Memigrasikan data dari MongoDB ke akun Azure Cosmos DB for MongoDB dengan menggunakan Azure Databricks
BERLAKU UNTUK: ![]() MongoDB
MongoDB
Panduan migrasi ini adalah bagian dari seri pada migrasi database dari MongoDB ke Azure Cosmos DB API untuk MongoDB. Langkah-langkah migrasi yang penting adalah pra-migrasi, migrasi, dan pasca-migrasi, seperti yang ditunjukkan di bawah ini.
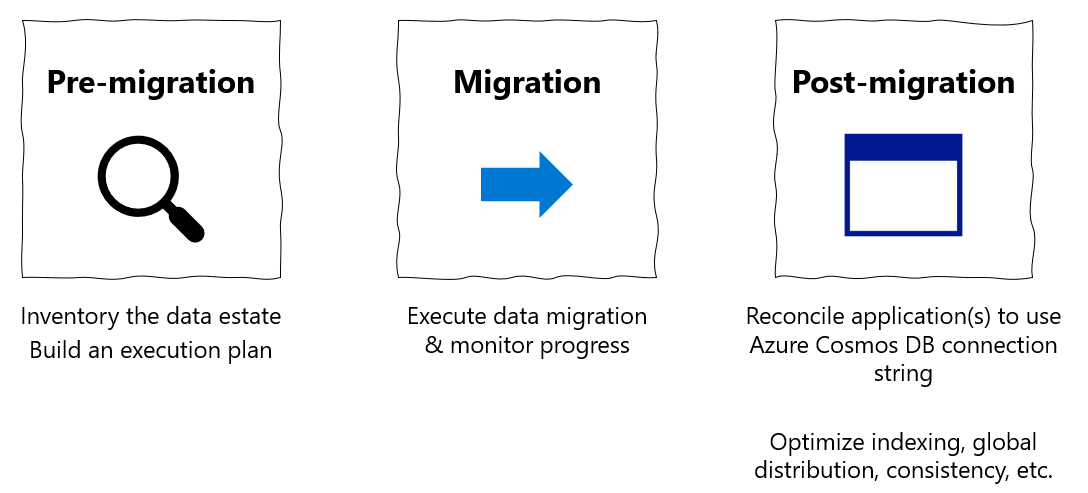
Migrasi data menggunakan Azure Databricks
Azure Databricks adalah penawaran platform sebagai layanan (PaaS) untuk Apache Spark. Azure Databricks menawarkan cara untuk melakukan migrasi secara offline pada himpunan data skala besar. Anda dapat menggunakan Azure Databricks untuk melakukan migrasi database offline dari MongoDB ke Azure Cosmos DB untuk MongoDB.
Dalam tutorial ini, Anda akan belajar cara:
Kluster Penyediaan Azure Databricks
Menambahkan dependensi
Buat dan jalankan Scala atau Python notebook
Optimalkan performa migrasi
Memecahkan masalah kesalahan pembatasan laju yang mungkin terlihat selama migrasi
Prasyarat
Untuk menyelesaikan tutorial ini, Anda perlu:
- Selesaikan langkah-langkah pra-migrasi seperti memperkirakan throughput dan memilih kunci shard.
- Buat akun Azure Cosmos DB untuk MongoDB.
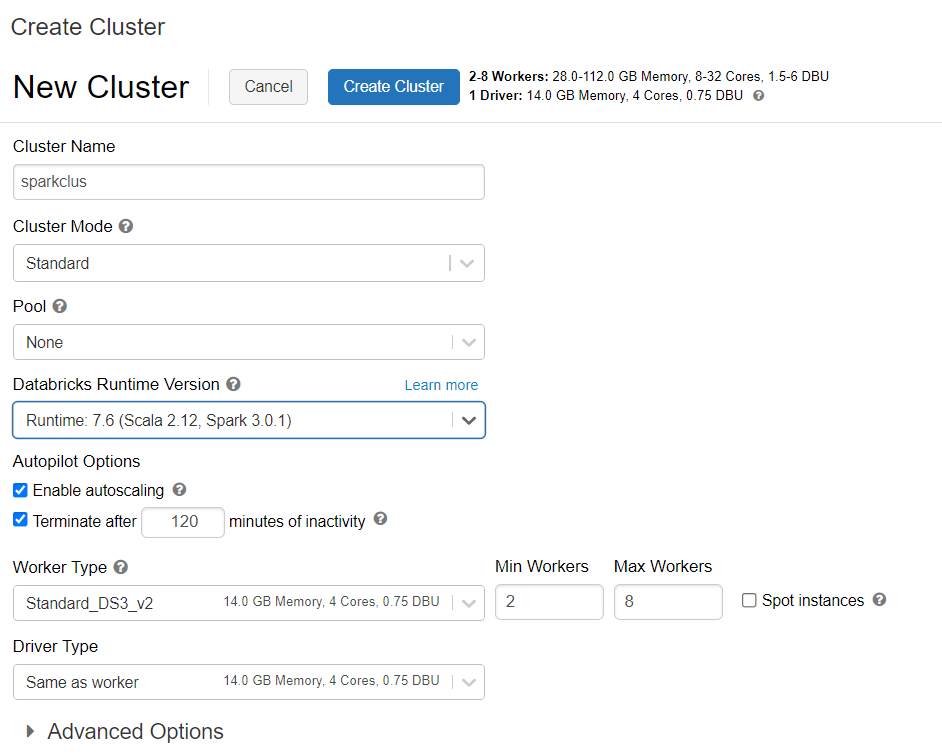
Kluster Penyediaan Azure Databricks
Anda dapat mengikuti instruksi untuk menyediakan klaster Azure Databricks. Sebaiknya pilih runtime bahasa umum Databricks versi 7.6 yang mendukung Spark 3.0.
Menambahkan dependensi
Tambahkan konektor MongoDB untuk pustaka Spark ke kluster Anda untuk menyambungkan ke titik akhir MongoDB dan Azure Cosmos DB for MongoDB asli. Di kluster Anda, pilih Pustaka>Pasang Baru>Maven, lalu tambahkan org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 koordinat Maven.
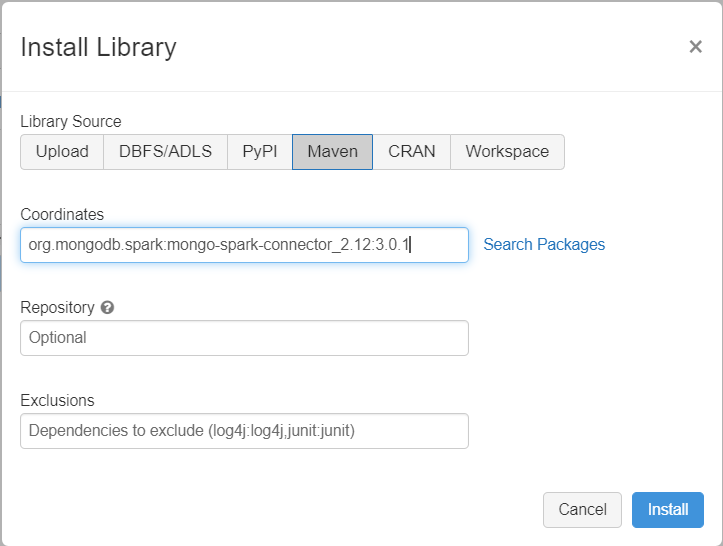
Pilih Pasang,lalu mulai ulang klaster ketika pemasangan selesai.
Catatan
Pastikan Anda menghidupkan ulang kluster Databricks setelah Konektor MongoDB untuk pustaka Spark telah dipasang.
Setelah itu, Anda dapat membuat Scala atau Python notebook untuk migrasi.
Membuat Scala notebook untuk migrasi
Membuat Scala Notebook di Databricks. Pastikan untuk memasukkan nilai yang tepat untuk variabel sebelum menjalankan kode berikut:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Membuat notebook Phyton untuk migrasi
Membuat Phyton Notebook di Databricks. Pastikan untuk memasukkan nilai yang tepat untuk variabel sebelum menjalankan kode berikut:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimalkan performa migrasi
Performa migrasi dapat disesuaikan melalui konfigurasi berikut:
Jumlah pekerja dan inti dalam kluster Spark: Lebih banyak pekerja berarti lebih banyak pecahan komputasi untuk menjalankan tugas.
maxBatchSize: Nilai
maxBatchSizemengendalikan laju saat data disimpan ke koleksi Azure Cosmos DB target. Namun, jika maxBatchSize terlalu tinggi untuk throughput koleksi, hal ini bisa menyebabkan kesalahan pembatasan laju.Anda perlu menyesuaikan jumlah pekerja dan maxBatchSize, tergantung pada jumlah eksekutor di kluster Spark, sepertinya pada ukuran (dan itulah mengapa RU dikenakan biaya) dari setiap dokumen yang ditulis dan batas throughput koleksi target.
Tip
maxBatchSize = Throughput koleksi/( Biaya RU untuk 1 dokumen * jumlah pekerja Spark * jumlah inti CPU per pekerja )
Partisi dan partitionKey MongoDB Spark: Partisi default yang digunakan adalah MongoDefaultPartitioner sedangkan partitionKey default adalah _id. Partisi dapat diubah dengan menetapkan nilai
MongoSamplePartitionerke properti konfigurasi inputspark.mongodb.input.partitioner. Demikian pula, partitionKey dapat diubah dengan menetapkan nama bidang yang sesuai ke properti konfigurasi inputspark.mongodb.input.partitioner.partitionKey. PartitionKey yang tepat dapat membantu menghindari penyimpangan data (sejumlah besar rekaman yang ditulis untuk nilai kunci shard yang sama).Nonaktifkan indeks selama transfer data: Untuk migrasi data dalam jumlah besar, pertimbangkan untuk menonaktifkan indeks, khususnya indeks kartubebas pada koleksi target. Indeks meningkatkan biaya RU untuk penulisan setiap dokumen. Membebaskan RU ini dapat membantu meningkatkan kecepatan transfer data. Anda dapat mengaktifkan indeks setelah data selesai dimigrasikan.
Pecahkan masalah
Kesalahan Batas Waktu (Kode galat 50)
Anda mungkin melihat kode kesalahan 50 untuk operasi terhadap database Azure Cosmos DB for MongoDB. Skenario berikut dapat menyebabkan kesalahan batas waktu:
- Throughput yang dialokasikan ke database rendah: Pastikan bahwa koleksi target telah memiliki throughput yang cukup.
- Data yang berlebihan condong dengan volume data yang besar. Jika Anda memiliki sejumlah besar data untuk dimigrasikan ke tabel tertentu tetapi memiliki penyimpangan data yang signifikan, Anda mungkin masih mengalami pembatasan kecepatan bahkan jika Anda memiliki beberapa unit permintaan yang tersedia dalam tabel Anda. Unit permintaan dibagi rata di antara partisi fisik dan penyimpangan data yang berat dapat menyebabkan penyempitan permintaan ke satu shard. Penyimpangan data berarti terdapat rekaman berjumlah besar untuk nilai kunci shard yang sama.
Pembatasan kecepatan (Kode galat 16500)
Anda mungkin melihat kode kesalahan 16500 untuk operasi terhadap database Azure Cosmos DB for MongoDB. Ini adalah kesalahan pembatasan kecepatan dan dapat diamati pada akun lama atau akun dengan fitur percobaan ulang sisi server yang dinonaktifkan.
- Mengaktifkan percobaan ulang sisi Server: Aktifkan fitur Percobaan Ulang Sisi Server (SSR) dan biarkan server mencoba kembali operasi pembatasan kecepatan secara otomatis.
Pengoptimalan pasca migrasi
Setelah memigrasikan data, Anda dapat menyambungkan ke Azure Cosmos DB dan mengelola data. Anda juga dapat mengikuti langkah pasca-migrasi lainnya seperti mengoptimalkan kebijakan pengindeksan, memperbarui tingkat konsistensi default, atau mengonfigurasi distribusi global untuk akun Azure Cosmos DB Anda. Untuk informasi lebih lanjut, lihat artikel Pengoptimalan pasca-migrasi.
Sumber Daya Tambahan:
- Mencoba melakukan perencanaan kapasitas untuk migrasi ke Azure Cosmos DB?
- Jika Anda hanya mengetahui jumlah vcore dan server di kluster database yang ada, baca tentang memperkirakan unit permintaan menggunakan vCore atau vCPU
- Jika Anda mengetahui rasio permintaan umum untuk beban kerja database Anda saat ini, baca memperkirakan unit permintaan menggunakan perencana kapasitas Azure Cosmos DB