Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara menggunakan Apache Kafka sebagai sumber atau sink saat menjalankan beban kerja Streaming Terstruktur di Azure Databricks.
Untuk informasi lebih lanjut mengenai Kafka, lihat dokumentasi Kafka.
Membaca data dari Kafka
Berikut adalah contoh untuk streaming bacaan dari Kafka.
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks juga mendukung semantik baca batch untuk sumber data Kafka, seperti yang ditunjukkan dalam contoh berikut:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Untuk pemuatan batch bertahap, Databricks merekomendasikan penggunaan Kafka dengan Trigger.AvailableNow. Lihat Pengonfigurasian pemrosesan batch inkremental.
Di Databricks Runtime 13.3 LTS ke atas, Azure Databricks menyediakan fungsi SQL untuk membaca data Kafka. Streaming dengan SQL hanya didukung di Alur Deklaratif Lakeflow atau dengan tabel streaming di Databricks SQL. Lihat fungsi bernilai tabel read_kafka.
Mengonfigurasi pembaca Kafka Structured Streaming
Azure Databricks menyediakan kata kunci kafka sebagai format data untuk mengonfigurasi koneksi ke Kafka 0.10+.
Berikut ini adalah konfigurasi yang paling umum untuk Kafka:
Ada beberapa cara untuk menentukan topik mana yang akan dijadikan langganan. Anda hanya boleh menyediakan salah satu parameter ini:
| Opsi | Nilai | Deskripsi |
|---|---|---|
| berlangganan | Daftar topik yang dipisahkan koma. | Daftar topik untuk berlangganan. |
| pola berlangganan | String regex di Java. | Pola yang digunakan untuk berlangganan topik. |
| menetapkan | String JSON {"topicA":[0,1],"topic":[2,4]}. |
Partisi topik tertentu yang perlu dikonsumsi. |
Konfigurasi penting lainnya:
| Opsi | Nilai | Nilai Bawaan | Deskripsi |
|---|---|---|---|
| kafka.bootstrap.servers | Daftar host:port yang dipisahkan koma. | kosong | [Diperlukan] Konfigurasi bootstrap.servers Kafka. Jika Anda menemukan tidak ada data dari Kafka, periksa daftar alamat broker terlebih dahulu. Jika daftar alamat broker salah, mungkin tidak ada kesalahan. Ini karena klien Kafka berasumsi bahwa broker pada akhirnya akan tersedia dan jika terjadi kesalahan jaringan, akan terus mencoba. |
| gagalKetikaDataHilang |
true atau false. |
true |
[Opsional] Apakah akan gagal kueri saat ada kemungkinan data hilang. Kueri dapat secara permanen gagal membaca data dari Kafka karena banyak skenario seperti topik yang dihapus, pemotongan topik sebelum diproses, dan sebagainya. Kami mencoba memperkirakan secara sederhana apakah data kemungkinan hilang atau tidak. Terkadang hal ini dapat menyebabkan alarm palsu. Atur opsi ini ke false jika tidak berfungsi seperti yang diharapkan, atau Anda ingin kueri melanjutkan pemrosesan meskipun data hilang. |
| minPartitions | Integer >= 0, 0 = dinonaktifkan. | 0 (dinonaktifkan) | [Opsional] Jumlah partisi minimum yang akan dibaca dari Kafka. Anda dapat mengonfigurasi Spark untuk menggunakan minimum partisi yang ditentukan secara acak ketika membaca dari Kafka menggunakan opsi minPartitions. Biasanya Spark memiliki pemetaan 1-1 dari topicPartitions Kafka ke partisi Spark yang dipakai dari Kafka. Jika Anda mengatur opsi minPartitions ke nilai yang lebih besar dari partisi topik Kafka Anda, Spark akan memecah partisi Kafka yang besar menjadi bagian-bagian yang lebih kecil. Opsi ini dapat diatur pada saat beban puncak, bias data, dan saat aliran data Anda tertinggal untuk meningkatkan laju pemrosesan. Ada pengorbanan berupa inisialisasi konsumen Kafka pada setiap pemicu, yang dapat berdampak pada kinerja jika Anda menggunakan SSL saat terhubung ke Kafka. |
| kafka.group.id | ID grup konsumen Kafka. | belum diatur | [Opsional] ID grup untuk digunakan saat membaca dari Kafka. Gunakan ini dengan hati-hati. Secara default, setiap kueri menghasilkan ID grup yang unik untuk membaca data. Untuk memastikan bahwa setiap kueri memiliki grup konsumennya sendiri yang tidak menghadapi gangguan dari konsumen lain, dan karena itu dapat membaca seluruh partisi dari topik langganannya. Dalam beberapa skenario (misalnya, otorisasi berbasis grup Kafka), Anda mungkin ingin menggunakan ID grup resmi tertentu untuk membaca data. Anda dapat secara opsional mengatur ID grup. Namun, lakukan ini dengan sangat hati-hati karena dapat menyebabkan tindakan yang tidak terduga.
|
| startingOffsets | paling awal , terbaru | terbaru | [Opsional] Titik awal saat kueri dimulai, baik "paling awal" yang berasal dari offset paling awal, atau string json yang menentukan offset awal untuk setiap TopicPartition. Di JSON, -2 sebagai offset dapat digunakan untuk merujuk ke yang paling awal, -1 ke yang terbaru. Catatan: Untuk kueri batch, terbaru (baik secara implisit atau dengan menggunakan -1 di json) tidak diperbolehkan. Untuk kueri streaming, ini hanya berlaku ketika kueri baru dimulai, dan proses melanjutkan akan selalu dilanjutkan dari titik di mana kueri berhenti. Partisi yang baru ditemukan selama kueri akan dimulai paling awal. |
Lihat Panduan Integrasi Kafka Structured Streaming untuk konfigurasi opsional lainnya.
Skema untuk catatan Kafka
Skema rekaman Kafka adalah:
| Kolom | Tipe |
|---|---|
| kunci | sistem biner |
| nilai | sistem biner |
| topik | benang |
| Partisi | int (integer) |
| Offset | panjang |
| penanda waktu | panjang |
| tipe cap waktu | int (integer) |
key dan value selalu dideserialisasi sebagai array byte dengan ByteArrayDeserializer. Gunakan operasi DataFrame (seperti cast("string")) untuk secara eksplisit mendeserialisasi kunci dan nilai.
Menulis data ke Kafka
Berikut ini adalah contoh untuk penulisan streaming ke Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks juga mendukung semantik penulisan batch ke sink data Kafka, seperti yang terlihat pada contoh di bawah ini.
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Mengonfigurasi penulis data Streaming Terstruktur Kafka
Penting
Databricks Runtime 13.3 LTS ke atas mencakup versi pustaka kafka-clients yang lebih baru yang memungkinkan penulisan idempoten secara default. Jika sink Kafka menggunakan versi 2.8.0 atau di bawahnya dengan ACL yang dikonfigurasi, tetapi tanpa IDEMPOTENT_WRITE diaktifkan, penulisan gagal dengan pesan kesalahan org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state.
Atasi kesalahan ini dengan meningkatkan ke Kafka versi 2.8.0 atau lebih tinggi, atau dengan mengatur .option(“kafka.enable.idempotence”, “false”) saat mengonfigurasi penulis Streaming Terstruktur Anda.
Skema yang disediakan untuk DataStreamWriter berinteraksi dengan sink Kafka. Anda bisa menggunakan bidang berikut:
| Nama kolom | Diperlukan atau opsional | Tipe |
|---|---|---|
key |
opsional |
STRING atau BINARY |
value |
wajib |
STRING atau BINARY |
headers |
opsional | ARRAY |
topic |
opsional (diabaikan jika topic diatur sebagai opsi penulis) |
STRING |
partition |
opsional | INT |
Berikut ini adalah opsi umum yang diatur saat menulis untuk Kafka:
| Opsi | Nilai | Nilai bawaan | Deskripsi |
|---|---|---|---|
kafka.boostrap.servers |
Daftar <host:port> yang dipisahkan koma |
tidak ada | [Diperlukan] Konfigurasi bootstrap.servers Kafka. |
topic |
STRING |
belum diatur | [Opsional] Mengatur topik untuk semua baris yang akan ditulis. Opsi ini mengambil alih kolom topik apa pun yang ada dalam data. |
includeHeaders |
BOOLEAN |
false |
[Opsional] Apakah akan menyertakan header Kafka dalam baris. |
Lihat Panduan Integrasi Kafka Structured Streaming untuk konfigurasi opsional lainnya.
Mengambil metrik Kafka
Anda bisa mendapatkan rata-rata, minimum, dan maksimum dari jumlah offset di mana query streaming tertinggal dari offset terbaru yang tersedia di antara semua topik berlangganan dengan metrik avgOffsetsBehindLatest, maxOffsetsBehindLatest, dan minOffsetsBehindLatest. Lihat Membaca Metrik Secara Interaktif.
Catatan
Tersedia untuk Databricks Runtime 9.1 ke atas.
Dapatkan perkiraan jumlah total byte yang belum digunakan proses kueri dari topik berlangganan dengan memeriksa nilai estimatedTotalBytesBehindLatest. Perkiraan ini didasarkan pada batch yang diproses dalam 300 detik terakhir. Jangka waktu yang menjadi dasar dari perkiraan dapat diubah dengan menetapkan opsi bytesEstimateWindowLength ke nilai yang berbeda. Misalnya, untuk mengaturnya ke 10 menit:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Jika Anda menjalankan streaming di buku catatan, Anda bisa melihat metrik ini di bawah tab Data Mentah di dasbor progres kueri streaming.
{
"sources": [
{
"description": "KafkaV2[Subscribe[topic]]",
"metrics": {
"avgOffsetsBehindLatest": "4.0",
"maxOffsetsBehindLatest": "4",
"minOffsetsBehindLatest": "4",
"estimatedTotalBytesBehindLatest": "80.0"
}
}
]
}
Menggunakan SSL untuk menyambungkan Azure Databricks ke Kafka
Untuk mengaktifkan koneksi SSL ke Kafka, ikuti instruksi dalam dokumentasi Confluent Enkripsi dan Autentikasi dengan SSL. Anda dapat memberikan konfigurasi yang dijelaskan di sana, diawali dengan kafka., sebagai opsi. Misalnya, Anda menentukan lokasi trust store di properti kafka.ssl.truststore.location.
Databricks merekomendasikan agar Anda:
- Simpan sertifikat Anda di penyimpanan objek cloud. Anda dapat membatasi akses ke sertifikat hanya ke kluster yang dapat mengakses Kafka. Lihat Tata kelola data dengan Azure Databricks.
- Simpan kata sandi sertifikat Anda sebagai secret dalam secret scope.
Contoh berikut menggunakan lokasi penyimpanan objek dan rahasia Databricks untuk mengaktifkan koneksi SSL:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Sambungkan Kafka pada HDInsight ke Azure Databricks
Buat kluster HDInsight Kafka.
Untuk petunjuk, lihat Sambungkan ke Kafka pada HDInsight melalui Azure Virtual Network.
Konfigurasikan broker Kafka untuk menyatakan alamat yang benar.
Ikuti petunjuk di Konfigurasi Kafka untuk IP advertising. Jika Anda mengelola Kafka sendiri di Azure Virtual Machines, pastikan konfigurasi broker
advertised.listenersdiatur ke IP internal dari host.Buat kluster Azure Databricks.
Pasangkan kluster Kafka ke kluster Azure Databricks.
Ikuti petunjuk di Jaringan Virtual Peer.
Autentikasi Perwakilan Layanan dengan ID Microsoft Entra dan Azure Event Hubs
Azure Databricks mendukung autentikasi pekerjaan Spark dengan layanan Azure Event Hubs. Autentikasi ini dilakukan melalui OAuth dengan MICROSOFT Entra ID.
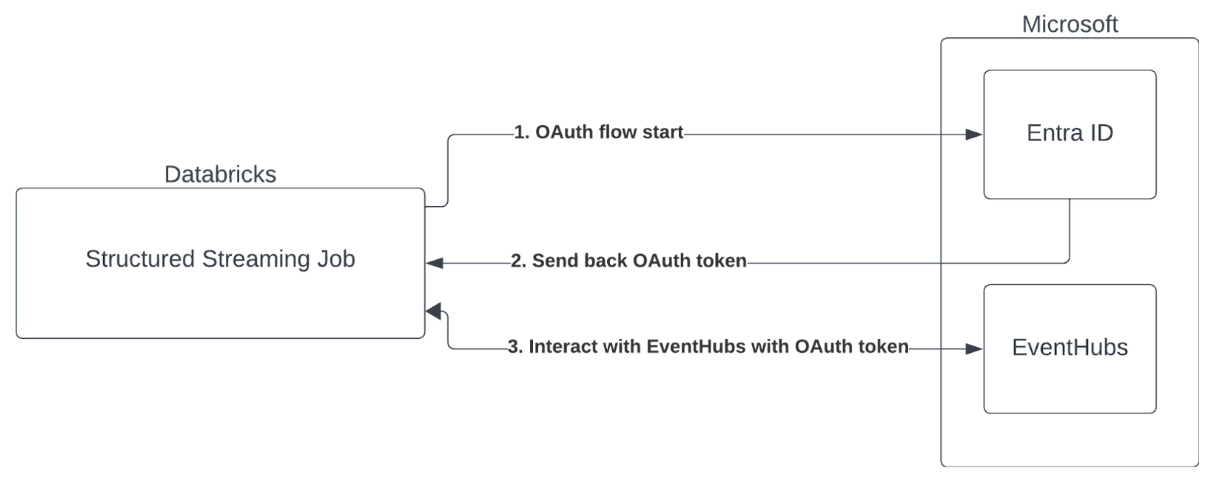
Azure Databricks mendukung autentikasi ID Microsoft Entra dengan ID klien dan rahasia di lingkungan komputasi berikut:
- Databricks Runtime 12.2 LTS ke atas pada komputasi yang dikonfigurasi dengan mode akses khusus (sebelumnya mode akses pengguna tunggal).
- Databricks Runtime 14.3 LTS ke atas pada komputasi yang dikonfigurasi dengan mode akses standar (sebelumnya mode akses bersama).
- Alur Deklaratif Lakeflow dikonfigurasi tanpa Katalog Unity.
Azure Databricks tidak mendukung autentikasi ID Microsoft Entra dengan sertifikat di lingkungan komputasi apa pun, atau di Alur Deklaratif Lakeflow yang dikonfigurasi dengan Katalog Unity.
Autentikasi ini tidak berfungsi pada komputasi dengan mode akses standar atau pada Unity Catalog Lakeflow Declarative Pipelines.
Dukungan kredensial layanan Unity Catalog untuk AWS MSK dan Azure Event Hubs
Sejak rilis DBR 16.1, Azure Databricks mendukung kredensial layanan Unity Catalog untuk mengautentikasi akses ke AWS Managed Streaming for Apache Kafka (MSK) dan Azure Event Hubs. Azure Databricks merekomendasikan pendekatan ini untuk menjalankan streaming Kafka pada kluster bersama dan saat menggunakan komputasi tanpa server.
Untuk menggunakan kredensial layanan Katalog Unity untuk autentikasi, lakukan langkah-langkah berikut:
- Buat kredensial layanan Unity Catalog baru. Jika Anda tidak terbiasa dengan proses ini, lihat Membuat kredensial layanan untuk instruksi tentang membuatnya.
- Berikan nama kredensial layanan Katalog Unity Anda sebagai opsi sumber dalam konfigurasi Kafka Anda. Atur opsi
databricks.serviceCredentialke nama kredensial layanan Anda.
Catatan: Saat Anda memberikan kredensial layanan Unity Catalog ke Kafka, jangan tentukan opsi ini karena tidak lagi diperlukan:
kafka.sasl.mechanismkafka.sasl.jaas.configkafka.security.protocolkafka.sasl.client.callback.handler.classkafka.sasl.oauthbearer.token.endpoint.url
Mengonfigurasi Konektor Kafka Streaming Terstruktur
Untuk melakukan autentikasi dengan ID Microsoft Entra, Anda harus memiliki nilai berikut:
ID penyewa. Anda dapat menemukan ini di tab layanan ID Microsoft Entra.
clientID (juga dikenal sebagai ID Aplikasi).
Rahasia klien. Setelah Anda memiliki ini, Anda harus menambahkannya sebagai rahasia ke Ruang Kerja Databricks Anda. Untuk menambahkan rahasia ini, lihat Manajemen rahasia.
Sebuah topik EventHubs. Anda dapat menemukan daftar topik di bagian Event Hubs di bawah bagian Entitas di halaman Namespace Event Hubs tertentu. Untuk bekerja dengan beberapa topik, Anda dapat mengatur peran IAM di tingkat Event Hubs.
Server untuk EventHubs. Anda dapat menemukan ini di halaman gambaran umum namespace Event Hubs tertentu:
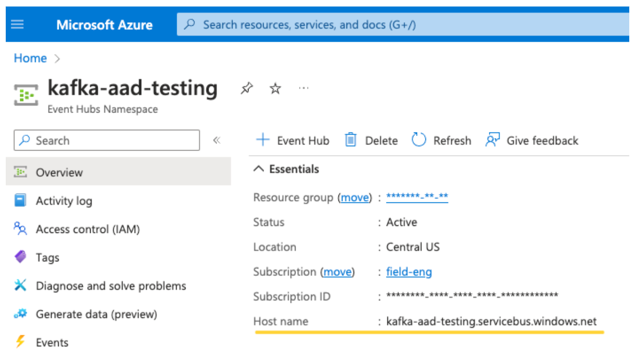
Selain itu, untuk menggunakan Id Entra, kita perlu memberi tahu Kafka untuk menggunakan mekanisme OAuth SASL (SASL adalah protokol generik, dan OAuth adalah jenis SASL "mekanisme"):
-
kafka.security.protocolharusSASL_SSL -
kafka.sasl.mechanismharusOAUTHBEARER -
kafka.sasl.login.callback.handler.classharus menjadi nama lengkap dari kelas Java dengan nilaikafkashadeduntuk pemroses panggilan balik saat login dari kelas Kafka yang telah dimodifikasi oleh kami. Lihat contoh berikut untuk kelas persis.
Contoh
Selanjutnya, mari kita lihat contoh yang sedang berjalan:
Phyton
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Menangani potensi kesalahan
Opsi streaming tidak didukung.
Jika Anda mencoba menggunakan mekanisme autentikasi ini di Lakeflow Declarative Pipelines yang dikonfigurasi dengan Unity Catalog, Anda mungkin menerima kesalahan berikut:
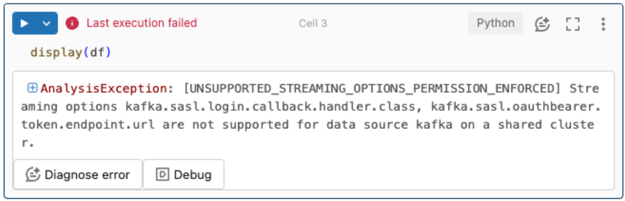
Untuk mengatasi kesalahan ini, gunakan konfigurasi komputasi yang didukung. Lihat Autentikasi Perwakilan Layanan dengan ID Microsoft Entra dan Azure Event Hubs.
Gagal membuat
KafkaAdminClientbaru.Ini adalah kesalahan internal yang dilemparkan Kafka jika salah satu opsi autentikasi berikut salah:
- ID Klien (juga dikenal sebagai ID Aplikasi)
- ID Penyewa
- Server EventHubs
Untuk mengatasi kesalahan, verifikasi bahwa nilai sudah benar untuk opsi ini.
Selain itu, Anda mungkin melihat kesalahan ini jika mengubah opsi konfigurasi yang disediakan secara default dalam contoh, yang diminta untuk tidak diubah, seperti
kafka.security.protocol.Tidak ada rekaman yang dikembalikan
Jika Anda mencoba menampilkan atau memproses DataFrame Tetapi tidak mendapatkan hasil, Anda akan melihat yang berikut ini di UI.
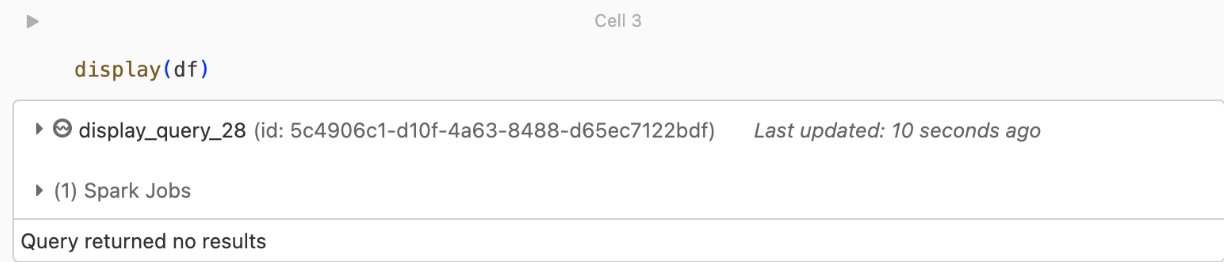
Pesan ini berarti bahwa autentikasi berhasil, tetapi EventHubs tidak mengembalikan data apa pun. Beberapa kemungkinan (meskipun tidak ada alasan lengkap) adalah:
- Anda menentukan topik EventHubs yang salah.
- Opsi konfigurasi Kafka default untuk
startingOffsetsadalahlatest, dan Saat ini Anda belum menerima data apa pun melalui topik tersebut. Anda dapat menetapkanstartingOffsetskeearliestuntuk mulai membaca data dari offset terawal milik Kafka.