Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Gunakan AutoML untuk menemukan algoritma regresi dan konfigurasi hiperparameter terbaik secara otomatis untuk memprediksi nilai numerik berkelanjutan.
Menyiapkan eksperimen regresi dengan UI
Anda dapat menyiapkan masalah regresi menggunakan UI AutoML dengan langkah-langkah berikut:
Di bar samping, pilih Eksperimen.
Di kartu Regresi, pilih Mulai pelatihan.
Halaman konfigurasikan eksperimen AutoML ditampilkan. Pada halaman ini, Anda mengonfigurasi proses AutoML, menentukan himpunan data, jenis masalah, target atau kolom label untuk diprediksi, metrik yang digunakan untuk mengevaluasi dan menilai eksekusi eksperimen, dan menghentikan kondisi.
Di bidang Komputasi, pilih kluster yang menjalankan Databricks Runtime ML.
Di bawah Himpunan Data, pilih Telusuri.
Navigasi ke tabel yang ingin Anda gunakan dan klik Pilih. Skema tabel muncul.
- Di Databricks Runtime 10.3 ML ke atas, Anda dapat menentukan kolom mana yang harus digunakan AutoML untuk pelatihan. Anda tidak dapat menghapus kolom yang dipilih sebagai target prediksi atau kolom waktu untuk memisahkan data.
- Dalam Databricks Runtime 10.4 LTS ML ke atas, Anda dapat menentukan bagaimana nilai null diimutkan dengan memilih dari Impute dengan dropdown. Secara default, AutoML memilih metode imputasi berdasarkan jenis kolom dan konten.
Catatan
Jika Anda menetapkan metode imputasi non-default, AutoML tidak melakukan deteksi jenis semantik.
Klik di bidang Target prediksi. Drop-down muncul dengan mencantumkan kolom yang ditampilkan dalam skema. Pilih kolom yang Anda inginkan untuk diprediksi oleh model.
Bidang Nama eksperimen menunjukkan nama default. Untuk mengubahnya, ketik nama baru di bidang.
Anda juga dapat:
- Tentukan opsi konfigurasi tambahan.
- Gunakan tabel fitur yang ada di Penyimpanan Fitur untuk menambah himpunan data input asli.
Konfigurasi tingkat lanjut
Buka bagian Konfigurasi Lanjutan (opsional) untuk mengakses parameter ini.
- Metrik evaluasi adalah metrik utama yang digunakan untuk mencetak eksekusi alur.
- Dalam Databricks Runtime 10.4 LTS ML ke atas, Anda dapat mengecualikan kerangka kerja pelatihan dari pertimbangan. Secara default, AutoML melatih model menggunakan kerangka kerja yang tercantum di bawah algoritma AutoML.
- Anda dapat mengedit kondisi berhenti. Kondisi penghentian default adalah:
- Untuk perkiraan eksperimen, berhenti setelah 120 menit.
- Dalam Databricks Runtime 10.4 LTS ML ke bawah, untuk eksperimen klasifikasi dan regresi, hentikan setelah 60 menit atau setelah menyelesaikan 200 uji coba, mana pun yang terjadi terlebih dahulu. Untuk Databricks Runtime 11.0 ML ke atas, jumlah uji coba tidak akan digunakan sebagai syarat untuk berhenti.
- Dalam Databricks Runtime 10.4 LTS ML ke atas, untuk eksperimen klasifikasi dan regresi, AutoML menggabungkan penghentian awal; ini menghentikan pelatihan dan penyetelan model jika metrik validasi tidak lagi membaik.
- Dalam Databricks Runtime 10.4 LTS ML ke atas, Anda dapat memilih
time columnuntuk membagi data untuk pelatihan, validasi, dan pengujian dalam urutan kronologis (hanya berlaku untuk klasifikasi dan regresi). - Databricks merekomendasikan untuk tidak mengisi bidang Direktori data. Melakukannya memicu perilaku default menyimpan himpunan data dengan aman sebagai artefak MLflow. Jalur DBFS dapat ditentukan, tetapi dalam hal ini, himpunan data tidak mewarisi izin akses eksperimen AutoML.
Menjalankan eksperimen dan memeriksa hasilnya
Untuk memulai eksperimen AutoML, klik Mulai AutoML. Eksperimen mulai berjalan, dan halaman pelatihan AutoML muncul. Untuk merefresh tabel eksekusi, klik  .
.
Lihat kemajuan eksperimen
Dari halaman ini, Anda dapat:
- Hentikan eksperimen kapan saja.
- Buka notebook eksplorasi data.
- Monitor berjalan.
- Navigasikan ke halaman jalankan untuk menjalankan apa pun.
Dengan Databricks Runtime 10.1 ML dan yang lebih baru, AutoML menampilkan peringatan untuk potensi masalah dengan himpunan data, seperti jenis kolom yang tidak didukung atau kolom kardinalitas tinggi.
Catatan
Databricks melakukan yang terbaik untuk menunjukkan potensi kesalahan atau masalah. Namun, ini mungkin tidak komprehensif dan mungkin tidak menangkap masalah atau kesalahan yang mungkin Anda cari.
Untuk melihat peringatan untuk himpunan data, klik tab Peringatan di halaman pelatihan atau halaman eksperimen setelah eksperimen selesai.
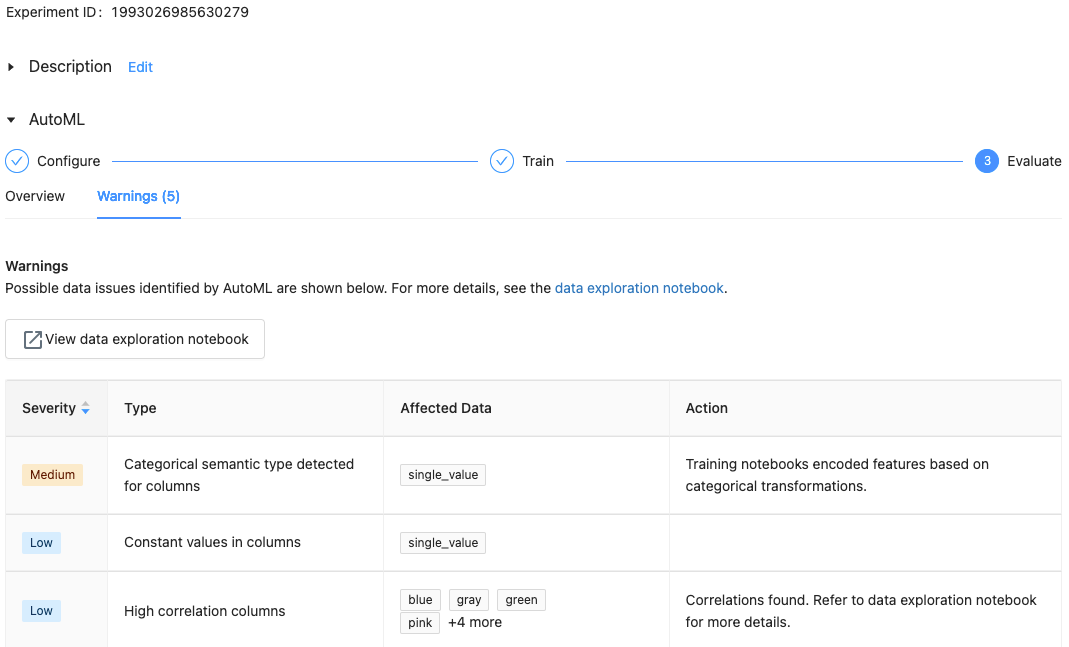
Melihat hasil
Ketika percobaan selesai, Anda dapat:
- Daftar dan sebarkan salah satu model dengan MLflow.
- Pilih Tampilkan buku catatan untuk model terbaik untuk meninjau dan mengedit buku catatan yang membuat model terbaik.
- Pilih Tampilkan buku catatan eksplorasi data untuk membuka buku catatan eksplorasi data.
- Cari, filter, dan urutkan eksekusi alur di tabel berjalan.
- Lihat detail untuk eksekusi apa pun:
- Buku catatan yang dihasilkan yang berisi kode sumber untuk uji coba dapat ditemukan dengan mengklik eksekusi MLflow. Buku catatan disimpan di bagian Artefak dari halaman eksekusi. Anda dapat mengunduh buku catatan ini dan mengimpornya ke ruang kerja, jika mengunduh artefak diaktifkan oleh administrator ruang kerja Anda.
- Untuk menampilkan hasil eksekusi, klik di kolom Model atau kolom Waktu Mulai. Halaman eksekusi muncul, memperlihatkan informasi tentang eksekusi uji coba (seperti parameter, metrik, dan tag) dan artefak yang dibuat oleh eksekusi, termasuk model. Halaman ini juga menyertakan cuplikan kode yang dapat Anda gunakan untuk membuat prediksi dengan model.
Untuk kembali ke eksperimen AutoML ini nanti, temukan di tabel di halaman Eksperimen. Hasil setiap eksperimen AutoML, termasuk notebook eksplorasi dan pelatihan data, disimpan dalam databricks_automl folder di rumah folder pengguna yang menjalankan eksperimen.
Mendaftarkan dan menyebarkan model
Anda dapat mendaftarkan dan menyebarkan model Anda dengan UI AutoML:
- Pilih tautan di kolom Model untuk model yang akan didaftarkan. Ketika eksekusi selesai, baris atas adalah model terbaik (berdasarkan metrik utama).
- Pilih
 untuk mendaftarkan model di Registri Model.
untuk mendaftarkan model di Registri Model. - Pilih
 Model di bar samping untuk menavigasi ke Registri Model.
Model di bar samping untuk menavigasi ke Registri Model. - Pilih nama model Anda dalam tabel model.
- Dari halaman model terdaftar, Anda dapat melayani model dengan Model Serving.
Tidak ada modul bernama 'pandas.core.indexes.numeric
Saat melayani model yang dibangun menggunakan AutoML dengan Model Serving, Anda mungkin mendapatkan kesalahan: No module named 'pandas.core.indexes.numeric.
Hal ini disebabkan oleh versi yang tidak kompatibel pandas antara AutoML dan model yang melayani lingkungan titik akhir. Anda dapat mengatasi kesalahan ini dengan menjalankan skrip add-pandas-dependency.py. Skrip mengedit requirements.txt dan conda.yaml untuk model yang dicatat untuk menyertakan versi dependensi yang sesuai pandas : pandas==1.5.3
- Ubah skrip untuk menyertakan
run_ideksekusi MLflow tempat model Anda dicatat. - Mendaftarkan ulang model ke registri model MLflow.
- Coba sajikan versi baru model MLflow.