Pemodelan data grafik dengan Azure Cosmos DB untuk Apache Gremlin
BERLAKU UNTUK: ![]() Gremlin
Gremlin
Artikel ini memberikan rekomendasi untuk penggunaan model data grafik. Praktik terbaik ini sangat penting untuk memastikan skalabilitas dan performa sistem database grafik seiring berkembangnya data. Model data yang efisien sangat penting untuk grafik skala besar.
Persyaratan
Proses yang diuraikan dalam panduan ini didasarkan pada berbagai asumsi berikut:
- Entitas dalam ruang masalah sudah teridentifikasi. Entitas ini dimaksudkan untuk dikonsumsi secara atomis untuk setiap permintaan. Dengan kata lain, sistem database tidak dirancang untuk mengambil data entitas tunggal dalam beberapa permintaan kueri.
- Ada pemahaman tentang persyaratan baca dan tulis untuk sistem database. Persyaratan ini memandu pengoptimalan yang diperlukan untuk model data grafik.
- Prinsip-prinsip standar grafik properti Apache Tinkerpop dipahami dengan baik.
Kapan saya memerlukan database grafik?
Solusi database grafik dapat digunakan secara optimal jika entitas dan hubungan dalam domain data memiliki salah satu karakteristik berikut:
- Entitas sangat terhubung melalui hubungan deskriptif. Manfaat dalam skenario ini adalah bahwa hubungan bertahan dalam penyimpanan.
- Ada hubungan siklus atau entitas yang direferensikan sendiri. Pola ini sering kali menjadi tantangan ketika Anda menggunakan database relasional atau dokumen.
- Ada hubungan yang berkembang secara dinamis antara beberapa entitas. Pola ini terutama berlaku atas data hierarkis atau berstruktur pohon dengan banyak tingkatan.
- Ada hubungan jamak-ke-jamak di antara beberapa entitas.
- Ada persyaratan tulis dan baca pada entitas dan juga hubungan.
Jika kriteria di atas terpenuhi, pendekatan database grafik kemungkinan memberikan keuntungan untuk kompleksitas kueri, skalabilitas model data, dan performa kueri.
Langkah selanjutnya adalah menentukan apakah grafik akan digunakan untuk tujuan analitik atau tujuan transaksional. Jika grafik dimaksudkan untuk digunakan untuk beban kerja komputasi dan pemrosesan data yang berat, ada baiknya menjelajahi konektor Cosmos DB Spark dan pustaka GraphX.
Cara menggunakan objek grafik
Standar grafik properti Apache Tinkerpop mendefinisikan dua jenis objek: simpul dan tepi.
Berikut ini adalah praktik terbaik untuk properti dalam objek grafik:
| Objek | Properti | Jenis | Catatan |
|---|---|---|---|
| Puncak | ID | String | Diberlakukan secara unik, per partisi. Jika nilai tidak disediakan saat penyisipan, GUID yang dihasilkan secara otomatis akan disimpan. |
| Puncak | Label | String | Properti ini digunakan untuk menentukan tipe entitas yang diwakili oleh puncak. Jika nilai tidak disediakan, vertex nilai default akan digunakan. |
| Puncak | Properti | String, boolean, numerik | Daftar properti terpisah yang disimpan sebagai pasangan nilai-kunci dalam setiap puncak. |
| Puncak | Kunci partisi | String, boolean, numerik | Properti ini mendefinisikan tempat puncak dan tepi keluarnya disimpan. Pelajari selengkapnya tentang pemartisian grafik. |
| Azure Stack Edge | ID | String | Diberlakukan secara unik, per partisi. Dibuat secara otomatis, secara default. Tepi biasanya tidak perlu diambil secara unik oleh ID. |
| Azure Stack Edge | Label | String | Properti ini digunakan untuk menentukan jenis hubungan yang dimiliki oleh dua simpul. |
| Azure Stack Edge | Properti | String, boolean, numerik | Daftar properti terpisah yang disimpan sebagai pasangan nilai-kunci dalam setiap tepi. |
Catatan
Tepi tidak memerlukan nilai kunci partisi, karena nilai secara otomatis ditetapkan berdasarkan verteks sumbernya. Pelajari selengkapnya di Menggunakan grafik yang dipartisi di Azure Cosmos DB.
Panduan pemodelan entitas dan hubungan
Panduan berikut membantu Anda mendekati pemodelan data untuk database grafik Azure Cosmos DB for Apache Gremlin . Panduan ini mengasumsikan terdapatnya definisi yang sudah ada dari domain data dan kueri untuk itu.
Catatan
Langkah-langkah berikut disajikan sebagai rekomendasi. Anda harus mengevaluasi dan menguji model akhir sebelum menganggapnya sebagai siap produksi. Selain itu, rekomendasi khusus untuk implementasi Gremlin API Azure Cosmos DB.
Memodelkan simpul dan properti
Langkah pertama untuk model data grafik adalah memetakan setiap entitas yang teridentifikasi ke objek puncak. Pemetaan satu-ke-satu dari semua entitas ke simpul harus menjadi langkah awal dan dapat berubah.
Salah satu kekeliruan yang umum terjadi adalah memetakan properti dari satu entitas menjadi beberapa simpul terpisah. Pertimbangkan contoh berikut, di mana entitas yang sama diwakili dengan dua cara berbeda:
Properti berbasis puncak: Dalam pendekatan ini, entitas menggunakan tiga simpul terpisah dan dua tepi untuk menggambarkan propertinya. Meskipun pendekatan ini dapat mengurangi redundansi, ini meningkatkan kompleksitas model. Peningkatan dalam kompleksitas model dapat mengakibatkan latensi tambahan, kompleksitas kueri, dan biaya komputasi. Model ini juga dapat menghadirkan tantangan dalam pemartisian.
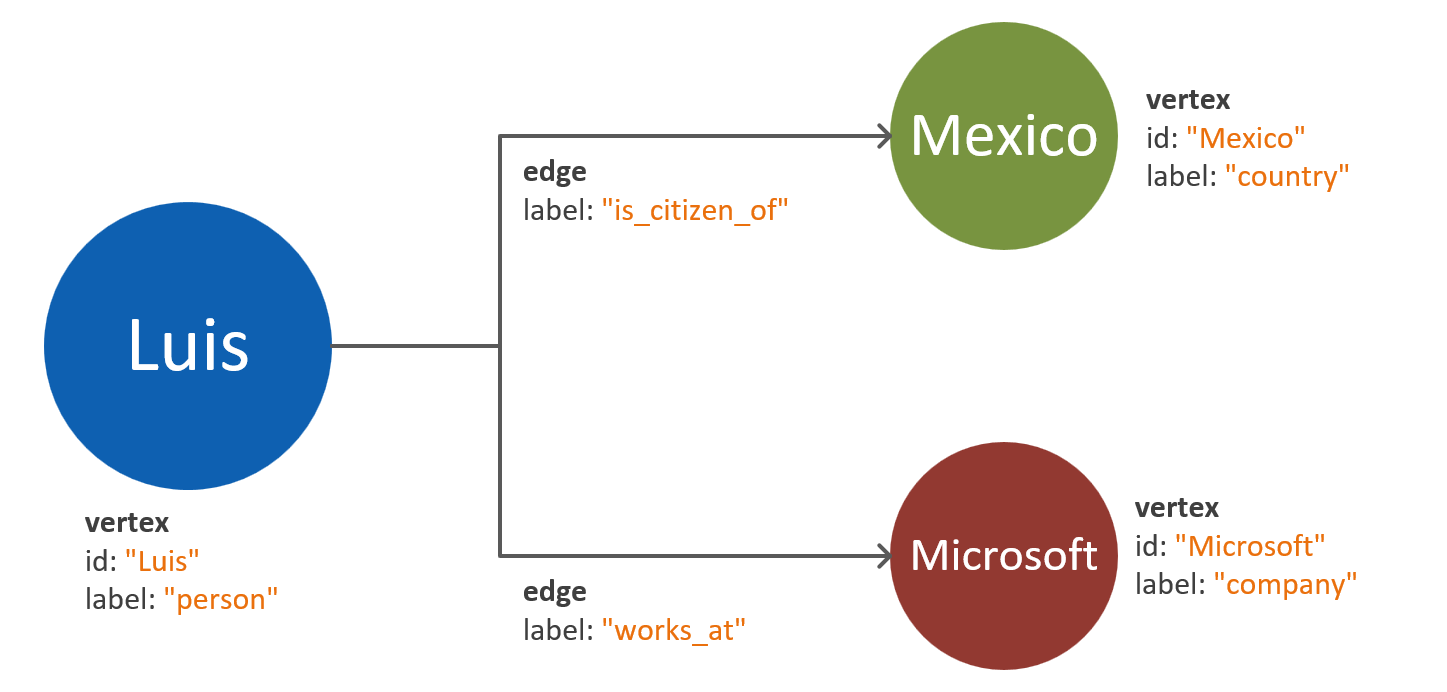
Simpul yang disematkan properti: Pendekatan ini memanfaatkan daftar pasangan kunci-nilai untuk mewakili semua properti entitas dalam suatu puncak. Pendekatan ini mengurangi kompleksitas model, yang mengarah pada kueri yang lebih sederhana dan traversal yang lebih hemat biaya.

Catatan
Diagram sebelumnya menunjukkan model grafik yang disederhanakan yang hanya membandingkan dua cara pembagian properti entitas.
Pola simpul yang disematkan properti pada umumnya memberikan pendekatan yang lebih berkinerja dan dapat diskalakan. Pendekatan default untuk model data grafik baru harus gravitasi terhadap pola ini.
Namun, ada skenario di mana merujuk properti mungkin memberikan keuntungan. Misalnya, jika properti yang dirujuk sering diperbarui. Gunakan vertex terpisah untuk mewakili properti yang terus berubah untuk meminimalkan jumlah operasi tulis yang diperlukan pembaruan.
Model hubungan dengan arah tepi
Setelah simpul dimodelkan, tepi dapat ditambahkan untuk menunjukkan hubungan di antara mereka. Aspek pertama yang perlu dievaluasi adalah arah hubungan.
Objek Edge memiliki arah default yang diikuti oleh traversal saat menggunakan out() fungsi atau outE() . Menggunakan arah alami ini menghasilkan operasi yang efisien, karena semua simpul disimpan dengan tepi keluar.
Namun, melintasi ke arah yang berlawanan dari tepi, menggunakan in() fungsi , selalu menghasilkan kueri lintas partisi. Pelajari selengkapnya tentang pemartisian grafik. Jika ada kebutuhan untuk terus melintas menggunakan fungsi in(), Anda disarankan untuk menambahkan tepi ke kedua arah.
Anda dapat menentukan arah tepi dengan menggunakan .to() atau .from() predikat dengan .addE() langkah Gremlin. Atau, gunakan pustaka pelaksana massal untuk Gremlin API.
Catatan
Objek Azure Stack Edge memiliki arah secara default.
Label hubungan
Menggunakan label hubungan deskriptif dapat meningkatkan efisiensi operasi resolusi tepi. Anda dapat menerapkan pola ini dengan cara berikut:
- Gunakan istilah non-generik untuk melabeli hubungan.
- Kaitkan label puncak sumber ke label puncak target dengan nama hubungan tersebut.
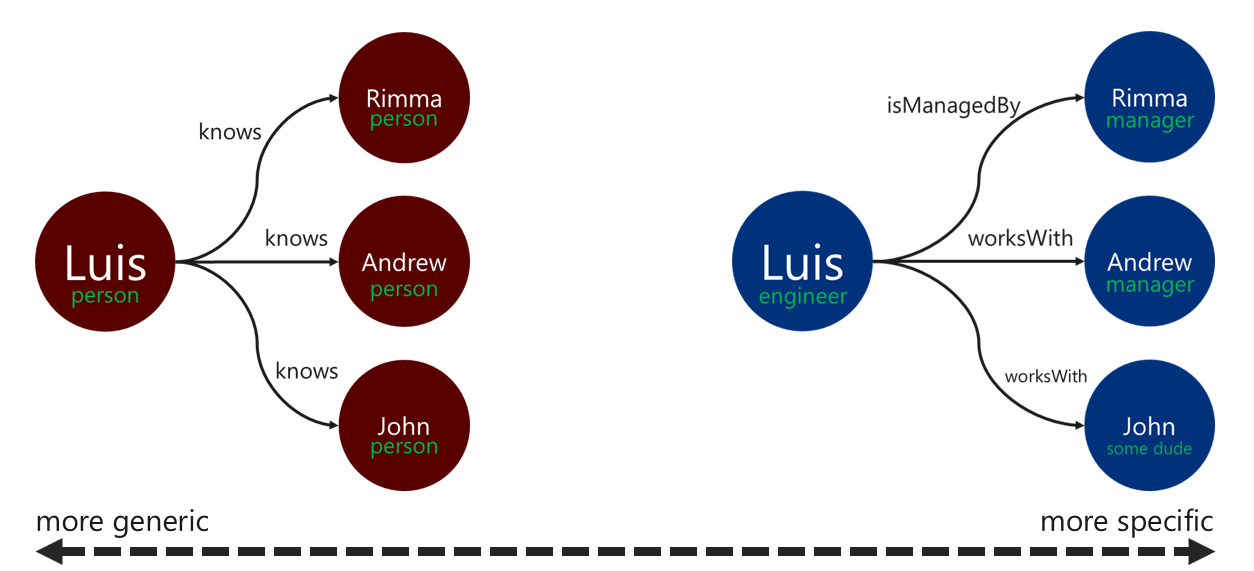
Semakin spesifik label yang digunakan traverser untuk memfilter tepi, semakin baik. Keputusan ini juga dapat berpengaruh signifikan pada biaya kueri. Anda dapat mengevaluasi biaya kueri kapan saja dengan menggunakan langkah executionProfile.
Langkah berikutnya
- Lihat daftar langkah-langkah Gremlin yang didukung.
- Pelajari tentang pemartisian database grafik untuk menangani grafik skala besar.
- Evaluasi kueri Gremlin Anda menggunakan langkah profil eksekusi.
- Model data desain grafik pihak ketiga.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk