras secara berlebihan berdasarkan tebakan rencana pertumbuhan di masa depan untuk sebuah aplikasi, yang seringkali salah.
Beberapa pelanggan mungkin memilih untuk tidak menyetel aplikasi, dan sebaliknya memilih untuk menyediakan sumber daya perangkat keras secara berlebihan. Pendekatan ini mungkin merupakan ide yang baik jika Anda tidak ingin mengubah aplikasi kunci saat sibuk. Tetapi, menyetel aplikasi dapat meminimalkan persyaratan sumber daya dan tagihan bulanan yang lebih rendah.
Praktik terbaik dan antipattern dalam desain aplikasi untuk Azure SQL Managed Instance
Meskipun tingkat layanan Azure SQL Managed Instance dirancang untuk meningkatkan stabilitas performa dan prediksi untuk aplikasi, beberapa praktik terbaik dapat membantu Anda menyetel aplikasi Anda untuk memanfaatkan sumber daya dengan lebih baik pada ukuran komputasi. Meskipun banyak aplikasi memiliki peningkatan performa yang signifikan hanya dengan beralih ke ukuran komputasi atau tingkat layanan yang lebih tinggi, beberapa aplikasi membutuhkan penyetelan tambahan untuk mendapatkan keuntungan dari tingkat layanan yang lebih tinggi.
Untuk peningkatan performa, pertimbangkan penyetelan tambahan aplikasi untuk aplikasi dengan karakteristik berikut:
Aplikasi yang memiliki performa yang lambat karena perilaku "ramai"
Aplikasi yang ramai membuat operasi akses data berlebihan yang sensitif terhadap latensi jaringan. Anda mungkin perlu memodifikasi jenis aplikasi ini untuk mengurangi jumlah operasi akses data ke database. Misalnya, Anda dapat meningkatkan performa aplikasi dengan menggunakan teknik seperti batching kueri ad hoc atau memindahkan kueri ke prosedur tersimpan. Untuk informasi selengkapnya, lihat Melakukan batch pada kueri.
Database dengan beban kerja intensif yang tidak dapat didukung oleh seluruh mesin tunggal
Database yang melebihi sumber daya dengan ukuran komputasi Premium tertinggi mungkin mendapat keuntungan dari penskalaan beban kerja. Untuk informasi selengkapnya, lihat Sharding lintas database dan Pemartisian secara fungsional.
Aplikasi yang memiliki kueri sub-optimal
Aplikasi yang memiliki kueri yang disetel dengan buruk mungkin tidak mendapat manfaat dari ukuran komputasi yang lebih tinggi. Ini termasuk kueri yang tidak memiliki klausul WHERE, memiliki indeks yang hilang, atau memiliki statistik yang sudah ketinggalan zaman. Aplikasi ini mendapat keuntungan dari teknik penyetelan performa kueri standar. Untuk informasi selengkapnya, lihat Indeks yang hilang dan Penyetelan dan petunjuk kueri.
Aplikasi yang memiliki desain akses data sub-optimal
Aplikasi yang memiliki masalah konkurensi akses data yang melekat, misalnya kebuntuan, mungkin tidak mendapat keuntungan dari ukuran komputasi yang lebih tinggi. Pertimbangkan untuk mengurangi komunikasi dua arah terhadap database dengan penembolokan data di sisi klien dengan layanan Penembolokan Azure atau teknologi penembolokan lainnya. Lihat Penembolokan tingkat aplikasi.
Untuk mencegah kebuntuan di Azure SQL Managed Instance, lihat Alat kebuntuan panduan Kebuntuan.
Menyetel database Anda
Di bagian ini, kami melihat beberapa teknik yang dapat Anda gunakan untuk menyetel database untuk mendapatkan performa terbaik untuk aplikasi Anda dan menjalankannya dengan ukuran komputasi serendah mungkin. Beberapa teknik ini cocok dengan praktik terbaik penyetelan SQL Server tradisional, tetapi yang lain khusus untuk Azure SQL Managed Instance. Dalam beberapa kasus, Anda dapat memeriksa sumber daya yang digunakan untuk database untuk menemukan area untuk menyetel lebih lanjut dan memperluas teknik SQL Server tradisional untuk bekerja di Azure SQL Managed Instance.
Mengidentifikasi serta menambahkan indeks yang hilang
Masalah umum dalam performa database OLTP berkaitan dengan desain database fisik. Seringkali, skema database dirancang dan dikirim tanpa pengujian yang diskalakan (baik dalam beban atau volume data). Sayangnya, performa rencana kueri mungkin dapat diterima dalam skala kecil tetapi terdegradasi secara substansial di bawah volume data tingkat produksi. Sumber yang paling umum dari masalah ini adalah kurangnya indeks yang sesuai untuk memenuhi filter atau pembatasan lain dalam sebuah kueri. Seringkali, indeks yang hilang bermanifestasi sebagai pemindaian tabel ketika pencarian indeks saja sudah cukup.
Dalam contoh ini, rencana kueri yang dipilih menggunakan pemindaian ketika pencarian saja sudah cukup:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
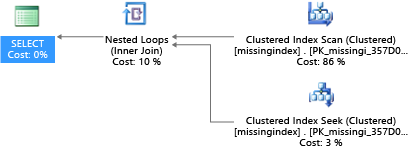
DMV yang dibangun ke dalam SQL Server sejak 2005 melihat kompilasi kueri di mana indeks akan secara signifikan mengurangi perkiraan biaya untuk menjalankan kueri. Selama eksekusi kueri, mesin database melacak seberapa sering setiap rencana kueri dijalankan, dan melacak perkiraan kesenjangan antara rencana kueri yang dieksekusi dan yang dibayangkan di mana indeks itu dulu berada. Anda dapat menggunakan DMV ini untuk menebak dengan cepat perubahan mana pada desain database fisik Anda yang mungkin meningkatkan biaya beban kerja keseluruhan untuk database dan beban kerja nyatanya.
Anda bisa menggunakan kueri ini untuk mengevaluasi potensi indeks yang hilang:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
Dalam contoh ini, kueri tersebut menghasilkan saran ini:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Setelah dibuat, pernyataan SELECT yang sama memilih rencana yang berbeda, yang menggunakan pencarian alih-alih pemindaian, dan kemudian menjalankan rencana tersebut dengan lebih efisien:
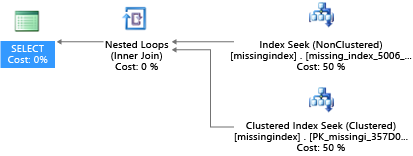
Wawasan utamanya adalah bahwa kapasitas IO dari sistem komoditas bersama lebih terbatas daripada mesin server khusus. Ada manfaat untuk mengecilkan IO yang tidak perlu untuk mengambil keuntungan maksimum dari sistem dalam sumber daya setiap ukuran komputasi dari tingkatan layanan. Pilihan desain database fisik yang sesuai dapat secara signifikan meningkatkan latensi untuk kueri individu, meningkatkan throughput dari konkurensi permintaan yang ditangani per unit skala, dan mengecilkan biaya yang diperlukan untuk memenuhi kueri.
Untuk informasi selengkapnya mengenai penyetelan indeks menggunakan permintaan indeks yang hilang, lihat Menyetel indeks non-kluster dengan saran indeks yang hilang.
Penyetelan dan petunjuk kueri
Pengoptimal kueri di Azure SQL Managed Instance mirip dengan pengoptimal kueri SQL Server tradisional. Sebagian besar praktik terbaik untuk menyetel kueri dan memahami batasan model penalaran untuk pengoptimal kueri juga berlaku untuk Azure SQL Managed Instance. Jika Anda menyetel kueri di Azure SQL Managed Instance, Anda mungkin mendapatkan manfaat tambahan untuk mengurangi permintaan sumber daya agregat. Aplikasi Anda mungkin dapat berjalan dengan biaya yang lebih rendah daripada yang setara yang tidak disetel karena dapat berjalan pada ukuran komputasi yang lebih rendah.
Contoh yang umum di SQL Server dan yang juga berlaku untuk Azure SQL Managed Instance adalah bagaimana pengoptimal kueri "mengintai" parameter. Selama kompilasi, pengoptimal kueri mengevaluasi nilai parameter saat ini untuk menentukan apakah itu dapat menghasilkan rencana kueri yang lebih optimal. Meskipun strategi ini sering dapat menyebabkan rencana kueri yang secara signifikan lebih cepat daripada rencana yang dikompilasi tanpa nilai parameter yang diketahui, saat ini ia bekerja secara tidak sempurna baik di Azure SQL Managed Instance. (Fitur Performa Kueri Cerdas baru yang diperkenalkan dengan SQL Server 2022 bernama Pengoptimalan Rencana Sensitivitas Parameter membahas skenario di mana satu rencana yang di-cache untuk kueri berparameter tidak optimal untuk semua kemungkinan nilai parameter masuk. Saat ini, Pengoptimalan Rencana Sensitivitas Parameter tidak tersedia di Azure SQL Managed Instance.)
Terkadang parameter tidak diendus, dan terkadang parameter diendus tetapi rencana yang dihasilkan tidak optimal untuk serangkaian nilai parameter lengkap dalam beban kerja. Microsoft menyertakan petunjuk kueri (arahan) sehingga Anda dapat menentukan niat dengan lebih sengaja dan mengambil alih perilaku default parameter yang mendeteksi. Anda dapat memilih untuk menggunakan petunjuk ketika perilaku default tidak sempurna untuk beban kerja pelanggan tertentu.
Contoh berikutnya menunjukkan bagaimana prosesor kueri dapat menghasilkan rencana yang sub-optimal baik untuk persyaratan performa maupun sumber daya. Contoh ini juga memperlihatkan bahwa jika Anda menggunakan petunjuk kueri, Anda dapat mengurangi waktu jalankan kueri dan persyaratan sumber daya untuk database Anda:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Kode penyiapan membuat tabel yang memiliki data terdistribusi secara tidak teratur dalam t1 tabel. Rencana kueri optimal berbeda berdasarkan parameter mana yang dipilih. Sayangnya, perilaku penembolokan paket tidak selalu mengolah ulang kueri berdasarkan nilai parameter yang paling umum. Sehingga memungkinkan bagi rencana sub-optimal untuk di-cache dan digunakan untuk banyak nilai, bahkan ketika rata-rata rencana yang berbeda mungkin merupakan pilihan rencana yang lebih baik. Kemudian rencana kueri membuat dua prosedur tersimpan yang identik, kecuali bahwa salah satunya memiliki petunjuk kueri khusus.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Kami menyarankan agar Anda menunggu setidaknya 10 menit sebelum memulai bagian 2 dari contohnya, sehingga hasilnya berbeda dalam data telemetri yang dihasilkan.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
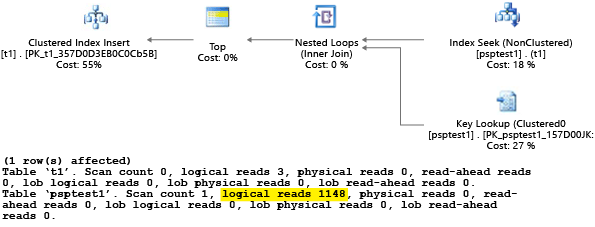
Setiap bagian dari contoh ini mencoba menjalankan pernyataan sisipan parameter 1.000 kali (untuk menghasilkan beban yang cukup untuk digunakan sebagai himpunan data pengujian). Ketika menjalankan prosedur tersimpan, prosesor kueri memeriksa nilai parameter yang diteruskan ke prosedur selama kompilasi pertamanya (parameter "mendeteksi"). Prosesor meng-cache rencana yang dihasilkan dan menggunakannya untuk invokasi nantinya, bahkan jika nilai parameternya berbeda. Rencana optimal mungkin tidak digunakan pada semua kasus. Terkadang Anda perlu memandu pengoptimal untuk memilih rencana yang lebih baik untuk kasus rata-rata daripada kasus tertentu dari saat kueri pertama kali dikompilasi. Dalam contoh ini, rencana awal menghasilkan rencana "pemindaian" yang membaca semua baris untuk menemukan setiap nilai yang cocok dengan parameter:

Karena kami menjalankan prosedur dengan menggunakan nilai 1, rencana yang dihasilkan optimal untuk nilai 1 tetapi kurang optimal untuk semua nilai lain dalam tabel. Hasilnya mungkin bukan yang Anda inginkan jika Anda memilih setiap rencana secara acak, karena rencananya bekerja lebih lambat dan menggunakan lebih banyak sumber daya.
Jika Anda menjalankan pengujian dengan SET STATISTICS IO yang diatur ke ON, pekerjaan pemindaian logis dalam contoh ini dilakukan di belakang layar. Anda dapat melihat bahwa ada 1.148 pembacaan yang dilakukan oleh rencana (yang tidak efisien, jika kasus rata-ratanya adalah mengembalikan hanya satu baris):

Bagian kedua dari contoh menggunakan petunjuk kueri untuk memberi tahu pengoptimal untuk menggunakan nilai tertentu selama proses kompilasi. Dalam hal ini, ini memaksa prosesor kueri untuk mengabaikan nilai yang diteruskan sebagai parameter, dan sebaliknya untuk mengasumsikan UNKNOWN. Ini mengacu pada nilai yang memiliki frekuensi rata-rata dalam tabel (mengabaikan kecondongan). Rencana yang dihasilkan adalah rencana berbasis pencarian yang lebih cepat dan menggunakan lebih sedikit sumber daya, secara rata-rata, daripada rencana di bagian 1 dari contoh berikut:
Anda dapat melihat efek dalam tampilan katalog sistem sys.server_resource_stats . Data dikumpulkan, dikumpulkan, dan diperbarui dalam interval 5 hingga 10 menit. Ada satu baris untuk setiap 15 detik pelaporan. Misalnya:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Anda dapat memeriksa sys.server_resource_stats untuk menentukan apakah sumber daya untuk pengujian menggunakan lebih banyak atau lebih sedikit sumber daya daripada pengujian lain. Saat Anda membandingkan data, pisahkan waktu pengujian sehingga tidak berada di jendela 5 menit yang sama dalam sys.server_resource_stats tampilan. Tujuan dari latihan ini adalah untuk mengecilkan jumlah total sumber daya yang digunakan, dan bukan untuk mengecilkan sumber daya puncak. Umumnya, mengoptimalkan sepotong kode untuk latensi juga mengurangi konsumsi sumber daya. Pastikan bahwa perubahan yang Anda lakukan pada aplikasi diperlukan, dan bahwa perubahan tidak berdampak negatif pada pengalaman pelanggan untuk seseorang yang mungkin menggunakan petunjuk kueri dalam aplikasi.
Jika beban kerja memiliki set kueri berulang, seringkali masuk akal untuk mengambil dan memvalidasi keoptimalan rencana pilihan Anda karena menekan unit ukuran sumber daya minimum yang diperlukan untuk menghosting database. Setelah Anda memvalidasinya, kadang-kadang periksa kembali rencana untuk membantu Anda memastikan bahwa rencana tersebut belum terdegradasi. Anda dapat mempelajari selengkapnya tentang petunjuk kueri (T-SQL).
Praktik terbaik untuk arsitektur database yang sangat besar di Azure SQL Managed Instance
Dua bagian berikut membahas dua opsi untuk memecahkan masalah dengan database yang sangat besar di Azure SQL Managed Instance.
Sharding lintas database
Karena Azure SQL Managed Instance berjalan pada perangkat keras komoditas, batas kapasitas untuk database individual lebih rendah daripada untuk penginstalan SQL Server lokal tradisional. Beberapa pelanggan menggunakan teknik sharding untuk menyebarkan operasi database melalui beberapa database ketika operasi tidak sesuai di dalam batas database individual di Azure SQL Managed Instance. Sebagian besar pelanggan yang menggunakan teknik sharding di Azure SQL Managed Instance membagi data mereka pada satu dimensi di beberapa database. Untuk pendekatan ini, Anda perlu memahami bahwa aplikasi OLTP sering melakukan transaksi yang hanya berlaku untuk satu baris atau ke sekelompok kecil baris dalam skema.
Misalnya, jika database memiliki nama pelanggan, pesanan, dan detail pesanan (seperti dalam AdventureWorks database), Anda dapat membagi data ini menjadi beberapa database dengan mengelompokkan pelanggan dengan pesanan terkait dan informasi detail pesanan. Anda dapat menjamin bahwa data pelanggan tetap berada dalam database individual. Aplikasi ini akan membagi pelanggan yang berbeda di seluruh database, secara efektif menyebarkan beban di beberapa database. Dengan sharding, pelanggan tidak hanya dapat menghindari batas ukuran database maksimum, tetapi Azure SQL Managed Instance juga dapat memproses beban kerja yang secara signifikan lebih besar dari batas ukuran komputasi yang berbeda, selama setiap database individual sesuai dengan batas tingkat layanannya.
Meskipun sharding database tidak mengurangi kapasitas sumber daya agregat sebagai sebuah solusi, itu sangat efektif untuk mendukung solusi yang sangat besar yang tersebar di beberapa database. Setiap database dapat berjalan pada ukuran komputasi yang berbeda untuk mendukung database yang sangat besar dan "efektif" dengan persyaratan sumber daya tinggi.
Pemartisian fungsional
Pengguna sering menggabungkan banyak fungsi dalam database individual. Misalnya, jika aplikasi memiliki logika untuk mengelola inventaris untuk sebuah toko, database tersebut mungkin memiliki logika yang terkait dengan inventaris, melacak pesanan pembelian, prosedur tersimpan, dan tampilan terindeks atau terwujud yang mengelola pelaporan akhir bulan. Teknik ini membuatnya lebih mudah untuk mengelola database untuk operasi seperti pencadangan, tetapi juga mengharuskan Anda untuk mengukur perangkat keras untuk menangani puncak beban di semua fungsi aplikasi.
Jika Anda menggunakan arsitektur peluasan skala di Azure SQL Managed Instance, ada baiknya untuk membagi berbagai fungsi aplikasi menjadi database yang berbeda. Jika Anda menggunakan teknik ini, setiap aplikasi diskalakan secara independen. Ketika aplikasi menjadi lebih sibuk (dan beban pada database meningkat), admin dapat memilih ukuran komputasi independen untuk setiap fungsi dalam aplikasi. Pada batasnya, dengan arsitektur ini, aplikasi bisa menjadi lebih besar daripada yang bisa ditangani satu mesin komoditas karena beban tersebar di beberapa mesin.
Batch kueri
Untuk aplikasi yang mengakses data dengan menggunakan kueri ad hoc yang sering dan bervolume tinggi, sejumlah besar waktu respons dihabiskan untuk komunikasi jaringan antara tingkat aplikasi dan tingkat database. Bahkan ketika aplikasi dan database berada di pusat data yang sama, latensi jaringan antara keduanya mungkin diperbesar oleh sejumlah besar operasi akses data. Untuk mengurangi komunikasi dua arah jaringan untuk operasi akses data, pertimbangkan untuk menggunakan opsi untuk mem-batch kueri ad hoc, atau untuk mengompilasinya sebagai prosedur tersimpan. Jika Anda mem-batch kueri ad hoc, Anda dapat mengirim beberapa kueri sebagai satu batch besar dalam satu komunikasi menuju database. Jika Anda mengompilasi kueri ad hoc di dalam prosedur tersimpan, Anda dapat mencapai hasil yang sama seolah-olah Anda mem-batch-nya. Menggunakan prosedur tersimpan juga memberi Anda keuntungan yaitu meningkatkan kemungkinan penembolokan rencana kueri dalam database sehingga Anda dapat menggunakan prosedur tersimpan lagi.
Beberapa aplikasi bersifat tulis-intensif. Terkadang Anda dapat mengurangi total beban IO pada database dengan mempertimbangkan cara mem-batch tulisan bersama. Seringkali, ini sesederhana menggunakan transaksi eksplisit alih-alih transaksi autocommit dalam prosedur tersimpan dan batch ad hoc. Untuk evaluasi berbagai teknik yang dapat Anda gunakan, lihat Teknik batching untuk aplikasi database di Azure. Lakukan eksperimen dengan beban kerja Anda sendiri untuk menemukan model yang tepat untuk mem-batch. Pastikan untuk memahami bahwa sebuah model mungkin memiliki jaminan konsistensi transaksional yang sedikit berbeda. Menemukan beban kerja yang tepat yang mengecilkan penggunaan sumber daya memerlukan penemuan kombinasi konsistensi dan tarik-ulur performa yang tepat.
Penembolokan tingkat aplikasi
Beberapa aplikasi database memiliki beban kerja baca-berat. Lapisan penembolokan dapat mengurangi beban pada database dan mungkin berpotensi mengurangi ukuran komputasi yang diperlukan untuk mendukung database dengan menggunakan Azure SQL Managed Instance. Dengan Azure Cache for Redis, jika Anda memiliki beban kerja baca-berat, Anda dapat membaca data sekali (atau mungkin sekali per mesin tingkat aplikasi, tergantung pada cara konfigurasinya), lalu menyimpan data tersebut di luar database Anda. Ini adalah cara untuk mengurangi beban database (CPU dan membaca IO), tetapi ada efek pada konsistensi transaksional karena data yang dibaca dari cache mungkin tidak sinkron dengan data dalam database. Meskipun pada banyak aplikasi beberapa tingkat inkonsistensi dapat diterima, itu tidak benar untuk semua beban kerja. Anda harus sepenuhnya memahami persyaratan aplikasi apa pun sebelum Anda menerapkan strategi penembolokan tingkat aplikasi.
Konten terkait
- Model pembelian vCore - Azure SQL Managed Instance
- Mengonfigurasi pengaturan tempdb untuk Azure SQL Managed Instance
- Memantau performa Microsoft Azure SQL Managed Instance menggunakan tampilan manajemen dinamis
- Menyetel indeks non-kluster dengan saran indeks yang hilang
- Memantau Azure SQL Managed Instance dengan Azure Monitor
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk