Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Untuk kasus penggunaan baru, Databricks merekomendasikan penyebaran agen di Databricks Apps untuk kontrol penuh atas kode agen, konfigurasi server, dan alur kerja penyebaran. Lihat Menulis agen AI dan menyebarkannya di Aplikasi Databricks.
Halaman ini menunjukkan cara menulis agen AI di Python menggunakan Agent Framework dan pustaka penulisan agen populer seperti LangGraph dan OpenAI.
Persyaratan
Petunjuk / Saran
Databricks merekomendasikan untuk menginstal versi terbaru klien MLflow Python saat mengembangkan agen.
Untuk menulis dan menyebarkan agen menggunakan pendekatan di halaman ini, instal perangkat berikut:
-
databricks-agents1.2.0 atau lebih tinggi -
mlflow3.1.3 atau lebih tinggi - Python 3.10 atau lebih tinggi.
- Gunakan komputasi tanpa server atau Databricks Runtime 13.3 LTS atau lebih tinggi untuk memenuhi persyaratan ini.
%pip install -U -qqqq databricks-agents mlflow
Databricks juga merekomendasikan penginstalan paket integrasi Databricks AI Bridge ke agen pembuat. Paket integrasi ini menyediakan lapisan API bersama yang berinteraksi dengan fitur AI Databricks, seperti Databricks AI/BI Genie dan Vector Search, di seluruh kerangka kerja penulisan agen dan SDK.
OpenAI
%pip install -U -qqqq databricks-openai
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
DSPy
%pip install -U -qqqq databricks-dspy
Agen Python Asli
%pip install -U -qqqq databricks-ai-bridge
Menggunakan ResponsesAgent untuk agen pembuat
Databricks merekomendasikan antarmuka MLflow ResponsesAgent untuk membuat agen kelas produksi.
ResponsesAgent memungkinkan Anda membangun agen dengan kerangka kerja pihak ketiga apa pun, lalu mengintegrasikannya dengan fitur AI Databricks untuk kemampuan pengelogan, pelacakan, evaluasi, penyebaran, dan pemantauan yang kuat.
ResponsesAgent Skema ini kompatibel dengan skema OpenAIResponses. Untuk mempelajari selengkapnya tentang OpenAI Responses, lihat OpenAI: Respons vs. ChatCompletion.
Nota
Antarmuka lama ChatAgent masih didukung pada Databricks. Namun, untuk agen baru, Databricks merekomendasikan penggunaan versi terbaru MLflow dan ResponsesAgent antarmuka.

ResponsesAgent memberikan manfaat berikut:
Kemampuan agen tingkat lanjut
- Dukungan multi-agen
- Output streaming: Streaming output dalam gugus yang lebih kecil.
- Sejarah pesan pemanggilan alat yang komprehensif: Mengembalikan beberapa pesan, termasuk pesan pemanggilan alat yang bersifat perantara, untuk meningkatkan kualitas dan pengelolaan percakapan.
- Dukungan untuk konfirmasi pemanggilan alat
- Dukungan untuk alat beroperasi jangka panjang
Pengembangan, penyebaran, dan pemantauan yang disederhanakan
-
Buat agen menggunakan kerangka kerja apa pun: Bungkus agen yang ada menggunakan antarmuka
ResponsesAgentuntuk mendapatkan kompatibilitas langsung dengan AI Playground, Evaluasi Agen, dan Pemantauan Agen. - Antarmuka penulisan bertipe: Menulis kode agen dengan menggunakan kelas Python bertipe, mendapatkan manfaat dari fitur pelengkapan otomatis di IDE dan notebook.
-
Inferensi tanda tangan otomatis: MLflow secara otomatis menyimpulkan
ResponsesAgenttanda tangan saat mencatat agen, menyederhanakan pendaftaran dan penyebaran. Lihat Infer Model Signature selama pengelogan. -
Pelacakan otomatis: MLflow secara otomatis melacak fungsi
predictdanpredict_streamAnda, serta menggabungkan respons yang dialirkan untuk memudahkan evaluasi dan tampilan. - tabel inferensi Gateway AI yang disempurnakan: Tabel inferensi Gateway AI diaktifkan secara otomatis untuk agen yang telah disebarkan, menyediakan akses ke metadata log permintaan terperinci.
-
Buat agen menggunakan kerangka kerja apa pun: Bungkus agen yang ada menggunakan antarmuka
Untuk mempelajari cara membuat ResponsesAgent, lihat contoh di bagian berikut dan dokumentasi MLflow - ResponsesAgent untuk Penyajian Model.
ResponsesAgent Contoh
Buku catatan berikut menunjukkan cara menulis streaming dan non-streaming ResponsesAgent menggunakan pustaka populer. Untuk mempelajari cara memperluas kemampuan agen ini, lihat Alat agen AI.
OpenAI
Agen obrolan sederhana OpenAI menggunakan model yang dihosting Databricks
Agen pemanggil alat OpenAI MCP
Agen pemanggil alat OpenAI menggunakan model yang dikelola oleh Databricks
Agen pemanggil alat OpenAI yang menggunakan model yang dihosting oleh OpenAI
LangGraph
Agen panggilan alat MCP LangGraph
DSPy
Agen pemanggil alat satu putaran DSPy
Contoh multi-agen
Untuk mempelajari cara membuat sistem multi-agen, lihat Menggunakan Genie dalam sistem multi-agen (Model Serving).
Contoh agen stateful
Untuk mempelajari cara membuat agen stateful dengan memori jangka pendek dan jangka panjang menggunakan Lakebase sebagai penyimpanan memori, lihat Memori agen AI (Model Serving).
Contoh agen tidak berkomunikasi
Tidak seperti agen berbasis percakapan yang mengelola dialog multi-giliran, agen non-berbasis percakapan berfokus pada menjalankan tugas yang ditentukan dengan baik secara efisien. Arsitektur yang disederhanakan ini memungkinkan throughput yang lebih tinggi untuk permintaan independen.
Untuk mempelajari cara membuat agen non-percakapan, lihat Agen AI non-percakapan menggunakan MLflow.
Bagaimana jika saya sudah memiliki agen?
Jika Anda sudah memiliki agen yang dibangun dengan LangChain, LangGraph, atau kerangka kerja serupa, Anda tidak perlu menulis ulang agen Anda untuk menggunakannya di Databricks. Sebagai gantinya, cukup bungkus agen Anda yang ada dengan antarmuka MLflow ResponsesAgent :
Tulis kelas pembungkus Python yang mewarisi dari
mlflow.pyfunc.ResponsesAgent.Di dalam kelas pembungkus, referensikan agen yang ada sebagai atribut
self.agent = your_existing_agent.Kelas
ResponsesAgentmengharuskan implementasi metodepredictyang mengembalikan objekResponsesAgentResponseuntuk menangani permintaan non-streaming. Berikut ini adalah contohResponsesAgentResponsesskema:import uuid # input as a dict {"input": [{"role": "user", "content": "What did the data scientist say when their Spark job finally completed?"}]} # output example ResponsesAgentResponse( output=[ { "type": "message", "id": str(uuid.uuid4()), "content": [{"type": "output_text", "text": "Well, that really sparked joy!"}], "role": "assistant", }, ] )Dalam fungsi
predict, konversi pesan masuk dariResponsesAgentRequestke dalam format yang diharapkan agen. Setelah agen menghasilkan respons, konversikan outputnya menjadiResponsesAgentResponseobjek.
Lihat contoh kode berikut untuk melihat cara mengonversi agen yang ada menjadi ResponsesAgent:
Konversi dasar
Untuk agen non-streaming, konversikan input dan output di dalam fungsi predict.
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
)
class MyWrappedAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Call your existing agent (non-streaming)
agent_response = self.agent.invoke(messages)
# Convert your agent's output to ResponsesAgent format, assuming agent_response is a str
output_item = (self.create_text_output_item(text=agent_response, id=str(uuid4())),)
# Return the response
return ResponsesAgentResponse(output=[output_item])
Streaming dengan penggunaan ulang kode
Untuk agen streaming, Anda dapat pintar dan menggunakan kembali logika untuk menghindari duplikat kode yang mengonversi pesan:
from typing import Generator
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages, included in full examples linked below
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Stream from your existing agent
item_id = str(uuid4())
aggregated_stream = ""
for chunk in self.agent.stream(messages):
# Convert each chunk to ResponsesAgent format
yield self.create_text_delta(delta=chunk, item_id=item_id)
aggregated_stream += chunk
# Emit an aggregated output_item for all the text deltas with id=item_id
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(text=aggregated_stream, id=item_id),
)
Migrasi dari ChatCompletions
Jika agen yang ada menggunakan API OpenAI ChatCompletions, Anda dapat memigrasikannya ke ResponsesAgent tanpa menulis ulang logika intinya. Tambahkan pembungkus yang:
- Mengkover pesan masuk
ResponsesAgentRequestke dalam formatChatCompletionsyang diharapkan oleh agen Anda. - Mengubah output
ChatCompletionske dalam skemaResponsesAgentResponse. - Secara opsional mendukung streaming dengan memetakan delta bertambah bertahap dari
ChatCompletionske dalamResponsesAgentStreamEventobjek.
from typing import Generator
from uuid import uuid4
from databricks.sdk import WorkspaceClient
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
# Legacy agent that outputs ChatCompletions objects
class LegacyAgent:
def __init__(self):
self.w = WorkspaceClient()
self.OpenAI = self.w.serving_endpoints.get_open_ai_client()
def stream(self, messages):
for chunk in self.OpenAI.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=messages,
stream=True,
):
yield chunk.to_dict()
# Wrapper that converts the legacy agent to a ResponsesAgent
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# `agent` is your existing ChatCompletions agent
self.agent = agent
def prep_msgs_for_llm(self, messages):
# dummy example of prep_msgs_for_llm
# real example of prep_msgs_for_llm included in full examples linked below
return [{"role": "user", "content": "Hello, how are you?"}]
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# process the ChatCompletion output stream
agent_content = ""
tool_calls = []
msg_id = None
for chunk in self.agent.stream(messages): # call the underlying agent's stream method
delta = chunk["choices"][0]["delta"]
msg_id = chunk.get("id", None)
content = delta.get("content", None)
if tc := delta.get("tool_calls"):
if not tool_calls: # only accommodate for single tool call right now
tool_calls = tc
else:
tool_calls[0]["function"]["arguments"] += tc[0]["function"]["arguments"]
elif content is not None:
agent_content += content
yield ResponsesAgentStreamEvent(**self.create_text_delta(content, item_id=msg_id))
# aggregate the streamed text content
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(agent_content, msg_id),
)
for tool_call in tool_calls:
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_function_call_item(
str(uuid4()),
tool_call["id"],
tool_call["function"]["name"],
tool_call["function"]["arguments"],
),
)
agent = MyWrappedStreamingAgent(LegacyAgent())
for chunk in agent.predict_stream(
ResponsesAgentRequest(input=[{"role": "user", "content": "Hello, how are you?"}])
):
print(chunk)
Untuk contoh lengkapnya, lihat ResponsesAgent contoh.
Respons streaming
Streaming memungkinkan agen mengirim respons dalam potongan real-time alih-alih menunggu respons lengkap. Untuk menerapkan streaming dengan ResponsesAgent, keluarkan serangkaian peristiwa delta diikuti dengan peristiwa penyelesaian akhir:
-
Memancarkan peristiwa delta: Kirim beberapa peristiwa
output_text.deltadenganitem_idyang sama untuk mengalirkan potongan teks secara real time. -
Selesaikan dengan peristiwa selesai: Mengirimkan peristiwa akhir
response.output_item.donedenganitem_idyang sama seperti peristiwa delta yang berisi teks output akhir lengkap.
Setiap peristiwa delta mengalirkan potongan teks ke klien. Peristiwa selesai akhir berisi teks respons lengkap dan memberi sinyal Databricks untuk melakukan hal berikut:
- Melacak output agen Anda dengan pelacakan MLflow
- Menggabungkan respons yang dialirkan dalam tabel inferensi AI Gateway
- Menampilkan output lengkap di antarmuka pengguna AI Playground
Penyebaran kesalahan pada streaming
Mosaic AI menyebarluaskan kesalahan apa pun yang ditemui saat streaming dengan token terakhir di bawah databricks_output.error. Menjadi tanggung jawab klien yang melakukan panggilan untuk menangani dan menampilkan kesalahan ini dengan benar.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Fitur tingkat lanjut
Input dan output kustom
Beberapa skenario mungkin memerlukan input agen tambahan, seperti client_type dan session_id, atau output seperti tautan sumber pengambilan yang tidak boleh disertakan dalam riwayat obrolan untuk interaksi di masa mendatang.
Untuk skenario ini, MLflow ResponsesAgent secara asli mendukung bidang custom_inputs dan custom_outputs. Anda dapat mengakses input kustom melalui request.custom_inputs dalam semua contoh yang ditautkan di atas dalam Contoh ResponsesAgent.
Peringatan
Aplikasi tinjauan Evaluasi Agen tidak mendukung jejak penyajian untuk agen dengan bidang input tambahan.
Lihat buku catatan berikut untuk mempelajari cara mengatur input dan output kustom.
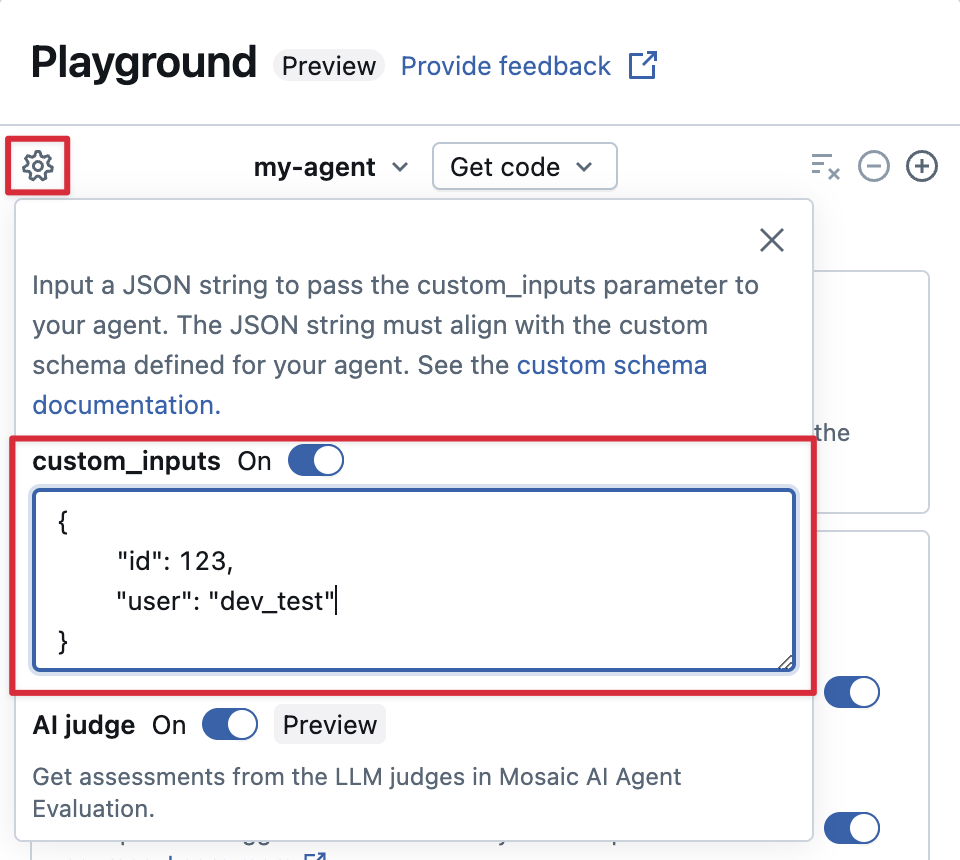
Berikan custom_inputs di AI Playground dan tinjau aplikasi
Jika agen Anda menerima input tambahan menggunakan custom_inputs bidang , Anda dapat memberikan input ini secara manual di AI Playground dan aplikasi ulasan.
Di AI Playground atau Aplikasi Tinjauan Agen, pilih
 .
.Aktifkan masukan_kustom.
Berikan objek JSON yang cocok dengan skema input yang ditentukan agen Anda.
Tentukan skema pengalih kustom
Agen AI biasanya menggunakan pengambil data untuk menemukan dan melakukan pencarian pada data yang tidak terstruktur di indeks pencarian vektor. Misalnya alat retriever, lihat Menyambungkan agen ke data yang tidak terstruktur.
Lacak pengambil data ini di dalam agen Anda dengan rentang MLflow RETRIEVER untuk mengaktifkan fitur produk Databricks, termasuk:
- Secara otomatis menampilkan tautan ke dokumen sumber yang diambil di antarmuka pengguna AI Playground
- Menjalankan penilaian otomatis untuk keterkaitan dan relevansi pengambilan data dalam Evaluasi Agen
Nota
Databricks merekomendasikan penggunaan alat retriever yang disediakan oleh paket Databricks AI Bridge seperti databricks_langchain.VectorSearchRetrieverTool dan databricks_openai.VectorSearchRetrieverTool karena sudah sesuai dengan skema MLflow retriever. Lihat Kembangkan secara lokal alat pengambilan Pencarian Vektor dengan AI Bridge.
Jika agen Anda menyertakan rentang retriever dengan skema kustom, panggil mlflow.models.set_retriever_schema saat Anda menentukan agen Anda dalam kode. Ini mencocokkan kolom output retriever Anda ke bidang yang diharapkan oleh MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Nota
Kolom doc_uri sangat penting saat mengevaluasi performa retriever.
doc_uri adalah pengidentifikasi utama untuk dokumen yang dikembalikan oleh retriever, memungkinkan Anda membandingkannya dengan kumpulan evaluasi kebenaran dasar. Lihat Set evaluasi (MLflow 2).
Pertimbangan penyebaran
Bersiap untuk Penyajian Model Databricks
Databricks menerapkan ResponsesAgent secara terdistribusi di lingkungan Databricks Model Serving. Ini berarti bahwa selama percakapan multi-giliran, replika server yang sama mungkin tidak menangani semua permintaan. Perhatikan implikasi yang harus diperhatikan dalam mengelola status agen berikut:
Hindari caching lokal: Saat meng-deploy
ResponsesAgent, jangan asumsikan replika yang sama menangani semua permintaan dalam percakapan multi-giliran. Mengkonstruksi kembali status internal menggunakan skema kamusResponsesAgentRequestuntuk setiap langkah.keadaan yang aman dari thread: Rancang keadaan agen agar thread-safe, mencegah konflik dalam lingkungan multi-thread.
Menginisialisasi status dalam fungsi
predict: Menginisialisasi status setiap kali fungsipredictdipanggil, bukan selama inisialisasiResponsesAgent. Menyimpan status di tingkatResponsesAgentdapat membocorkan informasi antara percakapan dan menyebabkan konflik karena satu replikaResponsesAgentdapat menangani permintaan dari beberapa percakapan.
Kode parametris untuk penyebaran di seluruh lingkungan
Memparametrisasi kode agen untuk menggunakan kembali kode agen yang sama di berbagai lingkungan.
Parameter adalah pasangan kunci-nilai yang Anda tentukan dalam kamus Python atau file .yaml.
Untuk mengonfigurasi kode, buat ModelConfig menggunakan kamus Python atau .yaml file.
ModelConfig adalah sekumpulan parameter kunci-nilai yang memungkinkan manajemen konfigurasi fleksibel. Misalnya, Anda dapat menggunakan kamus selama pengembangan lalu mengonversinya ke file .yaml untuk penyebaran produksi dan CI/CD.
Contoh ModelConfig ditunjukkan di bawah ini:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-meta-llama-3-3-70b-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Dalam kode agensi Anda, Anda dapat mengacu pada konfigurasi bawaan (pengembangan) dari file atau kamus .yaml.
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-meta-llama-3-3-70b-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Kemudian, saat mencatat agen Anda, tentukan parameter model_config ke log_model untuk menentukan set parameter kustom yang akan digunakan saat memuat agen yang dicatat. Lihat dokumentasi MLflow - ModelConfig.
Menggunakan kode sinkron atau pola panggilan balik
Untuk memastikan stabilitas dan kompatibilitas, gunakan kode sinkron atau pola berbasis panggilan balik dalam implementasi agen Anda.
Azure Databricks secara otomatis mengelola komunikasi asinkron untuk memberikan kesamaan waktu dan performa yang optimal saat Anda menjalankan agen. Memperkenalkan perulangan peristiwa kustom atau kerangka kerja asinkron dapat menyebabkan kesalahan seperti RuntimeError: This event loop is already running and caused unpredictable behavior.
Azure Databricks merekomendasikan untuk menghindari pemrograman asinkron, seperti menggunakan asyncio atau membuat loop peristiwa kustom, saat mengembangkan agen.