Mulai Cepat: Klasifikasi teks kustom
Gunakan artikel ini untuk memulai membuat proyek klasifikasi teks kustom tempat Anda dapat melatih model kustom untuk klasifikasi teks. Model adalah perangkat lunak kecerdasan buatan yang dilatih untuk melakukan tugas tertentu. Untuk sistem ini, model mengklasifikasikan teks, dan dilatih dengan belajar dari data yang diberi tag.
Klasifikasi teks kustom mendukung dua jenis proyek:
- Klasifikasi label tunggal - Anda dapat menetapkan satu kelas untuk setiap dokumen dalam himpunan data Anda. Misalnya, skrip film hanya dapat diklasifikasikan sebagai "Percintaan" atau "Komedi".
- Klasifikasi multi-label - Anda dapat menetapkan beberapa kelas untuk setiap dokumen dalam himpunan data Anda. Misalnya, skrip film dapat diklasifikasikan sebagai "Komedi" atau "Percintaan" dan "Komedi".
Dalam mulai cepat ini Anda dapat menggunakan himpunan data sampel yang disediakan untuk membangun klasifikasi multi-label di mana Anda dapat mengklasifikasikan skrip film ke dalam satu atau beberapa kategori atau Anda dapat menggunakan himpunan data klasifikasi-label tunggal tempat Anda dapat mengklasifikasikan abstrak makalah ilmiah ke dalam salah satu domain yang ditentukan.
Prasyarat
- Langganan Azure - Buat langganan gratis.
Membuat sumber daya Bahasa Azure AI baru dan akun penyimpanan Azure
Sebelum dapat menggunakan klasifikasi teks kustom, Anda harus membuat sumber daya Bahasa Azure AI, yang akan memberi Anda kredensial yang Anda butuhkan untuk membuat proyek dan mulai melatih model. Anda juga memerlukan akun penyimpanan Azure, tempat Anda dapat mengunggah himpunan data yang akan digunakan untuk membangun model Anda.
Penting
Untuk memulai dengan cepat, sebaiknya buat sumber daya Bahasa Azure AI baru menggunakan langkah-langkah yang disediakan dalam artikel ini. Menggunakan langkah-langkah dalam artikel ini, Anda dapat membuat sumber daya Bahasa dan akun penyimpanan secara bersamaan, yang lebih mudah daripada melakukannya nanti.
Jika Anda memiliki sumber daya yang sudah ada sebelumnya yang ingin digunakan, Anda harus menghubungkannya ke akun penyimpanan.
Buat sumber daya baru menggunakan portal Microsoft Azure
Buka portal Azure untuk membuat sumber daya Bahasa Azure AI baru.
Di jendela yang muncul, pilih Klasifikasi teks kustom & pengenalan entitas bernama kustom dari fitur kustom. Pilih Lanjutkan untuk membuat sumber daya Anda di bagian bawah layar.

Buat sumber daya Bahasa dengan detail berikut.
Nama Nilai yang diperlukan Langganan Langganan Azure Anda. Grup sumber daya Grup sumber daya yang akan berisi sumber daya Anda. Anda dapat menggunakan ruang kerja yang sudah ada atau membuat baru. Wilayah Salah satu wilayah yang didukung. Misalnya, "US Barat 2". Nama Nama sumber daya Anda. Tingkatan harga Salah satu tingkat harga yang didukung. Anda dapat menggunakan tingkat Gratis (F0) untuk mencoba layanan. Jika Anda mendapatkan pesan yang mengatakan "akun masuk Anda bukan pemilik grup sumber daya akun penyimpanan yang dipilih", akun Anda harus memiliki peran pemilik yang ditetapkan pada grup sumber daya sebelum Anda dapat membuat sumber daya Bahasa. Hubungi pemilik langganan Azure Anda untuk bantuan.
Anda dapat menentukan pemilik langganan Azure dengan mencari grup sumber daya Anda dan mengikuti tautan ke langganan terkait. lalu:
- Pilih tab Access Control (IAM)
- Pilih Penetapan peran
- Filter menurut Peran:Pemilik.
Di bagian Klasifikasi teks kustom & pengenalan entitas bernama kustom, pilih akun penyimpanan yang sudah ada atau pilih Akun penyimpanan baru. Perhatikan bahwa nilai ini untuk membantu Anda memulai, dan belum tentu nilai akun penyimpanan yang ingin Anda gunakan di lingkungan produksi. Untuk menghindari latensi selama membangun proyek Anda, sambungkan ke akun penyimpanan di wilayah yang sama dengan sumber daya Bahasa Anda.
Nilai akun penyimpanan Nilai yang direkomendasikan Nama akun penyimpanan Nama apa pun Jenis akun penyimpanan LRS Standar Pastikan Pemberitahuan AI yang Bertanggung Jawab diperiksa. Pilih Tinjau + buat di bagian bawah halaman.

Unggah data sampel ke kontainer blob
Setelah Anda membuat akun penyimpanan Azure dan menghubungkannya ke sumber daya Bahasa, Anda perlu mengunggah dokumen dari himpunan data sampel ke direktori akar kontainer Anda. Dokumen ini akan digunakan untuk melatih model Anda.
Unduh himpunan data sampel untuk proyek klasifikasi multi-label.
Buka file .zip, dan ekstrak folder yang berisi dokumen.
Himpunan data sampel yang disediakan berisi sekitar 200 dokumen, yang masing-masing merupakan ringkasan untuk film. Setiap dokumen milik satu atau beberapa kelas berikut:
- "Misteri"
- "Drama"
- "Thriller"
- "Komedi"
- "Aksi"
Di portal Azure, buka akun penyimpanan yang Anda buat, dan pilih. Anda dapat melakukan ini dengan mengklik Akun penyimpanan dan mengetikkan nama akun penyimpanan Anda ke filter untuk bidang apa pun.
jika grup sumber daya Anda tidak muncul, pastikan filter Langganan sama dengan diatur ke Semua.
Di akun penyimpanan Anda, pilih Kontainer dari menu kiri, yang terletak di bawah Penyimpanan data. Pada layar yang muncul, pilih + Kontainer. Beri kontainer nama contoh-data dan tinggalkan Tingkat akses publik default.

Setelah kontainer Anda dibuat, pilih itu. Lalu pilih tombol Unggah untuk memilih file dan
.jsonyang.txtAnda unduh sebelumnya.


Membuat proyek klasifikasi kustom
Setelah sumber daya serta kontainer penyimpanan Anda dikonfigurasi, buat proyek klasifikasi teks baru. Proyek adalah area kerja untuk membuat model ML kustom berdasarkan data Anda. Proyek Anda hanya dapat diakses oleh Anda dan orang lain yang memiliki akses ke sumber daya Bahasa yang digunakan.
Masuk ke Studio Bahasa. Sebuah jendela akan muncul yang memungkinkan Anda memilih langganan dan sumber daya Language. Pilih sumber daya Bahasa Anda.
Di bagian Klasifikasi teks di Studio Bahasa, pilih Klasifikasi teks kustom.
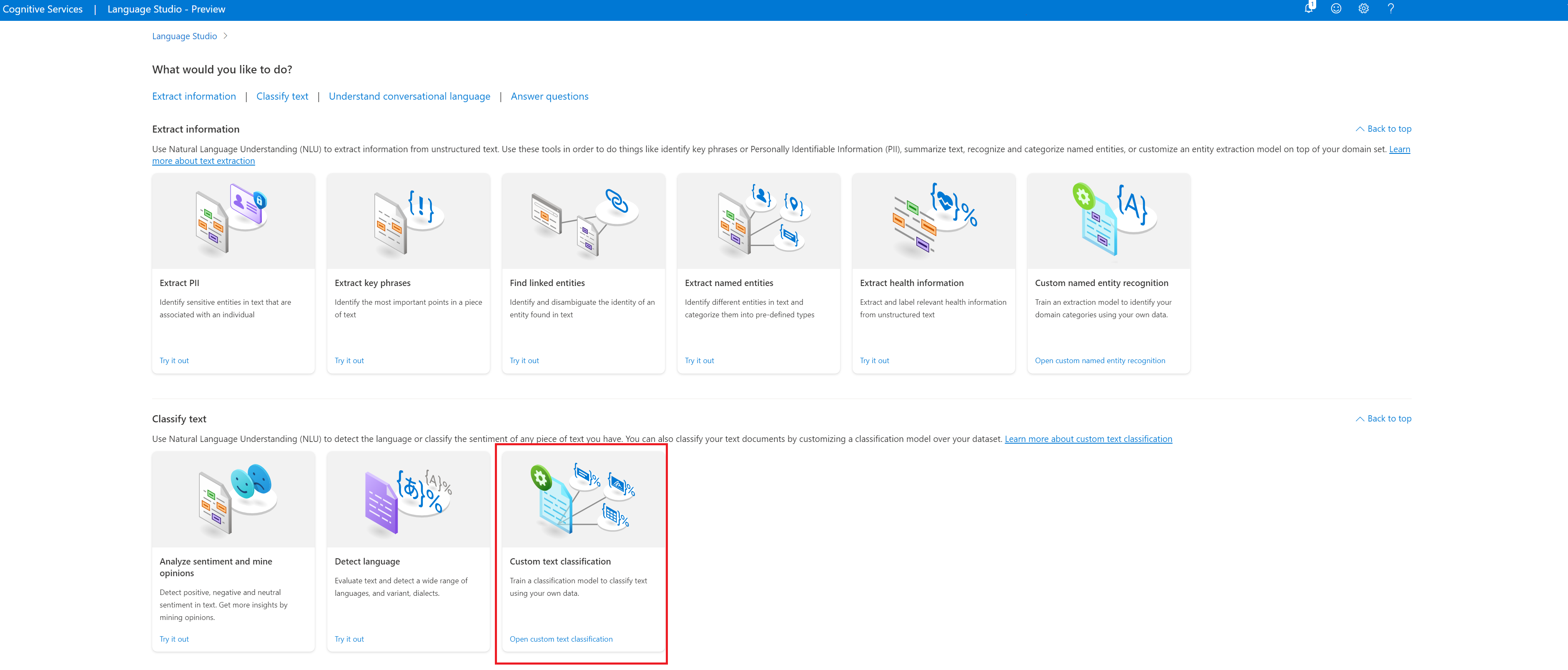
Pilih Buat proyek baru dari menu atas di halaman proyek Anda. Membuat proyek akan memungkinkan Anda melabeli data, melatih, mengevaluasi, meningkatkan, dan menyebarkan model Anda.
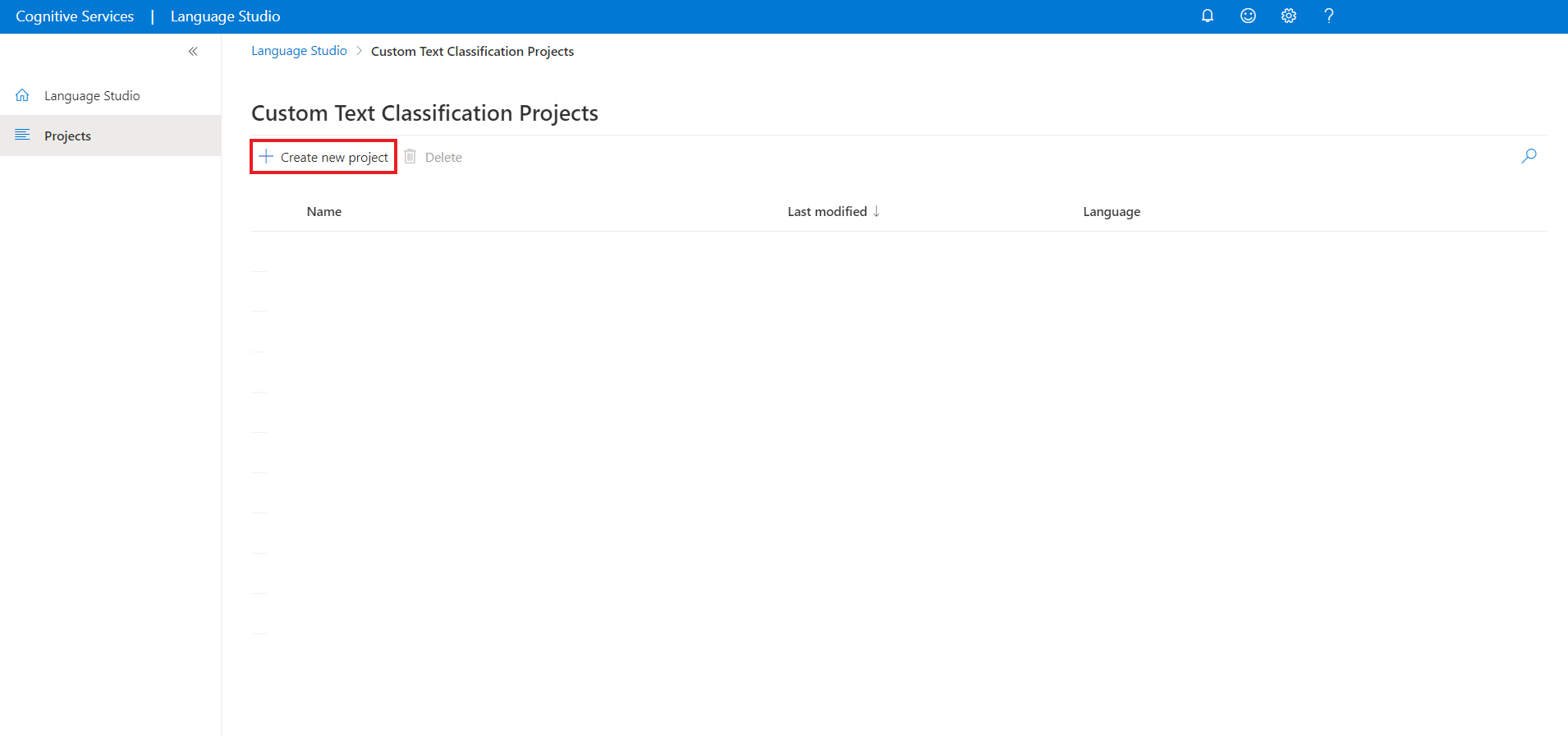
Setelah Anda mengeklik, Buat proyek baru, layar akan muncul untuk memungkinkan Anda menghubungkan akun penyimpanan Anda. Jika Anda sudah menyambungkan akun penyimpanan, Anda akan melihat akun penyimpanan tersambung. Jika tidak, pilih akun penyimpanan Anda dari menu dropdown yang muncul dan pilih akun penyimpanan Koneksi; ini akan mengatur peran yang diperlukan untuk akun penyimpanan Anda. Langkah ini mungkin akan mengembalikan kesalahan jika Anda tidak ditetapkan sebagai pemilik di akun penyimpanan.
Catatan
- Cukup lakukan langkah ini sekali untuk setiap sumber daya baru yang Anda gunakan.
- Proses ini tidak dapat diubah, jika Anda menghubungkan akun penyimpanan ke sumber daya Bahasa, Anda tidak dapat memutuskannya nanti.
- Anda hanya dapat menghubungkan sumber daya Bahasa Anda ke satu akun penyimpanan.

Pilih jenis proyek. Anda dapat membuat proyek Klasifikasi multi-label yang setiap dokumennya dapat disertakan dalam satu atau beberapa kelas atau proyek Klasifikasi label tunggal yang setiap dokumennya hanya dapat disertakan dalam satu kelas. Jenis yang dipilih tidak dapat diubah nanti. Pelajari selengkapnya jenis proyek

Masukkan informasi proyek, termasuk nama, deskripsi, dan bahasa pemrogram file dalam dokumen di proyek Anda. Jika Anda menggunakan contoh himpunan data, pilih Bahasa Inggris. Anda tidak akan dapat mengubah nama proyek Anda nanti. Pilih Selanjutnya.
Tip
Himpunan data Anda tidak harus sepenuhnya dalam bahasa pemrogram yang sama. Anda dapat memiliki beberapa dokumen, masing-masing dengan bahasa yang didukung berbeda. Jika himpunan data Anda berisi dokumen dari bahasa yang berbeda atau jika Anda mengharapkan teks dari bahasa yang berbeda selama waktu proses, pilih opsi aktifkan himpunan data multi-bahasa saat Anda memasukkan informasi dasar untuk proyek Anda. Opsi ini dapat diaktifkan nanti dari halaman Pengaturan proyek.
Pilih kontainer tempat Anda mengunggah himpunan data Anda.
Catatan
Jika Anda telah memberi label data Anda pastikan data mengikuti format yang didukung dan pilih Ya, dokumen saya sudah diberi label dan saya telah memformat file label JSON dan memilih file label dari menu drop-down di bawah ini.
Jika Anda menggunakan salah satu contoh himpunan data, gunakan file yang disertakan
webOfScience_labelsFileataumovieLabelsjson. Kemudian pilih Berikutnya.Tinjau data yang Anda masukkan dan pilih Buat Project.




Melatih model
Biasanya setelah Anda membuat proyek, Anda bisa melanjutkan dan mulai melabeli dokumen yang Anda miliki di kontainer yang terhubung ke proyek Anda. Untuk mulai cepat ini, Anda sudah mengimpor sampel himpunan data yang dilabeli dan menginisialisasi proyek Anda dengan sampel file berlabel JSON.
Untuk mulai melatih model Anda dari dalam Language Studio:
Pilih Pekerjaan pelatihan dari menu sebelah kiri.
Pilih Mulai pekerjaan pelatihan dari menu atas.
Pilih Latih model baru dan ketik nama model di kotak teks. Anda juga dapat menimpa model yang ada dengan memilih opsi ini dan memilih model yang ingin Anda timpa dari menu drop-down. Menimpa model terlatih tidak dapat diubah, tetapi tidak akan memengaruhi model yang Anda sebarkan hingga Anda menyebarkan model baru.
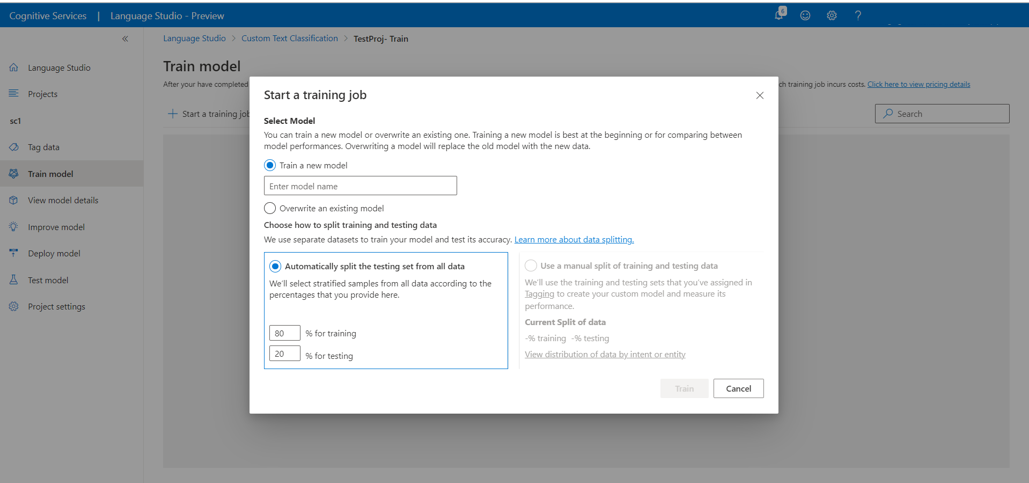
Pilih metode pemisahan data. Anda dapat memilih Memisahkan set pengujian secara otomatis dari data pelatihan di mana sistem akan membagi data berlabel Anda antara set pelatihan dan pengujian, sesuai dengan persentase yang ditentukan. Atau Anda dapat Menggunakan pemisahan manual data pelatihan dan pengujian, opsi ini hanya diaktifkan jika Anda telah menambahkan dokumen ke set pengujian Anda selama pelabelan data. Lihat Cara melatih model untuk informasi selengkapnya tentang pemisahan data.
Pilih tombol Latih.
Jika Anda memilih ID pekerjaan pelatihan dari daftar, panel samping akan muncul di mana Anda dapat memeriksa kemajuan Pelatihan, Status pekerjaan, dan detail lainnya untuk pekerjaan ini.
Catatan
- Hanya pekerjaan pelatihan yang berhasil diselesaikan yang akan menghasilkan model.
- Waktu untuk melatih model dapat memakan waktu antara beberapa menit hingga beberapa jam berdasarkan ukuran data berlabel Anda.
- Anda hanya dapat memiliki satu pekerjaan pelatihan yang berjalan pada satu waktu. Anda tidak dapat memulai pekerjaan pelatihan lain dalam proyek yang sama sampai pekerjaan yang sedang berjalan selesai.

Sebarkan model anda
Biasanya setelah melatih model, Anda akan meninjau detail evaluasi dan melakukan peningkatan jika perlu. Dalam mulai cepat ini, Anda hanya akan menyebarkan model Anda, dan membuatnya tersedia untuk Anda coba di Language Studio, atau Anda dapat memanggil API prediksi.
Untuk menyebarkan model Anda dari dalam Language Studio:
Pilih Menyebarkan model dari menu sebelah kiri.
Pilih Tambahkan penyebaran untuk memulai pekerjaan penyebaran baru.
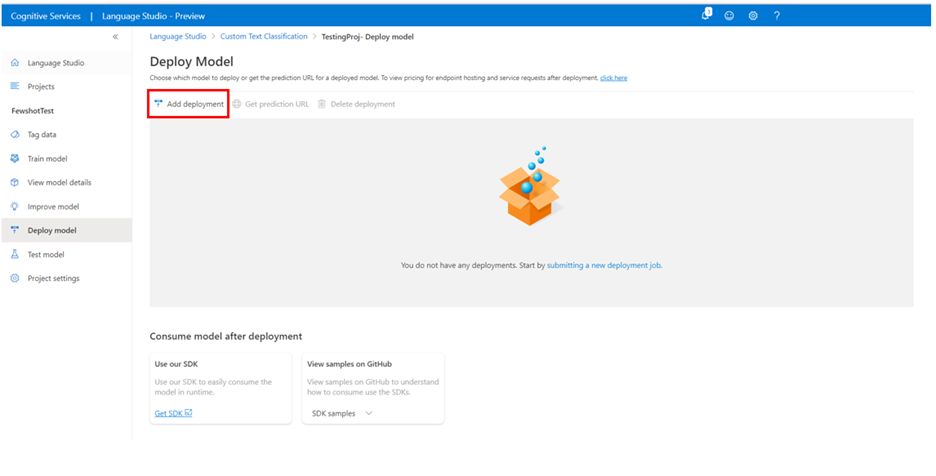
Pilih Buat penyebaran baru untuk membuat penyebaran baru dan tetapkan model terlatih dari menu drop-down di bawah ini. Anda juga dapat Menimpa penyebaran yang ada dengan memilih opsi ini dan memilih model terlatih yang ingin Anda tetapkan dari menu drop-down di bawah ini.
Catatan
Menimpa penyebaran yang ada tidak memerlukan perubahan pada panggilan API Prediksi Anda tetapi hasil yang Anda dapatkan akan didasarkan pada model yang baru ditetapkan.
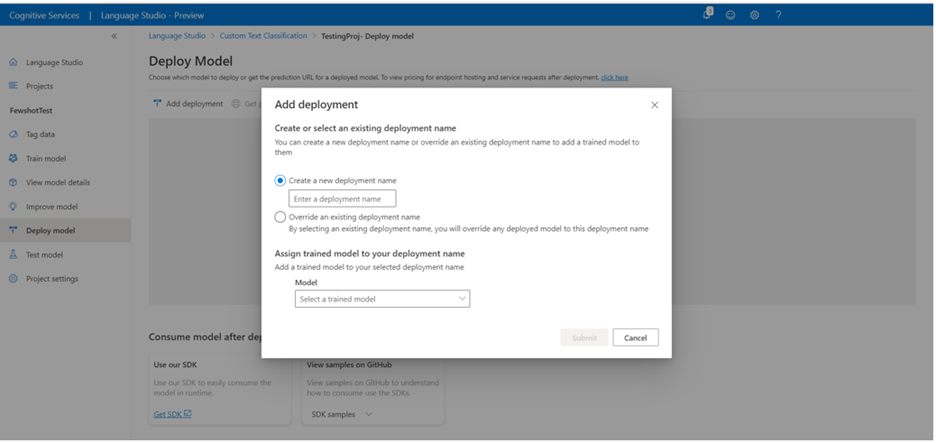
pilih Sebarkan untuk memulai pekerjaan penyebaran.
Setelah penyebaran berhasil, tanggal kedaluwarsa akan muncul di sampingnya. Kedaluwarsa penyebaran adalah ketika model yang Anda sebarkan tidak akan tersedia untuk digunakan untuk prediksi, yang biasanya terjadi dua belas bulan setelah konfigurasi pelatihan kedaluwarsa.


Uji model Anda
Setelah model disebarkan, Anda dapat mulai menggunakannya untuk mengklasifikasikan teks Anda melalui API Prediksi. Untuk mulai cepat ini, Anda akan menggunakan Language Studio untuk mengirimkan tugas klasifikasi teks kustom dan memvisualisasikan hasilnya. Dalam himpunan data sampel yang Anda unduh sebelumnya, Anda dapat menemukan beberapa dokumen pengujian yang dapat Anda gunakan pada langkah ini.
Untuk menguji model yang Anda sebarkan dalam Language Studio:
Pilih Menguji penyebaran dari menu di sisi kiri layar.
Pilih penyebaran yang ingin Anda uji. Anda hanya dapat menguji model yang ditetapkan untuk penyebaran.
Untuk proyek multi-bahasa, pilih bahasa teks yang sedang Anda uji menggunakan menu dropdown bahasa.
Pilih penyebaran yang ingin Anda kueri/uji dari menu dropdown.
Masukkan teks yang ingin Anda kirimkan dalam permintaan, atau unggah dokumen
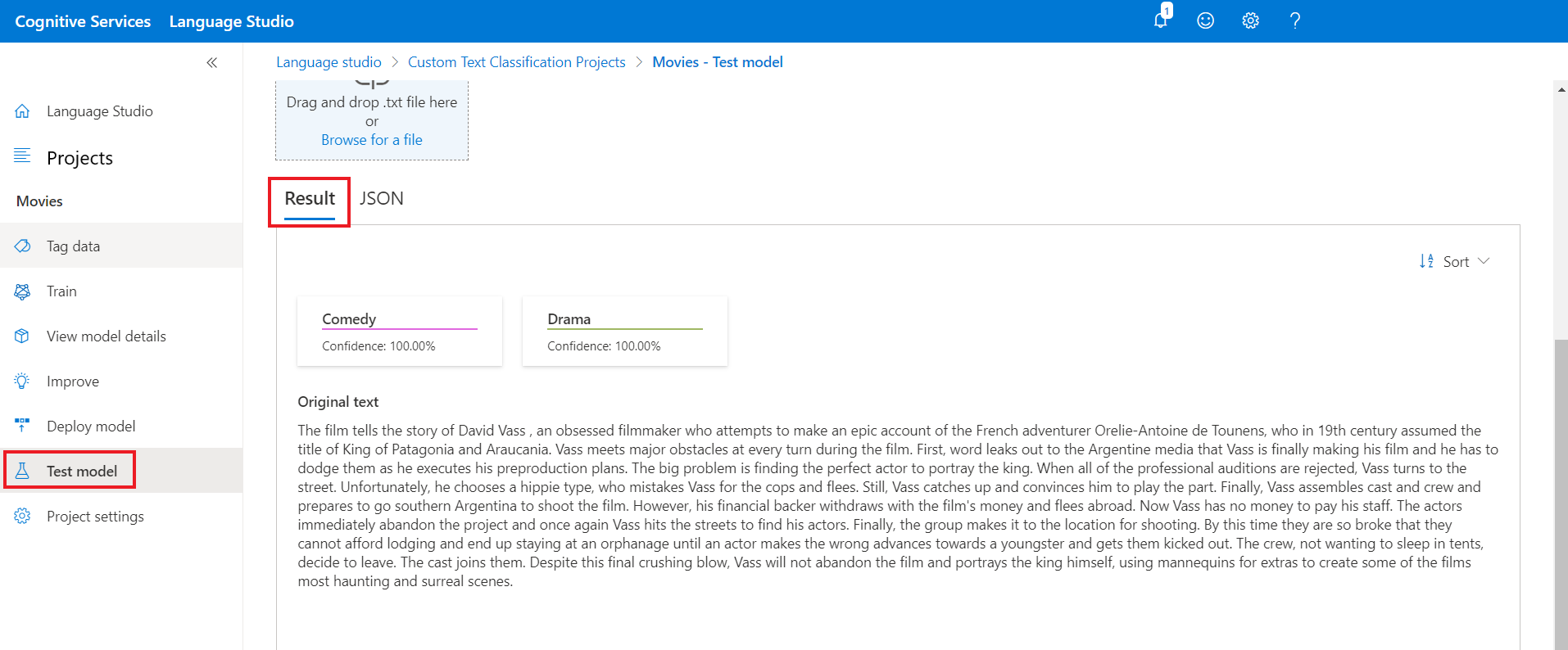
.txtyang akan digunakan. Jika Anda menggunakan salah satu contoh himpunan data, Anda dapat menggunakan salah satu file .txt yang disertakan.Pilih Jalankan pengujian dari menu atas.
Di tab Hasil, Anda dapat melihat prediksi kelas untuk teks Anda. Anda juga dapat melihat respons JSON di tab JSON. Contoh berikut adalah untuk proyek klasifikasi satu label. Proyek klasifikasi multi label dapat menampilkan lebih dari satu kelas dalam hasilnya.

Membersihkan proyek
Jika Anda tidak memerlukan proyek lagi, Anda dapat menghapus proyek menggunakan Language Studio. Pilih Klasifikasi teks kustom di bagian atas, lalu pilih proyek yang ingin Anda hapus. Pilih Hapus dari menu atas untuk menghapus proyek.
Prasyarat
- Langganan Azure - Buat langganan gratis.
Membuat sumber daya Bahasa Azure AI baru dan akun penyimpanan Azure
Sebelum dapat menggunakan klasifikasi teks kustom, Anda harus membuat sumber daya Bahasa Azure AI, yang akan memberi Anda kredensial yang Anda butuhkan untuk membuat proyek dan mulai melatih model. Anda juga memerlukan akun penyimpanan Azure, tempat Anda dapat mengunggah himpunan data yang akan digunakan dalam membangun model Anda.
Penting
Untuk memulai dengan cepat, sebaiknya buat sumber daya Bahasa Azure AI baru menggunakan langkah-langkah yang disediakan dalam artikel ini, yang akan memungkinkan Anda membuat sumber daya Bahasa, dan membuat dan/atau menghubungkan akun penyimpanan secara bersamaan, yang lebih mudah daripada melakukannya nanti.
Jika Anda memiliki sumber daya yang sudah ada sebelumnya yang ingin digunakan, Anda harus menghubungkannya ke akun penyimpanan.
Buat sumber daya baru menggunakan portal Microsoft Azure
Buka portal Azure untuk membuat sumber daya Bahasa Azure AI baru.
Di jendela yang muncul, pilih Klasifikasi teks kustom & pengenalan entitas bernama kustom dari fitur kustom. Pilih Lanjutkan untuk membuat sumber daya Anda di bagian bawah layar.
Buat sumber daya Bahasa dengan detail berikut.
Nama Nilai yang diperlukan Langganan Langganan Azure Anda. Grup sumber daya Grup sumber daya yang akan berisi sumber daya Anda. Anda dapat menggunakan ruang kerja yang sudah ada atau membuat baru. Wilayah Salah satu wilayah yang didukung. Misalnya, "US Barat 2". Nama Nama sumber daya Anda. Tingkatan harga Salah satu tingkat harga yang didukung. Anda dapat menggunakan tingkat Gratis (F0) untuk mencoba layanan. Jika Anda mendapatkan pesan yang mengatakan "akun masuk Anda bukan pemilik grup sumber daya akun penyimpanan yang dipilih", akun Anda harus memiliki peran pemilik yang ditetapkan pada grup sumber daya sebelum Anda dapat membuat sumber daya Bahasa. Hubungi pemilik langganan Azure Anda untuk bantuan.
Anda dapat menentukan pemilik langganan Azure dengan mencari grup sumber daya Anda dan mengikuti tautan ke langganan terkait. lalu:
- Pilih tab Access Control (IAM)
- Pilih Penetapan peran
- Filter menurut Peran:Pemilik.
Di bagian Klasifikasi teks kustom & pengenalan entitas bernama kustom, pilih akun penyimpanan yang sudah ada atau pilih Akun penyimpanan baru. Perhatikan bahwa nilai ini untuk membantu Anda memulai, dan belum tentu nilai akun penyimpanan yang ingin Anda gunakan di lingkungan produksi. Untuk menghindari latensi selama membangun proyek Anda, sambungkan ke akun penyimpanan di wilayah yang sama dengan sumber daya Bahasa Anda.
Nilai akun penyimpanan Nilai yang direkomendasikan Nama akun penyimpanan Nama apa pun Jenis akun penyimpanan LRS Standar Pastikan Pemberitahuan AI yang Bertanggung Jawab diperiksa. Pilih Tinjau + buat di bagian bawah halaman.
Unggah data sampel ke kontainer blob
Setelah Anda membuat akun penyimpanan Azure dan menghubungkannya ke sumber daya Bahasa, Anda perlu mengunggah dokumen dari himpunan data sampel ke direktori akar kontainer Anda. Dokumen ini akan digunakan untuk melatih model Anda.
Unduh himpunan data sampel untuk proyek klasifikasi multi-label.
Buka file .zip, dan ekstrak folder yang berisi dokumen.
Himpunan data sampel yang disediakan berisi sekitar 200 dokumen, yang masing-masing merupakan ringkasan untuk film. Setiap dokumen milik satu atau beberapa kelas berikut:
- "Misteri"
- "Drama"
- "Thriller"
- "Komedi"
- "Aksi"
Di portal Azure, buka akun penyimpanan yang Anda buat, dan pilih. Anda dapat melakukan ini dengan mengklik Akun penyimpanan dan mengetikkan nama akun penyimpanan Anda ke filter untuk bidang apa pun.
jika grup sumber daya Anda tidak muncul, pastikan filter Langganan sama dengan diatur ke Semua.
Di akun penyimpanan Anda, pilih Kontainer dari menu kiri, yang terletak di bawah Penyimpanan data. Pada layar yang muncul, pilih + Kontainer. Beri kontainer nama contoh-data dan tinggalkan Tingkat akses publik default.
Setelah kontainer Anda dibuat, pilih itu. Lalu pilih tombol Unggah untuk memilih file dan
.jsonyang.txtAnda unduh sebelumnya.
Dapatkan kunci sumber daya dan titik akhir Anda
Buka halaman gambaran umum sumber daya Anda di portal Microsoft Azure
Dari menu sebelah kiri, pilih Kunci dan Titik Akhir. Anda akan menggunakan titik akhir dan kunci untuk permintaan API

Membuat proyek klasifikasi kustom
Setelah sumber daya serta kontainer penyimpanan Anda dikonfigurasi, buat proyek klasifikasi teks baru. Proyek adalah area kerja untuk membuat model ML kustom berdasarkan data Anda. Proyek Anda hanya dapat diakses oleh Anda dan orang lain yang memiliki akses ke sumber daya Bahasa yang digunakan.
Memicu pekerjaan proyek impor
Kirim permintaan POST menggunakan URL, header, dan isi JSON berikut untuk mengimpor file label Anda. Pastikan file label Anda mengikuti format yang diterima.
Jika sebuah proyek dengan nama yang sama sudah ada, data proyek tersebut diganti.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama untuk proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Isi
Gunakan JSON berikut dalam permintaan Anda. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Tombol | Placeholder | Value | Contoh |
|---|---|---|---|
| versi-api | {API-VERSION} |
Versi API yang Anda panggil. Versi yang digunakan di sini harus versi API yang sama dengan di URL. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
| projectKind | customMultiLabelClassification |
Jenis proyek Anda. | customMultiLabelClassification |
| bahasa | {LANGUAGE-CODE} |
String yang menentukan kode bahasa untuk dokumen yang digunakan dalam proyek Anda. Jika proyek Anda adalah proyek multi-bahasa, pilih kode bahasa dari sebagian besar dokumen. Lihat dukungan bahasa untuk mempelajari selengkapnya tentang dukungan multi-bahasa. | en-us |
| multilingual | true |
Nilai boolean yang memungkinkan Anda memiliki dokumen dalam beberapa bahasa dalam kumpulan data Anda dan ketika model Anda disebarkan, Anda dapat membuat kueri model dalam bahasa apa pun yang didukung (tidak harus disertakan dalam dokumen pelatihan Anda. Lihat dukungan bahasa untuk mempelajari selengkapnya tentang dukungan multi-bahasa. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Nama kontainer penyimpanan Azure tempat Anda mengunggah dokumen. | myContainer |
| kelas | [] | Array yang berisi semua kelas yang Anda miliki dalam proyek. Ini adalah kelas yang Anda inginkan untuk mengklasifikasikan dokumen Anda. | [] |
| Dokumen | [] | Array yang berisi semua dokumen dalam proyek Anda dan kelas yang diberi label untuk dokumen ini. | [] |
| lokasi | {DOCUMENT-NAME} |
Lokasi dokumen dalam kontainer penyimpanan. Karena semua dokumen berada di akar kontainer, ini akan menjadi nama dokumen. | doc1.txt |
| himpunan data | {DATASET} |
Set pengujian yang akan digunakan untuk dokumen ini saat dibagi sebelum pelatihan. Lihat Cara melatih model untuk informasi selengkapnya tentang pemisahan data. Nilai yang mungkin untuk bidang ini adalah Train dan Test. |
Train |
Setelah mengirim permintaan API, Anda akan menerima respons 202 yang menunjukkan bahwa pekerjaan telah dikirimkan dengan benar. Di header respons, ekstrak nilai operation-location. Nilai ini akan diformat seperti ini:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} digunakan untuk mengidentifikasi permintaan Anda, karena operasi ini tidak asinkron. Anda akan menggunakan URL ini untuk mendapatkan status pekerjaan impor.
Kemungkinan skenario kesalahan untuk permintaan ini:
- Sumber daya yang dipilih tidak memiliki izin yang sesuai untuk akun penyimpanan.
storageInputContainerNameyang ditentukan tidak ada.- Kode bahasa tidak valid digunakan, atau jika jenis kode bahasa bukan string.
- Nilai
multilingualadalah string dan bukan boolean.
Dapatkan Status pekerjaan impor
Gunakan permintaan GET berikut untuk mendapatkan status impor proyek Anda. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
Minta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{JOB-ID} |
ID untuk menemukan status pelatihan model Anda. Nilai ini ada di nilai header location yang Anda terima pada langkah sebelumnya. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Melatih model
Biasanya setelah Anda membuat proyek, Anda melanjutkan dan mulai memberi tag dokumen yang Anda miliki di kontainer yang terhubung ke proyek Anda. Untuk mulai cepat ini, Anda sudah mengimpor sampel himpunan data yang ditandai dan menginisialisasi proyek Anda dengan sampel file tag JSON.
Mulai latih model Anda
Setelah proyek Anda diimpor, Anda dapat mulai melatih model Anda.
Kirim permintaan POST menggunakan URL, header, dan isi JSON berikut untuk mengirimkan pekerjaan pelatihan. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Isi permintaan
Gunakan JSON berikut di isi permintaan Anda. Model akan diberi {MODEL-NAME} setelah pelatihan selesai. Hanya pekerjaan pelatihan yang berhasil yang akan menghasilkan model.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Tombol | Placeholder | Value | Contoh |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nama model yang akan ditetapkan ke model Anda setelah berhasil dilatih. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Ini adalah versi model yang akan digunakan untuk melatih model. | 2022-05-01 |
| evaluationOptions | Opsi untuk membagi data Anda di seluruh set pelatihan dan pengujian. | {} |
|
| jenis | percentage |
Memisahkan metode. Nilai yang mungkin adalah percentage atau manual. Lihat Cara melatih model untuk informasi selengkapnya. |
percentage |
| trainingSplitPercentage | 80 |
Persentase data Anda yang diberi tag untuk disertakan dalam set pelatihan. Nilai yang disarankan adalah 80. |
80 |
| testingSplitPercentage | 20 |
Persentase data Anda yang diberi tag untuk disertakan dalam set pengujian. Nilai yang disarankan adalah 20. |
20 |
Catatan
trainingSplitPercentage dan testingSplitPercentage hanya diperlukan jika Kind diatur ke percentage dan jumlah kedua persentase harus sama dengan 100.
Setelah mengirim permintaan API, Anda akan menerima respons 202 yang menunjukkan bahwa pekerjaan telah dikirimkan dengan benar. Di header respons, ekstrak nilai location. Nilai ini akan diformat seperti ini:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} digunakan untuk mengidentifikasi permintaan Anda, karena operasi ini tidak asinkron. Anda dapat menggunakan URL ini untuk mendapatkan status pelatihan.
Dapatkan status pekerjaan pelatihan
Pelatihan bisa memakan waktu antara 10 dan 30 menit. Anda dapat menggunakan permintaan berikut untuk terus melakukan polling status pekerjaan pelatihan hingga berhasil diselesaikan.
Gunakan permintaan GET berikut untuk mendapatkan status kemajuan pelatihan model Anda. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
Minta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{JOB-ID} |
ID untuk menemukan status pelatihan model Anda. Nilai ini ada di nilai header location yang Anda terima pada langkah sebelumnya. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Lihat Siklus hidup model untuk mempelajari selengkapnya mengenai versi API lain yang tersedia. | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Isi Respons
Setelah mengirim permintaan, Anda akan mendapatkan respons berikut.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Sebarkan model anda
Biasanya setelah melatih model, Anda akan meninjau detail evaluasi dan melakukan perbaikan jika perlu. Dalam mulai cepat ini, Anda hanya akan menyebarkan model Anda, dan membuatnya tersedia untuk Anda coba di Language Studio, atau Anda dapat memanggil API prediksi.
Mengirimkan pekerjaan penyebaran
Kirim permintaan PUT menggunakan URL, header, dan isi JSON berikut untuk mengirimkan tugas penyebaran. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{DEPLOYMENT-NAME} |
Nama penyebaran Anda. Nilai ini peka huruf besar/kecil. | staging |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Isi permintaan
Gunakan JSON berikut dalam isi permintaan Anda. Gunakan nama model yang akan Anda tetapkan ke penyebaran.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Tombol | Placeholder | Value | Contoh |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nama model yang akan ditetapkan ke penyebaran Anda. Anda hanya dapat menetapkan model yang berhasil dilatih. Nilai ini peka huruf besar/kecil. | myModel |
Setelah mengirim permintaan API, Anda akan menerima respons 202 yang menunjukkan bahwa pekerjaan telah dikirimkan dengan benar. Di header respons, ekstrak nilai operation-location. Nilai ini akan diformat seperti ini:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} digunakan untuk mengidentifikasi permintaan Anda, karena operasi ini tidak asinkron. Anda dapat menggunakan URL ini untuk mendapatkan status penyebaran.
Dapatkan status pekerjaan penyebaran
Gunakan permintaan GET berikut untuk menanyakan status tugas penyebaran. Anda dapat menggunakan URL yang Anda terima dari langkah sebelumnya, atau mengganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{DEPLOYMENT-NAME} |
Nama penyebaran Anda. Nilai ini peka huruf besar/kecil. | staging |
{JOB-ID} |
ID untuk menemukan status pelatihan model Anda. Ini ada dalam nilai header location yang Anda terima di langkah sebelumnya. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
Ocp-Apim-Subscription-Key |
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Isi Respons
Setelah mengirim permintaan, Anda akan mendapatkan respons berikut. Pertahankan polling titik akhir ini sampai parameter status berubah menjadi "berhasil". Anda harus mendapatkan 200 kode untuk menunjukkan keberhasilan permintaan.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Mengklasifikasikan teks
Setelah model berhasil disebarkan, Anda dapat mulai menggunakannya untuk mengklasifikasikan teks Anda melalui API Prediksi. Dalam himpunan data sampel yang Anda unduh sebelumnya, Anda dapat menemukan beberapa dokumen pengujian yang dapat Anda gunakan pada langkah ini.
Mengirimkan tugas klasifikasi teks kustom
Gunakan permintaan POST ini untuk memulai tugas klasifikasi teks.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Lihat Siklus hidup model untuk mempelajari selengkapnya tentang versi API lain yang tersedia. | 2022-05-01 |
Header
| Tombol | Nilai |
|---|---|
| Ocp-Apim-Subscription-Key | Kunci Anda yang menyediakan akses menuju API ini. |
Isi
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Tombol | Placeholder | Value | Contoh |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nama pekerjaan Anda. | MyJobName |
documents |
[{},{}] | Daftar dokumen untuk menjalankan tugas. | [{},{}] |
id |
{DOC-ID} |
ID atau nama dokumen. | doc1 |
language |
{LANGUAGE-CODE} |
String yang menentukan kode bahasa untuk dokumen. Jika kunci ini tidak ditentukan, layanan akan menggunakan bahasa default proyek yang dipilih saat pembuatan proyek. Lihat dukungan bahasa untuk daftar kode bahasa yang didukung. | en-us |
text |
{DOC-TEXT} |
Tugas dokumen untuk menjalankan tugas. | Lorem ipsum dolor sit amet |
tasks |
Daftar tugas yang ingin kami jalankan. | [] |
|
taskName |
CustomMultiLabelClassification | Nama tugas | CustomMultiLabelClassification |
parameters |
Daftar parameter untuk diteruskan ke tugas. | ||
project-name |
{PROJECT-NAME} |
Nama untuk proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nama penyebaran Anda. Nilai ini peka huruf besar/kecil. | prod |
Respons
Anda akan menerima respons 202 yang menunjukkan keberhasilan. Di header respons, ekstrak operation-location.
operation-location diformat sebagai berikut:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Anda dapat menggunakan URL ini untuk mengkueri status penyelesaian tugas dan mendapatkan hasil saat tugas selesai.
Mendapatkan hasil tugas
Gunakan permintaan GET berikut ini untuk mengkueri status/hasil tugas klasifikasi kustom.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi model terkini yang dirilis. | 2022-05-01 |
Header
| Tombol | Nilai |
|---|---|
| Ocp-Apim-Subscription-Key | Kunci Anda yang menyediakan akses menuju API ini. |
Isi respons
Respons akan menjadi dokumen JSON dengan parameter berikut.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Membersihkan sumber daya
Saat tidak lagi membutuhkan proyek, Anda dapat menghapusnya dengan permintaan DELETE berikut. Ganti nilai tempat penampung dengan nilai Anda sendiri.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Placeholder | Value | Contoh |
|---|---|---|
{ENDPOINT} |
Titik akhir untuk mengautentikasi permintaan API Anda. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nama untuk proyek Anda. Nilai ini peka huruf besar/kecil. | myProject |
{API-VERSION} |
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia | 2022-05-01 |
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
| Tombol | Nilai |
|---|---|
| Ocp-Apim-Subscription-Key | Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda. |
Setelah mengirim permintaan API, Anda akan menerima respons 202 yang menunjukkan keberhasilan, yang berarti proyek Anda telah dihapus. Hasil call yang sukses dengan header Operation-Location yang digunakan untuk memeriksa status pekerjaan.
Langkah berikutnya
Setelah membuat model klasifikasi teks, Anda dapat:
Ketika Anda mulai membuat proyek klasifikasi teks Anda sendiri, gunakan artikel petunjuk untuk mempelajari lebih lanjut cara mengembangkan model Anda secara lebih detail: