Memigrasikan data dari Cassandra ke akun Azure Cosmos DB for Apache Cassandra dengan menggunakan Azure Databricks
BERLAKU UNTUK: ![]() Cassandra
Cassandra
API untuk Cassandra di Azure Cosmos DB telah menjadi pilihan yang bagus untuk beban kerja perusahaan yang berjalan di Apache Cassandra karena beberapa alasan:
Tidak ada overhead untuk mengelola dan memantau: Menghilangkan overhead untuk mengelola dan memantau setelan di seluruh file OS, JVM, dan YAML dan interaksi mereka.
Penghematan biaya yang signifikan: Anda dapat menghemat biaya dengan Azure Cosmos DB yang mencakup biaya Komputer Virtual, bandwidth, dan lisensi yang berlaku. Anda tidak perlu mengelola pusat data, server, penyimpanan SSD, jaringan, dan biaya listrik.
Kemampuan untuk menggunakan kode dan alat yang ada: Azure Cosmos DB menyediakan kompatibilitas tingkat protokol kawat dengan Cassandra SDK dan alat yang ada. Kompatibilitas ini memastikan bahwa Anda dapat menggunakan basis kode yang ada dengan Azure Cosmos DB untuk Apache Cassandra dengan perubahan sepele.
Ada banyak cara untuk memigrasikan beban kerja database dari satu platform ke platform lainnya. Azure Databricks adalah layanan platform as a service (PaaS) untuk Apache Spark yang menawarkan cara untuk melakukan migrasi luring dalam skala besar. Artikel ini menjelaskan langkah-langkah yang diperlukan untuk memigrasikan data dari keyspace dan tabel Apache Cassandra asli ke dalam Azure Cosmos DB for Apache Cassandra dengan menggunakan Azure Databricks.
Prasyarat
Provisikan akun Azure Cosmos DB untuk Apache Cassandra.
Tinjau dasar-dasar menyambungkan ke Azure Cosmos DB untuk Apache Cassandra.
Tinjau fitur yang didukung di Azure Cosmos DB untuk Apache Cassandra untuk memastikan kompatibilitas.
Pastikan Anda telah membuat ruang kunci dan tabel kosong di akun Azure Cosmos DB for Apache Cassandra target Anda.
Kluster Penyediaan Azure Databricks
Anda dapat mengikuti instruksi untuk menyediakan klaster Azure Databricks. Sebaiknya pilih runtime Databricks versi 7.5 yang mendukung Spark 3.0.

Menambahkan dependensi
Anda perlu menambahkan pustaka Apache Spark Cassandra Connector ke klaster Anda untuk terhubung ke titik akhir asli dan Azure Cosmos DB Cassandra. Di klaster Anda, pilih Pustaka > Pasang Baru > Maven, lalu tambahkan com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 di koordinat Maven.
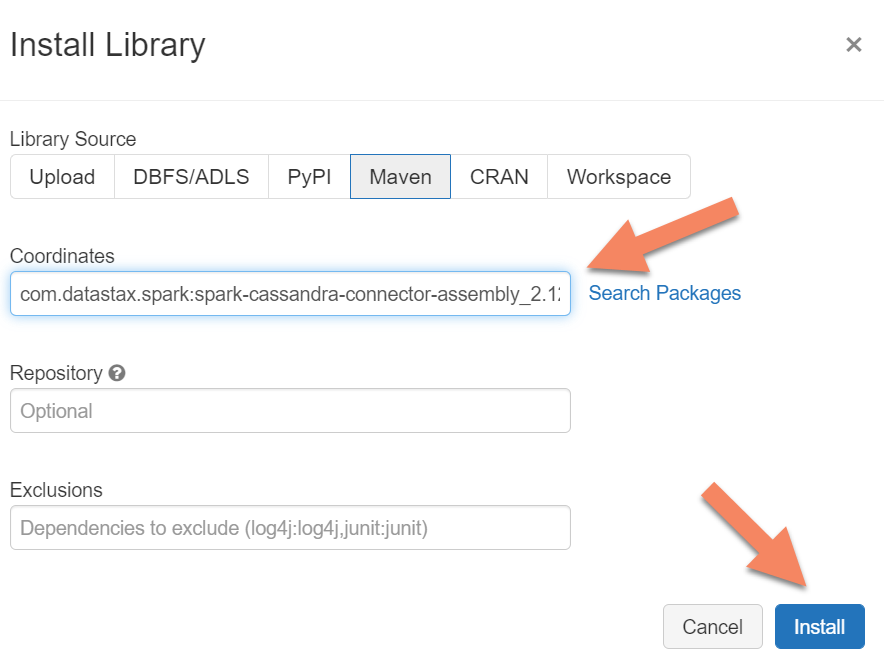
Pilih Pasang,lalu mulai ulang klaster ketika pemasangan selesai.
Catatan
Pastikan Anda memulai ulang klaster Databricks setelah pustaka Konektor Cassandra telah dipasang.
Peringatan
Sampel yang ditampilkan dalam artikel ini telah diuji dengan Spark versi 3.0.1 dan Cassandra Spark Connector yang sesuai com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Versi Spark dan/atau konektor Cassandra yang lebih baru mungkin tidak berfungsi seperti yang diharapkan.
Membuat Scala Notebook untuk migrasi
Membuat Scala Notebook di Databricks. Ganti konfigurasi Cassandra sumber dan target Anda dengan kredensial terkait, ruang kunci dan tabel sumber dan target. Kemudian jalankan perintah berikut:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Catatan
Nilai spark.cassandra.output.batch.size.rows dan spark.cassandra.output.concurrent.writes jumlah pekerja di klaster Spark Anda merupakan konfigurasi penting untuk menyesuaikan urutan demi menghindari pembatasan kecepatan. Pembatasan kecepatan terjadi ketika permintaan ke Azure Cosmos DB melebihi throughput yang disediakan atau unit permintaan (RU). Anda mungkin perlu menyesuaikan setelan ini, tergantung pada jumlah pelaksana di klaster Spark dan mungkin saja ukuran (dan biaya RU) dari setiap rekaman yang ditulis ke tabel target.
Pecahkan masalah
Pembatasan kecepatan (429 kesalahan)
Anda mungkin melihat kode kesalahan 429 atau teks kesalahan "permintaan kecepatan besar" meskipun setelah Anda mengurangi setelan ke nilai minimum. Skenario berikut dapat menyebabkan pembatasan kecepatan:
Throughput yang dialokasikan untuk tabel kurang dari 6.000 unit permintaan. Bahkan pada setelan minimum, Spark dapat menulis dengan kecepatan sekitar 6.000 unit permintaan atau lebih. Jika Anda telah menyediakan tabel di ruang kunci dengan throughput bersama, ada kemungkinan tabel ini memiliki kurang dari 6.000 RU yang tersedia pada waktu runtime.
Pastikan bahwa tabel yang Anda migrasikan memiliki setidaknya 6.000 RU yang tersedia saat Anda menjalankan migrasi. Jika perlu, alokasikan unit permintaan khusus ke tabel tersebut.
Data yang berlebihan condong dengan volume data yang besar. Jika Anda memiliki sejumlah besar data untuk dimigrasikan ke tabel tertentu tetapi memiliki kecondongan yang signifikan dalam data (yaitu sejumlah besar rekaman yang ditulis untuk nilai kunci partisi yang sama), maka Anda mungkin masih mengalami pembatasan kecepatan bahkan jika Anda memiliki beberapa unit permintaan yang disediakan dalam tabel Anda. Unit permintaan dibagi rata di antara partisi fisik, dan kecondongan data berat dapat menyebabkan penyempitan permintaan ke satu partisi.
Dalam skenario ini, kurangi setelan throughput minimal di Spark dan paksa migrasi berjalan lambat. Skenario ini bisa lebih umum ketika Anda memigrasikan tabel referensi atau kontrol yang aksesnya lebih jarang dan kecondongan bisa tinggi. Namun, jika kecondongan signifikan ada dalam jenis tabel lainnya, tinjau model data Anda untuk menghindari masalah partisi panas untuk beban kerja Anda selama keadaan operasi stabil.