Pemodelan data di Azure Cosmos DB
BERLAKU UNTUK: ![]() NoSQL
NoSQL
Sementara database bebas skema, seperti Azure Cosmos DB, membuatnya sangat mudah untuk menyimpan dan mengkueri data yang tidak terstruktur dan semi terstruktur, Anda harus menghabiskan waktu memikirkan model data Anda untuk mendapatkan sebagian besar layanan dalam hal performa dan skalabilitas dan biaya terendah.
Bagaimana data akan disimpan? Bagaimana aplikasi Anda akan mengambil dan meminta data? Apakah aplikasi Anda read-heavy, atau write-heavy?
Setelah membaca artikel ini, Anda akan dapat menjawab pertanyaan-pertanyaan berikut:
- Apa itu pemodelan data dan mengapa saya harus peduli?
- Bagaimana pemodelan data di Azure Cosmos DB berbeda dengan database relasional?
- Bagaimana cara mengekspresikan hubungan data dalam database non-relasional?
- Kapan saya menyematkan data dan kapan saya menautkan ke data?
Nomor dalam format JSON
Azure Cosmos DB menyimpan dokumen di JSON. Yang berarti perlu untuk dengan hati-hati menentukan apakah perlu untuk mengonversi angka menjadi string sebelum menyimpannya di json atau tidak. Semua angka idealnya harus dikonversi menjadi String, jika ada kemungkinan angka berada di luar batas angka presisi ganda menurut IEEE 754 binary64. Spesifikasi Json menyebutkan alasan penggunaan nomor di luar batas ini secara umum merupakan praktik yang buruk dalam format JSON karena kemungkinan masalah interoperabilitas. Kekhawatiran ini sangat relevan untuk kolom kunci partisi, karena tidak dapat diubah dan memerlukan migrasi data untuk mengubahnya nanti.
Menyematkan data
Ketika Anda mulai memodelkan data di Azure Cosmos DB, cobalah untuk memperlakukan entitas Anda sebagaiitem mandiri yang dinyatakan sebagai dokumen JSON.
Sebagai perbandingan, mari kita lihat terlebih dahulu bagaimana kita dapat memodelkan data dalam database relasional. Contoh berikut memperlihatkan bagaimana seseorang mungkin disimpan dalam database relasional.
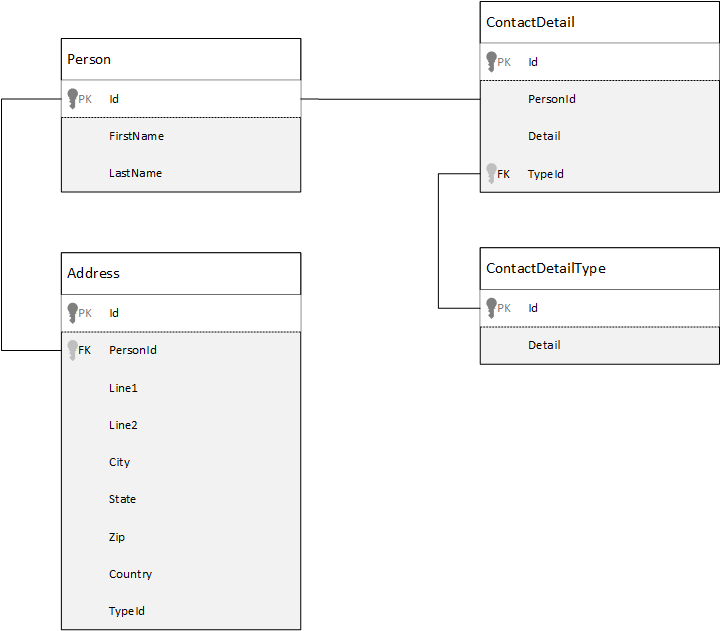
Saat bekerja dengan database relasional, strateginya adalah menormalkan semua data Anda. Menormalkan data Anda biasanya melibatkan pengambilan entitas, seperti seseorang, dan memecahnya menjadi komponen diskrit. Dalam contoh, seseorang mungkin memiliki beberapa catatan detail kontak, dan beberapa rekaman alamat. Detail kontak dapat dipecah lebih lanjut dengan mengekstraksi bidang umum lebih lanjut seperti jenis. Hal yang sama berlaku pada alamat, setiap catatan dapat berjenis Home atau Business.
Premis panduan saat menormalkan data adalah untuk menghindari penyimpanan data yang berlebihan pada setiap catatan dan lebih tepatnya merujuk ke data. Dalam contoh ini, untuk membaca seseorang, dengan semua detail dan alamat kontak mereka, Anda perlu menggunakan JOINS untuk secara efektif menyusun kembali (atau mendenormalisasi) data Anda pada waktu proses.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Operasi tulis di banyak tabel individual diperlukan untuk memperbarui detail dan alamat kontak satu orang.
Sekarang mari kita lihat bagaimana kita akan memodelkan data yang sama dengan entitas mandiri di Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Dengan menggunakan pendekatan ini, kami telah mendenormalisasi rekaman orang tersebut, dengan menyematkan semua informasi yang terkait dengan orang ini, seperti detail dan alamat kontak mereka, ke dalam satu dokumen JSON . Selain itu, karena kami tidak terbatas pada skema tetap, kami memiliki fleksibilitas untuk melakukan hal-hal seperti memiliki detail kontak dengan berbagai bentuk sepenuhnya.
Mengambil rekaman orang lengkap dari database sekarang menjadi tunggal operasi baca terhadap satu kontainer dan untuk satu item. Memperbarui rekaman seseorang, dengan detail dan alamat kontak mereka, juga merupakan operasi tulis tunggal terhadap satu item.
Dengan mendenormalisasi data, aplikasi Anda mungkin perlu mengeluarkan lebih sedikit kueri dan pembaruan untuk menyelesaikan operasi umum.
Saat yang tepat untuk menyematkan
Secara umum, gunakan model data yang disematkan saat:
- Ada hubungan yang terkandung antar entitas.
- Ada hubungan satu-ke-beberapa antar entitas.
- Ada data yang disematkan yang jarang berubah.
- Ada data yang disematkan yang tidak akan tumbuh tanpa ikatan.
- Ada data yang disematkan yang sering dikueri bersama.
Catatan
Biasanya model data yang dinormalisasi memberikan performa baca yang lebih baik.
Saat yang tidak tepat untuk menyematkan
Sementara aturan praktis di Azure Cosmos DB adalah untuk mendenormalisasi semuanya dan menanamkan semua data ke dalam satu item, ini dapat menyebabkan beberapa situasi yang harus dihindari.
Perhatikan cuplikan JSON ini.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Ini mungkin seperti apa entitas posting dengan komentar yang disematkan jika kami memodelkan blog biasa, atau CMS, sistem. Masalah dengan contoh ini adalah bahwa array komentar tidak terikat, yang berarti bahwa tidak ada batas (praktis) untuk jumlah komentar yang dapat dilihat oleh satu post. Ini mungkin menjadi masalah karena ukuran item dapat tumbuh sangat besar sehingga merupakan desain yang harus Anda hindari.
Seiring ukuran item berkembang, kemampuan untuk mengirimkan data melalui kabel serta membaca dan memperbarui item, dalam skala, maka akan berpengaruh.
Dalam hal ini, akan lebih baik untuk mempertimbangkan model data berikut.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Model ini memiliki dokumen untuk setiap komentar dengan properti yang berisi pengenal postingan. Hal ini memungkinkan posting berisi sejumlah komentar dan dapat berkembang secara efisien. Pengguna yang ingin melihat lebih banyak komentar terbaru akan meminta kontainer ini melewati postId yang harus menjadi kunci partisi untuk kontainer komentar.
Kasus lain dari lemahnya menyematkan data adalah saat data yang disematkan sering digunakan di seluruh item dan akan sering berubah.
Perhatikan cuplikan JSON ini.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Ini bisa mewakili portofolio saham seseorang. Kami telah memilih untuk menyematkan informasi saham ke dalam setiap dokumen portofolio. Pada lingkungan di mana data terkait sering berubah, seperti aplikasi perdagangan saham, menyematkan data yang sering berubah berarti Anda terus memperbarui setiap dokumen portofolio setiap kali saham diperdagangkan.
Saham zbzb mungkin diperdagangkan ratusan kali dalam satu hari dan ribuan pengguna dapat memiliki zbzb pada portofolio mereka. Dengan model data seperti contoh, kita harus memperbarui ribuan dokumen portofolio berkali-kali setiap hari yang mengarah ke sistem yang tidak akan menskalakan dengan baik.
Data referensi
Menyematkan data berfungsi dengan baik untuk banyak kasus tetapi ada skenario saat mendenormalisasi data Anda menyebabkan lebih banyak masalah daripada yang layak. Jadi apa yang harus kita lakukan sekarang?
Database hubungan bukan satu-satunya tempat di mana Anda dapat membuat hubungan antar entitas. Dalam database dokumen, Anda mungkin memiliki informasi dalam satu dokumen yang berkaitan dengan data di dokumen lain. Kami tidak merekomendasikan membangun sistem yang akan lebih cocok untuk database relasional di Azure Cosmos DB, atau database dokumen lainnya, tetapi hubungan sederhana baik-baik saja dan mungkin berguna.
Dalam JSON kami memilih untuk menggunakan contoh portofolio saham dari sebelumnya tetapi kali ini kami merujuk ke item saham pada portofolio alih-alih menyematkannya. Dengan cara ini, ketika item stok sering berubah sepanjang hari satu-satunya dokumen yang perlu diperbarui adalah dokumen stok tunggal.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Kelemahan langsung dari pendekatan ini adalah jika aplikasi Anda diperlukan untuk menampilkan informasi tentang setiap saham yang disimpan saat menampilkan portofolio seseorang; dalam hal ini Anda harus melakukan beberapa perjalanan ke database untuk memuat informasi untuk setiap dokumen saham. Di sini kami telah membuat keputusan untuk meningkatkan efisiensi operasi tulis, yang sering terjadi sepanjang hari, tetapi pada gilirannya dikompromikan pada operasi baca yang berpotensi kurang berdampak pada performa sistem khusus ini.
Catatan
Model data yang dinormalisasi dapat memerlukan lebih banyak putaran ke server.
Bagaimana dengan kunci asing?
Karena saat ini tidak ada konsep batasan, kunci asing atau sebaliknya, hubungan antar-dokumen yang Anda miliki dalam dokumen secara efektif menjadi "tautan lemah" dan tidak akan diverifikasi oleh database itu sendiri. Jika Anda ingin memastikan bahwa data yang dimaksud dokumen benar-benar ada, maka Anda perlu melakukan ini di aplikasi Anda, atau dengan menggunakan pemicu sisi server atau prosedur yang disimpan di Azure Cosmos DB.
Saat yang tepat untuk mereferensikan
Secara umum, gunakan model data yang dinormalkan saat:
- Mewakili hubungan satu-ke-banyak.
- Mewakili hubungan banyak-ke-banyak.
- Data terkait sering berubah.
- Data yang direferensikan dapat berupa tidak terikat.
Catatan
Biasanya normalisasi memberikan performa tulis yang lebih baik.
Di mana saya membuat hubungan?
Pertumbuhan hubungan membantu menentukan dokumen mana untuk menyimpan referensi.
Jika kita mengamati JSON yang memodelkan penerbit dan buku.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Jika jumlah buku per penerbit kecil dengan pertumbuhan terbatas, maka menyimpan referensi buku di dalam dokumen penerbit mungkin berguna. Namun, jika jumlah buku per penerbit tidak terbatas, model data ini akan menyebabkan array yang dapat diubah dan bertambah, seperti dalam contoh dokumen penerbit.
Beralih hal-hal di sekitar sedikit akan menghasilkan model yang masih mewakili data yang sama tetapi sekarang menghindari koleksi mutable besar ini.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
Dalam contoh ini, kami telah menghilangkan koleksi yang tidak terikat pada dokumen penerbit. Sebaliknya kita hanya memiliki referensi ke penerbit pada setiap dokumen buku.
Bagaimana cara memodelkan relasi banyak ke banyak?
Dalam database relasional relasi banyak ke banyak sering dimodelkan dengan tabel gabungan, yang hanya menggabungkan rekaman dari tabel lain bersama-sama.
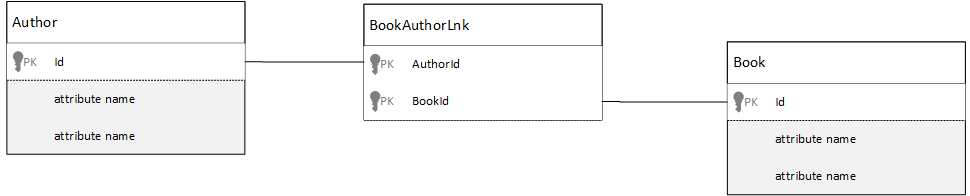
Anda mungkin tergoda untuk mereplikasi hal yang sama menggunakan dokumen dan menghasilkan model data yang terlihat mirip dengan yang berikut ini.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Ini akan berhasil. Namun, memuat penulis dengan buku mereka, atau memuat buku dengan penulisnya, akan selalu memerlukan setidaknya dua kueri tambahan terhadap database. Satu kueri ke dokumen gabungan lalu kueri lain untuk mengambil dokumen aktual yang sedang digabungkan.
Jika gabungan ini hanya menggabungkan dua bagian dari data, lalu mengapa tidak menghilangkan seluruhnya? Pertimbangkan contoh berikut.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Sekarang, jika saya memiliki penulis, saya segera tahu buku mana yang telah mereka tulis, dan sebaliknya jika saya memiliki dokumen buku yang dimuat, saya akan tahu ID penulis. Ini menyimpan kueri perantara terhadap tabel gabungan yang mengurangi jumlah perjalanan pulang pergi server yang harus dilakukan aplikasi Anda.
Model data hibrid
Kami sekarang telah melihat penyisipan (atau denormalisasi) dan referensi (atau normalisasi) data. Setiap pendekatan memiliki kelebihan dan kekurangan.
Tidak selalu harus baik atau, jangan takut untuk mencampur hal-hal sedikit.
Berdasarkan pola penggunaan dan beban kerja spesifik aplikasi Anda, mungkin ada kasus di mana pencampuran data yang disematkan dan direferensikan masuk akal dan dapat menyebabkan logika aplikasi yang lebih sederhana dengan lebih sedikit perjalanan pulang pergi server sambil tetap mempertahankan tingkat performa yang baik.
Pertimbangkan JSON berikut.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Di sini kami telah (sebagian besar) mengikuti model yang disematkan, di mana data dari entitas lain disematkan di dokumen tingkat teratas, tetapi data lain direferensikan.
Jika Anda melihat dokumen buku, kita dapat melihat beberapa bidang yang menarik ketika kita melihat array penulis. Ada bidang id yang merupakan bidang yang kita gunakan untuk merujuk kembali ke dokumen penulis, praktik standar dalam model yang dinormalisasi, tetapi kemudian kita juga memiliki name dan thumbnailUrl. Kita bisa memakai id dan membiarkan aplikasi menerima banyak informasi tambahan yang diperlukan dari penulis masing-masing dokumen menggunakan "tautan", tetapi karena aplikasi kita menampilkan nama penulis dan foto thumbnail dengan setiap buku yang ditampilkan, kita bisa menyimpan putaran ke server per buku dalam suatu daftar dengan mendenormalisasikan beberapa data dari penulis.
Tentunya, jika nama penulis berubah atau mereka ingin memperbarui foto mereka, kita harus memperbarui setiap buku yang pernah diterbitkan tetapi untuk aplikasi kami, berdasarkan asumsi bahwa penulis tidak sering mengubah nama mereka, ini adalah keputusan desain yang dapat diterima.
Dalam contoh, ada nilai agregat yang telah dihitung sebelumnya untuk menghemat pemrosesan mahal pada operasi baca. Dalam contoh, beberapa data yang disematkan dalam dokumen penulis adalah data yang dihitung pada run-time. Setiap kali buku baru diterbitkan, dokumen buku dibuat dan bidang countOfBooks diatur ke nilai terhitung berdasarkan jumlah dokumen buku yang ada untuk penulis tertentu. Optimalisasi ini akan baik dalam membaca sistem berat di mana kita mampu melakukan komputasi pada tulisan untuk mengoptimalkan bacaan.
Kemampuan untuk memiliki model dengan bidang yang telah dihitung sebelumnya dimungkinkan karena Azure Cosmos DB mendukung transaksi multi-dokumen. Banyak toko NoSQL tidak dapat melakukan transaksi di seluruh dokumen dan oleh karena itu menganjurkan keputusan desain, seperti "selalu sematkan semuanya," karena keterbatasan ini. Dengan Azure Cosmos DB, Anda dapat menggunakan pemicu sisi server, atau prosedur tersimpan, yang menyisipkan buku dan memperbarui penulis semuanya dalam transaksi ACID. Sekarang Anda tidak perlu menanamkan semuanya ke dalam satu dokumen hanya untuk memastikan bahwa data Anda tetap konsisten.
Membedakan antara berbagai jenis dokumen
Dalam beberapa skenario, Anda mungkin ingin mencampur jenis dokumen yang berbeda dalam koleksi yang sama; ini biasanya terjadi ketika Anda ingin beberapa dokumen terkait duduk di partisi yang sama. Misalnya, Anda dapat menempatkan buku dan ulasan buku dalam koleksi yang sama dan mempartisinya dengan bookId. Dalam situasi seperti itu, Anda biasanya ingin menambahkan dokumen Anda dengan bidang yang mengidentifikasi jenisnya untuk membedakannya.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Pemodelan data untuk Azure Synapse Link dan penyimpanan analitik Azure Cosmos DB
Azure Synapse Link untuk Azure Cosmos DB adalah kemampuan pemrosesan transaksional dan analitik hibrida native cloud yang memungkinkan Anda menjalankan analitik mendekati real-time melalui data operasional di Azure Cosmos DB. Azure Synapse Link menciptakan integrasi mulus yang ketat antara Azure Cosmos DB dan Azure Synapse Analytics.
Integrasi ini terjadi melalui penyimpanan analitik Azure Cosmos DB, representasi berskala kolom dari data transaksional Anda yang memungkinkan analitik berskala besar tanpa berdampak pada beban kerja transaksional Anda. Penyimpanan analitik ini cocok untuk kueri yang cepat dan hemat biaya pada himpunan data operasional yang besar, tanpa menyalin data dan memengaruhi performa beban kerja transaksional Anda. Saat Anda membuat kontainer dengan penyimpanan analitik yang diaktifkan, atau saat Anda mengaktifkan penyimpanan analitik pada kontainer yang ada, semua penyisipan, pembaruan, dan penghapusan transaksional disinkronkan dengan penyimpanan analitik hampir secara real time, tidak diperlukan Pengubahan Umpan maupun ETL.
Dengan Azure Synapse Link, Anda sekarang dapat langsung terhubung ke kontainer Azure Cosmos DB dari Azure Synapse Analytics dan mengakses penyimpanan analitik, tanpa biaya RU (unit permintaan). Azure Synapse Analytics saat ini mendukung Azure Synapse Link dengan Synapse Apache Spark dan kluster SQL tanpa server. Jika Anda memiliki akun Azure Cosmos DB yang didistribusikan secara global, setelah Anda mengaktifkan penyimpanan analitis untuk kontainer, itu akan tersedia di semua wilayah untuk akun tersebut.
Inferensi skema otomatis penyimpanan analitik
Meskipun penyimpanan transaksi Azure Cosmos DB dianggap sebagai data semi terstruktur berorientasi baris, penyimpanan analitik memiliki format kolom dan terstruktur. Konversi ini dibuat secara otomatis untuk pelanggan, menggunakan aturan inferensi skema untuk penyimpanan analitik. Terdapat batasan dalam proses konversi: jumlah maksimum tingkat berlapis, jumlah maksimum properti, jenis data yang tidak didukung, dan lainnya.
Catatan
Dalam konteks penyimpanan analitik, kami menganggap struktur berikut sebagai properti:
- JSON "elemen" atau "pasangan nilai string yang dipisahkan oleh
:". - Objek JSON, dibatasi oleh
{dan}. - Array JSON, dibatasi oleh
[dan].
Anda dapat mengecilkan dampak konversi inferensi skema, dan memaksimalkan kapabilitas analitis Anda, dengan menggunakan teknik berikut ini.
Normalisasi kasus
Normalisasi menjadi tidak berarti, karena dengan Azure Synapse Link Anda dapat bergabung di antara kontainer Anda menggunakan T-SQL atau Spark SQL. Keuntungan normalisasi yang diharapkan adalah:
- Ruang data yang lebih kecil di penyimpanan transaksional dan analitis.
- Transaksi lebih kecil.
- Properti per dokumen lebih sedikit.
- Struktur data dengan tingkat berlapis lebih sedikit.
Dua faktor terakhir ini, lebih sedikit properti dan lebih sedikit tingkat, membantu performa kueri analitik Anda tetapi juga mengurangi kemungkinan bagian data Anda tidak diwakili di penyimpanan analitik. Seperti yang dijelaskan dalam artikel tentang aturan inferensi skema otomatis, ada batasan untuk jumlah tingkatan dan properti yang dinyatakan dalam penyimpanan analitik.
Faktor penting lainnya untuk normalisasi adalah bahwa kumpulan tanpa server SQL di Azure Synapse mendukung tataan hasil dengan hingga 1.000 kolom, dan mengekspos kolom berlapis juga diperhitungkan dalam batas tersebut. Dengan kata lain, penyimpanan analitik dan kumpulan tanpa server Synapse SQL memiliki batas 1.000 properti.
Namun, apa yang harus dilakukan karena denormalisasi adalah teknik pemodelan data yang penting untuk Azure Cosmos DB? Jawabannya adalah Anda harus menemukan keseimbangan yang tepat untuk beban kerja transaksional dan analitis Anda.
Kunci Partisi
Kunci partisi (PK) Azure Cosmos DB Anda tidak digunakan di penyimpanan analitik. Dan sekarang Anda bisa menggunakan partisi khusus penyimpanan analitik untuk menyalin penyimpanan analitik menggunakan PK yang Anda inginkan. Karena isolasi ini, Anda dapat memilih PK untuk data transaksional dengan fokus pada penyerapan data dan pembacaan titik, sementara kueri lintas partisi dapat dilakukan dengan Azure Synapse Link. Mari kita lihat contohnya:
Dalam skenario IoT global hipotetis, device id merupakan PK yang baik karena semua perangkat memiliki volume data yang serupa dan dengan itu Anda tidak akan mengalami masalah partisi panas. Tetapi jika Anda ingin menganalisis data lebih dari satu perangkat, seperti "semua data dari kemarin" atau "total per kota," Anda mungkin memiliki masalah karena itu adalah kueri lintas partisi. Kueri tersebut dapat merusak performa transaksional Anda karena kueri-kueri ini menggunakan bagian dari throughput dalam unit permintaan agar dijalankan. Namun, dengan Azure Synapse Link, Anda dapat menjalankan kueri analitik ini tanpa biaya unit permintaan. Format kolom penyimpanan analitik dioptimalkan untuk kueri analitik dan Azure Synapse Link menerapkan karakteristik ini untuk memungkinkan performa yang baik dengan runtime Azure Synapse Analytics.
Jenis data dan nama properti
Artikel aturan inferensi skema otomatis mencantumkan jenis data yang didukung. Meskipun jenis data yang tidak didukung memblokir representasi di penyimpanan analitik, jenis data yang didukung mungkin diproses secara berbeda oleh runtime Azure Synapse. Salah satu contohnya adalah: Ketika menggunakan string DateTime yang mengikuti standar UTC ISO 8601, kluster Spark di Azure Synapse akan menunjukkan kolom ini sebagai string, dan kluster SQL tanpa server di Azure Synapse akan menunjukkan kolom ini sebagai varchar(8000).
Tantangan lainnya adalah tidak semua karakter diterima oleh Azure Synapse Spark. Meskipun spasi putih diterima, namun karakter seperti titik dua, aksen nontirus, dan koma tidak diterima. Katakanlah, dokumen Anda memiliki properti bernama "Nama Depan, Nama Belakang". Properti ini diwakili di penyimpanan analitik dan kumpulan tanpa server Synapse SQL dapat membacanya tanpa masalah. Namun karena tersedia dalam penyimpanan analitik, Azure Synapse Spark tidak dapat membaca data sama sekali dari penyimpanan analitik, termasuk semua properti lainnya. Pada akhirnya, Anda tidak dapat menggunakan Azure Synapse Spark apabila Anda memiliki satu properti yang namanya menggunakan karakter yang tidak didukung.
Perataan data
Semua properti di tingkat akar data Azure Cosmos DB Anda akan diwakili di penyimpanan analitis sebagai kolom dan segala sesuatu yang berada di tingkat yang lebih dalam dari model data dokumen Anda akan direpresentasikan sebagai JSON, juga dalam struktur berlapis. Struktur berlapis menuntut pemrosesan ekstra dari runtime Azure Synapse untuk meratakan data dalam format terstruktur, apa yang mungkin menjadi tantangan dalam skenario big data.
Dokumen hanya akan memiliki dua kolom di penyimpanan analitis, id dan contactDetails. Semua data lainnya, email dan phone, akan memerlukan pemrosesan ekstra melalui fungsi SQL untuk dibaca satu per satu.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Dokumen akan memiliki tiga kolom di penyimpanan analitis, , idemail, dan phone. Semua data dapat diakses secara langsung sebagai kolom.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Tingkatan data
Azure Synapse Link memungkinkan Anda mengurangi biaya dari perspektif berikut:
- Lebih sedikit kueri yang berjalan di database transaksional.
- PK yang dioptimalkan untuk penyerapan data dan pembacaan titik, mengurangi ruang data, skenario partisi panas, dan pemisahan partisi.
- Tingkatan data karena time-to-live (attl) analitik tidak tergantung pada time-to-live (attl) transaksional. Anda dapat menyimpan data transaksional di penyimpanan transaksional selama beberapa hari, minggu, bulan, dan menyimpan data di penyimpanan analitik selama bertahun-tahun bahkan selama-lamanya. Format kolom penyimpanan analitik menghadirkan pemadatan data yang alami, dari 50% hingga 90%. Dan biaya per GB adalah ~10% dari harga penyimpanan transaksional sebenarnya. Untuk informasi selengkapnya tentang batasan file cadangan saat ini, lihat ringkasan penyimpanan analitik.
- Tidak ada pekerjaan ETL yang berjalan di lingkungan Anda, yang berarti bahwa Anda tidak perlu menyediakan unit permintaan untuk mereka.
Redundansi terkontrol
Ini merupakan alternatif tepat untuk situasi ketika model data sudah ada dan tidak dapat diubah. Dan model data yang sudah ada tidak cocok dengan penyimpanan analitik karena aturan inferensi skema otomatis seperti batas tingkat berlapis atau jumlah maksimum properti. Jika demikian, Anda dapat menggunakan Perubahan Umpan Azure Cosmos DB untuk mereplikasi data Anda ke kontainer lain, menerapkan transformasi yang diperlukan untuk model data yang ramah Azure Synapse Link. Mari kita lihat contohnya:
Skenario
Kontainer CustomersOrdersAndItems digunakan untuk menyimpan pesanan on-line termasuk detail pelanggan dan item: alamat penagihan, alamat pengiriman, metode pengiriman, status pengiriman, harga item, dll. Hanya 1.000 properti pertama yang diwakili dan informasi utama tidak disertakan dalam penyimpanan analitis, memblokir penggunaan Azure Synapse Link. Kontainer memiliki PB rekaman, tidak dimungkinkan untuk mengubah aplikasi dan merombak data.
Perspektif lain dari masalah ini adalah volume data yang besar. Miliaran baris terus digunakan oleh Departemen Analitik, yang mencegahnya untuk menggunakan tttl untuk penghapusan data lama. Mempertahankan seluruh riwayat data dalam database transaksional karena kebutuhan analitis memaksanya untuk terus meningkatkan penyediaan unit permintaan, yang berdampak pada biaya. Beban kerja transaksional dan analitis bersaing untuk sumber daya yang sama secara bersamaan.
Apa yang harus dilakukan?
Solusi dengan Pengubahan Umpan
- Tim teknisi memutuskan untuk menggunakan Ubah Umpan untuk mengisi tiga kontainer baru:
Customers,Orders, danItems. Dengan Change Feed mereka akan menormalisasi dan meratakan data. Informasi yang tidak diperlukan dihapus dari model data dan setiap kontainer memiliki hampir 100 properti, menghindari kehilangan data karena batas inferensi skema otomatis. - Kontainer baru ini telah mengaktifkan penyimpanan analitik dan saat ini Departemen Analitik menggunakan Synapse Analytics untuk membaca data, mengurangi penggunaan unit permintaan karena kueri analitik terjadi di Synapse Apache Spark dan kluster SQL tanpa server.
- Kontainer
CustomersOrdersAndItemssekarang memiliki tttl yang diatur untuk menyimpan data selama enam bulan saja, yang memungkinkan pengurangan penggunaan unit permintaan lain, karena ada minimal satu unit permintaan per GB di Azure Cosmos DB. Lebih sedikit data, maka lebih sedikit unit permintaan.
Poin-poin penting
Takeaway terbesar dari artikel ini adalah memahami bahwa pemodelan data di dunia yang bebas skema sama pentingnya dengan sebelumnya.
Sama seperti tidak adanya cara tunggal untuk mewakili sepotong data di layar, tidak ada pula cara tunggal untuk memodelkan data Anda. Anda perlu memahami aplikasi Anda dan bagaimana aplikasi menghasilkan, mengonsumsi, dan memproses data. Kemudian, dengan menerapkan beberapa pedoman yang disajikan di sini Anda dapat mengatur tentang membuat model yang membahas kebutuhan mendesak aplikasi Anda. Ketika aplikasi Anda perlu diubah, Anda dapat menggunakan fleksibilitas database bebas skema untuk merangkul perubahan itu dan mengembangkan model data Anda dengan mudah.