Tutorial: Merancang dasbor analitik real-time dengan menggunakan Azure Cosmos DB for PostgreSQL
BERLAKU UNTUK: ![]() Azure Cosmos DB for PostgreSQL (didukung oleh ekstensi database Citus ke PostgreSQL)
Azure Cosmos DB for PostgreSQL (didukung oleh ekstensi database Citus ke PostgreSQL)
Dalam tutorial ini, Anda menggunakan Azure Cosmos DB for PostgreSQL untuk mempelajari cara:
- Membuat kluster
- Menggunakan utilitas psql untuk membuat skema
- Mendistribusikan tabel di seluruh simpul
- Membuat data sampel
- Melakukan rollup
- Membuat kueri data mentah dan agregat
- Membuat data kedaluwarsa
Prasyarat
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Membuat kluster
Masuk ke portal Azure dan ikuti langkah-langkah ini untuk membuat kluster Azure Cosmos DB for PostgreSQL:
Buka Buat kluster Azure Cosmos DB for PostgreSQL di portal Azure.
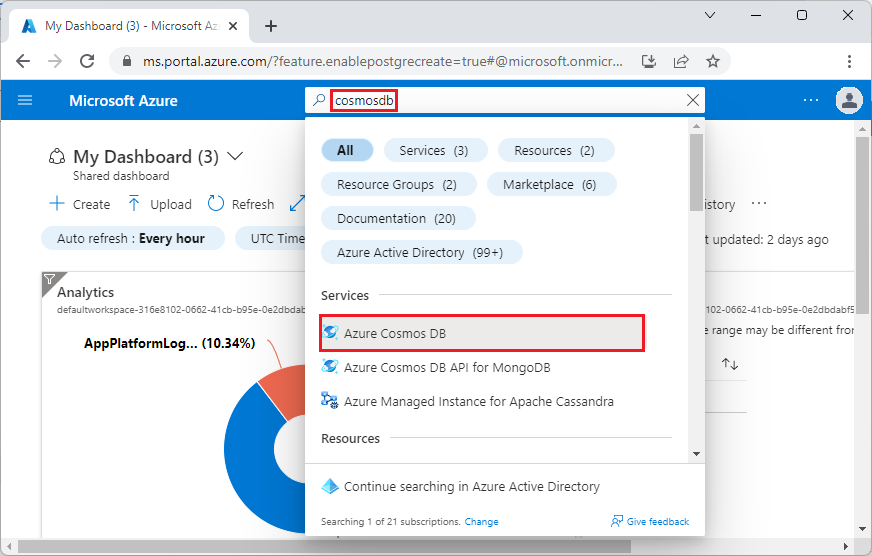
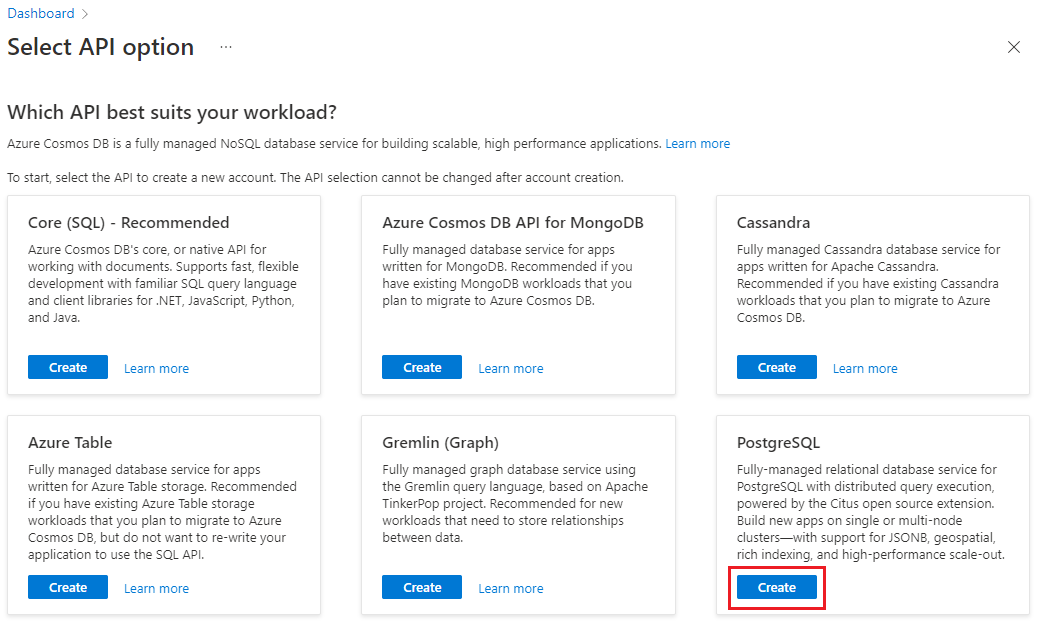
Pada formulir Buat kluster Azure Cosmos DB for PostgreSQL:
Isi informasi pada tab Dasar.
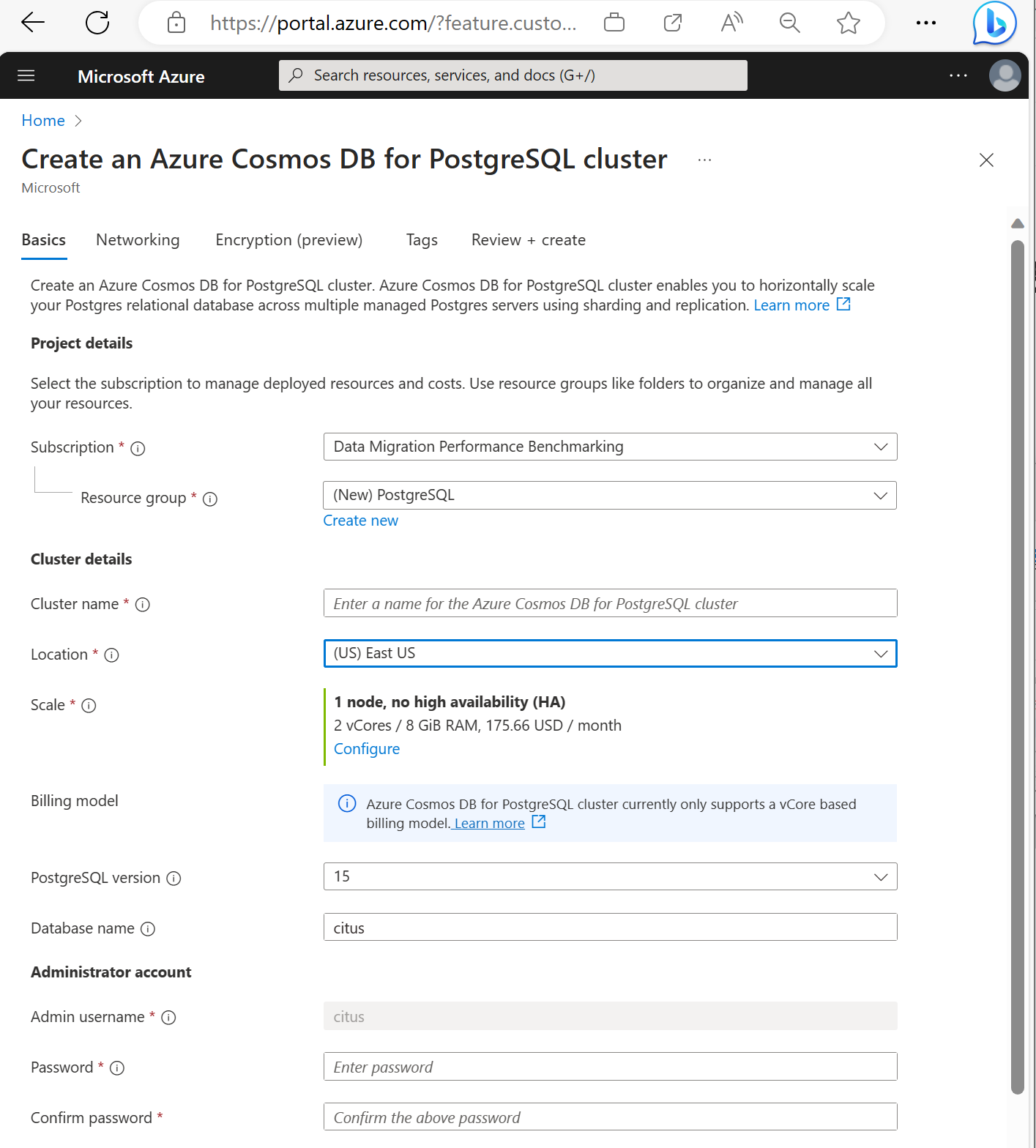
Sebagian besar opsi cukup jelas, tetapi perlu diingat:
- Nama kluster menentukan nama DNS yang digunakan aplikasi Anda untuk menyambungkan, dalam bentuk
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Anda dapat memilih versi PostgreSQL utama seperti 15. Azure Cosmos DB for PostgreSQL selalu mendukung versi Citus terbaru untuk versi Postgres utama yang dipilih.
- Nama pengguna admin harus memiliki nilai
citus. - Anda dapat membiarkan nama database pada nilai defaultnya 'citus' atau menentukan satu-satunya nama database Anda. Anda tidak dapat mengganti nama database setelah provisi kluster.
- Nama kluster menentukan nama DNS yang digunakan aplikasi Anda untuk menyambungkan, dalam bentuk
Pilih Berikutnya : Jaringan di bagian bawah layar.
Pada layar Jaringan, pilih Izinkan akses publik dari layanan dan sumber daya Azure dalam Azure ke kluster ini.
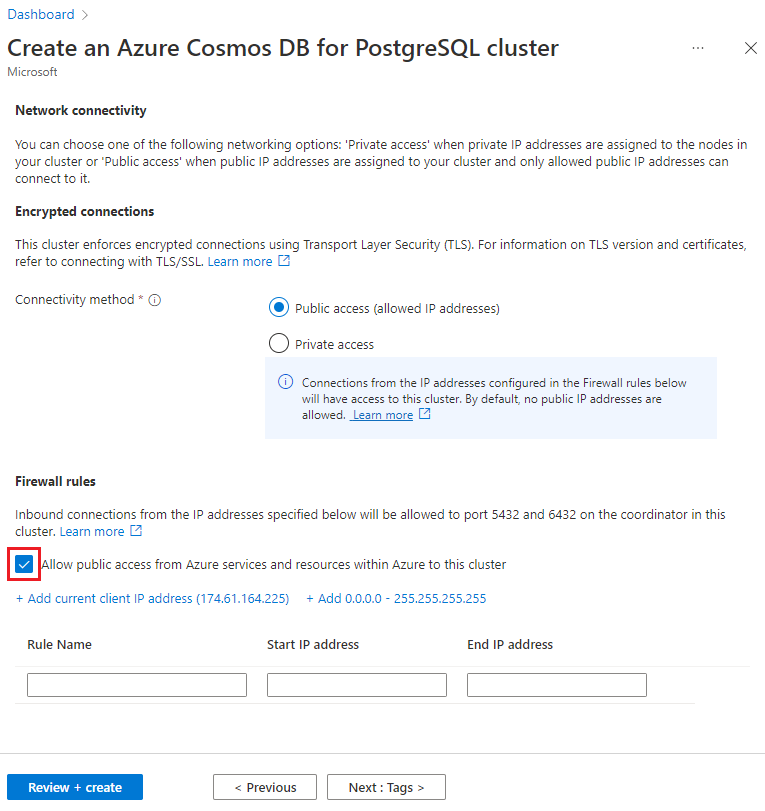
Pilih Tinjau + buat, dan saat validasi lolos, pilih Buat untuk membuat kluster.
Provisi membutuhkan waktu beberapa menit. Halaman akan dialihkan untuk memantau penyebaran. Saat status berubah dari Penyebaran dalam proses menjadi Penyebaran selesai, pilih Buka sumber daya.
Menggunakan utilitas psql untuk membuat skema
Setelah tersambung ke Azure Cosmos DB for PostgreSQL menggunakan psql, Anda dapat menyelesaikan beberapa tugas dasar. Tutorial ini memandu Anda melalui cara menyerap data lalu lintas dari analitik web, lalu menggulung data untuk menyediakan dasbor real-time berdasarkan data tersebut.
Mari buat tabel yang akan menggunakan semua data lalu lintas web mentah kami. Jalankan perintah berikut di terminal psql:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Kami juga akan membuat tabel yang akan menyimpan agregat per menit kami, dan tabel yang mempertahankan posisi rollup terakhir kami. Jalankan perintah berikut dalam psql juga:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Anda bisa melihat tabel yang baru dibuat dalam daftar tabel sekarang dengan perintah psql ini:
\dt
Mendistribusikan tabel di seluruh simpul
Penyebaran Azure Cosmos DB for PostgreSQL menyimpan baris tabel pada simpul yang berbeda berdasarkan nilai kolom yang ditunjuk pengguna. "Kolom distribusi" ini menandai bagaimana data dipecah di seluruh simpul.
Atur kolom distribusi menjadi site_id, tombol shard. Dalam psql, jalankan fungsi ini:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Penting
Mendistribusikan tabel atau menggunakan sharding berbasis skema diperlukan untuk memanfaatkan fitur performa Azure Cosmos DB for PostgreSQL. Jika Anda tidak mendistribusikan tabel atau skema, simpul pekerja tidak dapat membantu menjalankan kueri yang melibatkan data mereka.
Membuat data sampel
Sekarang kluster kita harus siap untuk menyerap beberapa data. Kami dapat menjalankan hal berikut secara lokal dari koneksi psql kami untuk terus menyisipkan data.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
Kueri menyisipkan sekitar delapan baris setiap detik. Baris disimpan pada simpul pekerja yang berbeda seperti yang diarahkan oleh kolom distribusi, site_id.
Catatan
Biarkan kueri pembuatan data berjalan, dan buka koneksi psql kedua untuk perintah yang tersisa dalam tutorial ini.
Kueri
Azure Cosmos DB for PostgreSQL memungkinkan beberapa simpul memproses kueri secara paralel untuk kecepatan. Misalnya, database menghitung agregat seperti SUM dan COUNT pada simpul pekerja, dan menggabungkan hasilnya menjadi jawaban akhir.
Berikut adalah kueri untuk menghitung permintaan web per menit beserta beberapa statistik. Cobalah menjalankannya dalam psql dan amati hasilnya.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Menggulir data
Kueri sebelumnya berfungsi dengan baik pada tahap awal, tetapi performanya menurun saat data Anda diskalakan. Bahkan dengan pemrosesan terdistribusi, lebih cepat untuk menghitung ulang data daripada menghitung ulang berulang kali.
Kami dapat memastikan dasbor kami tetap berjalan cepat dengan secara teratur menggulung data mentah ke dalam tabel agregat. Anda dapat bereksperimen dengan durasi agregasi. Kami menggunakan tabel agregasi per menit, tetapi Anda bisa memecah data menjadi 5, 15, atau 60 menit sebagai gantinya.
Untuk menjalankan roll-up ini dengan lebih mudah, kami akan memasukkannya ke dalam fungsi plpgsql. Jalankan perintah ini dalam psql untuk membuat fungsi rollup_http_request.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Dengan menerapkan fungsi kami, jalankan untuk melakukan roll up data:
SELECT rollup_http_request();
Dengan data kami dalam formulir pra-agregat, kami dapat meminta tabel rollup untuk mendapatkan laporan yang sama seperti sebelumnya. Jalankan kueri berikut:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Data lama yang kedaluwarsa
Rollup membuat kueri lebih cepat, tetapi kami masih perlu membuat data lama kedaluwarsa untuk menghindari biaya penyimpanan yang tidak terbatas. Tentukan berapa lama Anda ingin menyimpan data untuk setiap granularitas, dan gunakan kueri standar untuk menghapus data yang kedaluwarsa. Dalam contoh berikut, kami memutuskan untuk menyimpan data mentah selama satu hari, dan agregasi per menit selama satu bulan:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
Dalam produksi, Anda dapat membungkus kueri ini dalam fungsi dan memanggilnya setiap menit dalam pekerjaan cron.
Membersihkan sumber daya
Pada langkah-langkah sebelumnya, Anda membuat sumber daya Azure dalam kluster. Jika Anda tidak mengharapkan untuk membutuhkan sumber daya ini di masa mendatang, hapus kluster. Tekan tombol Hapus di halaman Gambaran Umum untuk kluster Anda. Saat diminta di halaman pop-up, konfirmasi nama kluster dan klik tombol Hapus akhir.
Langkah berikutnya
Dalam tutorial ini, Anda mempelajari cara memprovisikan kluster. Anda menyambungkan dengan psql, membuat skema, dan mendistribusikan data. Anda mempelajari cara mengkueri data dalam bentuk mentah, secara teratur mengagregasi data tersebut, mengkueri tabel agregat, dan membuat data lama kedaluwarsa.
- Pelajari tentang jenis node kluster
- Tentukan ukuran awal terbaik untuk kluster Anda
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk