Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Anda mendeklarasikan transformasi dalam pipeline untuk menentukan bagaimana record diproses melalui logika kueri, menggunakan pola umum seperti join antara stream dan tabel statis, agregasi inkremental, serta kombinasi tabel streaming dan materialized view.
Anda dapat menentukan himpunan data terhadap kueri apa pun yang mengembalikan DataFrame. Anda dapat menggunakan operasi bawaan Apache Spark, UDF, logika kustom, dan model MLflow sebagai transformasi dalam alur Anda. Setelah data diserap ke dalam alur Anda, Anda dapat menentukan himpunan data baru terhadap sumber upstream untuk membuat tabel streaming baru, tampilan materialisasi, dan tampilan.
Untuk panduan tentang memilih antara tampilan, tampilan materialisasi, dan tabel streaming, lihat Apa itu alur?. Untuk mempelajari cara melakukan pemrosesan stateful secara efektif dalam alur pemrosesan, lihat Mengoptimalkan pemrosesan stateful dengan tanda air.
Mengecualikan tabel dari skema target
Jika Anda harus menghitung tabel perantara yang tidak ditujukan untuk konsumsi eksternal, Anda dapat mencegahnya diterbitkan ke skema menggunakan kata kunci PRIVATE. Tabel privat masih menyimpan dan memproses data sesuai dengan semantik alur tetapi tidak boleh diakses di luar alur saat ini. Tabel privat eksis selama masa hidup dari pipeline yang membuatnya. Gunakan sintaks berikut untuk mendeklarasikan tabel privat:
SQL
CREATE PRIVATE STREAMING TABLE private_table
AS SELECT ... ;
Phyton
@dp.table(
private=True)
def private_table():
return ("...")
Menggabungkan tabel streaming dan tampilan materialisasi dalam satu alur
Tabel streaming mewarisi jaminan pemrosesan dari Apache Spark Structured Streaming dan dikonfigurasi untuk memproses kueri dari sumber data yang hanya menambahkan, di mana baris baru selalu dimasukkan ke dalam tabel sumber daripada dimodifikasi.
Nota
Meskipun secara default, tabel streaming memerlukan sumber data yang hanya dapat ditambahkan, ketika sumber streaming adalah tabel streaming lain yang membutuhkan pembaruan atau penghapusan, Anda dapat mengubah perilaku ini dengan menggunakan flag skipChangeCommits
Pola streaming umum melibatkan memasukkan data sumber untuk membuat himpunan data awal dalam alur kerja. Himpunan data awal ini biasanya disebut tabel perunggu dan sering melakukan transformasi sederhana.
Sebaliknya, tabel akhir dalam pipeline, umumnya disebut sebagai tabel emas, sering memerlukan agregasi yang rumit atau pembacaan dari target operasi AUTO CDC ... INTO. Karena operasi ini secara inheren membuat pembaruan daripada penambahan, mereka tidak didukung sebagai input ke tabel streaming. Transformasi ini lebih cocok untuk pandangan materialisasi.
Dengan mencampur tabel streaming dan tampilan materialisasi ke dalam satu alur, Anda dapat menyederhanakan alur Anda, menghindari penyerapan ulang atau pemrosesan ulang data mentah yang mahal, dan memiliki kekuatan penuh SQL untuk menghitung agregasi kompleks melalui himpunan data yang dikodekan dan difilter secara efisien. Contoh berikut mengilustrasikan jenis pemrosesan campuran ini:
Nota
Contoh-contoh ini menggunakan Auto Loader untuk memuat file dari penyimpanan cloud. Untuk memuat file dengan Auto Loader dalam alur Katalog Unity yang diaktifkan, Anda harus menggunakan lokasi eksternal. Untuk mempelajari selengkapnya tentang menggunakan Katalog Unity dengan alur, lihat Menggunakan Katalog Unity dengan alur.
Phyton
@dp.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dp.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dp.materialized_view
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.read.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM STREAM read_files(
"abfss://path/to/raw/data",
format => "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Pelajari selengkapnya tentang menggunakan Auto Loader untuk menyerap file JSON secara bertahap dari penyimpanan Azure.
Gabungan statis aliran
Penggabungan stream-statis adalah pilihan yang baik saat melakukan denormalisasi aliran data berkelanjutan yang hanya dapat ditambahkan dengan tabel dimensi yang sebagian besar bersifat statis.
Dengan setiap pembaruan alur, rekaman baru dari arus digabungkan dengan cuplikan terbaru dari tabel statis. Jika rekaman ditambahkan atau diperbarui dalam tabel statis setelah data terkait dari tabel streaming diproses, rekaman yang dihasilkan tidak dihitung ulang kecuali refresh penuh dilakukan.
Dalam alur yang dikonfigurasi untuk eksekusi yang dipicu, tabel statis mengembalikan hasil pada saat pembaruan dimulai. Dalam alur yang dikonfigurasi untuk eksekusi berkelanjutan, versi terbaru tabel statis dikueri setiap kali tabel memproses pembaruan.
Berikut ini adalah contoh penggabungan aliran dengan data statis:
Phyton
@dp.table
def customer_sales():
return spark.readStream.table("sales").join(spark.read.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Menghitung agregat secara efisien
Anda dapat menggunakan tabel streaming untuk menghitung agregat distributif sederhana secara bertahap seperti jumlah, min, maks, atau jumlah, dan agregat aljabar seperti rata-rata atau simpangan baku. Databricks merekomendasikan agregasi bertahap untuk kueri dengan jumlah grup terbatas, seperti kueri dengan klausa GROUP BY country. Hanya data input baru yang dibaca dengan setiap pembaruan.
Untuk mempelajari lebih lanjut tentang cara menulis kueri pipeline yang menjalankan agregasi inkremental, lihat Menjalankan agregasi berbasis jendela dengan watermark.
Gunakan model MLflow dalam pipeline
Nota
Untuk menggunakan model MLflow dalam alur yang mendukung Katalog Unity, alur Anda harus dikonfigurasi untuk menggunakan saluran preview. Untuk menggunakan saluran current, Anda harus mengonfigurasi alur Anda untuk menerbitkan ke metastore Hive.
Anda dapat menggunakan model yang dilatih dengan MLflow dalam pipeline. Model MLflow diperlakukan sebagai transformasi di Azure Databricks, yang berarti model tersebut bertindak berdasarkan input Spark DataFrame dan mengembalikan hasil sebagai Spark DataFrame. Karena alur menentukan himpunan data terhadap DataFrames, Anda dapat mengonversi beban kerja Apache Spark yang menggunakan MLflow menjadi alur hanya dengan beberapa baris kode. Untuk informasi selengkapnya tentang MLflow, lihat MLflow di Databricks.
Jika Anda sudah memiliki skrip Python yang memanggil model MLflow, Anda dapat mengadaptasi kode ini ke alur dengan menggunakan @dp.table atau @dp.materialized_view dekorator dan memastikan fungsi didefinisikan untuk mengembalikan hasil transformasi. Pipeline tidak menginstal MLflow secara bawaan, jadi pastikan bahwa Anda telah menginstal pustaka MLflow dengan %pip install mlflow dan telah mengimpor mlflow dan dp di bagian atas kode sumber Anda. Untuk pengenalan sintaks alur, lihat Mengembangkan kode alur dengan Python.
Untuk menggunakan model MLflow dalam alur, selesaikan langkah-langkah berikut:
- Dapatkan run ID dan nama model MLflow. ID eksekusi dan nama model digunakan untuk membangun URI model MLflow.
- Gunakan URI untuk menentukan Spark UDF untuk memuat model MLflow.
- Panggil UDF dalam definisi tabel Anda untuk menggunakan model MLflow.
Contoh berikut menunjukkan sintaks dasar untuk pola ini:
%pip install mlflow==2.20.2
from pyspark import pipelines as dp
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dp.materialized_view
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Sebagai contoh lengkap, kode berikut mendefinisikan Spark UDF bernama loaded_model_udf yang memuat model MLflow yang dilatih pada data risiko pinjaman. Kolom data yang digunakan untuk membuat prediksi diteruskan sebagai argumen ke UDF. Tabel loan_risk_predictions menghitung prediksi untuk setiap baris dalam loan_risk_input_data.
%pip install mlflow==2.20.2
from pyspark import pipelines as dp
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dp.materialized_view(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Pertahankan penghapusan atau pembaruan manual
Alur memungkinkan Anda menghapus atau memperbarui rekaman secara manual dari tabel dan melakukan operasi refresh untuk mengolah ulang tabel hilir.
Secara default, alur mengolah ulang hasil tabel berdasarkan data input setiap kali diperbarui, jadi Anda harus memastikan rekaman yang dihapus tidak dimuat ulang dari data sumber. Mengatur properti tabel pipelines.reset.allowed ke false mencegah refresh ke tabel tetapi tidak mencegah penulisan bertahap ke tabel atau data baru mengalir ke tabel.
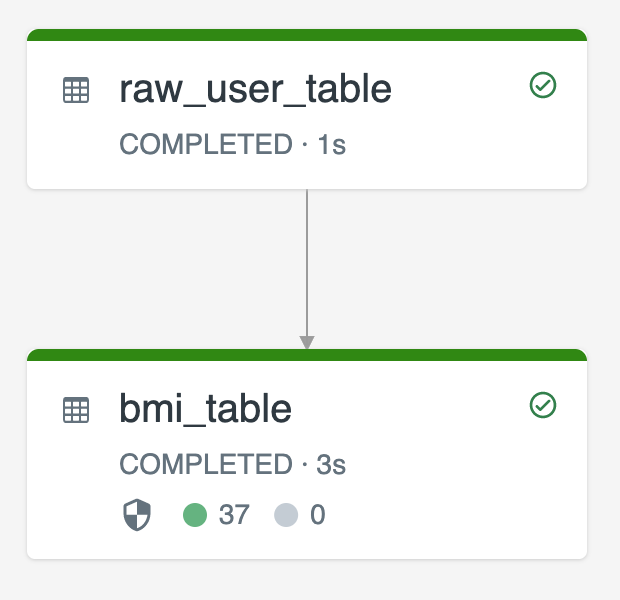
Diagram berikut mengilustrasikan contoh menggunakan dua tabel streaming:
-
raw_user_tablemenyerap data pengguna mentah dari sumber. -
bmi_tablemenghitung skor BMI secara bertahap menggunakan berat dan tinggi dariraw_user_table.
Anda ingin menghapus atau memperbarui catatan pengguna secara manual dari raw_user_table dan menghitung ulang bmi_table.
Kode berikut menunjukkan pengaturan properti tabel pipelines.reset.allowed ke false untuk menonaktifkan refresh penuh untuk raw_user_table sehingga perubahan yang dimaksudkan dipertahankan dari waktu ke waktu, tetapi tabel hilir dikomputasi ulang saat pembaruan alur dijalankan:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM STREAM read_files("/databricks-datasets/iot-stream/data-user", format => "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);