Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini membimbing Anda membangun agen AI yang secara bersamaan menggunakan pengambilan dan alat.
Ini adalah tutorial tingkat menengah yang mengasumsikan beberapa keakraban dengan dasar-dasar membangun agen di Databricks. Jika Anda baru dalam membangun agen, lihat Mulai menggunakan agen AI.
Contoh notebook mencakup semua kode yang digunakan dalam tutorial.
Tutorial ini mencakup beberapa tantangan inti dalam membangun aplikasi AI generatif:
- Menyederhanakan pengalaman pengembangan untuk tugas umum seperti membuat alat dan men-debug eksekusi agen.
- Tantangan operasional seperti:
- Konfigurasi agen pelacakan
- Menentukan input dan output dengan cara yang dapat diprediksi
- Mengelola versi dependensi
- Kontrol dan penyebaran versi
- Mengukur dan meningkatkan kualitas dan keandalan agen.
Untuk kesederhanaan, tutorial ini menggunakan pendekatan dalam memori untuk mengaktifkan pencarian kata kunci atas himpunan data yang berisi dokumentasi Databricks yang dipotong.
Contoh buku catatan
Notebook mandiri ini dirancang untuk dengan cepat membuat Anda bekerja dengan agen AI Mosaik menggunakan contoh dokumen corpus. Ini siap untuk dijalankan tanpa penyiapan atau data yang diperlukan.
Demo agen AI Mosaik
Membuat agen dan alat
Mosaic AI Agent Framework mendukung banyak kerangka kerja penulisan yang berbeda. Contoh ini menggunakan LangGraph untuk mengilustrasikan konsep, tetapi ini bukan tutorial LangGraph.
Untuk contoh kerangka kerja lain yang didukung, lihat Menulis agen AI dan menyebarkannya di Aplikasi Databricks.
Langkah pertama adalah membuat agen. Anda harus menentukan klien LLM dan daftar alat. Paket databricks-langchain Python mencakup klien yang kompatibel dengan LangChain dan LangGraph untuk LLM Databricks dan alat yang terdaftar di Unity Catalog.
Titik akhir harus berupa API pemanggilan fungsi Model Dasar atau Model Eksternal yang menggunakan Gateway AI. Lihat Model yang didukung.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
Kode berikut mendefinisikan fungsi yang membuat agen dari model dan beberapa alat, mendiskusikan internal kode agen ini berada di luar cakupan halaman ini. Untuk informasi selengkapnya tentang cara membuat agen LangGraph, lihat dokumentasi LangGraph.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Menentukan alat agen
Alat adalah konsep mendasar untuk membangun agen. Mereka menyediakan kemampuan untuk mengintegrasikan LLM dengan kode yang ditentukan manusia. Saat diberikan perintah dan daftar alat, LLM yang memanggil alat menghasilkan argumen untuk menggunakan alat tersebut. Untuk informasi selengkapnya tentang alat dan menggunakannya dengan agen Mosaic AI, lihat Alat agen AI.
Langkah pertama adalah membuat alat ekstraksi kata kunci berdasarkan TF-IDF. Contoh ini menggunakan scikit-learn dan alat Unity Catalog.
Paket ini databricks-langchain menyediakan cara mudah untuk bekerja dengan alat Katalog Unity. Kode berikut menggambarkan cara mengimplementasikan dan mendaftarkan alat ekstraktor kata kunci.
Nota
Ruang kerja Databricks memiliki alat bawaan, system.ai.python_exec, yang dapat Anda gunakan untuk memperluas agen dengan kemampuan menjalankan skrip Python di lingkungan yang terisolasi. Alat bawaan lain yang berguna termasuk koneksi eksternal dan fungsi AI.
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Berikut adalah penjelasan tentang kode di atas:
- Membuat klien yang menggunakan Unity Catalog di ruang kerja Databricks sebagai "repositori" untuk membuat dan menemukan alat.
- Menentukan fungsi Python yang melakukan ekstraksi kata kunci TF-IDF.
- Mendaftarkan fungsi Python sebagai fungsi Katalog Unity.
Alur kerja ini memecahkan beberapa masalah umum. Anda sekarang memiliki registri pusat untuk alat yang, seperti objek lain di Unity Catalog, dapat diatur. Misalnya, jika perusahaan memiliki cara standar untuk menghitung tingkat pengembalian internal, Anda dapat menentukannya sebagai fungsi di Unity Catalog, dan memberikan akses ke semua pengguna atau agen dengan peran tersebut FinancialAnalyst .
Untuk membuat alat ini dapat digunakan oleh agen LangChain, gunakan UCFunctionToolkit yang membuat kumpulan alat untuk diberikan kepada LLM untuk pemilihan:
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
Kode berikut menunjukkan cara menguji alat:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
Kode berikut membuat agen yang menggunakan alat ekstraksi kata kunci.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
Dalam jejak yang dihasilkan, Anda bisa melihat bahwa LLM memilih alat.
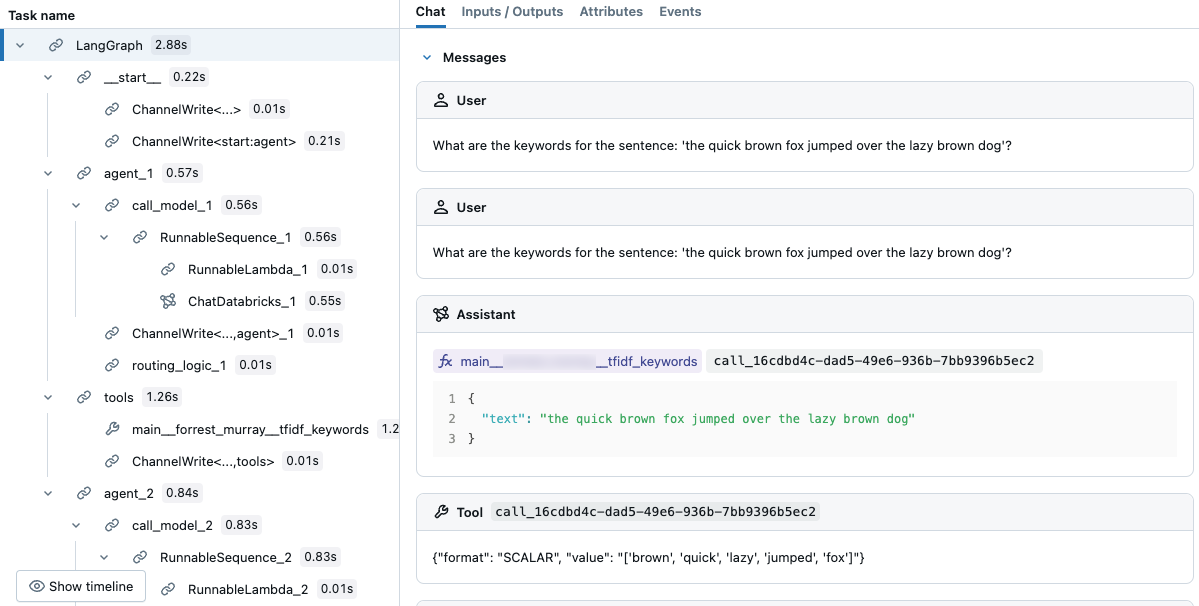
Gunakan jejak log untuk melakukan debugging pada agen
MLflow Tracing adalah alat yang ampuh untuk men-debug dan mengamati aplikasi AI generatif, termasuk agen. Ini menangkap informasi operasi terperinci melalui rentang, yang merangkum segmen kode tertentu dan mencatat input, output, dan data waktu.
Untuk pustaka populer seperti LangChain, aktifkan pelacakan otomatis dengan mlflow.langchain.autolog(). Anda juga dapat menggunakan mlflow.start_span() untuk menyesuaikan penelusuran. Misalnya, Anda dapat menambahkan bidang nilai data kustom atau pelabelan untuk pengamatan. Kode yang berjalan dalam konteks rentang tersebut dikaitkan dengan bidang yang Anda tentukan. Dalam contoh di dalam memori TF-IDF ini, berikan nama dan tipe rentang.
Untuk mempelajari selengkapnya tentang pelacakan, lihat Pelacakan MLflow - Pengamatan GenAI.
Contoh berikut membuat alat retriever menggunakan indeks TF-IDF dalam memori sederhana. Ini menunjukkan pencatatan otomatis untuk pelaksanaan alat dan pelacakan rentang khusus untuk pengamatan yang lebih baik.
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
Kode ini menggunakan jenis rentang khusus, RETRIEVER, yang dikhususkan untuk alat pencari. Fitur agen Mosaic AI lainnya (seperti AI Playground, antarmuka pengguna tinjauan, dan evaluasi) menggunakan RETRIEVER tipe span untuk menampilkan hasil pengambilan.
Alat Retriever mengharuskan Anda menentukan skemanya untuk memastikan kompatibilitas dengan fitur-fitur Databricks berikutnya. Untuk informasi selengkapnya tentang mlflow.models.set_retriever_schema, lihat Skema pengalih kustom.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
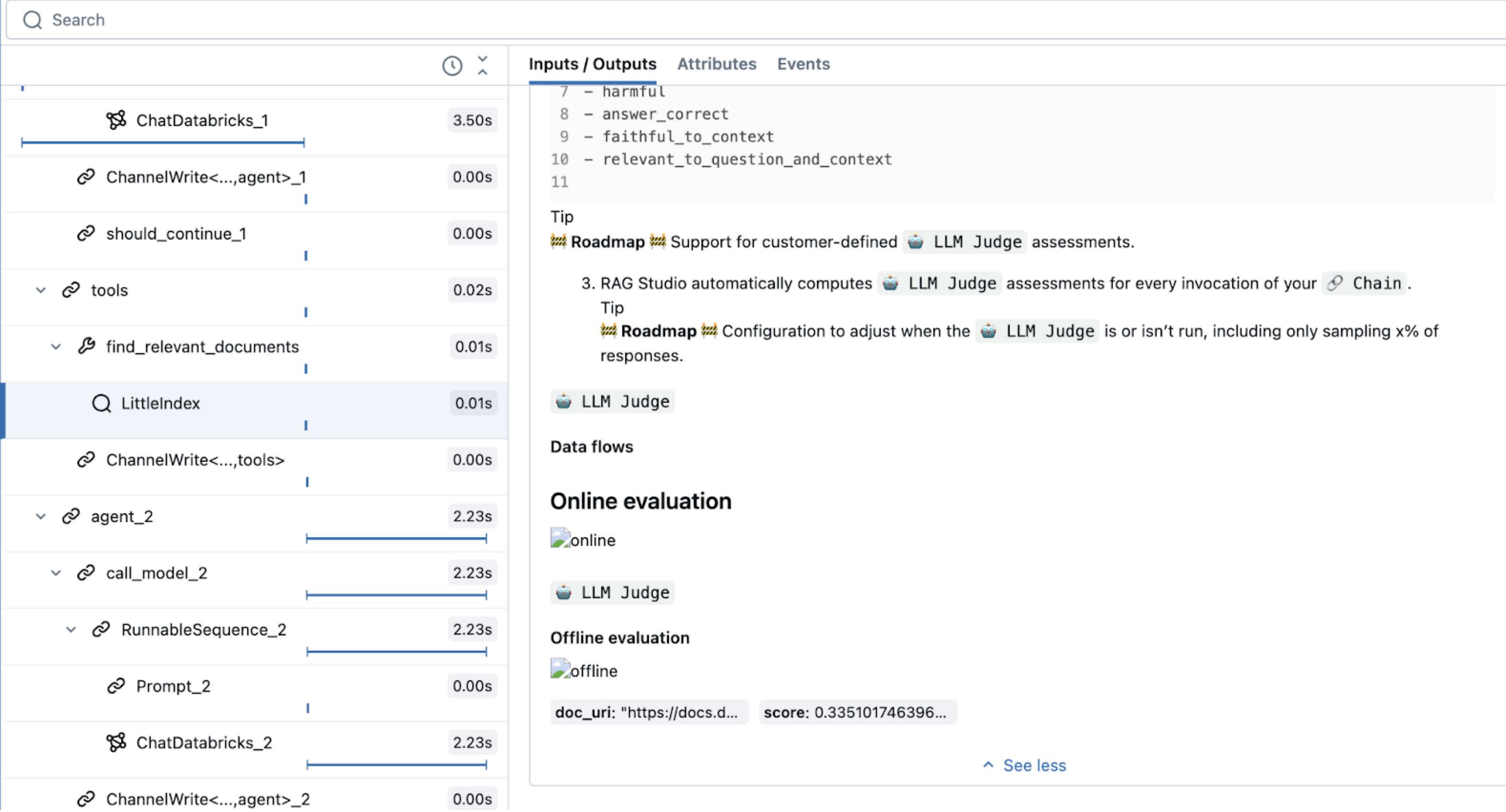
Tentukan agen
Langkah selanjutnya adalah mengevaluasi agen dan menyiapkannya untuk implementasi. Pada tingkat tinggi, ini melibatkan hal-hal berikut:
- Tentukan API yang dapat diprediksi untuk agen menggunakan tanda tangan.
- Tambahkan konfigurasi model, yang memudahkan untuk mengonfigurasi parameter.
- Catat model dengan dependensi yang memberinya lingkungan yang dapat direproduksi dan memungkinkan Anda mengonfigurasi autentikasinya ke layanan lain.
Antarmuka MLflow ChatAgent menyederhanakan penentuan input dan output agen. Untuk menggunakannya, tentukan agen Anda sebagai subkelas ChatAgent, menerapkan fungsi inferensi non-streaming dengan predict dan fungsi inferensi streaming dengan predict_stream.
ChatAgent adalah agnostik untuk pilihan kerangka kerja penulisan agen Anda, memungkinkan Anda untuk dengan mudah menguji dan menggunakan kerangka kerja dan implementasi agen yang berbeda - satu-satunya persyaratan adalah mengimplementasikan predict antarmuka dan predict_stream .
Penulisan agen Anda dengan menggunakan ChatAgent memberikan berbagai manfaat, antara lain:
- Dukungan keluaran streaming
- Sejarah pesan pemanggilan alat yang komprehensif: Mengembalikan beberapa pesan, termasuk pesan pemanggilan alat yang bersifat perantara, untuk meningkatkan kualitas dan pengelolaan percakapan.
- dukungan sistem multi-agen
- Integrasi fitur Databricks: Kompatibilitas siap pakai dengan 'AI Playground', 'Evaluasi Agen', dan 'Pemantauan Agen'.
- Antarmuka penulisan bertipe: Menulis kode agen dengan menggunakan kelas Python bertipe, mendapatkan manfaat dari fitur pelengkapan otomatis di IDE dan notebook.
Untuk informasi selengkapnya tentang penulisan ChatAgent lihat Skema agen input dan output warisan (Model Melayani).
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
Kode berikut menunjukkan cara menggunakan ChatAgent.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
Konfigurasikan agen dengan parameter
Kerangka Kerja Agen memungkinkan Anda mengontrol eksekusi agen dengan parameter. Ini berarti Anda dapat dengan cepat menguji konfigurasi agen yang berbeda, seperti mengalihkan titik akhir LLM atau mencoba alat yang berbeda tanpa mengubah kode yang mendasar.
Kode berikut membuat kamus konfigurasi yang mengatur parameter agen saat menginisialisasi model.
Untuk detail selengkapnya tentang membuat parameter agen, lihat Kode parametris untuk penyebaran di seluruh lingkungan.
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Catat agen
Setelah menentukan agen, langkah selanjutnya adalah mencatatnya. Dalam MLflow, pengelogan agen berarti menyimpan konfigurasi agen (termasuk dependensi) sehingga dapat digunakan untuk evaluasi dan penyebaran.
Nota
Saat mengembangkan agen di notebook, MLflow menyimpulkan dependensi agen dari lingkungan notebook.
Untuk mencatat agen dari buku catatan, Anda dapat menulis semua kode yang menentukan model dalam satu sel, lalu menggunakan %%writefile perintah ajaib untuk menyimpan definisi agen ke file:
%%writefile agent.py
...
<Code that defines the agent>
Jika agen memerlukan akses ke sumber daya eksternal, seperti Unity Catalog untuk menjalankan alat ekstraksi kata kunci, Anda harus mengonfigurasi autentikasi untuk agen sehingga dapat mengakses sumber daya saat disebarkan.
Untuk menyederhanakan autentikasi untuk sumber daya Databricks, aktifkan passthrough autentikasi otomatis:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
Untuk mempelajari selengkapnya tentang agen pengelogan, lihat Pengelogan berbasis kode.
Evaluasi agen
Langkah selanjutnya adalah mengevaluasi agen untuk melihat performanya. Evaluasi Agen menantang dan menimbulkan banyak pertanyaan, seperti berikut ini:
- Apa metrik yang tepat untuk mengevaluasi kualitas? Bagaimana cara mempercayai output metrik ini?
- Saya perlu mengevaluasi banyak ide - bagaimana saya...
- jalankan evaluasi dengan cepat sehingga sebagian besar waktu saya tidak dihabiskan untuk menunggu?
- Cepatlah membandingkan versi agen saya berdasarkan kualitas, biaya, dan latensi.
- Bagaimana cara cepat mengidentifikasi akar penyebab masalah kualitas?
Sebagai ilmuwan atau pengembang data, Anda mungkin bukan ahli materi pelajaran yang sebenarnya. Bagian lainnya menjelaskan alat Evaluasi Agen yang dapat membantu Anda menentukan output yang baik.
Membuat kumpulan evaluasi
Untuk menentukan arti kualitas untuk agen, Anda menggunakan metrik untuk mengukur performa agen pada kumpulan evaluasi. Lihat Menentukan "kualitas": Set evaluasi.
Dengan Evaluasi Agen, Anda dapat membuat set evaluasi sintetis dan mengukur kualitas dengan menjalankan evaluasi. Idenya adalah memulai dari fakta, seperti sekumpulan dokumen, dan "bekerja mundur" dengan menggunakan fakta-fakta tersebut untuk menghasilkan serangkaian pertanyaan. Anda dapat mengkondisikan pertanyaan yang dihasilkan dengan memberikan beberapa panduan:
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
Evaluasi yang dihasilkan meliputi yang berikut ini:
Bidang permintaan yang terlihat seperti yang
ChatAgentRequestdisebutkan sebelumnya:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}Daftar "konten yang diharapkan diperoleh". Skema retriever didefinisikan dengan bidang
contentdandoc_uri.[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]Daftar fakta yang diharapkan. Ketika Anda membandingkan dua respons, mungkin sulit untuk menemukan perbedaan kecil di antara mereka. Fakta yang diharapkan menyaring perbedaan antara jawaban yang benar, jawaban yang sebagian benar, dan jawaban yang salah, serta meningkatkan baik kualitas penilaian AI maupun pengalaman orang-orang yang bekerja dengan agen tersebut.
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]Bidang source_id yang di sini adalah
SYNTHETIC_FROM_DOC. Saat Anda membangun set evaluasi yang lebih lengkap, sampel akan berasal dari berbagai sumber yang berbeda, sehingga bidang ini membedakannya.
Untuk mempelajari selengkapnya tentang membuat set evaluasi, lihat Mensintesis kumpulan evaluasi.
Mengevaluasi agen menggunakan hakim LLM
Mengevaluasi performa agen secara manual pada begitu banyak contoh yang dihasilkan tidak efisien. Dalam skala besar, menggunakan LLM sebagai juri adalah solusi yang jauh lebih masuk akal. Untuk menggunakan hakim bawaan yang tersedia saat menggunakan Evaluasi Agen, gunakan kode berikut:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
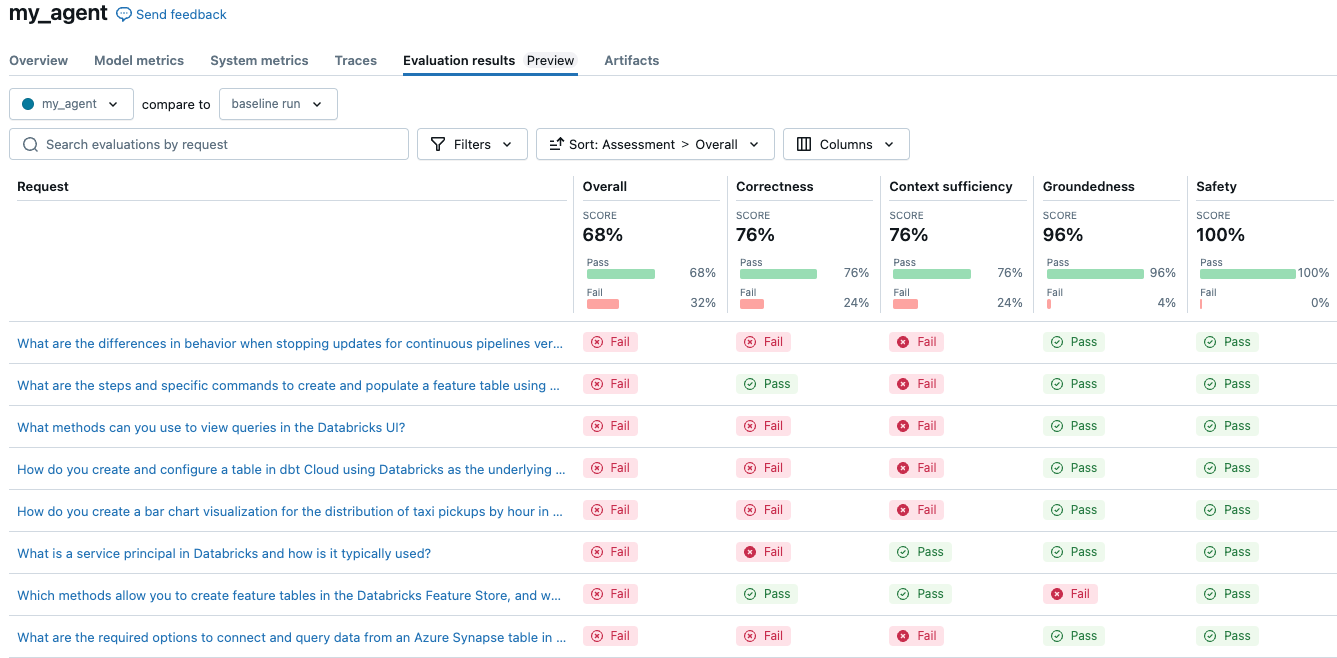
Agen sederhana mencetak skor 68% secara keseluruhan. Hasil Anda mungkin berbeda di sini tergantung pada konfigurasi yang Anda gunakan. Menjalankan eksperimen untuk membandingkan tiga LLM yang berbeda untuk biaya dan kualitas sesingkat mengubah konfigurasi dan mengevaluasi ulang.
Pertimbangkan untuk mengubah konfigurasi model untuk menggunakan LLM, prompt sistem, atau pengaturan suhu yang berbeda.
Hakim-hakim ini dapat disesuaikan untuk mengikuti pedoman yang sama yang akan digunakan pakar manusia untuk mengevaluasi respons. Untuk informasi selengkapnya tentang juri LLM, lihat Hakim AI bawaan (MLflow 2).
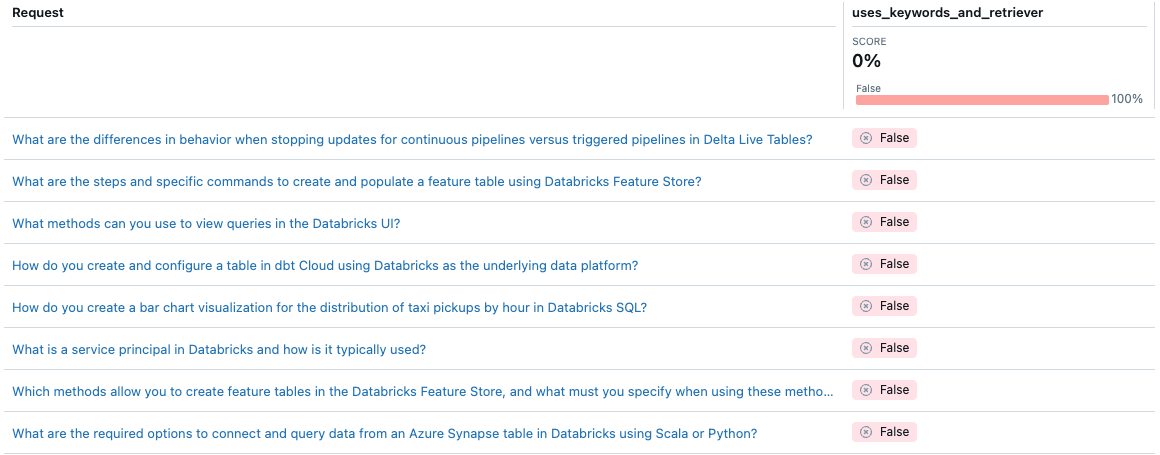
Dengan Evaluasi Agen, Anda dapat menyesuaikan cara Mengukur kualitas agen tertentu menggunakan metrik kustom. Anda dapat memikirkan evaluasi seperti pengujian integrasi, dan metrik individual sebagai pengujian unit. Contoh berikut menggunakan metrik Boolean untuk memeriksa apakah agen menggunakan ekstraksi kata kunci dan retriever untuk permintaan tertentu:
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Perhatikan bahwa agen tidak pernah menggunakan ekstraksi kata kunci. Bagaimana Anda dapat memperbaiki masalah ini?
Menyebarkan dan memantau agen
Ketika Anda siap untuk mulai menguji agen Anda dengan pengguna nyata, Agent Framework menyediakan solusi siap produksi untuk melayani agen di Mosaic AI Model Serving.
Menyebarkan agen ke Model Serving memberikan manfaat berikut:
- Model Serving mengelola autoscaling, pengelogan, kontrol versi, dan kontrol akses, memungkinkan Anda untuk fokus pada pengembangan agen berkualitas.
- Pakar subjek dapat menggunakan Aplikasi Ulasan untuk berinteraksi dengan agen dan memberikan umpan balik yang dapat dimasukkan ke dalam pemantauan dan evaluasi Anda.
- Anda dapat memantau agen dengan menjalankan evaluasi pada lalu lintas waktu nyata. Meskipun lalu lintas pengguna tidak menyertakan kebenaran dasar, hakim LLM (dan metrik kustom yang Anda buat) melakukan evaluasi yang tidak diawasi.
Kode berikut menyebarkan agen ke endpoint pelayan. Untuk informasi selengkapnya, lihat Menyebarkan agen untuk aplikasi AI generatif (Model Melayani).
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)