Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Arsitektur medali menjelaskan serangkaian lapisan data yang menunjukkan kualitas data yang disimpan di lakehouse. Azure Databricks merekomendasikan untuk mengambil pendekatan berlapis untuk membangun satu sumber kebenaran untuk produk data perusahaan.
Arsitektur ini menjamin atomitas, konsistensi, isolasi, dan durabilitas saat data melewati beberapa lapisan validasi dan transformasi sebelum disimpan dalam tata letak yang dioptimalkan untuk analitik yang efisien. Istilah perunggu (mentah), perak (divalidasi), dan emas (diperkaya) menggambarkan kualitas data di masing-masing lapisan ini.
Arsitektur medali sebagai pola desain data
Arsitektur medali adalah pola desain data yang digunakan untuk mengatur data secara logis. Tujuannya adalah untuk secara bertahap dan progresif meningkatkan struktur dan kualitas data saat mengalir melalui setiap lapisan arsitektur (dari perunggu ⇒ tabel lapisan Silver ⇒ Gold). Kadang, arsitektur medalion juga disebut sebagai arsitektur multi-hop.
Dengan memajukan data melalui lapisan ini, organisasi dapat secara bertahap meningkatkan kualitas dan keandalan data, sehingga lebih cocok untuk kecerdasan bisnis dan aplikasi pembelajaran mesin.
Mengikuti arsitektur medali adalah praktik terbaik yang direkomendasikan tetapi bukan persyaratan.
| Pertanyaan | Perunggu | Perak | Emas |
|---|---|---|---|
| Apa yang terjadi di lapisan ini? | Penyerapan data mentah | Pembersihan dan validasi data | Pemodelan dan agregasi dimensi |
| Siapa pengguna yang dimaksudkan? |
|
|
|
Contoh arsitektur medali
Contoh arsitektur medali ini menunjukkan lapisan perunggu, perak, dan emas untuk digunakan oleh tim operasi bisnis. Setiap lapisan disimpan dalam skema katalog ops yang berbeda.
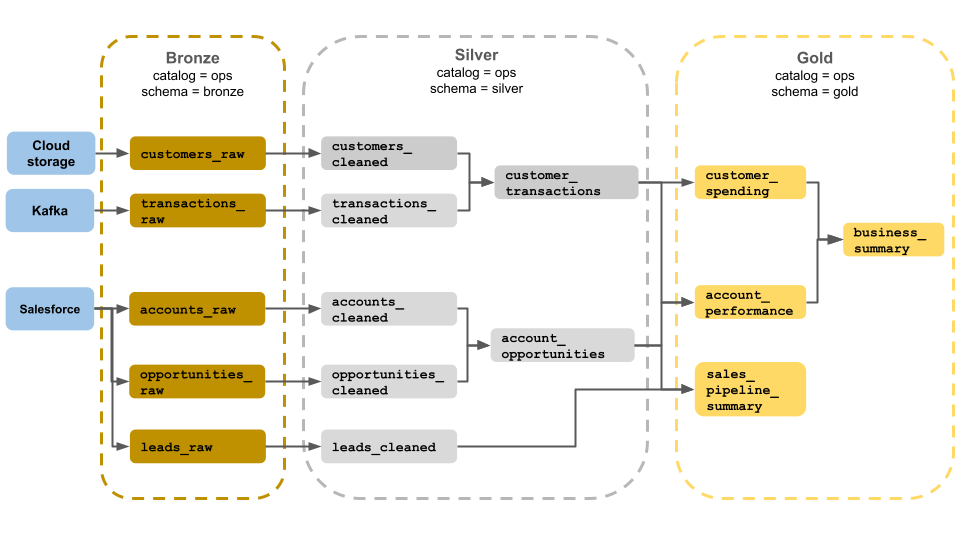
-
Lapisan perunggu (
ops.bronze): Menyerap data mentah dari penyimpanan cloud, Kafka, dan Salesforce. Tidak ada pembersihan atau validasi data yang dilakukan di sini. -
Lapisan perak (
ops.silver): Pembersihan dan validasi data dilakukan di lapisan ini.- Data tentang pelanggan dan transaksi dibersihkan dengan menghilangkan null dan mengkarantina rekaman yang tidak valid. Himpunan data ini digabungkan ke dalam himpunan data baru yang disebut
customer_transactions. Ilmuwan data dapat menggunakan himpunan data ini untuk analitik prediktif. - Demikian pula, akun dan himpunan data peluang dari Salesforce bergabung untuk membuat
account_opportunities, yang ditingkatkan dengan informasi akun. - Data
leads_rawdibersihkan dalam himpunan data yang disebutleads_cleaned.
- Data tentang pelanggan dan transaksi dibersihkan dengan menghilangkan null dan mengkarantina rekaman yang tidak valid. Himpunan data ini digabungkan ke dalam himpunan data baru yang disebut
-
Lapisan emas (
ops.gold): Lapisan ini dirancang untuk pengguna bisnis. Ini berisi lebih sedikit himpunan data daripada perak dan emas.-
customer_spending: Rata-rata dan total pengeluaran untuk setiap pelanggan. -
account_performance: Performa harian untuk setiap akun. -
sales_pipeline_summary: Informasi tentang proses alur penjualan end-to-end. -
business_summary: Informasi yang sangat agregat untuk staf eksekutif.
-
Menyerap data mentah ke lapisan perunggu
Lapisan perunggu berisi data mentah dan tidak valid. Data yang diserap dalam lapisan perunggu biasanya memiliki karakteristik berikut:
- Berisi dan mempertahankan status mentah sumber data dalam format aslinya.
- Ditambahkan secara bertahap dan tumbuh dari waktu ke waktu.
- Dirancang untuk digunakan oleh pekerjaan komputasi yang memperkaya data untuk silver tables, dan tidak untuk akses oleh analis maupun ilmuwan data.
- Berfungsi sebagai sumber kebenaran tunggal, mempertahankan keakuratan data.
- Memungkinkan pemrosesan ulang dan audit dengan menyimpan semua data historis.
- Dapat berupa kombinasi transaksi streaming dan batch dari sumber, termasuk penyimpanan objek cloud (misalnya, S3, GCS, ADLS), bus pesan (misalnya, Kafka, Kinesis, dll.), dan sistem federasi (misalnya, Lakehouse Federation).
Membatasi pembersihan atau validasi data
Validasi data minimal dilakukan di lapisan perunggu. Untuk mencegah hilangnya data, Azure Databricks merekomendasikan menyimpan kebanyakan bidang sebagai string, VARIANT, atau biner untuk perlindungan dari perubahan skema yang tidak terduga. Kolom metadata mungkin ditambahkan, seperti bukti atau sumber data (misalnya, _metadata.file_name ).
Memvalidasi dan mendeduplikasi data di lapisan perak
Pembersihan dan validasi data dilakukan dalam lapisan perak.
Membuat tabel perak dari lapisan perunggu
Untuk membangun lapisan perak, baca data dari satu atau beberapa tabel perunggu atau perak, dan tulis data ke tabel perak.
Azure Databricks tidak merekomendasikan menulis langsung ke tabel silver dari proses pemasukan data. Jika Anda menulis langsung dari pengambilan data, Anda akan menyebabkan kegagalan karena perubahan skema atau data yang rusak di sumber data. Dengan asumsi semua sumber bersifat hanya-tambah, konfigurasikan sebagian besar pembacaan dari bronze sebagai pembacaan streaming. Pembacaan secara batch sebaiknya dicadangkan untuk kumpulan data berukuran kecil (misalnya, tabel dimensi yang kecil).
Lapisan perak mewakili versi data yang divalidasi, dibersihkan, dan diperkaya. Lapisan perak:
- Harus selalu menyertakan setidaknya satu representasi yang divalidasi dan tidak diagregasi dari setiap rekaman. Jika representasi agregat mendorong banyak beban kerja hilir, representasi tersebut mungkin berada di lapisan perak, tetapi biasanya berada di lapisan emas.
- Adalah tempat Anda melakukan pembersihan data, deduplikasi, dan normalisasi.
- Meningkatkan kualitas data dengan memperbaiki kesalahan dan inkonsistensi.
- Menyusun data ke dalam format yang lebih dapat dikonsumsi untuk pemrosesan hilir.
Menegakkan kualitas data
Operasi berikut dilakukan dalam tabel perak:
- Penerapan skema
- Penanganan nilai null dan nilai yang hilang
- Deduplikasi data
- Penyelesaian masalah data yang tidak berurutan dan terlambat tiba
- Pemeriksaan dan penegakan kualitas data
- Evolusi skema
- Pengubahan jenis data
- Penggabungan
Mulai pemodelan data
Adalah umum untuk mulai melakukan pemodelan data di lapisan perak, termasuk memilih cara mewakili data yang sangat berlapis atau semi terstruktur:
- Gunakan
VARIANTjenis data. - Gunakan string-string
JSON. - Buat struktur, peta, dan array.
- Meratakan skema atau menormalkan data ke dalam beberapa tabel.
Analisis tenaga dengan lapisan emas
Lapisan emas mewakili pandangan yang sangat terperinci dari data yang berperan dalam mendorong analitik hilir, dasbor, ML (pembelajaran mesin), dan aplikasi. Data lapisan emas sering kali sangat diagregasi dan difilter untuk periode waktu atau wilayah geografis tertentu. Ini berisi himpunan data yang bermakna secara semantik yang memetakan ke fungsi dan kebutuhan bisnis.
Lapisan emas:
- Terdiri dari data agregat yang disesuaikan untuk analitik dan pelaporan.
- Selaras dengan logika dan persyaratan bisnis.
- Dioptimalkan untuk performa dalam kueri dan dasbor.
Selaras dengan logika dan persyaratan bisnis
Lapisan emas adalah tempat Anda akan memodelkan data untuk pelaporan dan analitik menggunakan model dimensi dengan membangun hubungan dan menentukan langkah-langkah. Analis dengan akses ke data dalam emas harus dapat menemukan data khusus domain dan menjawab pertanyaan.
Karena lapisan emas memodelkan domain bisnis, beberapa pelanggan membuat beberapa lapisan emas untuk memenuhi kebutuhan bisnis yang berbeda, seperti SDM, keuangan, dan IT.
Membuat agregat yang disesuaikan untuk analitik dan pelaporan
Organisasi sering kali perlu membuat fungsi agregat untuk langkah-langkah seperti rata-rata, jumlah, maksimum, dan minimum. Misalnya, jika bisnis Anda perlu menjawab pertanyaan tentang total penjualan mingguan, Anda dapat membuat tampilan materialisasi yang disebut weekly_sales yang telah mengagregasi data ini sehingga analis dan orang lain tidak perlu membuat ulang tampilan materialisasi yang sering digunakan.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimalkan untuk meningkatkan performa dalam kueri dan dasbor
Mengoptimalkan tabel berlapis emas untuk meningkatkan performa adalah praktik terbaik karena himpunan data ini sering diakses. Sejumlah besar data historis biasanya diakses di lapisan sliver dan tidak terwujud dalam lapisan emas.
Mengontrol biaya dengan menyesuaikan frekuensi penyerapan data
Mengontrol biaya dengan menentukan seberapa sering untuk menyerap data.
| Frekuensi penyerapan data | Biaya | Latensi | Contoh deklaratif | Contoh prosedural |
|---|---|---|---|---|
| Pemasukan bertahap berkelanjutan | Lebih tinggi | Lebih rendah |
|
|
| Penyerapan bertahap yang dipicu | Lebih rendah | Lebih tinggi |
|
|
| Pemrosesan batch dengan metode inkremental manual | Lebih rendah | Tertinggi, karena jarang dijalankan. |
|