API Model Fondasi throughput yang disediakan
Artikel ini menunjukkan cara menyebarkan model menggunakan API Model Foundation dengan throughput yang disediakan. Databricks merekomendasikan throughput yang disediakan untuk beban kerja produksi, dan memberikan inferensi yang dioptimalkan untuk model fondasi dengan jaminan performa.
Lihat API Model Foundation throughput yang disediakan untuk daftar arsitektur model yang didukung.
Persyaratan
Lihat persyaratan.
Untuk menyebarkan model fondasi yang disempurnakan,
- Model Anda harus dicatat menggunakan MLflow 2.11 atau lebih tinggi, ATAU Databricks Runtime 15.0 ML atau lebih tinggi.
- Databricks merekomendasikan penggunaan model di Unity Catalog untuk mengunggah dan mengunduh model besar yang lebih cepat.
[Disarankan] Menyebarkan model fondasi dari Unity Catalog
Penting
Fitur ini ada di Pratinjau Publik.
Databricks merekomendasikan penggunaan model fondasi yang telah diinstal sebelumnya di Unity Catalog. Anda dapat menemukan model ini di bawah katalog system dalam skema ai (system.ai).
Untuk menyebarkan model fondasi:
- Navigasikan ke
system.aidi Catalog Explorer. - Klik nama model yang akan disebarkan.
- Pada halaman model, klik tombol Layani model ini.
- Halaman Buat titik akhir penyajian muncul. Lihat Membuat titik akhir throughput yang disediakan menggunakan UI.
Menyebarkan model fondasi dari Databricks Marketplace
Atau, Anda dapat menginstal model fondasi ke Unity Catalog dari Databricks Marketplace.
Anda dapat mencari keluarga model dan dari halaman model, Anda dapat memilih Dapatkan akses dan memberikan kredensial masuk untuk menginstal model ke Unity Catalog.
Setelah model diinstal ke Unity Catalog, Anda dapat membuat model yang melayani titik akhir menggunakan Antarmuka Pengguna penyajian.
Menyebarkan model DBRX
Databricks merekomendasikan untuk melayani model Instruksi DBRX untuk beban kerja Anda. Untuk melayani model DBRX Instruct menggunakan throughput yang disediakan, ikuti panduan dalam [Disarankan] Menyebarkan model fondasi dari Unity Catalog.
Saat melayani model DBRX ini, throughput yang disediakan mendukung panjang konteks hingga 16k.
Model DBRX menggunakan perintah sistem default berikut untuk memastikan relevansi dan akurasi dalam respons model:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Mencatat model fondasi yang disempurnakan
Jika Anda tidak dapat menggunakan model dalam system.ai skema atau menginstal model dari Databricks Marketplace, Anda dapat menyebarkan model fondasi yang disempurnakan dengan mencatatnya ke Unity Catalog. Berikut ini memperlihatkan cara menyiapkan kode Anda untuk mencatat model MLflow ke Unity Catalog:
mlflow.set_registry_uri('databricks-uc')
CATALOG = "ml"
SCHEMA = "llm-catalog"
MODEL_NAME = "mpt" # or "bge"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Anda dapat mencatat model Anda menggunakan ragam MLflow transformers dan menentukan argumen tugas dengan antarmuka jenis model yang sesuai dari opsi berikut:
task="llm/v1/completions"task="llm/v1/chat"task="llm/v1/embeddings"
Argumen ini menentukan tanda tangan API yang digunakan untuk model yang melayani titik akhir, dan model yang dicatat dengan cara ini memenuhi syarat untuk throughput yang disediakan.
Model yang dicatat dari sentence_transformers paket juga mendukung menentukan "llm/v1/embeddings" jenis titik akhir.
Untuk model yang dicatat menggunakan MLflow 2.12 atau lebih tinggi, log_model argumen task mengatur metadatatask nilai kunci secara otomatis. task Jika argumen dan metadatatask argumen diatur ke nilai yang berbeda, maka Exception akan dimunculkan.
Berikut ini adalah contoh cara mencatat model bahasa penyelesaian teks yang dicatat menggunakan MLflow 2.12 atau lebih tinggi:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
registered_model_name=registered_model_name
)
Untuk model yang dicatat menggunakan MLflow 2.11 atau lebih tinggi, Anda dapat menentukan antarmuka untuk titik akhir menggunakan nilai metadata berikut:
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Berikut ini adalah contoh cara mencatat model bahasa penyelesaian teks yang dicatat menggunakan MLflow 2.11 atau lebih tinggi:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
metadata={"task": "llm/v1/completions"},
registered_model_name=registered_model_name
)
Throughput yang disediakan juga mendukung model penyematan BGE kecil dan besar. Berikut ini adalah contoh cara mencatat model, BAAI/bge-small-en-v1.5 sehingga dapat dilayani dengan throughput yang disediakan menggunakan MLflow 2.11 atau lebih tinggi:
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-small-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="bge-small-transformers",
task="llm/v1/embeddings",
metadata={"task": "llm/v1/embeddings"}, # not needed for MLflow >=2.12.1
registered_model_name=registered_model_name
)
Saat mencatat model BGE yang disempurnakan, Anda juga harus menentukan model_type kunci metadata:
metadata={
"task": "llm/v1/embeddings",
"model_type": "bge-large" # Or "bge-small"
}
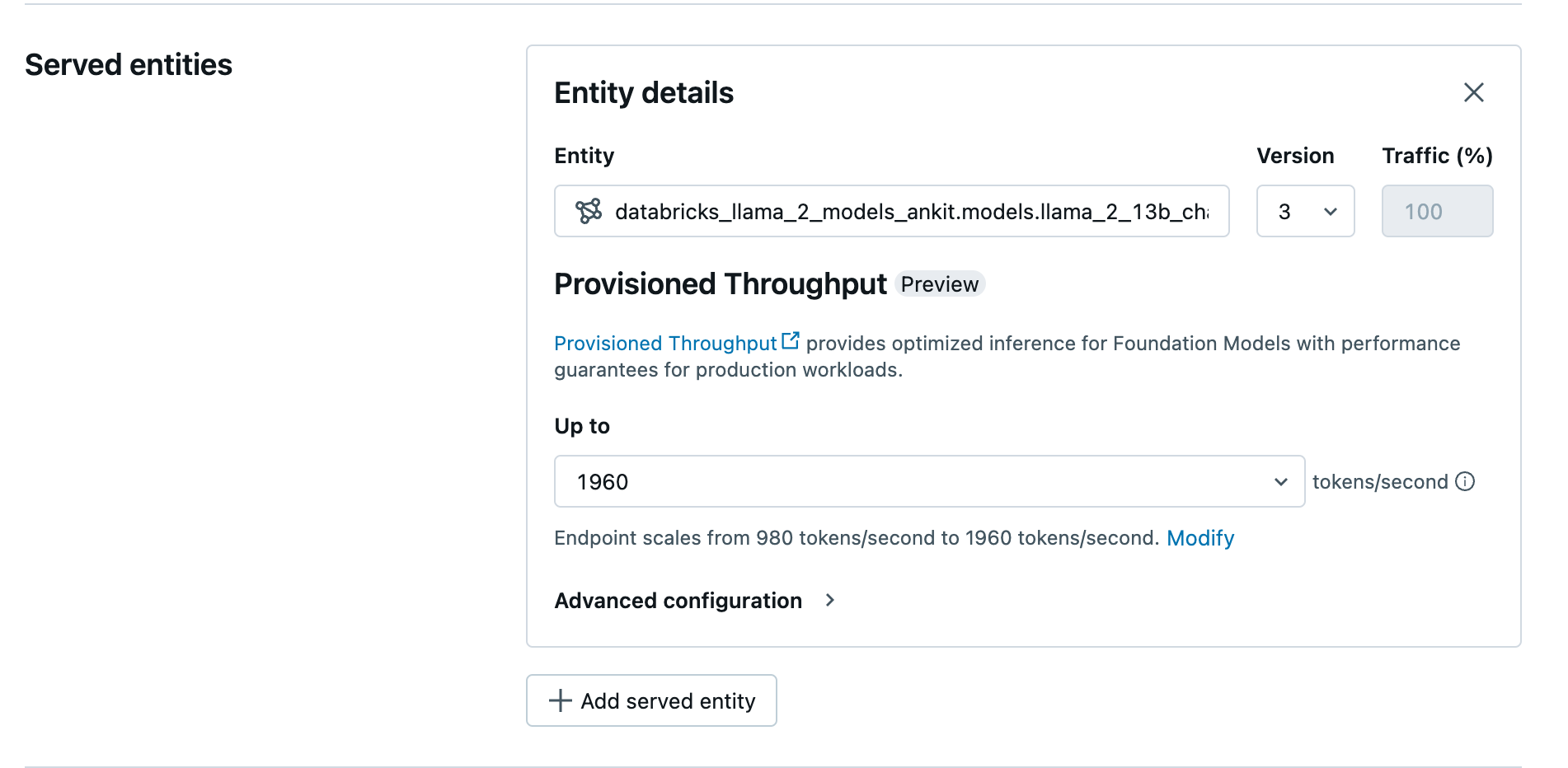
Membuat titik akhir throughput yang disediakan menggunakan UI
Setelah model yang dicatat berada di Unity Catalog, buat titik akhir penyajian throughput yang disediakan dengan langkah-langkah berikut:
- Navigasi ke Antarmuka pengguna Penyajian di ruang kerja Anda.
- Pilih Buat titik akhir penyajian.
- Di bidang Entitas, pilih model Anda dari Katalog Unity. Untuk model yang memenuhi syarat, UI untuk Entitas yang Dilayani menunjukkan layar Throughput yang Disediakan.
- Di menu dropdown Hingga, Anda dapat mengonfigurasi token maksimum per throughput detik untuk titik akhir Anda.
- Titik akhir throughput yang disediakan secara otomatis diskalakan, sehingga Anda dapat memilih Ubah untuk melihat token minimum per detik tempat titik akhir Anda dapat menurunkan skala.
Membuat titik akhir throughput yang disediakan menggunakan REST API
Untuk menyebarkan model Anda dalam mode throughput yang disediakan menggunakan REST API, Anda harus menentukan min_provisioned_throughput bidang dan max_provisioned_throughput dalam permintaan Anda.
Untuk mengidentifikasi rentang throughput yang disediakan yang sesuai untuk model Anda, lihat Mendapatkan throughput yang disediakan dalam kenaikan.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Dapatkan throughput yang disediakan dalam kenaikan
Throughput yang disediakan tersedia dalam kenaikan token per detik dengan kenaikan tertentu yang bervariasi menurut model. Untuk mengidentifikasi rentang yang sesuai untuk kebutuhan Anda, Databricks merekomendasikan penggunaan API informasi pengoptimalan model dalam platform.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Berikut ini adalah contoh respons dari API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Contoh buku catatan
Notebook berikut menunjukkan contoh cara membuat API Model Foundation throughput yang disediakan:
Throughput yang disediakan berfungsi untuk notebook model Llama2
Layanan throughput yang disediakan untuk buku catatan model Mistral
Layanan throughput yang disediakan untuk notebook model BGE
Batasan
- Penyebaran model mungkin gagal karena masalah kapasitas GPU, yang mengakibatkan waktu habis selama pembuatan atau pembaruan titik akhir. Hubungi tim akun Databricks Anda untuk membantu mengatasinya.
- Penskalaan otomatis untuk API Model Foundation lebih lambat daripada penyajian model CPU. Databricks merekomendasikan provisi berlebihan untuk menghindari batas waktu permintaan.
Sumber Daya Tambahan:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk