Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Fitur ini ada di Pratinjau Publik.
Artikel ini memperlihatkan kepada Anda cara menjalankan eksperimen prakiraan tanpa server menggunakan UI Pelatihan Model Mosaic AI.
Pelatihan Model AI Mosaik - prakiraan menyederhanakan prakiraan data rangkaian waktu dengan secara otomatis memilih algoritma dan hiperparameter terbaik, sekaligus berjalan pada sumber daya komputasi yang dikelola sepenuhnya.
Untuk memahami perbedaan antara prakiraan tanpa server dan prakiraan komputasi klasik, lihat Prakiraan tanpa server vs. prakiraan komputasi klasik.
Persyaratan
- Data pelatihan dengan kolom rangkaian waktu, disimpan sebagai tabel Katalog Unity.
- Jika Secure Egress Gateway (SEG) diaktifkan pada ruang kerja,
pypi.orgharus ditambahkan ke daftar domain yang diizinkan. Lihat Mengelola kebijakan jaringan untuk kontrol keluar tanpa server.
Membuat eksperimen prakiraan dengan UI
Buka halaman arahan Azure Databricks Anda dan klik eksperimen di bar samping.
Di ubin Prakiraan, pilih Mulai pelatihan.
Pilih data pelatihan dari daftar tabel Katalog Unity yang bisa Anda akses.
-
Kolom waktu: Pilih kolom yang berisi periode waktu untuk rangkaian waktu. Kolom harus berjenis
timestampataudate. - Frekuensi prakiraan: Pilih unit waktu yang mewakili frekuensi data input Anda. Misalnya, menit, jam, hari, bulan. Ini menentukan granularitas rangkaian waktu Anda.
- Horison Prakiraan: Tentukan berapa banyak unit dari frekuensi yang dipilih untuk diramalkan ke masa depan. Bersama dengan frekuensi prakiraan, ini mendefinisikan unit waktu dan jumlah unit waktu yang akan diprakirakan.
Nota
Untuk menggunakan algoritma
Auto-ARIMA, rangkaian waktu harus memiliki frekuensi reguler di mana interval antara dua titik harus sama di seluruh rangkaian waktu. AutoML menangani langkah-langkah waktu yang hilang dengan mengisi nilai-nilai tersebut dengan nilai sebelumnya. -
Kolom waktu: Pilih kolom yang berisi periode waktu untuk rangkaian waktu. Kolom harus berjenis
Pilih kolom target prediksi yang Anda inginkan untuk diprediksi model.
Secara opsional, tentukan tabel Unity Catalog jalur data Prediksi untuk menyimpan perkiraan output.
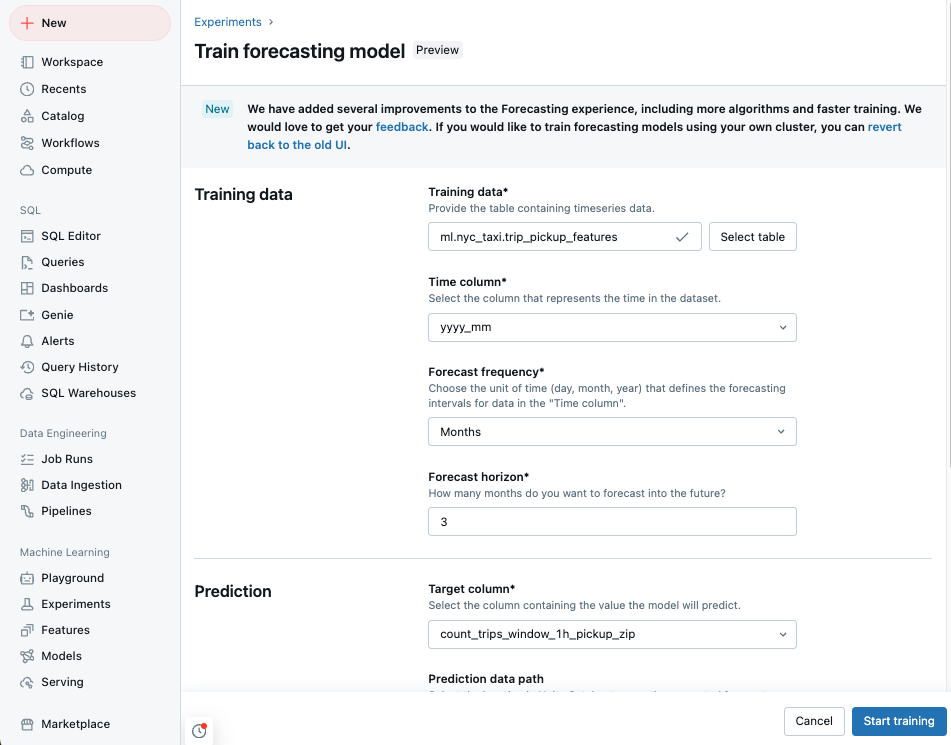
Pilih lokasi dan nama Katalog Unity untuk pendaftaran model.
Secara opsional, atur opsi Tingkat Lanjut :
- Nama eksperimen: Berikan nama eksperimen MLflow.
- Kolom pengidentifikasi rangkaian waktu - Untuk prakiraan multi-seri, pilih kolom yang mengidentifikasi rangkaian waktu individual. Databricks mengelompokkan data menurut kolom ini sebagai rangkaian waktu yang berbeda dan melatih model untuk setiap seri secara independen.
- Metrik utama: Pilih metrik utama yang digunakan untuk mengevaluasi dan memilih model terbaik.
- Kerangka kerja pelatihan: Pilih kerangka kerja untuk dijelajahi AutoML.
- Pisahkan kolom: Pilih kolom yang berisi pemisahan data kustom. Nilai harus "train" (latih), "validate" (validasi), "test" (uji)
- kolom Bobot: Tentukan kolom yang akan digunakan untuk rangkaian waktu pembobotan. Semua sampel untuk rangkaian waktu tertentu harus memiliki bobot yang sama. Berat harus dalam kisaran [0, 10000].
- Wilayah liburan: Pilih wilayah liburan untuk digunakan sebagai kovariate dalam pelatihan model.
- Batas Waktu: Atur durasi maksimum untuk eksperimen AutoML.
Jalankan eksperimen dan pantau hasilnya
Untuk memulai eksperimen AutoML, klik Mulai pelatihan. Dari halaman pelatihan eksperimen, Anda dapat melakukan hal berikut:
- Hentikan eksperimen kapan saja.
- Monitor beroperasi.
- Navigasikan ke halaman eksekusi untuk setiap proses.
Selain itu, Anda dapat memeriksa status eksperimen saat melalui tahapan berikut:
- Preprocessing: Validasi dan siapkan tabel input dengan mengimputasi nilai yang hilang dan memisahkan data menjadi pelatihan, validasi, dan data pengujian. Pemrosesan pembuatan fitur otomatis, seperti pengkodean satu-nol untuk fitur kategoris, juga terjadi selama tahap ini.
- Tuning: Jelajahi algoritma prakiraan yang berbeda dan setel hiperparameter.
- Pelatihan: Latih dan evaluasi model akhir dengan konfigurasi terbaik yang dipilih. Daftarkan model di Katalog Unity jika jalur ditentukan.
Melihat hasil atau menggunakan model terbaik
Setelah pelatihan selesai, hasil prediksi disimpan dalam tabel Delta tertentu dan model terbaik didaftarkan ke Unity Catalog.
Dari halaman eksperimen, Anda memilih dari langkah-langkah berikutnya berikut:
- Pilih Tampilkan prediksi untuk melihat tabel hasil prakiraan.
- Pilih notebook inferensi Batch untuk membuka notebook yang dibuat secara otomatis untuk inferensi batch menggunakan model terbaik.
- Pilih Buat titik akhir penyajian untuk menyebarkan model terbaik ke titik akhir Model Serving.
Prakiraan tanpa server vs. prakiraan komputasi klasik
Tabel berikut ini meringkas perbedaan antara prakiraan tanpa server dan prakiraan dengan komputasi klasik
| Fitur | Prakiraan tanpa server | Prakiraan komputasi klasik |
|---|---|---|
| Infrastruktur komputasi | Azure Databricks mengelola konfigurasi komputasi dan secara otomatis mengoptimalkan biaya dan performa. | Komputasi yang dikonfigurasi pengguna |
| Pemerintahan | Model dan artefak yang terdaftar ke Unity Catalog | Penyimpanan file ruang kerja yang dikonfigurasi pengguna |
| Pilihan algoritma | Model statistik ditambah algoritma jaring neural pembelajaran mendalam DeepAR | Model statistik |
| Integrasi penyimpanan fitur | Tidak didukung | Dukungan |
| Notebook yang dibuat secara otomatis | Notebook inferensi batch | Kode sumber untuk semua percobaan |
| Penerapan model sekali klik | Didukung | Tidak didukung |
| Pemisahan pelatihan/validasi/pengujian kustom | Didukung | Tidak didukung |
| Bobot kustom untuk rangkaian waktu individual | Didukung | Tidak didukung |