Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini berisi rekomendasi untuk menerapkan ekspektasi dalam skala besar dan contoh pola lanjutan yang didukung oleh harapan. Pola-pola ini menggunakan beberapa himpunan data bersama dengan harapan dan mengharuskan pengguna memahami sintaks dan semantik tampilan materialisasi, tabel streaming, dan harapan.
Untuk gambaran umum dasar perilaku dan sintaks ekspektasi, lihat Mengelola kualitas data dengan harapan alur.
Harapan portabel dan dapat digunakan kembali
Databricks merekomendasikan praktik terbaik berikut saat menerapkan harapan untuk meningkatkan portabilitas dan mengurangi beban pemeliharaan:
| Recommendation | Dampak |
|---|---|
| Simpan definisi ekspektasi secara terpisah dari logika alur. | Terapkan harapan dengan mudah ke beberapa himpunan data atau alur. Perbarui, audit, dan pertahankan harapan tanpa memodifikasi kode sumber alur. |
| Tambahkan tag kustom untuk membuat grup ekspektasi terkait. | Memfilter ekspektasi berdasarkan tag. |
| Terapkan ekspektasi secara konsisten di seluruh himpunan data serupa. | Gunakan harapan yang sama di beberapa himpunan data dan alur untuk mengevaluasi logika yang identik. |
Contoh berikut menunjukkan menggunakan tabel atau kamus Delta untuk membuat repositori harapan pusat. Fungsi Python kustom kemudian menerapkan harapan ini ke himpunan data dalam contoh alur:
Tabel Delta
Contoh berikut membuat tabel bernama rules untuk mempertahankan aturan:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
Contoh Python berikut menentukan ekspektasi kualitas data berdasarkan aturan dalam rules tabel. Fungsi get_rules() membaca aturan dari tabel rules dan mengembalikan sebuah kamus Python yang berisi aturan yang sesuai dengan argumen tag yang dilewatkan ke fungsi.
Dalam contoh ini, kamus diterapkan menggunakan @dp.expect_all_or_drop() dekorator untuk memberlakukan batasan kualitas data.
Misalnya, rekaman apa pun yang gagal memenuhi aturan dengan tag validity akan dihapus dari tabel raw_farmers_market.
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Modul Python
Contoh berikut membuat modul Python untuk mempertahankan aturan. Untuk contoh ini, simpan kode ini dalam file bernama rules_module.py di folder yang sama dengan buku catatan yang digunakan sebagai kode sumber untuk alur:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
Contoh Python berikut menentukan ekspektasi kualitas data berdasarkan aturan yang rules_module.py ditentukan dalam file. Fungsi get_rules() mengembalikan sebuah kamus Python yang berisi aturan yang cocok dengan argumen tag yang telah diteruskan.
Dalam contoh ini, kamus diterapkan menggunakan @dp.expect_all_or_drop() dekorator untuk memberlakukan batasan kualitas data.
Misalnya, rekaman apa pun yang gagal memenuhi aturan dengan tag validity akan dihapus dari tabel raw_farmers_market.
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Validasi jumlah baris
Contoh berikut memvalidasi kesetaraan jumlah baris antara table_a dan table_b untuk memeriksa bahwa tidak ada data yang hilang selama transformasi:
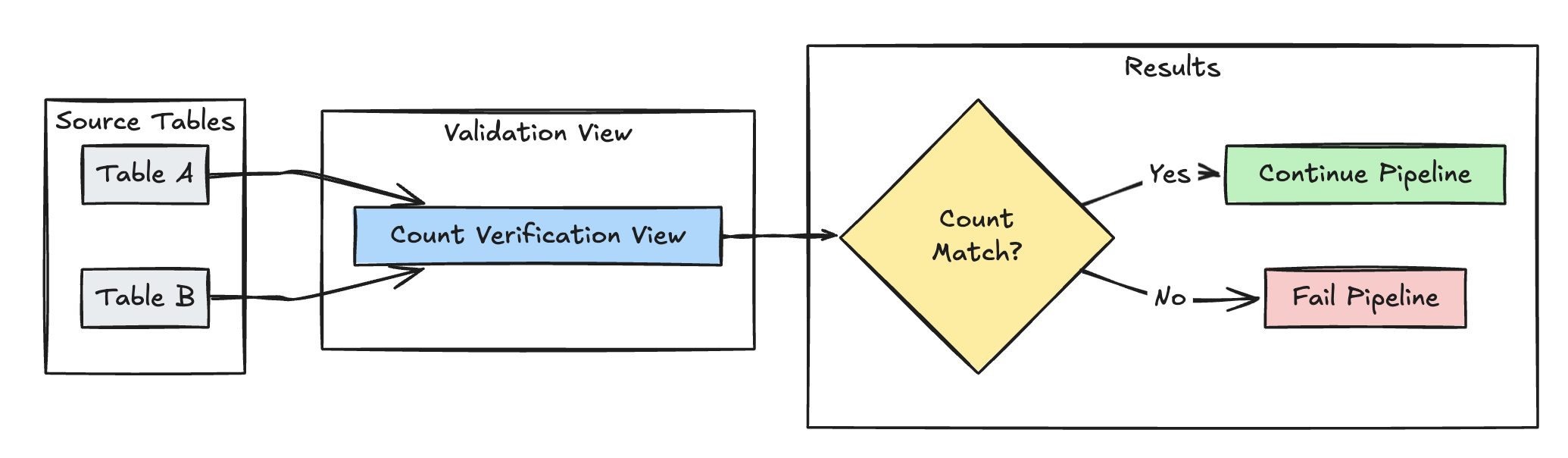
Phyton
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Deteksi catatan yang hilang
Contoh berikut memvalidasi bahwa semua rekaman yang diharapkan ada dalam report tabel:
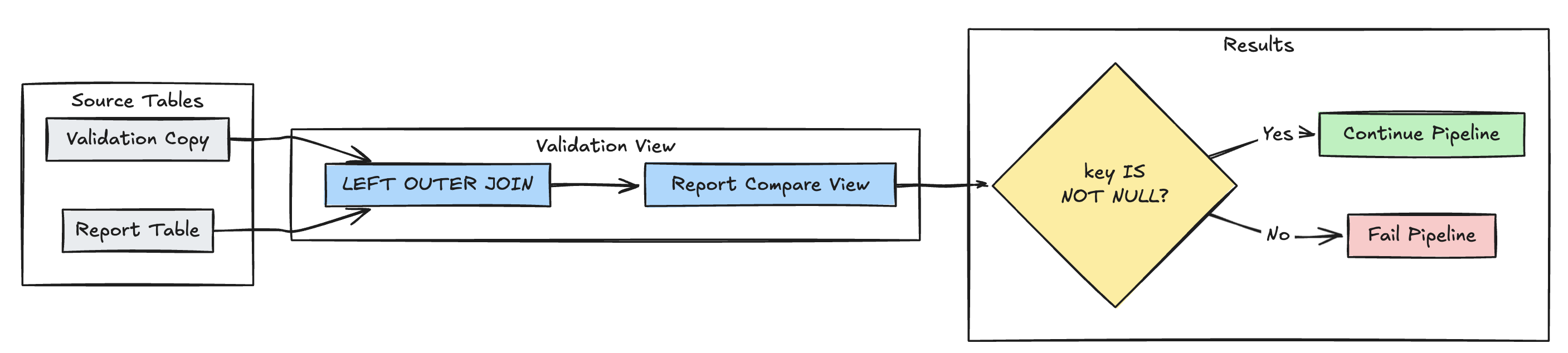
Phyton
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Keunikan kunci utama
Contoh berikut memvalidasi batasan kunci utama di seluruh tabel:
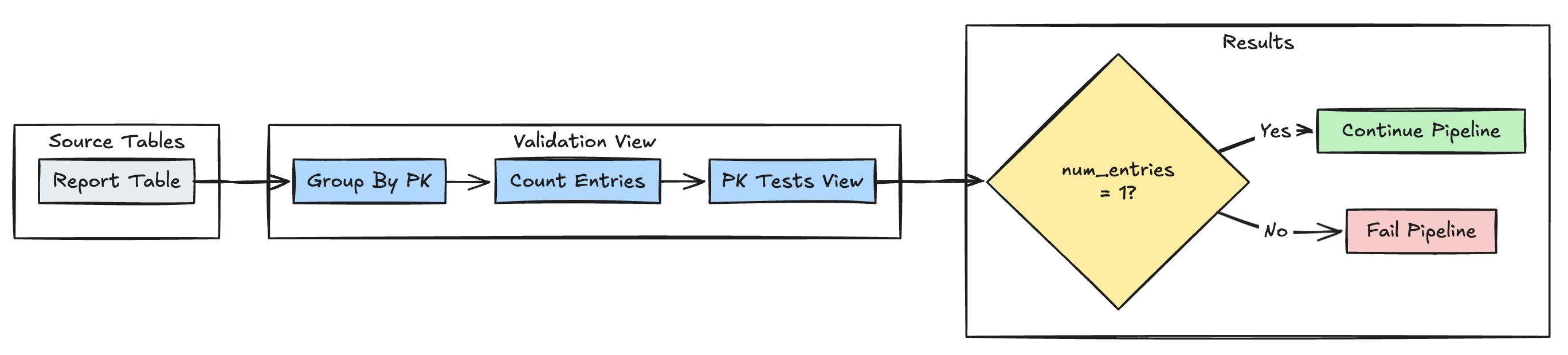
Phyton
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Pola evolusi skema
Contoh berikut menunjukkan cara menangani evolusi skema untuk kolom tambahan. Gunakan pola ini saat Anda memigrasikan sumber data atau menangani beberapa versi data hulu, memastikan kompatibilitas mundur sambil memberlakukan kualitas data:
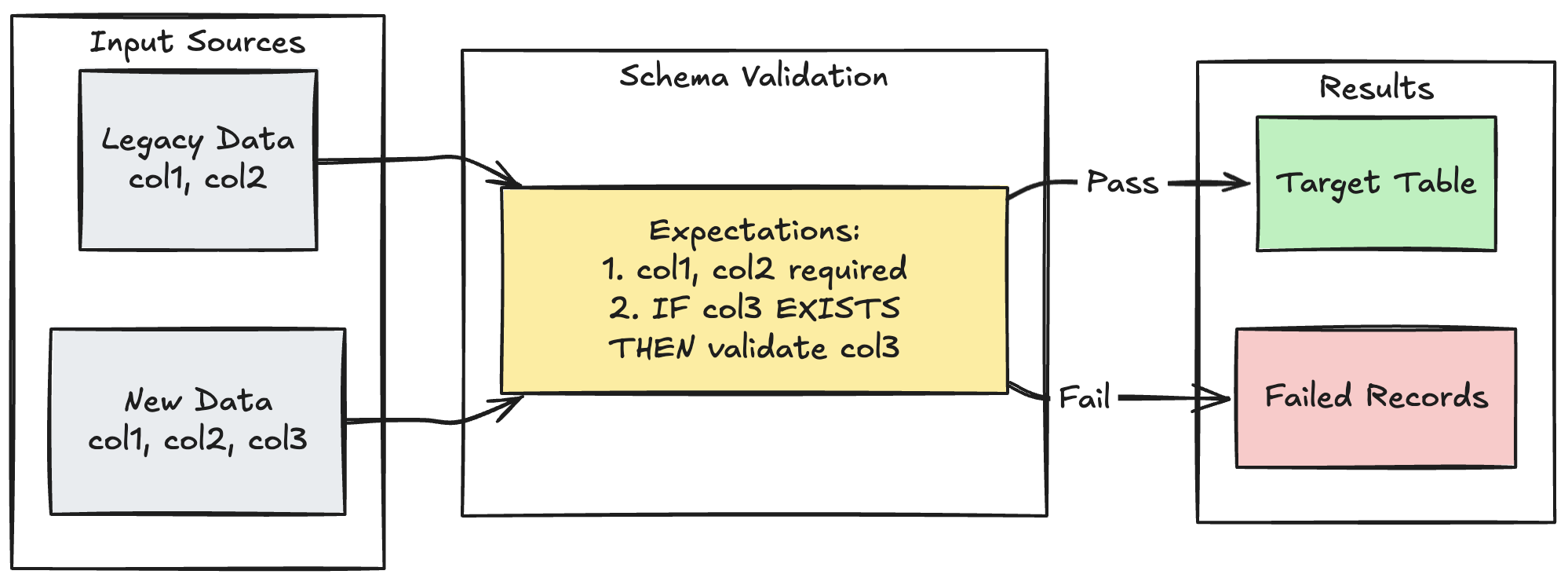
Phyton
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Pola validasi berbasis rentang
Contoh berikut menunjukkan cara memvalidasi poin data baru terhadap rentang statistik historis, membantu mengidentifikasi outlier dan anomali dalam aliran data Anda:
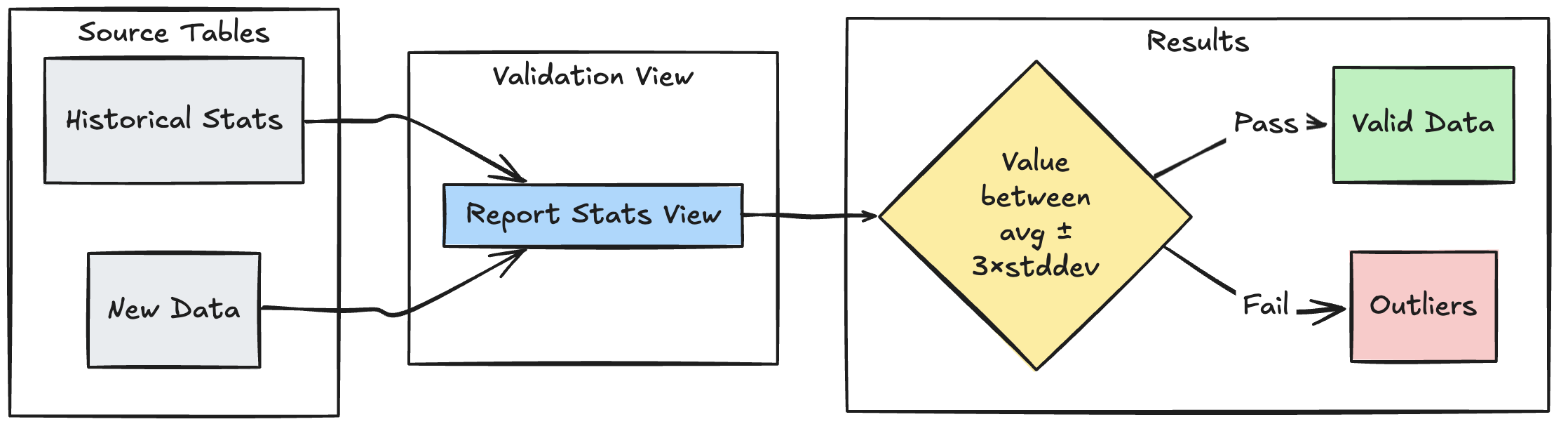
Phyton
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Mengkarantina rekaman yang tidak valid
Pola ini menggabungkan ekspektasi dengan tabel dan tampilan sementara untuk melacak metrik kualitas data selama pembaruan alur dan mengaktifkan jalur pemrosesan terpisah untuk rekaman yang valid dan tidak valid dalam operasi hilir.
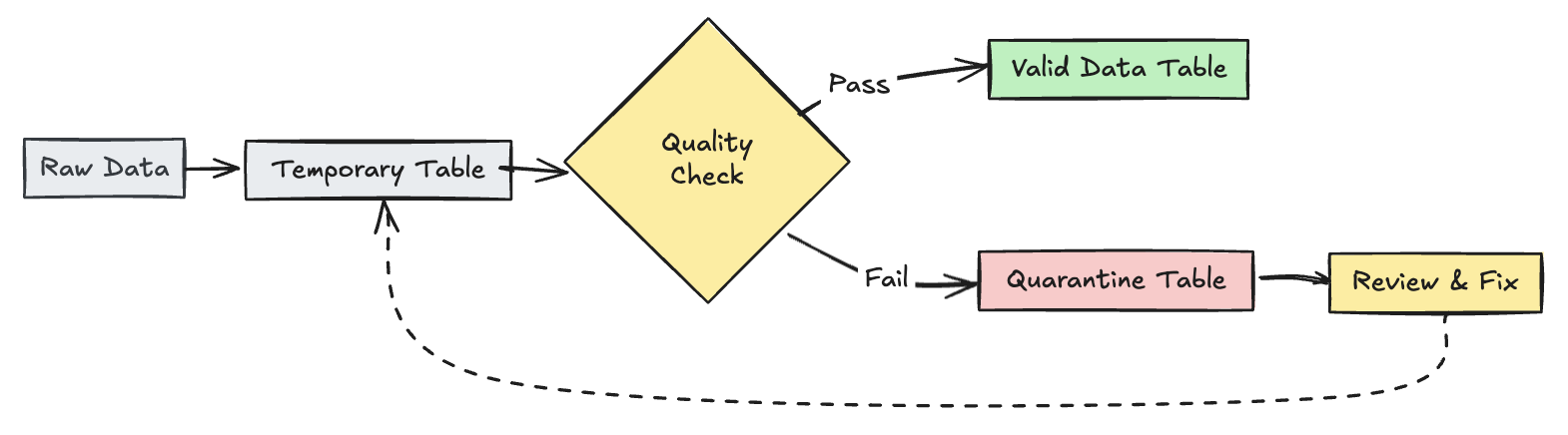
Phyton
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;