Mengidentifikasi dan mentranskripsi konten multi-bahasa secara otomatis
Penting
Karena pengumuman penghentian Azure Media Services, Azure AI Video Indexer mengumumkan penyesuaian fitur Azure AI Video Indexer. Lihat Perubahan yang terkait dengan penghentian Azure Media Service (AMS) untuk memahami apa artinya ini untuk akun Azure AI Video Indexer Anda. Lihat panduan Mempersiapkan penghentian AMS: Pembaruan VI dan migrasi.
Azure AI Video Indexer mendukung identifikasi dan transkripsi bahasa otomatis dalam konten multi-bahasa. Proses ini meliputi mengidentifikasi bahasa lisan secara otomatis dalam berbagai segmen dari audio, mengirim setiap segmen file media untuk ditranskripsi, dan menggabungkan transkripsi kembali ke satu kesatuan transkripsi.
Memilih identifikasi multi-bahasa pada pengindeksan dengan portal
Anda dapat memilih deteksi multi-bahasa saat mengunggah dan mengindeks video. Atau, Anda dapat memilih deteksi multi-bahasa saat mengindeks ulang video Anda. Langkah-langkah berikut menjelaskan cara mengindeks ulang:
Telusuri ke situs web Azure AI Video Indexer dan masuk.
Buka halaman Pustaka dan arahkan kursor ke nama video yang ingin diindeks ulang.
Di sudut kanan bawah, pilih tombol Indeks ulang video .
Dalam dialog Indeks ulang video, pilih deteksi multi-bahasa dari kotak drop-down Bahasa sumber video.
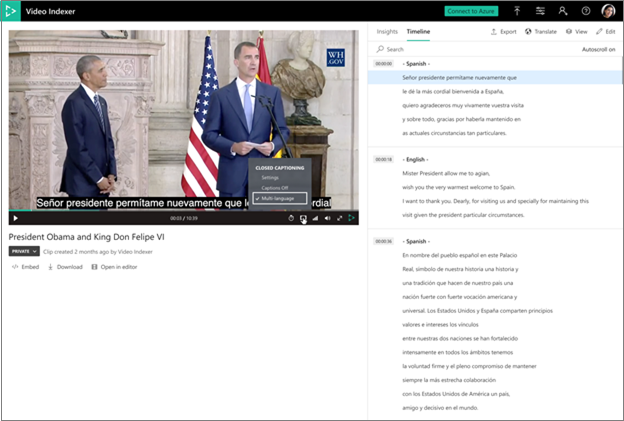
- Saat video diindeks sebagai multi-bahasa, pengguna untuk melihat segmen mana yang ditranskripsikan dalam bahasa mana.
- Terjemahan ke semua bahasa sepenuhnya tersedia dari transkrip multi-bahasa.
- Semua wawasan lain muncul dalam bahasa yang paling terdeteksi dalam audio.
- Pemasangan teks tertutup pada pemutar juga tersedia dalam multi-bahasa.
Memilih identifikasi multi-bahasa pada pengindeksan dengan API
Saat mengindeks atau mengindeks ulang video menggunakan API, pilih opsi multi-language detection di parameter sourceLanguage.
Output model
Model mengambil semua bahasa yang terdeteksi dalam video dalam satu daftar
"sourceLanguage": null,
"sourceLanguages": [
"es-ES",
"en-US"
],
Selain itu, setiap instans di bagian transkripsi menyertakan bahasa tempat instans ditranskripsikan
{
"id": 136,
"text": "I remember well when my youth Minister took me to hear Doctor King I was a teenager.",
"confidence": 0.9343,
"speakerId": 1,
"language": "en-US",
"instances": [
{
"adjustedStart": "0:21:10.42",
"adjustedEnd": "0:21:17.48",
"start": "0:21:10.42",
"end": "0:21:17.48"
}
]
},
Pedoman dan batasan
- Audio yang berisi bahasa selain yang Anda pilih menghasilkan hasil yang tidak terduga.
- Panjang segmen minimal untuk mendeteksi setiap bahasa adalah 15 detik.
- Rata-rata offset deteksi bahasa adalah 3 detik.
- Ucapan harus berkelanjutan. Pergantian antar bahasa yang sering dapat memengaruhi performa model.
- Ucapan pembicara non-asli dapat memengaruhi performa model (misalnya, ketika pembicara menggunakan bahasa pertama mereka dan mereka beralih ke bahasa lain).
- Model ini dirancang untuk mengenali ucapan percakapan spontan dengan akustik audio yang wajar (bukan perintah suara, nyanyian, dll.).
- Pembuatan dan pengeditan proyek tidak tersedia untuk video multi-bahasa.
- Model bahasa kustom tidak tersedia saat menggunakan deteksi multi-bahasa.
- Menambahkan kata kunci tidak didukung.
- Indikasi bahasa tidak disertakan dalam file teks tertutup yang diekspor.
- Transkrip pembaruan di API tidak mendukung beberapa file bahasa.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk