dcountif() (aggregation function)
Memperkirakan jumlah nilai expr yang berbeda untuk baris di mana predikat dievaluasi ke true.
Nilai null diabaikan dan tidak memperhitungkan perhitungan.
Catatan
Fungsi ini digunakan bersama dengan ringkasan operator.
Sintaks
dcountif(expr, predikat, [,akurasi])
Pelajari selengkapnya tentang konvensi sintaksis.
Parameter
| Nama | Jenis | Diperlukan | Deskripsi |
|---|---|---|---|
| expr | string |
✔️ | Ekspresi yang digunakan untuk perhitungan agregasi. |
| predicate | string |
✔️ | Ekspresi yang digunakan untuk memfilter baris. |
| Akurasi | int |
Kontrol antara kecepatan dan akurasi. Jika tidak ditentukan, nilai defaultnya adalah 1. Lihat Akurasi estimasi untuk nilai yang didukung. |
Mengembalikan
Mengembalikan perkiraan jumlah nilai expr yang berbeda untuk baris yang predikatnya dievaluasi ke true.
Tip
dcountif() dapat mengembalikan kesalahan dalam kasus di mana semua, atau tidak ada baris yang melewati ekspresi Predicate.
Contoh
Contoh ini menunjukkan berapa banyak jenis peristiwa badai fatal yang terjadi di setiap negara bagian.
StormEvents
| summarize DifferentFatalEvents=dcountif(EventType,(DeathsDirect + DeathsIndirect)>0) by State
| where DifferentFatalEvents > 0
| order by DifferentFatalEvents
Tabel hasil yang ditampilkan hanya menyertakan 10 baris pertama.
| Provinsi | DifferentFatalEvents |
|---|---|
| CALIFORNIA | 12 |
| TEXAS | 12 |
| OKLAHOMA | 10 |
| ILLINOIS | 9 |
| KANSAS | 9 |
| NEW YORK | 9 |
| NEW JERSEY | 7 |
| WASHINGTON | 7 |
| MICHIGAN | 7 |
| MISSOURI | 7 |
| ... | ... |
Akurasi estimasi
Fungsi ini menggunakan varian dari algoritma HyperLogLog (HLL), yang melakukan estimasi stokastik dari kardinalitas yang ditetapkan. Algoritma ini menyediakan "kenop" yang dapat digunakan untuk menyeimbangkan akurasi dan waktu eksekusi per ukuran memori:
| Akurasi | Kesalahan (%) | Jumlah entri |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Catatan
Kolom "jumlah entri" adalah jumlah penghitung 1 byte dalam implementasi HLL.
Algoritma ini mencakup beberapa ketentuan untuk melakukan penghitungan sempurna (zero error), jika kardinalitas set berukuran cukup kecil:
- Ketika tingkat akurasi adalah
1, 1000 nilai dikembalikan - Ketika tingkat akurasi adalah
2, 8000 nilai dikembalikan
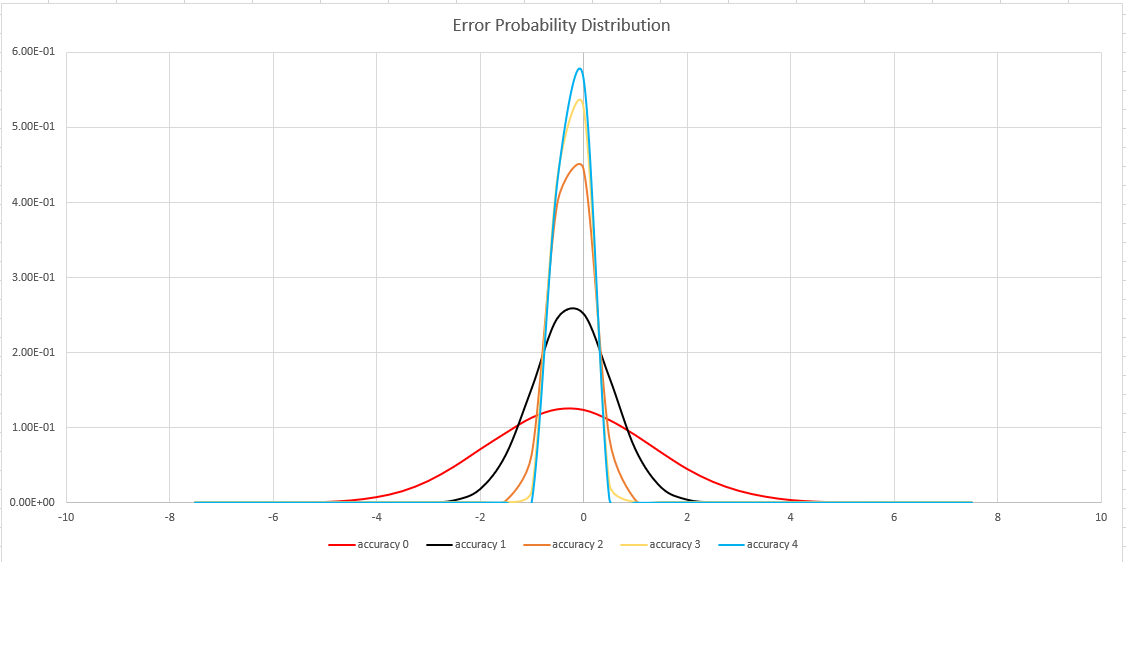
Batas kesalahan bersifat probabilistik, bukan batas teoritis. Nilainya adalah simpangan baku dari distribusi kesalahan (sigma), dan 99,7% estimasi akan memiliki kesalahan relatif di bawah 3 x sigma.
Gambar berikut menunjukkan fungsi distribusi peluang dari kesalahan estimasi relatif, dalam persentase, untuk semua pengaturan akurasi yang didukung:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk