Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Azure Cosmos DB for PostgreSQL tidak lagi didukung untuk proyek baru. Jangan gunakan layanan ini untuk proyek baru. Sebagai gantinya, gunakan salah satu dari dua layanan ini:
Gunakan Azure Cosmos DB for NoSQL untuk solusi database terdistribusi yang dirancang untuk skenario skala tinggi dengan perjanjian tingkat layanan ketersediaan (SLA) 99,999%, skala otomatis instan, dan failover otomatis di beberapa wilayah.
Gunakan fitur Elastic Clusters dari Azure Database For PostgreSQL untuk PostgreSQL yang dipecah menggunakan ekstensi Citus sumber terbuka.
Dalam tutorial ini, Anda menggunakan Azure Cosmos DB for PostgreSQL untuk mempelajari cara:
- Membuat kluster
- Menggunakan utilitas psql untuk membuat skema
- Mendistribusikan tabel di seluruh simpul
- Memasukkan data sampel
- Kueri data penyewa
- Berbagi data di antara penyewa
- Menyesuaikan skema setiap penyewa
Prasyarat
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Membuat kluster
Masuk ke portal Azure dan ikuti langkah-langkah ini untuk membuat kluster Azure Cosmos DB for PostgreSQL:
Pergi ke Buat kluster Azure Cosmos DB untuk PostgreSQL di portal Azure.
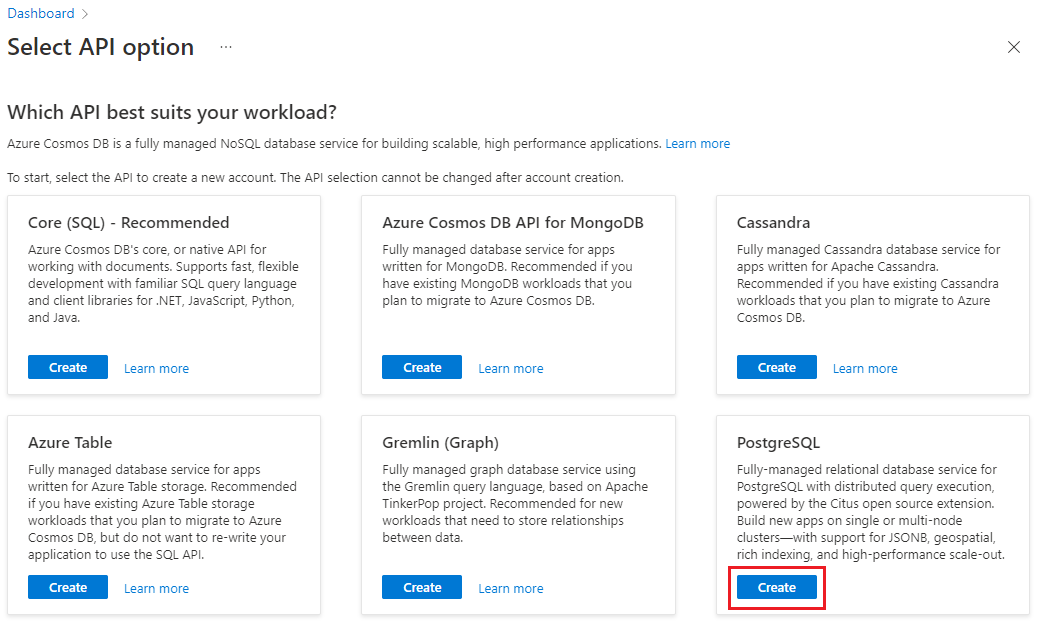
Pada formulir "Buat Kluster Azure Cosmos DB untuk PostgreSQL":
Isi informasi pada tab Dasar.
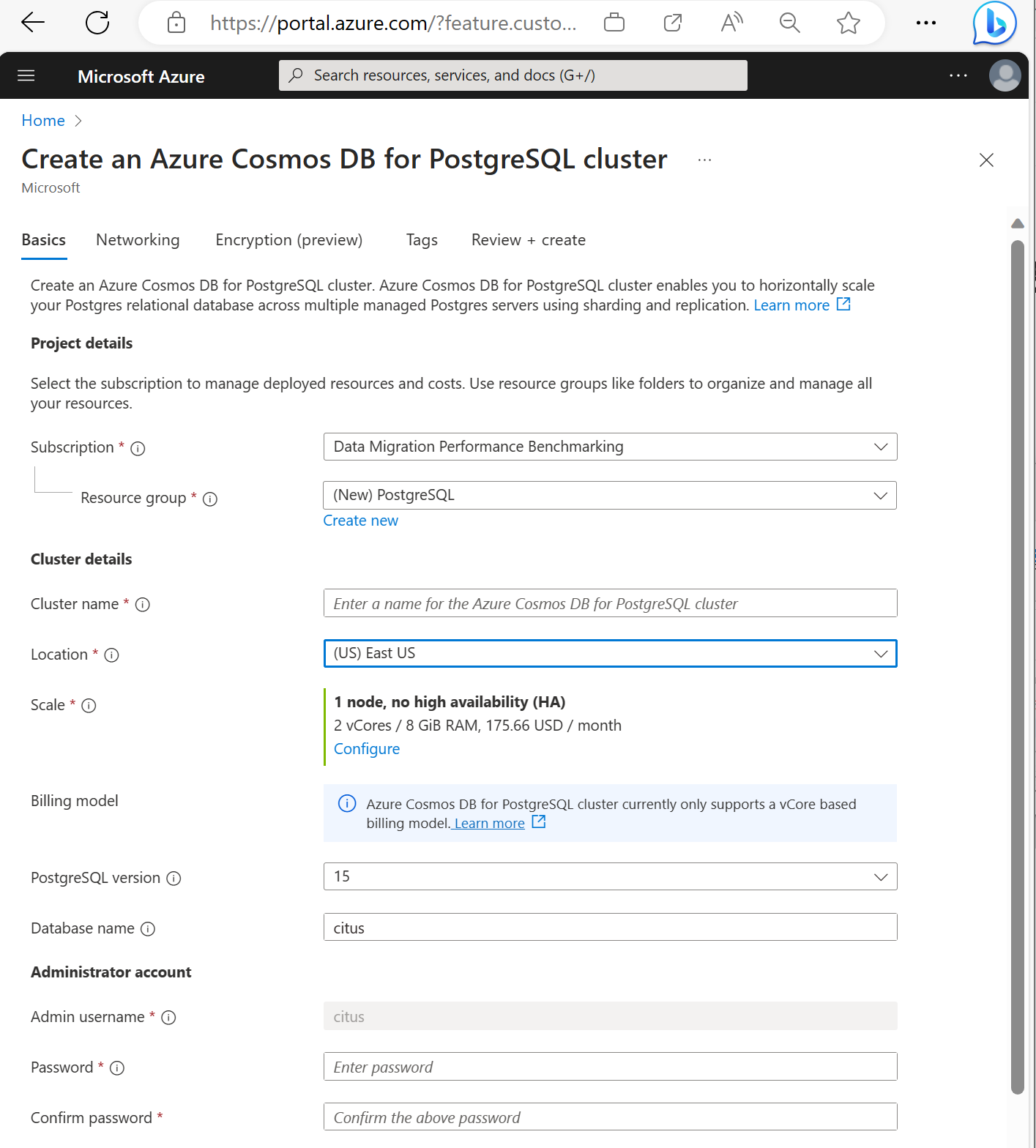
Sebagian besar opsi cukup jelas, tetapi perlu diingat:
- Nama kluster menentukan nama DNS yang digunakan aplikasi Anda untuk menyambungkan, dalam bentuk
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Anda dapat memilih versi PostgreSQL utama seperti 15. Azure Cosmos DB for PostgreSQL selalu mendukung versi Citus terbaru untuk versi Postgres utama yang dipilih.
- Nama pengguna admin harus memiliki nilai
citus. - Anda dapat membiarkan nama database pada nilai defaultnya 'citus' atau menentukan satu-satunya nama database Anda. Anda tidak dapat mengganti nama database setelah provisi kluster.
- Nama kluster menentukan nama DNS yang digunakan aplikasi Anda untuk menyambungkan, dalam bentuk
Pilih Berikutnya : Jaringan di bagian bawah layar.
Pada layar Jaringan, pilih Izinkan akses publik dari layanan dan sumber daya Azure dalam Azure ke kluster ini.
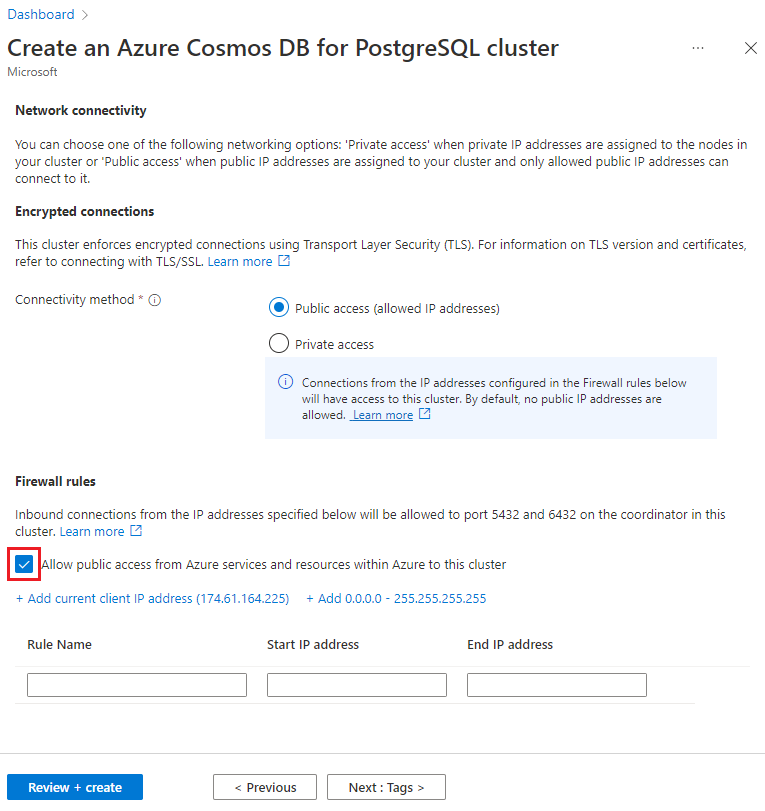
Pilih Tinjau + buat, dan saat validasi lolos, pilih Buat untuk membuat kluster.
Penyediaan membutuhkan waktu beberapa menit. Halaman akan dialihkan untuk memantau penyebaran. Saat status berubah dari Penyebaran dalam proses menjadi Penyebaran selesai, pilih Buka sumber daya.
Menggunakan utilitas psql untuk membuat skema
Setelah tersambung ke Azure Cosmos DB for PostgreSQL menggunakan psql, Anda dapat menyelesaikan beberapa tugas dasar. Tutorial ini memandu Anda untuk dapat membuat aplikasi web yang memungkinkan pengiklan melacak kampanye mereka.
Aplikasi tersebut bisa digunakan oleh banyak perusahaan, jadi mari kita buat satu tabel untuk menyimpan informasi tentang perusahaan dan satu lagi untuk kampanye mereka. Di konsol psql, jalankan perintah-perintah ini:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Setiap kampanye akan membayar untuk menayangkan iklannya. Tambahkan tabel untuk iklan juga, dengan menjalankan kode berikut dalam psql setelah kode di atas:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Terakhir, kami akan melacak statistik klik dan tayangan untuk setiap iklan:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Anda bisa melihat tabel yang baru dibuat dalam daftar tabel sekarang dalam psql dengan menjalankan:
\dt
Aplikasi multipenyewa hanya dapat memberlakukan keunikan per penyewa, itulah sebabnya semua kunci utama dan kunci asing menyertakan ID perusahaan.
Mendistribusikan tabel di seluruh simpul
Penyebaran Azure Cosmos DB for PostgreSQL melakukan penyimpanan baris tabel pada simpul-simpul yang berbeda berdasarkan nilai dari kolom yang ditentukan oleh pengguna. "Kolom distribusi" ini menandai penyewa mana yang memiliki baris mana.
Mari kita atur kolom distribusi menjadi company_id, pengidentifikasi penyewa. Dalam psql, jalankan fungsi ini:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Penting
Mendistribusikan tabel atau menggunakan sharding berbasis skema diperlukan untuk memanfaatkan fitur performa Azure Cosmos DB for PostgreSQL. Jika Anda tidak mendistribusikan tabel atau skema, simpul pekerja tidak dapat membantu menjalankan kueri yang melibatkan data mereka.
Memasukkan data sampel
Di luar psql sekarang, di baris perintah normal, unduh himpunan data sampel:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Kembali ke dalam psql, muat data secara massal. Pastikan untuk menjalankan psql di direktori yang sama tempat Anda mengunduh file data.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Data ini sekarang akan tersebar di seluruh node pekerja.
Kueri data penyewa
Ketika aplikasi meminta data untuk satu penyewa, database dapat menjalankan kueri pada satu simpul pekerja. Kueri penyewa tunggal memfilter berdasarkan satu ID penyewa. Misalnya, kueri berikut memfilter company_id = 5 untuk iklan dan tayangan. Cobalah menjalankannya dalam psql untuk melihat hasilnya.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Berbagi data di antara penyewa
Hingga saat ini, semua tabel telah didistribusikan oleh company_id. Namun demikian, sejumlah data tidak otomatis menjadi "milik" penyewa tertentu, dan dapat dibagikan. Misalnya, semua perusahaan dalam contoh platform iklan mungkin ingin mendapatkan informasi geografis untuk audiens mereka berdasarkan alamat IP.
Buat tabel untuk menyimpan informasi geografis yang dibagikan. Jalankan perintah berikut dalam psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Selanjutnya, buat geo_ips "tabel referensi" untuk menyimpan salinan tabel pada setiap simpul pekerja.
SELECT create_reference_table('geo_ips');
Isi dengan contoh data. Ingatlah untuk menjalankan perintah ini dalam psql dari dalam direktori tempat Anda mengunduh himpunan data.
\copy geo_ips from 'geo_ips.csv' with csv
Menggabungkan tabel klik dengan geo_ips efisien di semua node. Berikut ini merupakan penggabungan untuk menemukan lokasi setiap orang yang mengeklik iklan 290. Coba jalankan perintah di psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Menyesuaikan skema setiap penyewa
Setiap penyewa mungkin perlu menyimpan informasi khusus yang tidak diperlukan oleh orang lain. Namun, semua penyewa menggunakan satu infrastruktur yang sama dengan skema database yang identik. Ke mana data tambahan bisa masuk?
Salah satu triknya adalah dengan menggunakan jenis kolom terbuka seperti JSONB dari PostgreSQL. Skema kami memiliki bidang JSONB di clicks yang disebut user_data.
Suatu perusahaan (misalnya, perusahaan lima), dapat menggunakan kolom untuk melacak apakah pengguna menggunakan perangkat seluler.
Berikut adalah kueri untuk menemukan siapa yang mengklik lebih banyak: pengunjung dengan perangkat seluler atau pengunjung tradisional.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Kita dapat mengoptimalkan kueri ini untuk satu perusahaan dengan membuat indeks parsial.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Secara umum, kita dapat membuat indeks GIN pada setiap kunci dan nilai dalam kolom.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Membersihkan sumber daya
Pada langkah-langkah sebelumnya, Anda membuat sumber daya Azure dalam kluster. Jika Anda tidak mengharapkan untuk membutuhkan sumber daya ini di masa mendatang, hapus kluster. Pilih tombol Hapus di halaman Gambaran Umum untuk kluster Anda. Ketika diminta pada halaman pop-up, konfirmasi nama kluster dan pilih tombol Hapus akhir.
Langkah berikutnya
Dalam tutorial ini, Anda mempelajari cara memprovisikan kluster. Anda menyambungkan dengan psql, membuat skema, dan mendistribusikan data. Anda belajar menjalankan kueri data baik di dalam maupun di antara penyewa, serta menyesuaikan skema untuk setiap penyewa.
- Pelajari tentang jenis node kluster
- Tentukan ukuran awal terbaik untuk kluster Anda