Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Aktivitas Pekerjaan Azure Databricks di pipeline menjalankan pekerjaan Databricks di ruang kerja Azure Databricks Anda, termasuk pekerjaan tanpa server. Artikel ini membangun artikel aktivitas transformasi data, yang menyajikan gambaran umum tentang transformasi data dan aktivitas transformasi yang didukung. Azure Databricks adalah platform terkelola untuk menjalankan Apache Spark.
Anda dapat membuat pekerjaan Databricks langsung melalui antarmuka pengguna Azure Data Factory Studio.
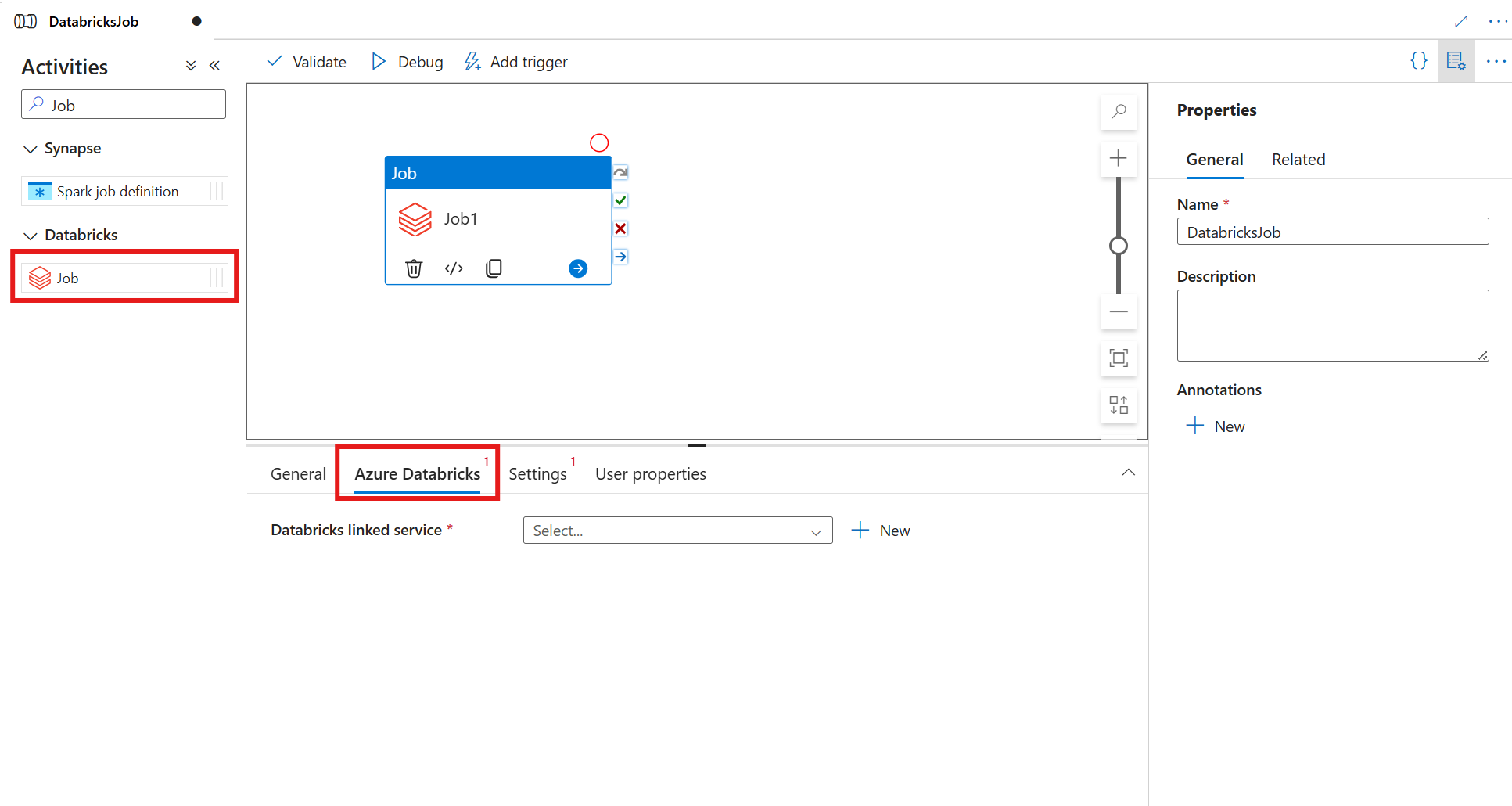
Menambahkan aktivitas Job untuk Azure Databricks ke pipeline dengan UI
Untuk menggunakan aktivitas tugas untuk Azure Databricks dalam alur, selesaikan langkah-langkah berikut:
Cari Job di panel Aktivitas pipeline, dan seret aktivitas Job ke kanvas pipeline.
Pilih aktivitas Pekerjaan baru di kanvas jika belum dipilih.
Pilih tab Azure Databricks untuk memilih atau membuat layanan tertaut Azure Databricks baru.
Nota
Aktivitas pekerjaan Azure Databricks secara otomatis berjalan pada kluster tanpa server, sehingga Anda tidak perlu menentukan kluster dalam konfigurasi layanan tertaut Anda. Sebagai gantinya, pilih opsi Tanpa Server .
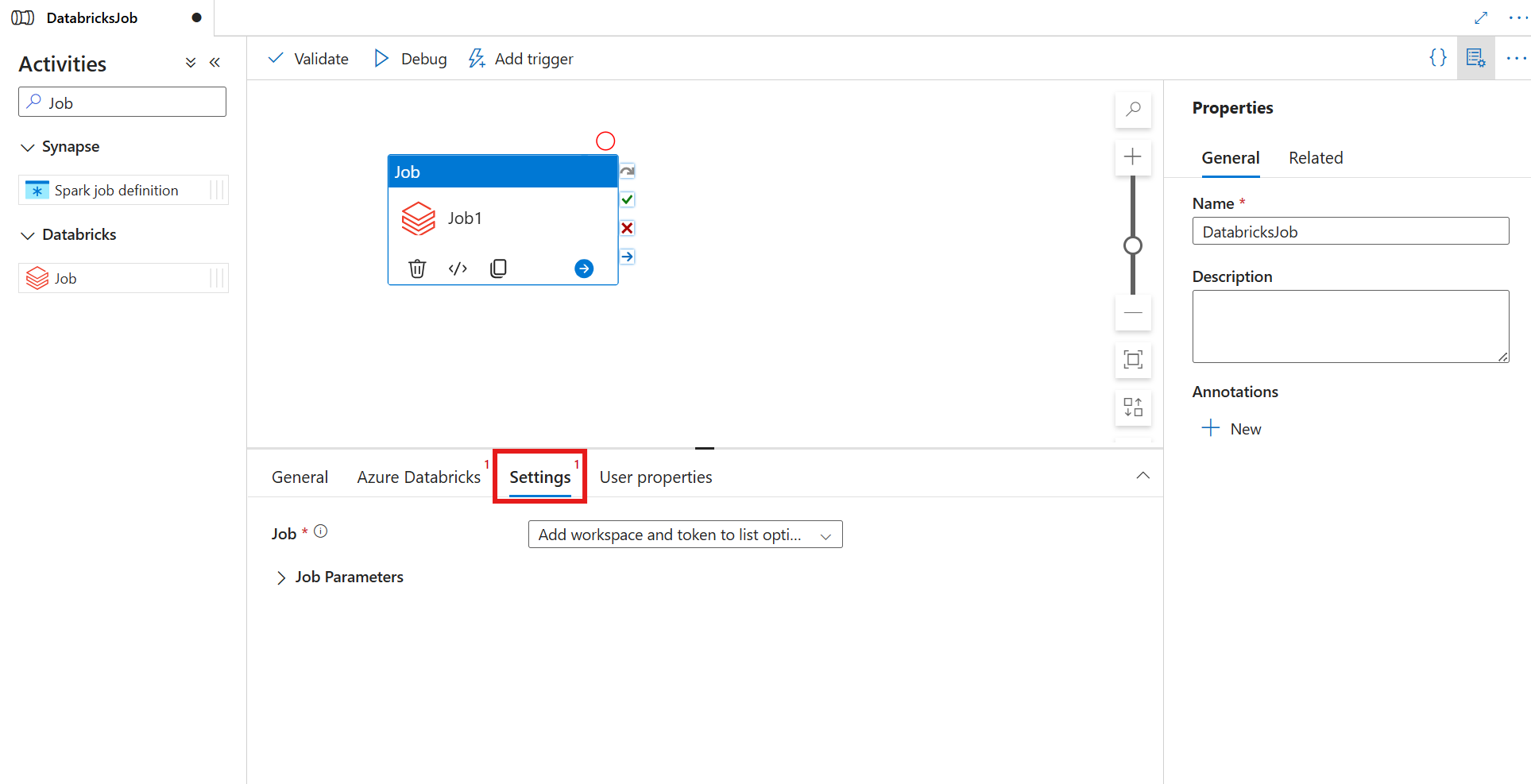
Pilih tab Settings dan tentukan pekerjaan yang akan dijalankan pada Azure Databricks, parameter dasar opsional untuk diteruskan ke pekerjaan, dan pustaka lain yang akan diinstal pada kluster untuk menjalankan pekerjaan.


Definisi aktivitas pekerjaan Databricks
Berikut adalah contoh definisi JSON dari Aktivitas Pekerjaan Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksJob",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"jobID": "012345678910112",
"jobParameters": {
"testParameter": "testValue"
},
}
}
}
Properti aktivitas Pekerjaan Databricks
Tabel berikut menjelaskan properti JSON yang digunakan dalam definisi JSON:
| Harta benda | Deskripsi | Diperlukan |
|---|---|---|
| Nama | Nama aktivitas di dalam alur. | Ya |
| deskripsi | Teks yang menjelaskan aktivitas yang dilakukan. | Tidak. |
| jenis | Untuk Aktivitas Pekerjaan Databricks, jenis aktivitasnya adalah DatabricksJob. | Ya |
| NamaLayananTerkait | Nama Layanan Tertaut Databricks tempat pekerjaan Databricks berjalan. Untuk mempelajari layanan tertaut ini, lihat artikel Layanan tertaut komputasi. | Ya |
| jobId | ID pekerjaan yang akan dijalankan di Ruang Kerja Databricks. | Ya |
| jobParameters | Larik pasangan Kunci dan Nilai. Parameter pekerjaan dapat digunakan untuk setiap aktivitas yang dijalankan. Jika pekerjaan mengambil parameter yang tidak ditentukan, nilai default dari pekerjaan akan digunakan. Temukan informasi lebih lanjut tentang parameter di Pekerjaan Databricks. | Tidak. |
Meneruskan parameter antara pekerjaan dan alur
Anda dapat meneruskan parameter ke pekerjaan menggunakan properti jobParameters dalam aktivitas Databricks.
Nota
Parameter pekerjaan hanya didukung pada IR yang dikelola sendiri versi 5.52.0.0 atau lebih baru.