Pencatatan Otomatis Databricks
Pencatatan Otomatis Databricks adalah solusi tanpa kode yang memperluas pencatatan otomatis MLflow untuk memberikan pelacakan eksperimen otomatis untuk sesi pelatihan pembelajaran mesin di Azure Databricks.
Dengan Pencatatan Otomatis Databricks, parameter model, metrik, file, dan informasi garis keturunan secara otomatis ditangkap saat Anda melatih model dari berbagai pustaka pembelajaran mesin populer. Sesi pelatihan dicatat sebagai eksekusi pelacakan MLflow. File model juga dilacak sehingga Anda dapat dengan mudah mencatatnya ke MLflow Model Registry dan menyebarkannya untuk penilaian real time dengan Model Serving.
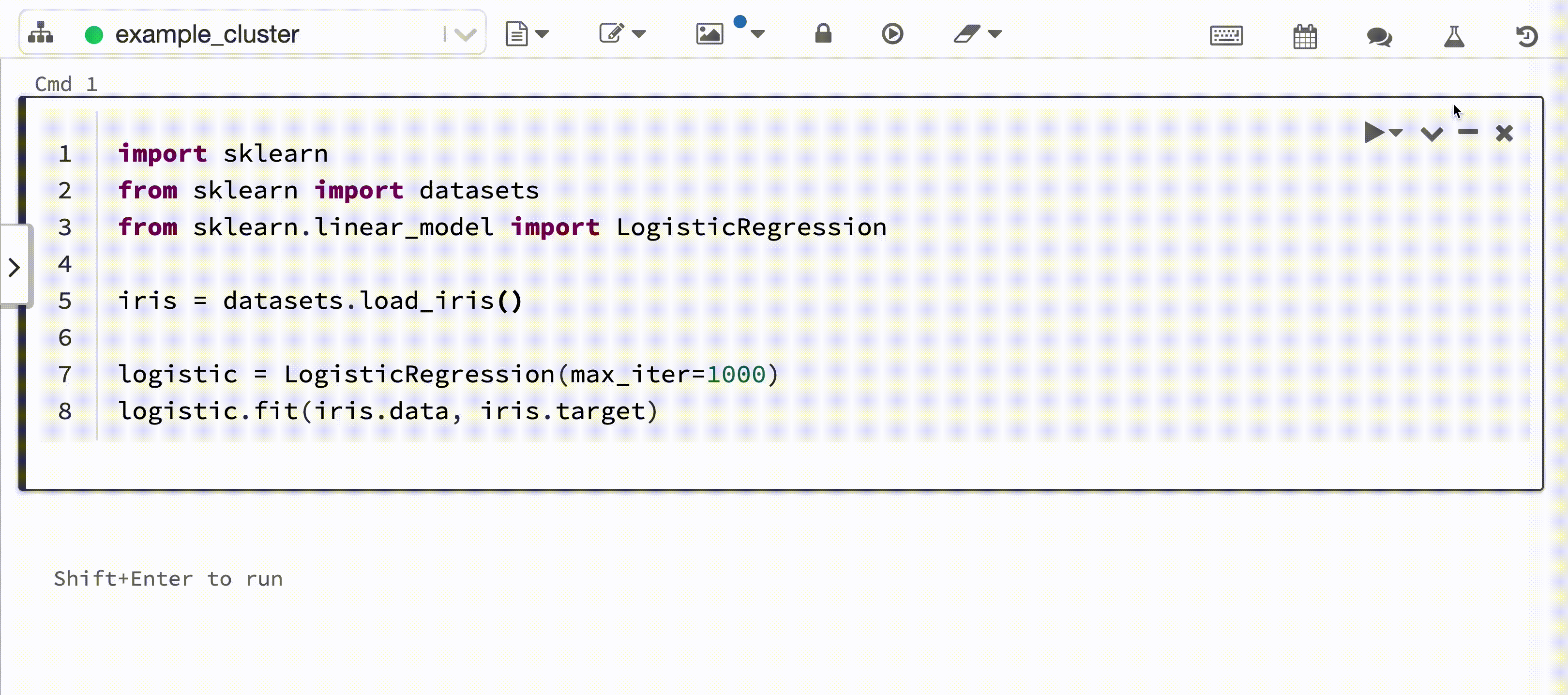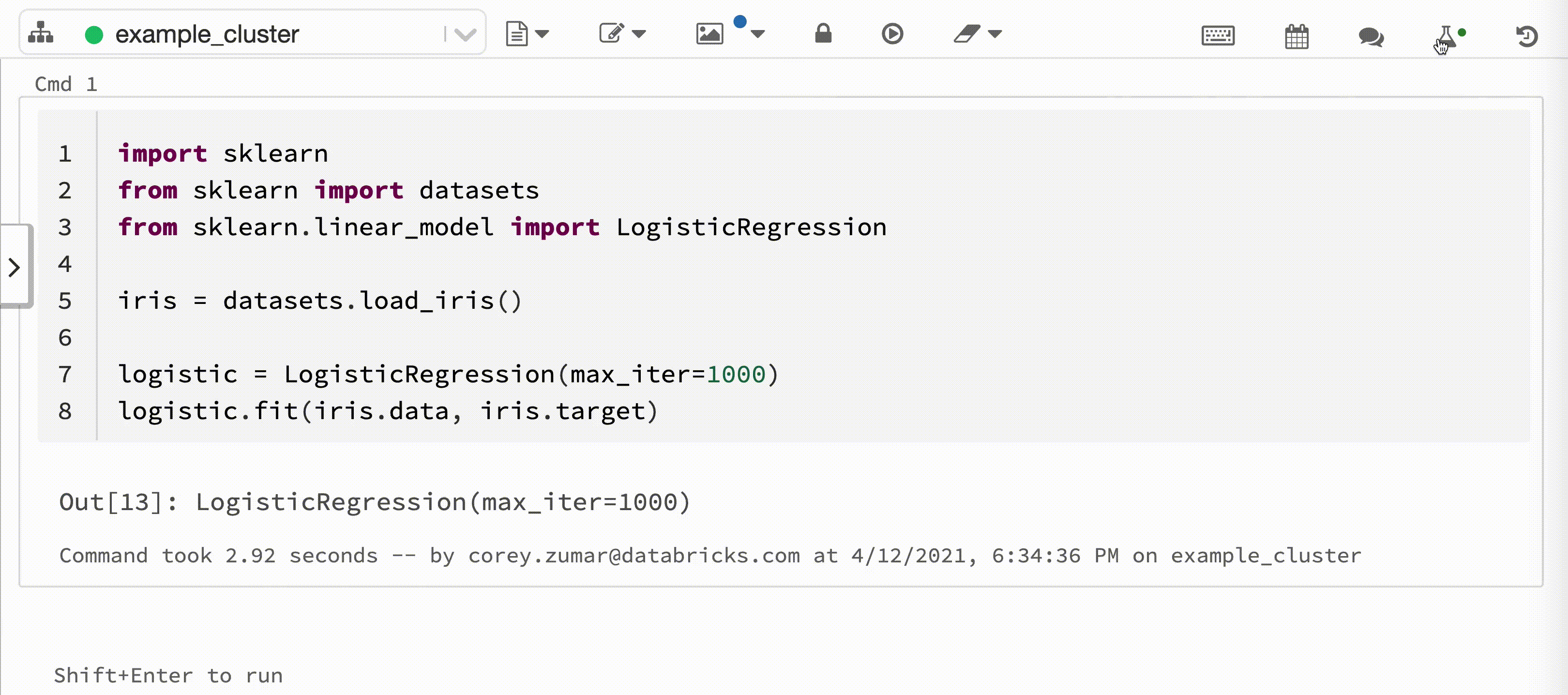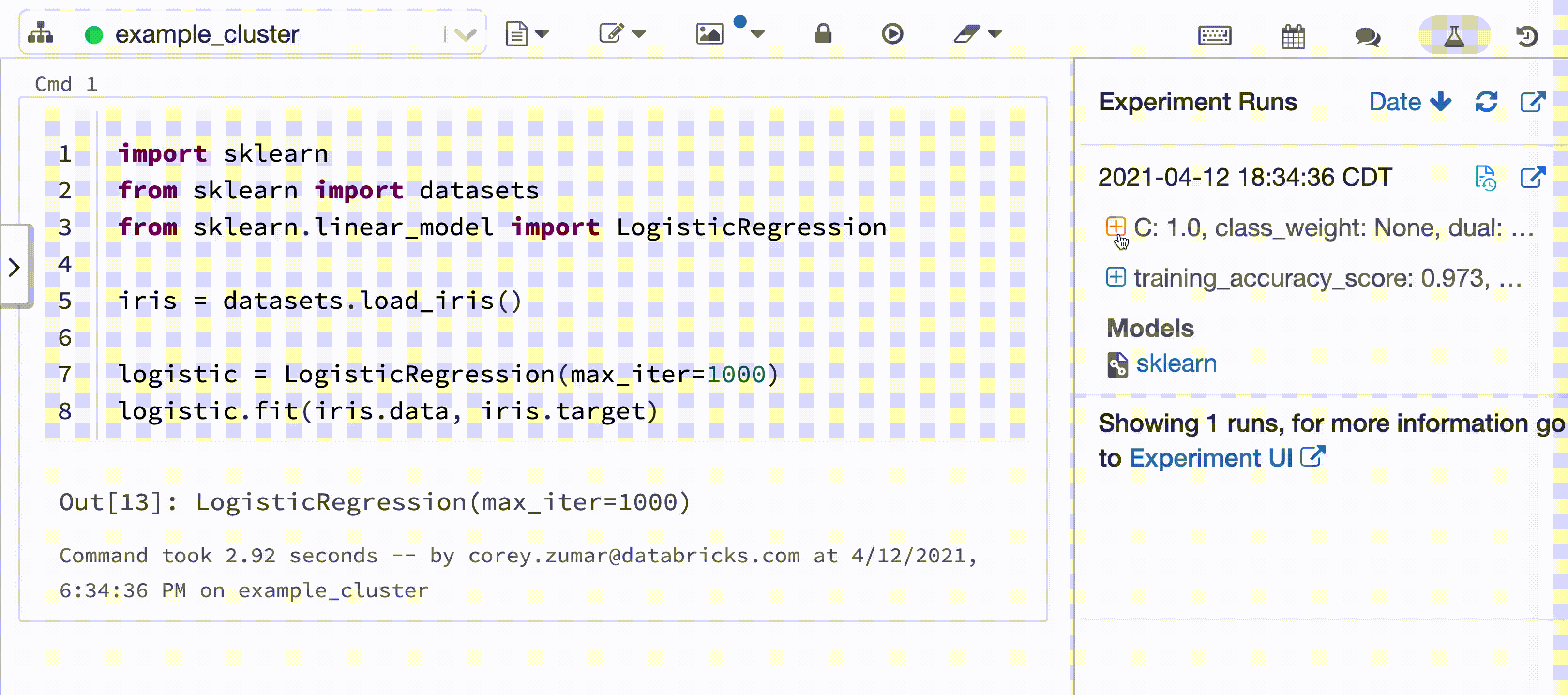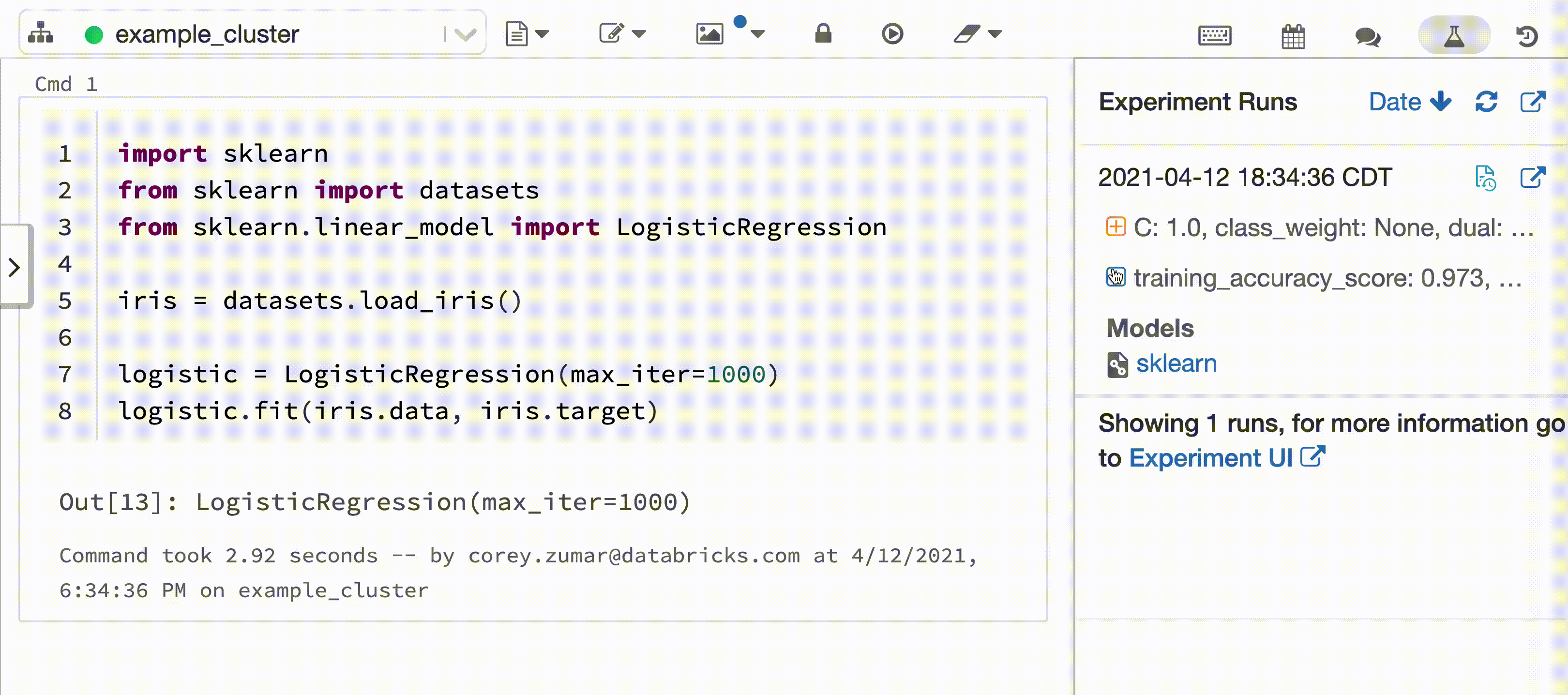
Video berikut menunjukkan Pencatatan Otomatis Databricks dengan sesi pelatihan model pembelajaran scikit di buku catatan Python interaktif. Informasi pelacakan secara otomatis ditangkap dan ditampilkan di bar samping Eksekusi Eksperimen dan di antarmuka pengguna MLflow.
Persyaratan
- Databricks Autologging umumnya tersedia di semua wilayah dengan Databricks Runtime 10.4 LTS ML atau lebih tinggi.
- Databricks Autologging tersedia di wilayah pratinjau tertentu dengan Databricks Runtime 9.1 LTS ML atau lebih tinggi.
Cara kerjanya
Saat Anda melampirkan notebook Python interaktif ke kluster Azure Databricks, Databricks Autologging memanggil mlflow.autolog() untuk menyiapkan pelacakan untuk sesi pelatihan model Anda. Saat Anda melatih model di buku catatan, informasi pelatihan model secara otomatis dilacak dengan Pelacakan MLflow. Untuk informasi tentang bagaimana informasi pelatihan model ini diamankan dan dikelola, lihat Keamanan dan manajemen data.
Konfigurasi default untuk panggilan mlflow.autolog() adalah:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Anda dapat menyesuaikan konfigurasi pencatatan otomatis.
Penggunaan
Untuk menggunakan Pencatatan Otomatis Databricks, latih model pembelajaran mesin dalam kerangka kerja yang didukung menggunakan buku catatan Azure Databricks Python interaktif. Pencatatan Otomatis Databricks secara otomatis mencatat informasi garis keturunan model, parameter, dan metrik ke Pelacakan MLflow. Anda juga dapat menyesuaikan perilaku Pencatatan Otomatis Databricks.
Catatan
Pencatatan Otomatis Databricks tidak diterapkan untuk eksekusi yang dibuat menggunakan API lancar MLflow dengan mlflow.start_run(). Dalam kasus ini, Anda harus menelepon mlflow.autolog() untuk menyimpan konten yang dicatat otomatis ke eksekusi MLflow. Lihat Melacak konten tambahan.
Mengkustomisasi perilaku pencatatan
Untuk menyesuaikan pencatatan, gunakan mlflow.autolog().
Fungsi ini menyediakan parameter konfigurasi untuk mengaktifkan pencatatan model (log_models), mengumpulkan contoh input (log_input_examples), mengonfigurasi peringatan (silent), dan banyak lagi.
Melacak konten tambahan
Untuk melacak metrik, parameter, file, dan metadata tambahan dengan eksekusi MLflow yang dibuat oleh Databricks Autologging, ikuti langkah-langkah ini di notebook Python interaktif Azure Databricks:
- Panggil mlflow.autolog() dengan
exclusive=False. - Mulai eksekusi MLflow menggunakan mlflow.start_run().
Anda dapat membungkus panggilan ini pada
with mlflow.start_run(); ketika Anda melakukan ini, eksekusi berakhir secara otomatis setelah selesai. - Gunakan metode Pelacakan MLflow, seperti mlflow.log_param(), untuk melacak konten pra-pelatihan.
- Latih satu atau beberapa model pembelajaran mesin dalam kerangka kerja yang didukung oleh Pencatatan Otomatis Databricks.
- Gunakan metode Pelacakan MLflow, seperti mlflow.log_metric(), untuk melacak konten pasca-pelatihan.
- Jika Anda tidak menggunakan
with mlflow.start_run()di Langkah 2, akhiri MLflow yang dijalankan menggunakan mlflow.end_run().
Contohnya:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Nonaktifkan Pencatatan Otomatis Databricks
Untuk menonaktifkan Databricks Autologging di notebook Python interaktif Azure Databricks, panggil mlflow.autolog() dengan disable=True:
import mlflow
mlflow.autolog(disable=True)
Administrator juga dapat menonaktifkan Databricks Autologging untuk semua kluster di ruang kerja dari tab Tingkat Lanjut di halaman pengaturan admin. Kluster harus dihidupkan ulang agar perubahan ini berlaku.
Lingkungan dan kerangka kerja yang didukung
Pencatatan Otomatis Databricks didukung dalam buku catatan Python interaktif dan tersedia untuk kerangka kerja ML berikut:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- Petir PyTorch
- XGBoost
- LightGBM
- Gluon
- Fast.ai (versi 1.x)
- statsmodels.
Untuk informasi selengkapnya tentang masing-masing kerangka kerja yang didukung, lihat Pencatatan otomatis MLflow.
Manajemen keamanan dan data
Semua informasi pelatihan model yang dilacak dengan Pencatatan Otomatis Databricks disimpan dalam Pelacakan MLflow dan diamankan dengan izin Eksperimen MLflow. Anda dapat berbagi, memodifikasi, atau menghapus informasi pelatihan model menggunakan MLflow Tracking API atau Antarmuka Pengguna.
Administrasi
Administrator dapat mengaktifkan atau menonaktifkan Databricks Autologging untuk semua sesi buku catatan interaktif di seluruh ruang kerja mereka di tab Tingkat Lanjut di halaman pengaturan admin. Perubahan tidak berlaku sampai kluster dihidupkan ulang.
Batasan
- Pencatatan Otomatis Databricks tidak didukung dalam pekerjaan Azure Databricks. Untuk menggunakan pencatatan otomatis dari pekerjaan, Anda dapat secara eksplisit memanggil mlflow.autolog().
- Pencatatan Otomatis Databricks hanya diaktifkan pada {i>node
- Integrasi scikit-learn XGBoost tidak didukung.
Apache Spark MLlib, Hyperopt, dan pelacakan MLflow otomatis
Pencatatan Otomatis Databricks tidak mengubah perilaku integrasi pelacakan MLflow otomatis yang ada untuk Apache Spark MLlib dan Hyperopt.
Catatan
Dalam Databricks Runtime 10.1 ML, menonaktifkan integrasi pelacakan MLflow otomatis untuk Apache Spark MLlib CrossValidator dan TrainValidationSplit model juga menonaktifkan fitur Pencatatan Otomatis Databricks untuk semua model Apache Spark MLlib.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk