Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Important
Azure Cosmos DB for PostgreSQL berada di jalur penghentian dan tidak lagi direkomendasikan untuk proyek baru. Sebagai gantinya, gunakan salah satu dari dua layanan ini:
Untuk beban kerja PostgreSQL : gunakan fitur Elastic Clusters dari Azure Database For PostgreSQL untuk menggunakan fitur PostgreSQL skala horizontal dan terdistribusi yang terkandung dalam ekstensi Citus sumber terbuka. Untuk panduan migrasi, lihat migrasi ke Azure Database for PostgreSQL dengan Elastic Cluster.
Untuk beban kerja NoSQL, gunakan Azure Cosmos DB untuk NoSQL untuk solusi database terdistribusi yang mencakup perjanjian tingkat layanan ketersediaan (SLA) 99,999%, skala otomatis instan, dan failover otomatis di beberapa wilayah.
Kolokasi berarti menyimpan informasi terkait bersama-sama pada simpul yang sama. Kueri bisa berjalan cepat ketika semua data yang diperlukan tersedia tanpa ada lalu lintas jaringan. Kolokasi data terkait pada simpul yang berbeda memungkinkan kueri berjalan secara efisien secara paralel pada setiap simpul.
Penempatan bersama data untuk tabel yang didistribusikan dengan hash
Di Azure Cosmos DB for PostgreSQL, sebuah baris disimpan dalam shard jika hash dari nilai di kolom distribusi jatuh ke dalam rentang hash shard tersebut. Pecahan dengan rentang hash yang sama selalu ditempatkan pada simpul yang sama. Baris dengan nilai kolom distribusi yang sama selalu berada pada simpul yang sama di seluruh tabel. Konsep tabel terdistribusi hash juga dikenal sebagai sharding berbasis baris. Dalam sharding berbasis skema, tabel dalam skema terdistribusi selalu dikolokasi.
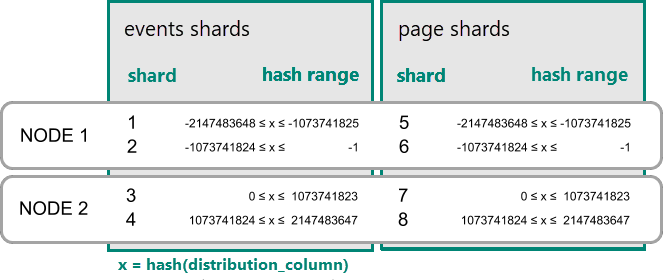
Contoh praktis dari kolokasi
Pertimbangkan tabel berikut yang mungkin merupakan bagian dari SaaS analitik web multipenyewa:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Sekarang kami ingin menjawab pertanyaan yang mungkin dikeluarkan oleh dasbor yang berinteraksi dengan pelanggan. Contoh kueri adalah "Tunjukkan jumlah kunjungan dalam seminggu terakhir untuk semua halaman yang dimulai dengan '/blog' untuk klien enam."
Jika data kami berada dalam satu server PostgreSQL, kami dapat dengan mudah mengekspresikan kueri kami dengan menggunakan serangkaian operasi relasional yang kaya yang ditawarkan oleh SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Selama kumpulan kerja untuk kueri ini pas dalam memori, tabel server tunggal adalah solusi yang tepat. Mari kita pertimbangkan peluang penskalaan model data dengan Azure Cosmos DB for PostgreSQL.
Mendistribusikan tabel sesuai ID
Kueri server tunggal mulai melambat seiring dengan bertambahnya jumlah penyewa dan data yang disimpan untuk setiap penyewa. Jumlah kerja tidak lagi cocok dalam memori dan CPU menjadi hambatan.
Dalam hal ini, kita dapat memecah data di banyak simpul dengan menggunakan Azure Cosmos DB for PostgreSQL. Pilihan pertama dan terpenting yang perlu kita buat ketika kita memutuskan untuk pecahan adalah kolom distribusi. Mari kita mulai dengan pilihan naif menggunakan event_id untuk tabel acara dan page_id untuk tabel page.
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Ketika data tersebar di berbagai pekerja, kita tidak dapat melakukan penggabungan seperti yang kita lakukan pada satu simpul PostgreSQL. Sebaliknya, kita perlu mengeluarkan dua pertanyaan:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Setelah itu, hasil dari dua langkah tersebut perlu digabungkan oleh aplikasi.
Menjalankan kueri harus mengakses data dalam pecahan yang tersebar di seluruh simpul.
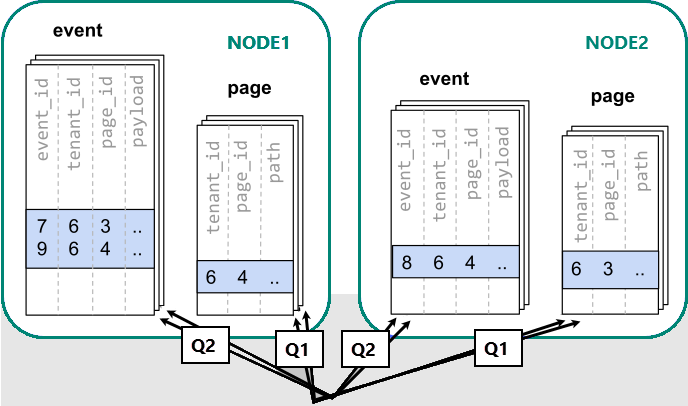
Dalam hal ini, distribusi data menciptakan kelemahan substansial:
- Overhead dari melakukan kueri pada setiap shard dan menjalankan beberapa kueri.
- Beban Q1 dalam mengembalikan banyak baris ke klien.
- Q2 menjadi besar.
- Kebutuhan untuk menulis kueri dalam beberapa langkah memerlukan perubahan dalam aplikasi.
Data tersebar, sehingga kueri dapat disejajarkan. Ini hanya bermanfaat jika jumlah pekerjaan yang dilakukan oleh kueri secara substansial lebih besar daripada biaya melakukan kueri pada banyak shard.
Mendistribusikan tabel menurut penyewa
Di Azure Cosmos DB for PostgreSQL, baris dengan nilai kolom distribusi yang sama dijamin berada di simpul yang sama. Mulai dari awal, kita dapat membuat tabel kita dengan tenant_id sebagai kolom distribusi.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Sekarang Azure Cosmos DB for PostgreSQL dapat menjawab kueri server tunggal asli tanpa modifikasi (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Karena filter dan penggabungan pada tenant_id, Azure Cosmos DB for PostgreSQL mengetahui bahwa seluruh kueri dapat dijawab dengan menggunakan kumpulan shard yang terkolokasi yang berisi data untuk penyewa tertentu. Satu simpul PostgreSQL dapat menjawab kueri dalam satu langkah.
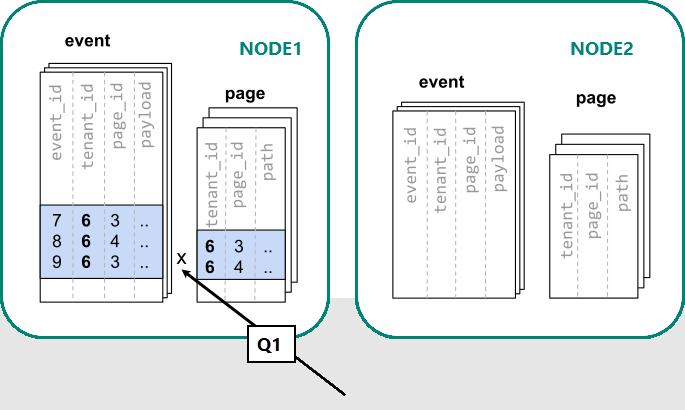
Dalam beberapa kasus, kueri dan skema tabel harus diubah untuk menyertakan ID penyewa dalam batasan unik dan kondisi gabungan. Perubahan ini biasanya mudah.
Langkah berikutnya
- Lihat bagaimana data penyewa dikolokasikan dalam tutorial multipenyewa.