Gambaran umum pengindeksan di Azure Cosmos DB
BERLAKU UNTUK: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Meja
Meja
Azure Cosmos DB adalah database skema-agnostik yang memungkinkan Anda melakukan iterasi pada aplikasi Anda tanpa harus berurusan dengan skema atau manajemen indeks. Secara default, Azure Cosmos DB secara otomatis mengindeks setiap properti untuk semua item dalam kontainer Anda tanpa harus menentukan skema apa pun atau mengonfigurasi indeks sekunder.
Artikel ini bertujuan untuk menjelaskan cara Azure Cosmos DB mengindeks data dan cara menggunakan indeks untuk meningkatkan performa kueri. Disarankan untuk melalui bagian ini sebelum menjelajahi cara menyesuaikan kebijakan pengindeksan.
Setiap kali item disimpan dalam kontainer, kontennya diproyeksikan sebagai dokumen JSON, lalu dikonversi menjadi representasi pohon. Konversi ini berarti bahwa setiap properti item tersebut direpresentasikan sebagai simpul di pohon. Node root semu dibuat sebagai induk untuk semua properti tingkat pertama item. Node daun berisi nilai skalar aktual yang dibawa oleh item.
Sebagai contoh, pertimbangkan item ini:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Pohon ini mewakili contoh item JSON:
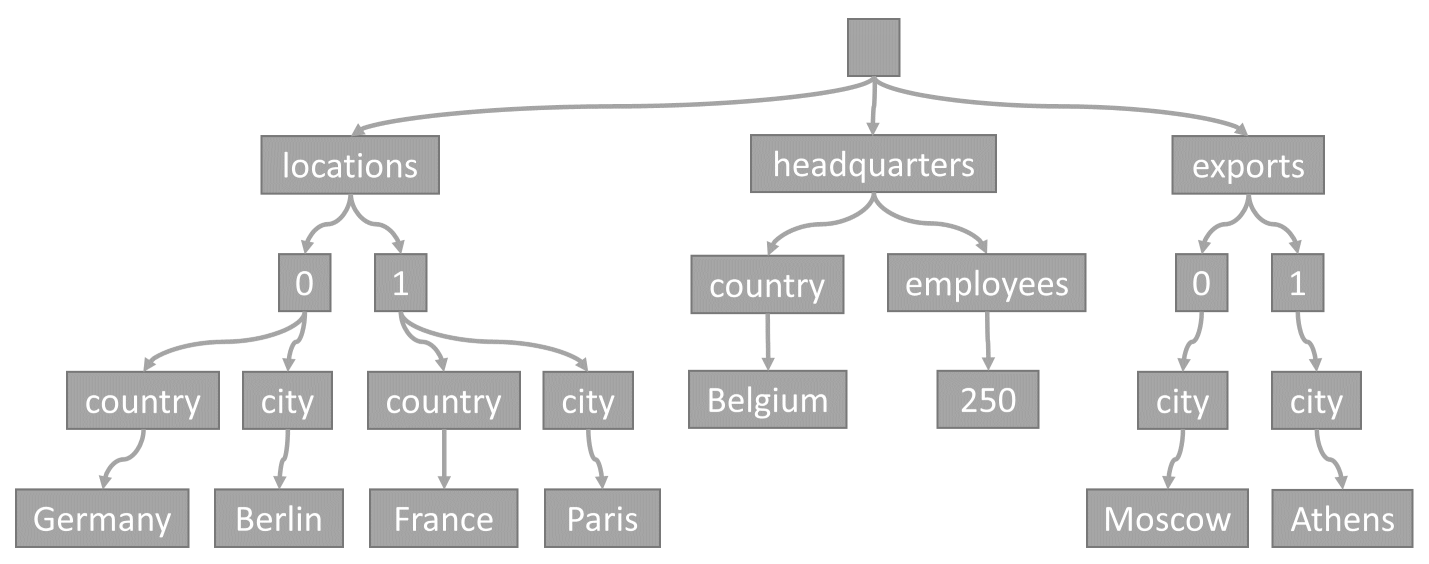
Perhatikan bagaimana array dikodekan di pohon: setiap entri dalam array mendapatkan node menengah yang dilabeli dengan indeks entri itu dalam array (0, 1 dll.).
Alasan mengapa Azure Cosmos DB mengubah item menjadi pohon adalah karena memungkinkan sistem untuk mereferensikan properti menggunakan jalur mereka di dalam pohon tersebut. Untuk mendapatkan jalur untuk properti, kita dapat melintasi pohon dari node akar ke properti itu, dan menggabungkan label dari setiap node yang dilalui.
Berikut adalah jalur untuk setiap properti dari item contoh yang dijelaskan sebelumnya:
/locations/0/country: "Jerman"/locations/0/city: "Berlin"/locations/1/country: "Prancis"/locations/1/city: "Paris"/headquarters/country: "Belgia"/headquarters/employees: 250/exports/0/city: "Moskow"/exports/1/city: "Athena"
Azure Cosmos DB secara efektif mengindeks jalur setiap properti dan nilai yang sesuai saat item ditulis.
Azure Cosmos DB saat ini mendukung tiga jenis indeks. Anda bisa mengonfigurasi jenis indeks ini ketika mendefinisikan kebijakan pengindeksan.
Indeks rentang didasarkan pada struktur seperti pohon yang diurutkan. Jenis indeks rentang digunakan untuk:
Kueri kesetaraan:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Kecocokan kesetaraan pada elemen array
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Kueri rentang:
SELECT * FROM container c WHERE c.property > 'value'Catatan
(bekerja untuk
>,<,>=,<=,!=)Memeriksa keberadaan properti:
SELECT * FROM c WHERE IS_DEFINED(c.property)Fungsi sistem string:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")Kueri
ORDER BY:SELECT * FROM container c ORDER BY c.propertyKueri
JOIN:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Indeks rentang dapat digunakan pada nilai skalar (string atau angka). Kebijakan pengindeksan default untuk kontainer yang baru dibuat memberlakukan indeks rentang untuk string atau nomor apa pun. Untuk mempelajari cara mengonfigurasi indeks rentang, lihat Contoh kebijakan pengindeksan rentang
Catatan
Klausa ORDER BY yang memerintah berdasarkan satu properti selalu memerlukan indeks rentang dan akan gagal jika jalur yang direferensikannya tidak memilikinya. Demikian pula, kueri ORDER BY yang memerintahkan berdasarkan beberapa properti selalu memerlukan indeks komposit.
Indeks Spasial memungkinkan kueri yang efisien pada objek geospasial, seperti points, lines, polygons, dan multipolygon. Kueri ini menggunakan kata kunci ST_DISTANCE, ST_WITHIN, ST_INTERSECTS. Berikut adalah beberapa contoh yang menggunakan jenis indeks spasial:
Kueri jarak geospasial:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geospasial dalam kueri:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Kueri berpotongan geospasial:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Indeks spasial dapat digunakan pada objek GeoJSON yang diformat dengan benar. Points, LineStrings, Polygons, dan MultiPolygons saat ini didukung. Untuk mempelajari cara mengonfigurasi indeks spasial, lihat Contoh kebijakan pengindeksan spasial
Indeks komposit meningkatkan efisiensi saat Anda melakukan operasi pada beberapa bidang. Jenis indeks komposit digunakan untuk:
Kueri
ORDER BYpada beberapa properti:SELECT * FROM container c ORDER BY c.property1, c.property2Kueri dengan filter dan
ORDER BY. Kueri ini dapat menggunakan indeks komposit jika properti filter ditambahkan ke klausaORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Kueri dengan filter pada dua properti atau lebih di mana setidaknya satu properti merupakan filter kesetaraan
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Selama satu predikat filter menggunakan salah satu jenis indeks, mesin kueri mengevaluasinya terlebih dahulu sebelum memindai sisanya. Misalnya, jika Anda memiliki kueri SQL seperti SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Kueri di atas terlebih dahulu akan memfilter entri dengan firstName = "Andrew" menggunakan indeks. Kemudian melewati semua entri firstName = "Andrew" melalui alur berikutnya untuk mengevaluasi predikat filter CONTAINS.
Anda dapat mempercepat kueri dan menghindari pemindaian kontainer penuh saat menggunakan fungsi yang melakukan pemindaian penuh seperti CONTAINS. Anda dapat menambahkan lebih banyak predikat filter yang menggunakan indeks untuk mempercepat kueri ini. Urutan klausa filter tidak penting. Mesin kueri mencari tahu predikat mana yang lebih selektif dan menjalankan kueri yang sesuai.
Untuk mempelajari cara mengonfigurasi indeks komposit, lihat Contoh kebijakan pengindeksan komposit
Indeks vektor meningkatkan efisiensi saat melakukan pencarian vektor menggunakan VectorDistance fungsi sistem. Pencarian vektor akan memiliki latensi yang jauh lebih rendah, throughput yang lebih tinggi, dan konsumsi RU yang lebih sedikit saat memanfaatkan indeks vektor.
Untuk mempelajari cara mengonfigurasi indeks vektor, lihat contoh kebijakan pengindeksan vektor
ORDER BYkueri pencarian vektor:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Proyeksi skor kesamaan dalam kueri pencarian vektor:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filter rentang pada skor kesamaan.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Penting
Saat ini, kebijakan vektor dan indeks vektor tidak dapat diubah setelah pembuatan. Untuk membuat perubahan, buat koleksi baru.
Ada lima cara agar mesin kueri dapat mengevaluasi filter kueri, diurutkan dari yang paling efisien hingga yang paling tidak efisien:
- Pencarian indeks
- Pemindaian indeks presisi
- Pemindaian indeks yang diperluas
- Pemindaian indeks penuh
- Pemindaian penuh
Saat Anda mengindeks jalur properti, mesin kueri secara otomatis menggunakan indeks seefisien mungkin. Selain mengindeks jalur properti baru, Anda tidak perlu mengonfigurasi apa pun untuk mengoptimalkan penggunaan indeks oleh kueri. Biaya RU kueri adalah kombinasi dari biaya RU dari penggunaan indeks dan biaya RU dari pemuatan item.
Berikut adalah tabel yang meringkas berbagai cara indeks digunakan di Azure Cosmos DB:
| Jenis pencarian indeks | Deskripsi | Contoh Umum | Biaya RU dari penggunaan indeks | Biaya RU dari memuat item dari penyimpanan data transaksional |
|---|---|---|---|---|
| Pencarian indeks | Membaca hanya nilai terindeks yang diperlukan dan memuat hanya item yang cocok dari tempat penyimpanan data transaksional | Filter kesetaraan, IN | Konstan per filter kesetaraan | Bertambah berdasarkan jumlah item dalam hasil kueri |
| Pemindaian indeks presisi | Melakukan pencarian biner dari nilai terindeks dan memuat hanya item yang cocok dari tempat penyimpanan data transaksional | Perbandingan rentang (>, <, <=, atau >=), StartsWith | Mirip dengan pencarian indeks, sedikit bertambah berdasarkan kardinalitas properti terindeks | Bertambah berdasarkan jumlah item dalam hasil kueri |
| Pemindaian indeks yang diperluas | Melakukan pencarian yang dioptimalkan (tetapi kurang efisien dibandingkan dengan pencarian biner) dari nilai terindeks dan memuat hanya item yang cocok dari tempat penyimpanan data transaksional | StartsWith (tidak peka huruf besar/kecil), StringEquals (tidak peka huruf besar/kecil) | Sedikit bertambah berdasarkan kardinalitas properti terindeks | Bertambah berdasarkan jumlah item dalam hasil kueri |
| Pemindaian indeks penuh | Membaca set berbeda dari nilai terindeks dan memuat hanya item yang cocok dari tempat penyimpanan data transaksional | Contains, EndsWith, RegexMatch, LIKE | Bertambah secara linier berdasarkan kardinalitas properti terindeks | Bertambah berdasarkan jumlah item dalam hasil kueri |
| Pemindaian penuh | Muat semua item dari tempat penyimpanan data transaksional | Upper, Lower | T/A | Bertambah berdasarkan jumlah item dalam kontainer |
Saat menulis kueri, Anda harus menggunakan predikat filter yang menggunakan indeks seefisien mungkin. Misalnya, jika atau StartsWith Contains akan berfungsi untuk kasus penggunaan Anda, Anda harus memilih StartsWith karena melakukan pemindaian indeks yang tepat alih-alih pemindaian indeks penuh.
Di bagian ini, kami membahas detail selengkapnya tentang cara kueri menggunakan indeks. Tingkat detail ini tidak perlu dipelajari untuk mulai menggunakan Azure Cosmos DB tetapi didokumentasikan secara rinci untuk pengguna yang penasaran. Kami mereferensikan item contoh yang dibagikan sebelumnya dalam dokumen ini:
Contoh item:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB menggunakan indeks terbalik. Indeks tersebut bekerja dengan memetakan setiap jalur JSON ke set item yang memuat nilai tersebut. Pemetaan ID item dinyatakan di banyak halaman indeks berbeda untuk kontainer. Berikut adalah contoh diagram indeks terbalik untuk kontainer yang menyertakan dua item contoh:
| Jalur | Nilai | Daftar ID item |
|---|---|---|
| /locations/0/country | Jerman | 1 |
| /locations/0/country | Ireland | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Prancis | 1 |
| /locations/1/city | Paris | 1 |
| /headquarters/country | Belgia | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
Indeks terbalik memiliki dua atribut penting:
- Untuk jalur tertentu, nilai diurutkan dalam urutan naik. Oleh karena itu, mesin kueri dapat dengan mudah menjalankan
ORDER BYdari indeks. - Untuk jalur tertentu, mesin kueri dapat memindai set berbeda dari nilai yang mungkin untuk mengidentifikasi halaman indeks tempat adanya hasil.
Mesin kueri dapat memanfaatkan indeks terbalik dengan empat cara yang berbeda:
Pertimbangkan kueri berikut:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Predikat kueri (pemfilteran pada item di mana lokasi mana pun memiliki "Prancis" sebagai negara/wilayahnya) akan cocok dengan jalur yang disorot dalam diagram ini:
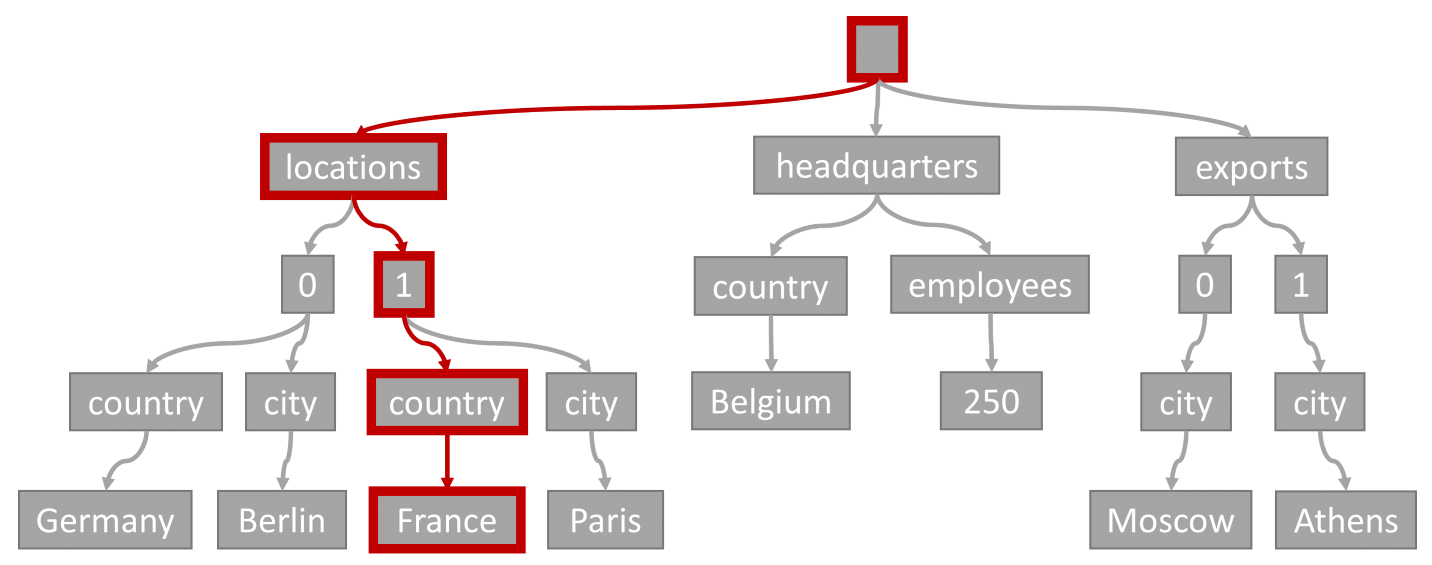
Karena kueri ini memiliki filter kesetaraan, setelah melintasi struktur pohon ini, kita dapat dengan cepat mengidentifikasi halaman indeks yang memuat hasil kueri. Dalam hal ini, mesin kueri akan membaca halaman indeks yang berisi Item 1. Pencarian indeks adalah cara paling efisien untuk menggunakan indeks. Dengan pencarian indeks, kami hanya membaca halaman indeks yang diperlukan dan hanya memuat item dalam hasil kueri. Oleh karena itu, waktu pencarian indeks dan biaya RU dari pencarian indeks sangat rendah, terlepas dari total volume data.
Pertimbangkan kueri berikut:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Predikat kueri (pemfilteran item yang memiliki lebih dari 200 karyawan) dapat dievaluasi dengan pemindaian indeks presisi jalur headquarters/employees. Saat melakukan pemindaian indeks presisi, mesin kueri akan mulai dengan melakukan pencarian biner terhadap set yang berbeda dari nilai yang mungkin untuk menemukan lokasi dari nilai 200 untuk jalur headquarters/employees. Karena nilai untuk setiap jalur diurutkan dalam urutan naik, mesin kueri dapat dengan mudah melakukan pencarian biner. Setelah berhasil menemukan nilai 200, mesin kueri akan mulai membaca semua halaman indeks yang tersisa (dengan arah naik).
Karena mesin kueri dapat melakukan pencarian biner untuk menghindari pemindaian halaman indeks yang tidak perlu, pemindaian indeks presisi cenderung memiliki latensi dan biaya RU yang sebanding dengan operasi pencarian indeks.
Pertimbangkan kueri berikut:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Predikat kueri (pemfilteran pada item yang memiliki kantor pusat di lokasi yang dimulai dengan "United" yang tidak peka huruf besar/kecil") dapat dievaluasi dengan pemindaian headquarters/country indeks jalur yang diperluas. Operasi yang melakukan pemindaian indeks yang diperluas memiliki pengoptimalan yang membuat operasi tersebut tidak perlu memindai setiap halaman indeks, tetapi biayanya sedikit lebih mahal daripada pencarian biner pemindaian indeks presisi.
Misalnya, saat mengevaluasi tidak peka huruf besar/kecil StartsWith, mesin kueri memeriksa indeks untuk kombinasi nilai huruf besar dan kecil yang mungkin berbeda. Pengoptimalan ini memungkinkan mesin kueri untuk menghindari membaca sebagian besar halaman indeks. Fungsi sistem yang berbeda memiliki pengoptimalan yang berbeda yang dapat mereka gunakan untuk menghindari membaca setiap halaman indeks, sehingga secara luas dikategorikan sebagai pemindaian indeks yang diperluas.
Pertimbangkan kueri berikut:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Predikat kueri (pemfilteran pada item yang memiliki kantor pusat di lokasi yang berisi "United") dapat dievaluasi dengan pemindaian headquarters/country indeks jalur. Tidak seperti pemindaian indeks yang tepat, pemindaian indeks penuh selalu memindai serangkaian nilai yang berbeda untuk mengidentifikasi halaman indeks di mana ada hasil. Dalam hal ini, Contains dijalankan pada indeks. Waktu pencarian indeks dan biaya RU untuk pemindaian indeks meningkat seiring dengan peningkatan kardinalitas jalur. Dengan kata lain, semakin banyak nilai berbeda yang mungkin yang perlu dipindai oleh mesin kueri, semakin tinggi juga latensi dan biaya RU yang diperlukan untuk melakukan pemindaian indeks penuh.
Misalnya, pertimbangkan dua properti: town dan country. Kardinalitas kota adalah 5.000 dan kardinalitas country adalah 200. Ini adalah dua contoh kueri yang masing-masing memiliki fungsi sistem Contains yang melakukan pemindaian indeks penuh pada properti town. Kueri pertama menggunakan lebih banyak RU daripada kueri kedua karena kardinalitas kota lebih tinggi dari country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Dalam beberapa kasus, mesin kueri mungkin tidak dapat mengevaluasi filter kueri dengan menggunakan indeks. Dalam hal ini, mesin kueri perlu memuat semua item dari penyimpanan transaksional untuk mengevaluasi filter kueri. Pemindaian penuh tidak menggunakan indeks dan memiliki biaya RU yang meningkat secara linier dengan ukuran data total. Untungnya, tidak banyak operasi yang membutuhkan pemindaian penuh.
Jika Anda tidak menentukan kebijakan indeks vektor dan menggunakan VectorDistance fungsi sistem dalam ORDER BY klausul, maka ini akan menghasilkan pemindaian Penuh dan memiliki biaya RU lebih tinggi daripada jika Anda menentukan kebijakan indeks vektor. Kesamaan, jika Anda menggunakan VectorDistance dengan nilai boolean brute force diatur ke true, dan tidak memiliki indeks yang flat ditentukan untuk jalur vektor, maka pemindaian penuh akan terjadi.
Dalam contoh sebelumnya, kita hanya mempertimbangkan kueri yang memiliki ekspresi filter sederhana (misalnya, kueri yang hanya memiliki satu filter kesetaraan atau rentang). Pada kenyataannya, sebagian besar kueri memiliki ekspresi filter yang jauh lebih kompleks.
Pertimbangkan kueri berikut:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Untuk menjalankan kueri ini, mesin kueri harus melakukan pencarian indeks pada headquarters/employees dan pemindaian indeks penuh pada headquarters/country. Mesin kueri memiliki heuristik internal yang digunakan untuk mengevaluasi ekspresi filter kueri seefisien mungkin. Dalam hal ini, mesin kueri akan menghindari pembacaan halaman indeks yang tidak perlu dengan melakukan pencarian indeks terlebih dahulu. Jika misalnya, hanya 50 item yang cocok dengan filter kesetaraan, mesin kueri hanya perlu mengevaluasi Contains pada halaman indeks yang berisi 50 item tersebut. Tidak perlu melakukan pemindaian indeks penuh terhadap seluruh kontainer.
Kueri dengan fungsi agregat harus bergantung secara eksklusif pada indeks agar dapat menggunakannya.
Dalam beberapa kasus, indeks dapat memberikan hasil positif palsu. Misalnya, saat mengevaluasi Contains pada indeks, jumlah kecocokan dalam indeks mungkin melebihi jumlah hasil kueri. Mesin kueri memuat semua kecocokan indeks, mengevaluasi filter pada item yang dimuat, dan hanya mengembalikan hasil yang benar.
Untuk sebagian besar kueri, memuat kecocokan indeks positif palsu tidak memiliki efek nyata pada pemanfaatan indeks.
Misalnya, pertimbangkan kueri di bawah ini:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Fungsi Contains sistem dapat mengembalikan beberapa kecocokan positif palsu, sehingga mesin kueri perlu memverifikasi apakah setiap item yang dimuat cocok dengan ekspresi filter. Dalam contoh ini, mesin kueri mungkin hanya perlu memuat beberapa item tambahan, sehingga efeknya pada pemanfaatan indeks dan biaya RU minimal.
Namun, kueri dengan fungsi agregat harus bergantung secara eksklusif pada indeks agar dapat menggunakannya. Misalnya, pertimbangkan kueri berikut dengan agregat Count:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Seperti dalam contoh pertama, fungsi sistem Contains dapat memberikan beberapa hasil kecocokan positif palsu. Namun, tidak seperti kueri SELECT *, kueri Count tidak dapat mengevaluasi ekspresi filter pada item yang dimuat untuk memverifikasi semua kecocokan indeks. Kueri Count harus mengandalkan indeks secara eksklusif, jadi jika ada kemungkinan ekspresi filter mengembalikan kecocokan positif palsu, mesin kueri akan menggunakan pemindaian penuh.
Kueri dengan fungsi agregat berikut harus bergantung secara eksklusif pada indeks, jadi pengevaluasian beberapa fungsi sistem memerlukan pemindaian penuh.
Baca selengkapnya tentang pengindeksan di artikel berikut ini: