Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
CI/CD (Integrasi Berkelanjutan dan Pengiriman Berkelanjutan) telah menjadi landasan rekayasa dan analitik data modern, karena memastikan bahwa perubahan kode terintegrasi, diuji, dan disebarkan dengan cepat dan andal. Databricks mengakui bahwa Anda mungkin memiliki beragam persyaratan CI/CD yang dibentuk oleh preferensi organisasi Anda, alur kerja yang ada, dan lingkungan teknologi tertentu, dan menyediakan kerangka kerja fleksibel yang mendukung berbagai opsi CI/CD.
Halaman ini menjelaskan praktik terbaik untuk membantu Anda merancang dan membangun alur CI/CD yang kuat dan disesuaikan yang selaras dengan kebutuhan dan batasan unik Anda. Dengan memanfaatkan wawasan ini, Anda dapat mempercepat inisiatif rekayasa data dan analitik, meningkatkan kualitas kode, dan mengurangi risiko kegagalan penyebaran.
Prinsip inti CI/CD
Alur CI/CD yang efektif berbagi prinsip dasar terlepas dari spesifikasi implementasinya. Praktik terbaik universal berikut berlaku di seluruh preferensi organisasi, alur kerja pengembang, dan lingkungan cloud, dan memastikan konsistensi di berbagai implementasi, baik tim Anda memprioritaskan pengembangan notebook-first atau alur kerja infrastruktur sebagai kode. Adopsi prinsip-prinsip ini sebagai pagar pembatas sambil menyesuaikan spesifikasi untuk rangkaian dan proses teknologi organisasi Anda.
- Kontrol versi segala sesuatu
- Simpan notebook, skrip, definisi infrastruktur (IaC), dan konfigurasi pekerjaan di Git.
- Gunakan strategi percabangan, seperti Gitflow, yang selaras dengan lingkungan pengembangan, penahapan, dan penyebaran produksi standar.
- Mengotomatiskan pengujian
- Menerapkan pengujian unit untuk logika bisnis menggunakan pustaka, seperti pytest untuk Python dan ScalaTest untuk Scala.
- Memvalidasi fungsionalitas notebook dan alur kerja dengan alat seperti Databricks CLI bundle validate.
- Gunakan pengujian integrasi untuk alur kerja dan alur data, seperti chispa untuk Spark DataFrames.
- Menggunakan Infrastruktur sebagai Kode (IaC)
- Tentukan kluster, pekerjaan, dan konfigurasi ruang kerja dengan Paket Automasi Deklaratif YAML atau Terraform.
- Parameterisasikan pengaturan yang khusus untuk lingkungan, seperti ukuran kluster dan rahasia, alih-alih meng-hardcode.
- Mengisolasi lingkungan
- Pertahankan ruang kerja terpisah untuk pengembangan, penahapan, dan produksi.
- Gunakan MLflow Model Registry untuk penerapan versi model di seluruh lingkungan.
- Pilih alat yang cocok dengan ekosistem cloud Anda:
- Azure: Azure DevOps dan Bundel Otomatisasi Deklaratif atau Terraform.
- AWS: GitHub Actions dan Declarative Automation Bundles atau Terraform.
- GCP: Cloud Build dan Paket Otomatisasi Deklaratif atau Terraform.
- Memantau dan mengotomatiskan pemulihan
- Lacak tingkat keberhasilan penyebaran, performa pekerjaan, dan cakupan pengujian.
- Terapkan mekanisme rollback otomatis untuk penyebaran yang gagal.
- Menyatukan manajemen aset
- Gunakan Bundel Otomatisasi Deklaratif untuk menyebarkan kode, pekerjaan, dan infrastruktur sebagai satu unit. Hindari manajemen buku catatan, pustaka, dan alur kerja yang terpisah atau terisolasi.
Note
Databricks merekomendasikan federasi identitas beban kerja untuk autentikasi CI/CD. Federasi identitas beban kerja menghilangkan kebutuhan akan rahasia Databricks, yang menjadikannya cara paling aman untuk mengautentikasi alur otomatis Anda ke Databricks. Lihat Mengaktifkan federasi identitas beban kerja di CI/CD.
Bundel Otomatisasi Deklaratif untuk CI/CD
Bundel Otomatisasi Deklaratif (sebelumnya dikenal sebagai Bundel Aset Databricks) menawarkan pendekatan terpadu yang kuat untuk mengelola kode, alur kerja, dan infrastruktur dalam ekosistem Databricks dan direkomendasikan untuk alur CI/CD Anda. Dengan menggabungkan elemen-elemen ini ke dalam satu unit yang ditentukan YAML, bundel menyederhanakan penyebaran dan memastikan konsistensi di seluruh lingkungan. Namun, untuk pengguna yang terbiasa dengan alur kerja CI/CD tradisional, mengadopsi bundel mungkin memerlukan perubahan cara berpikir.
Misalnya, pengembang Java digunakan untuk membangun JAR dengan Maven atau Gradle, menjalankan pengujian unit dengan JUnit, dan mengintegrasikan langkah-langkah ini ke dalam alur CI/CD. Demikian pula, pengembang Python sering mengemas kode ke dalam roda dan menguji dengan pytest, sementara pengembang SQL berfokus pada validasi kueri dan manajemen buku catatan. Dengan bundel, alur kerja ini menyatu ke dalam format yang lebih terstruktur dan preskriptif, menekankan kode bundling dan infrastruktur untuk penyebaran yang mulus.
Bagian berikut mengeksplorasi bagaimana pengembang dapat menyesuaikan alur kerja mereka untuk memanfaatkan bundel secara efektif.
Untuk memulai Bundel Otomatisasi Deklaratif dengan cepat, coba tutorial: Mengembangkan pekerjaan dengan Bundel Automasi Deklaratif atau Mengembangkan alur dengan Bundel Otomatisasi Deklaratif.
Rekomendasi kontrol sumber CI/CD
Pilihan pertama yang perlu dibuat pengembang saat menerapkan CI/CD adalah cara menyimpan dan membuat versi file sumber. Bundel memungkinkan Anda untuk dengan mudah menyatukan semua - kode sumber, artefak build, dan file konfigurasi - serta menempatkannya di repositori kode sumber yang sama, tetapi opsi lain adalah memisahkan file konfigurasi bundel dari file yang terkait dengan kode. Pilihannya tergantung pada alur kerja, kompleksitas proyek, dan persyaratan CI/CD tim Anda, tetapi Databricks merekomendasikan hal berikut:
- Untuk proyek kecil atau konektor yang ketat antara kode dan konfigurasi, gunakan satu repositori untuk konfigurasi kode dan bundel untuk menyederhanakan alur kerja.
- Untuk tim yang lebih besar atau siklus rilis independen, gunakan repositori terpisah untuk konfigurasi kode dan bundel, tetapi buat alur CI/CD yang jelas yang memastikan kompatibilitas antar versi.
Apakah Anda memilih untuk menempatkan bersama atau memisahkan file terkait kode dari file konfigurasi bundel Anda, selalu gunakan artefak yang diberi versi, seperti hash commit Git, saat mengunggah ke Databricks atau penyimpanan eksternal untuk memastikan kemampuan pelacakan dan rollback.
Repositori tunggal untuk kode dan konfigurasi
Dalam pendekatan ini, kode sumber dan file konfigurasi bundel disimpan di repositori yang sama. Ini menyederhanakan alur kerja dan memastikan perubahan atom.
| Pros | Cons |
|---|---|
|
|
Contoh: Kode Python dalam bundel
Contoh ini memiliki file Python dan file bundel dalam satu repositori:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── workflows/
│ │ ├── my_pipeline.yml # YAML pipeline def
│ │ └── my_pipeline_job.yml # YAML job def that runs pipeline
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
├── src/
│ ├── my_pipeline.ipynb # pipeline notebook
│ └── mypython.py # Additional Python
└── README.md
Memisahkan repositori untuk kode dan konfigurasi
Dalam pendekatan ini, kode sumber berada di satu repositori, sementara file konfigurasi bundel dipertahankan di repositori lain. Opsi ini sangat ideal untuk tim atau proyek yang lebih besar di mana grup terpisah menangani pengembangan aplikasi dan manajemen alur kerja Databricks.
| Pros | Cons |
|---|---|
|
|
Contoh: Proyek dan bundel Java
Dalam contoh ini, proyek Java dan filenya berada dalam satu repositori dan file bundel berada di repositori lain.
Repositori 1: File Java
Repositori pertama berisi semua file terkait Java:
java-app-repo/
├── pom.xml # Maven build configuration
├── src/
│ ├── main/
│ │ ├── java/ # Java source code
│ │ │ └── com/
│ │ │ └── mycompany/
│ │ │ └── app/
│ │ │ └── App.java
│ │ └── resources/ # Application resources
│ └── test/
│ ├── java/ # Unit tests for Java code
│ │ └── com/
│ │ └── mycompany/
│ │ └── app/
│ │ └── AppTest.java
│ └── resources/ # Test-specific resources
├── target/ # Compiled JARs and classes
└── README.md
- Pengembang menulis kode aplikasi di
src/main/javaatausrc/main/scala. - Pengujian unit disimpan di
src/test/javaatausrc/test/scala. - Pada permintaan pull atau commit, alur CI/CD:
- Kompilasi kode ke dalam JAR, misalnya,
target/my-app-1.0.jar. - Unggah JAR ke volume Databricks Unity Catalog. Lihat mengunggah JAR.
- Kompilasi kode ke dalam JAR, misalnya,
Repositori 2: File bundel
Repositori kedua hanya berisi file konfigurasi bundel:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── jobs/
│ │ ├── my_java_job.yml # YAML job dev
│ │ └── my_other_job.yml # Additional job definitions
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
└── README.md
Konfigurasi bundel databricks.yml dan definisi pekerjaan dipertahankan secara independen.
databricks.yml mereferensikan artefak JAR yang diunggah, misalnya:
- jar: /Volumes/artifacts/my-app-${{ GIT_SHA }}.)jar
Alur kerja CI/CD yang direkomendasikan
Baik Anda menempatkan bersama atau memisahkan file file kode dengan file konfigurasi bundel Anda, alur kerja yang direkomendasikan adalah sebagai berikut:
- Mengkompilasi dan menguji kode
- Dipicu saat ada permintaan pull atau komit ke cabang utama.
- Kompilasi kode dan jalankan pengujian unit.
- Keluarkan file versi, misalnya,
my-app-1.0.jar.
- Unggah dan simpan file yang dikompilasi, seperti JAR, ke volume Databricks Unity Catalog.
- Simpan file yang dikompilasi dalam volume Databricks Unity Catalog atau repositori artefak seperti AWS S3 atau Azure Blob Storage.
- Gunakan skema penomoran versi yang terkait dengan hash komit Git atau versi semantik, misalnya,
dbfs:/mnt/artifacts/my-app-${{ github.sha }}.jar.
- Validasi bundel
- Jalankan
databricks bundle validateuntuk memastikan bahwadatabricks.ymlkonfigurasi sudah benar. - Langkah ini memastikan bahwa kesalahan konfigurasi, misalnya, pustaka yang hilang, ditangkap lebih awal.
- Jalankan
- Menyebarkan paket
- Gunakan
databricks bundle deployuntuk menyebarkan bundel ke lingkungan penahapan atau produksi. - Rujuk pustaka yang dikompilasi yang diunggah di
databricks.yml. Untuk informasi tentang mereferensikan pustaka, lihat Dependensi pustaka Bundel Otomatisasi Deklaratif.
- Gunakan
Strategi percabangan
Ada berbagai strategi percabangan yang dapat Anda pilih saat menyiapkan alur CI/CD Anda. Praktik terbaik yang paling sederhana adalah:
- Kembangkan secara lokal atau di ruang kerja dan sebarkan ke ruang kerja pengembangan Databricks untuk menguji perubahan.
- Buat cabang fitur dalam sistem kontrol versi untuk mengelola pembaruan dan sinkronkan perubahan lokal atau ruang kerja Anda secara teratur.
- Setelah pengujian selesai, gabungkan cabang fitur ke cabang utama.
- CI/CD secara otomatis mendistribusikan cabang utama ke ruang kerja staging dan pengujian otomatis dimulai.
- Ketika pengujian penahapan dan pemeriksaan lulus, CI/CD menyebarkan cabang utama ke ruang kerja produksi.
Langkah-langkah ini diuraikan dalam diagram berikut:
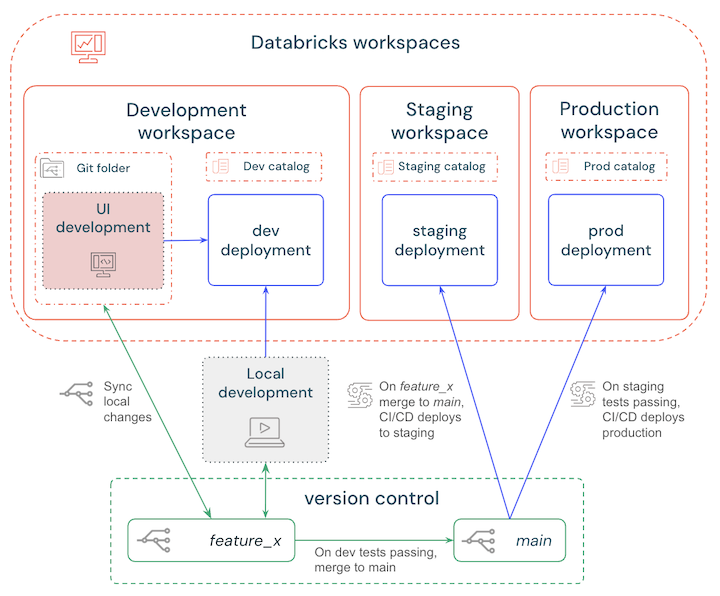
CI/CD untuk pembelajaran mesin
Proyek pembelajaran mesin memperkenalkan tantangan CI/CD yang unik dibandingkan dengan pengembangan perangkat lunak tradisional. Saat menerapkan CI/CD untuk proyek ML, Anda mungkin perlu mempertimbangkan hal berikut:
- Koordinasi multi-tim: Ilmuwan data, insinyur, dan tim MLOps sering menggunakan alat dan alur kerja yang berbeda. Databricks menyatukan proses ini dengan MLflow untuk pelacakan eksperimen, Delta Sharing untuk tata kelola data, dan Bundel Otomatisasi Deklaratif untuk infrastruktur sebagai kode.
- Versi data dan model: Alur ML memerlukan pelacakan tidak hanya kode tetapi juga skema data pelatihan, distribusi fitur, dan artefak model. Databricks Delta Lake menyediakan transaksi ACID dan perjalanan waktu untuk penerapan versi data, sementara MLflow Model Registry menangani silsilah model.
- Reproduksi di seluruh lingkungan: Model ML bergantung pada kombinasi data, kode, dan infrastruktur tertentu. Bundel Otomasi Deklaratif memastikan penyebaran atomik dari komponen-komponen ini di seluruh lingkungan pengembangan, uji coba, dan produksi dengan menggunakan definisi YAML.
- Pelatihan dan pemantauan ulang berkelanjutan: Model menurun karena penyimpangan data. Lakeflow Jobs memungkinkan alur pelatihan ulang otomatis, sementara MLflow terintegrasi dengan Prometheus dan Pemantauan Kualitas Data Databricks untuk pelacakan performa.
Ekosistem MLOps untuk ML CI/CD
Databricks membahas kompleksitas ML CI/CD melalui MLOps Stacks, kerangka kerja tingkat produksi yang menggabungkan Bundel Automasi Deklaratif, alur kerja CI/CD yang telah dikonfigurasi sebelumnya, dan templat proyek ML modular. Tumpukan teknologi ini menerapkan praktik terbaik sambil memungkinkan fleksibilitas untuk kolaborasi antar tim di seluruh peran di bidang rekayasa data, ilmu data, dan MLOps.
| Team | Responsibilities | Contoh komponen bundel | Contoh artefak |
|---|---|---|---|
| Teknisi data | Membangun alur ETL, memberlakukan kualitas data | Lakeflow Spark Declarative Pipelines YAML, kebijakan kluster |
etl_pipeline.yml, feature_store_job.yml |
| Ilmuwan data | Mengembangkan logika pelatihan model, memvalidasi metrik | Proyek MLflow, alur kerja berbasis buku catatan |
train_model.yml, batch_inference_job.yml |
| Insinyur MLOps | Mengatur penyebaran, memantau alur | Variabel lingkungan, dasbor pemantauan |
databricks.yml, lakehouse_monitoring.yml |
Kolaborasi ML CI/CD mungkin terlihat seperti:
- Insinyur data melakukan perubahan pada pipeline ETL ke dalam sebuah bundel, memicu validasi skema otomatis serta penyebaran di tahap percobaan.
- Ilmuwan data mengirimkan kode ML, yang kemudian menjalankan pengujian unit dan didistribusikan ke ruang kerja penahapan untuk pengujian integrasi.
- Teknisi MLOps meninjau metrik validasi dan mempromosikan model yang diperiksa ke produksi menggunakan MLflow Registry.
Untuk detail implementasi, lihat:
- Bundel MLOps Stacks: Panduan langkah demi langkah untuk inisialisasi dan penyebaran bundel.
- Repositori GitHub MLOps Stacks: Templat yang telah disiapkan untuk pelatihan, inferensi, dan CI/CD.
Dengan menyelaraskan tim dengan bundel standar dan Tumpukan MLOps, organisasi dapat merampingkan kolaborasi sambil mempertahankan auditabilitas seluruh siklus hidup ML.
CI/CD untuk pengembang SQL
Pengembang SQL yang menggunakan Databricks SQL untuk mengelola tabel streaming dan tampilan materialisasi dapat memanfaatkan integrasi Git dan alur CI/CD untuk menyederhanakan alur kerja mereka dan mempertahankan alur berkualitas tinggi. Dengan diperkenalkannya dukungan Git untuk kueri, pengembang SQL dapat fokus pada penulisan kueri sambil memanfaatkan Git untuk mengontrol file mereka .sql secara versi, yang memungkinkan kolaborasi dan otomatisasi tanpa memerlukan keahlian infrastruktur yang mendalam. Selain itu, editor SQL memungkinkan kolaborasi real-time dan terintegrasi dengan mulus dengan alur kerja Git.
Untuk alur kerja SQL-centric:
Pengendalian versi file SQL
- Simpan file .sql di repositori Git menggunakan folder Databricks Git atau penyedia Git eksternal, misalnya, GitHub, Azure DevOps.
- Gunakan cabang (misalnya, pengembangan, penahapan, produksi) untuk mengelola perubahan khusus lingkungan.
.sqlIntegrasikan file ke dalam alur CI/CD untuk mengotomatiskan penyebaran:- Validasi perubahan sintaksis dan skema selama permintaan pull.
- Sebarkan
.sqlfile ke alur kerja atau pekerjaan Databricks SQL.
Pengaturan parameter untuk isolasi lingkungan
Gunakan variabel dalam
.sqlfile untuk mereferensikan sumber daya khusus lingkungan secara dinamis, seperti jalur data atau nama tabel:CREATE OR REFRESH STREAMING TABLE ${env}_sales_ingest AS SELECT * FROM read_files('s3://${env}-sales-data')
Menjadwalkan dan memantau pembaruan
- Gunakan tugas SQL dalam tugas Databricks untuk menjadwalkan pembaruan tabel dan tampilan materialisasi (
REFRESH MATERIALIZED VIEW view_name). - Pantau riwayat refresh menggunakan tabel sistem.
- Gunakan tugas SQL dalam tugas Databricks untuk menjadwalkan pembaruan tabel dan tampilan materialisasi (
Alur kerja mungkin:
- Kembangkan: Tulis dan uji
.sqlskrip secara lokal atau di editor Databricks SQL, lalu terapkan ke cabang Git. - Validasi: Selama permintaan pull, validasi sintaksis dan kompatibilitas skema menggunakan pemeriksaan CI otomatis.
- Sebarkan: Setelah digabungkan, sebarkan skrip .sql ke lingkungan target menggunakan alur CI/CD, misalnya, GitHub Actions atau Azure Pipelines.
- Monitor: Gunakan dasbor dan pemberitahuan Databricks untuk melacak performa kueri dan kesegaran data.
CI/CD untuk pengembang dashboard
Databricks mendukung integrasi dasbor ke dalam alur kerja CI/CD menggunakan Bundel Otomatisasi Deklaratif. Fitur ini memungkinkan pengembang dasbor untuk:
- Dasbor kontrol versi, yang memastikan auditabilitas dan menyederhanakan kolaborasi antar tim.
- Mengotomatiskan penerapan dasbor sekaligus dengan pekerjaan dan alur di seluruh lingkungan, untuk keselarasan menyeluruh.
- Kurangi kesalahan manual dan pastikan pembaruan diterapkan secara konsisten di seluruh lingkungan.
- Pertahankan alur kerja analitik berkualitas tinggi sambil mematuhi praktik terbaik CI/CD.
Untuk dasbor di CI/CD:
databricks bundle generateGunakan perintah untuk mengekspor dasbor yang ada sebagai file JSON dan menghasilkan konfigurasi YAML yang menyertakannya dalam bundel:resources: dashboards: sales_dashboard: display_name: 'Sales Dashboard' file_path: ./dashboards/sales_dashboard.lvdash.json warehouse_id: ${var.warehouse_id}Simpan file-file ini
.lvdash.jsondi repositori Git untuk melacak perubahan dan berkolaborasi secara efektif.Sebarkan dasbor secara authomatis di alur CI/CD dengan
databricks bundle deploy. Misalnya, langkah Tindakan GitHub untuk penyebaran:name: Deploy Dashboard run: databricks bundle deploy --target=prod env: DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }}Gunakan variabel, misalnya
${var.warehouse_id}, untuk membuat parameter konfigurasi seperti gudang SQL atau sumber data, memastikan penyebaran yang mulus di seluruh lingkungan dev, penahapan, dan produksi.bundle generate --watchGunakan opsi untuk terus menyinkronkan file JSON dasbor lokal dengan perubahan yang dibuat di antarmuka pengguna Databricks. Jika terjadi perbedaan, gunakan--forceflag selama deployment untuk menggantikan dasbor jarak jauh dengan versi lokal.
Untuk informasi tentang dasbor dalam bundel, rujuk ke sumber daya dasbor. Untuk detail tentang perintah bundel, lihat bundle grup perintah.