Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Gambaran Umum
Skor kustom menawarkan fleksibilitas utama untuk menentukan dengan tepat bagaimana kualitas aplikasi GenAI Anda diukur. Skor kustom memberikan fleksibilitas untuk menentukan metrik evaluasi yang disesuaikan dengan kasus penggunaan bisnis spesifik Anda, baik berdasarkan heuristik sederhana, logika tingkat lanjut, atau evaluasi terprogram.
Gunakan skor kustom untuk skenario berikut:
- Menentukan metrik evaluasi hueristik kustom atau berbasis kode
- Menyesuaikan bagaimana data dari jejak aplikasi Anda dipetakan ke juri LLM yang didukung penelitian Databricks di skorer LLM yang telah ditentukan sebelumnya
- Membuat hakim LLM dengan teks perintah kustom menggunakan artikel skorer LLM berbasis perintah .
- Menggunakan model LLM Anda sendiri (bukan model hakim LLM yang dihosting Databricks) untuk evaluasi
- Kasus penggunaan lain di mana Anda membutuhkan lebih banyak fleksibilitas dan kontrol daripada yang disediakan oleh abstraksi yang telah ditentukan sebelumnya
Nota
Lihat halaman konsep scorer atau ke dokumen API untuk referensi terperinci tentang antarmuka scorer kustom.
Gambaran umum penggunaan
Skor kustom ditulis dalam Python dan memberi Anda kontrol penuh untuk mengevaluasi data apa pun dari jejak aplikasi Anda. Satu scorer kustom berfungsi di harnessevaluate(...) untuk evaluasi offline atau jika diteruskan ke create_monitor(...) untuk pemantauan produksi.
Jenis output berikut didukung:
- String pass/fail:
"yes" or "no"nilai string dirender sebagai "Pass" atau "Fail" di UI. - Nilai numerik: Nilai ordinal: bilangan bulat atau float.
- Nilai Boolean:
TrueatauFalse. - Objek umpan balik: Mengembalikan
Feedbackobjek dengan skor, alasan, dan metadata tambahan
Sebagai input, penilai kustom memiliki akses ke:
-
Pelacakan MLflow lengkap, termasuk rentang, atribut, dan output. Jejak diteruskan ke penilai kustom sebagai kelas yang diinstansiasi
mlflow.entities.trace. -
inputsKamus, berasal dari himpunan data input atau pasca-proses MLflow dari jejak Anda. - Nilai
outputsberasal dari dataset input atau jejak. Jikapredict_fndisediakan, nilaioutputsakan menjadi pengembalian daripredict_fn. -
expectationsKamus, berasal dariexpectationsbidang dalam himpunan data input, atau penilaian yang terkait dengan pelacakan.
Dekorator @scorer memungkinkan pengguna untuk menentukan metrik evaluasi kustom yang dapat diteruskan ke dalam mlflow.genai.evaluate() menggunakan argumen scorers atau create_monitor(...).
Fungsi scorer dipanggil dengan argumen bernama berdasarkan spesifikasi di bawah ini. Semua argumen bernama bersifat opsional sehingga Anda dapat menggunakan kombinasi apa pun. Misalnya, Anda dapat menentukan scorer yang hanya memiliki inputs dan trace sebagai argumen dan menghilangkan outputs dan expectations:
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
@scorer
def my_custom_scorer(
*, # evaluate(...) harness will always call your scorer with named arguments
inputs: Optional[dict[str, Any]], # The agent's raw input, parsed from the Trace or dataset, as a Python dict
outputs: Optional[Any], # The agent's raw output, parsed from the Trace or
expectations: Optional[dict[str, Any]], # The expectations passed to evaluate(data=...), as a Python dict
trace: Optional[mlflow.entities.Trace] # The app's resulting Trace containing spans and other metadata
) -> int | float | bool | str | Feedback | list[Feedback]
Pendekatan pengembangan scorer kustom
Saat mengembangkan metrik, Anda harus dengan cepat melakukan iterasi pada metrik tanpa harus menjalankan aplikasi setiap kali Anda membuat perubahan pada scorer. Untuk melakukan ini, kami merekomendasikan langkah-langkah berikut:
Langkah 1: Tentukan metrik awal, aplikasi, dan data evaluasi Anda
import mlflow
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
from typing import Any
@mlflow.trace
def my_app(input_field_name: str):
return {'output': input_field_name+'_output'}
@scorer
def my_metric() -> int:
# placeholder return value
return 1
eval_set = [{'inputs': {'input_field_name': 'test'}}]
Langkah 2: Hasilkan jejak dari aplikasi Anda menggunakan evaluate()
eval_results = mlflow.genai.evaluate(
data=eval_set,
predict_fn=my_app,
scorers=[dummy_metric]
)
Langkah 3: Mengkueri dan menyimpan jejak yang dihasilkan
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
Langkah 4: Berikan jejak yang dihasilkan sebagai input ke evaluate() saat Anda mengiterasi metrik Anda
Fungsi search_traces mengembalikan Pandas DataFrame jejak, yang dapat Anda langsung berikan sebagai himpunan data input ke evaluate(). Ini memungkinkan Anda untuk dengan cepat melakukan iterasi pada metrik Anda tanpa harus menjalankan kembali aplikasi Anda.
@scorer
def my_metric(outputs: Any):
# Implement the actual metric logic here.
return outputs == "test_output"
# Note the lack of a predict_fn parameter
mlflow.genai.evaluate(
data=generated_traces,
scorers=[my_metric],
)
Contoh pencetak skor kustom
Dalam panduan ini, kami akan menunjukkan berbagai pendekatan untuk membangun skorer kustom.

Prasyarat: membuat aplikasi sampel dan mendapatkan salinan lokal jejak
Di semua pendekatan, kami menggunakan aplikasi sampel di bawah ini dan salinan jejak (diekstraksi menggunakan pendekatan di atas).
import mlflow
from openai import OpenAI
from typing import Any
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
# Enable auto logging for OpenAI
mlflow.openai.autolog()
# Connect to a Databricks LLM via OpenAI using the same credentials as MLflow
# Alternatively, you can use your own OpenAI credentials here
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token,
base_url=f"{mlflow_creds.host}/serving-endpoints"
)
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
return response.choices[0].message.content
# Create a list of messages for the LLM to generate a response
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def dummy_metric():
# This scorer is just to help generate initial traces.
return 1
# Generate initial traces by running the sample_app.
# The results, including traces, are logged to the MLflow experiment defined above.
initial_eval_results = mlflow.genai.evaluate(
data=eval_dataset, predict_fn=sample_app, scorers=[dummy_metric]
)
generated_traces = mlflow.search_traces(run_id=initial_eval_results.run_id)
Setelah menjalankan kode di atas, Anda harus memiliki tiga jejak dalam eksperimen Anda.
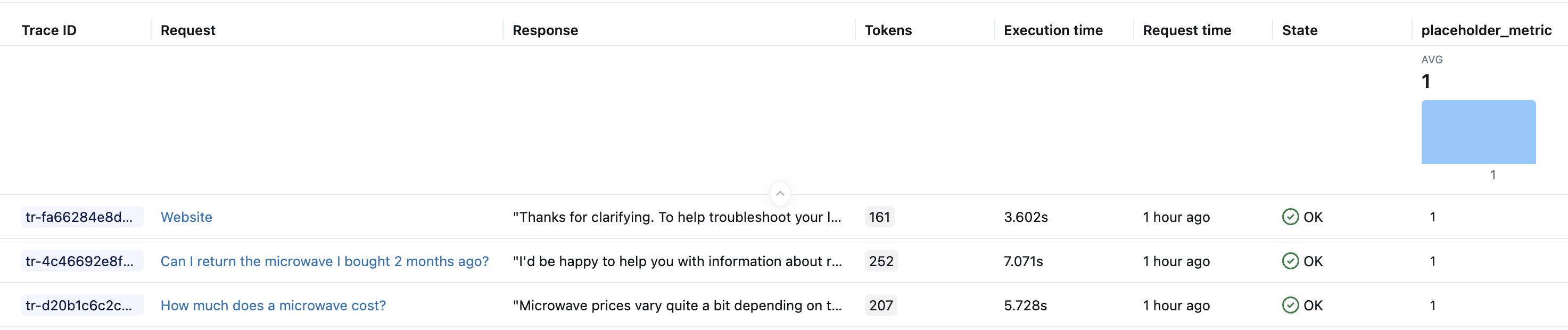
Contoh 1: Mengakses data dari jejak
Akses objek Pelacakan MLflow lengkap untuk menggunakan berbagai detail (rentang, input, output, atribut, waktu) untuk perhitungan metrik terperinci.
Nota
Dari generated_traces bagian prasyarat akan digunakan sebagai data input untuk contoh-contoh ini.
Scorer ini memeriksa apakah total waktu eksekusi pelacakan berada dalam rentang yang dapat diterima.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # second
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
Contoh 2: Membungkus hakim LLM yang telah ditentukan sebelumnya
Buat penilaian kustom yang mengintegrasikan hakim LLM MLflow yang telah ditentukan sebelumnya. Gunakan ini untuk memproses awal data jejak untuk hakim atau memproses kembali umpan baliknya.
Contoh ini menunjukkan cara membungkus is_context_relevant hakim yang mengevaluasi apakah konteks yang diberikan relevan dengan kueri, untuk mengevaluasi apakah respons asisten relevan dengan kueri pengguna.
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
# The `inputs` field for `sample_app` is a dictionary like: {"messages": [{"role": ..., "content": ...}, ...]}
# We need to extract the content of the last user message to pass to the relevance judge.
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the custom relevance scorer
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
Contoh 3: Menggunakan expectations
Ketika mlflow.genai.evaluate() dipanggil dengan argumen data yang berupa daftar kamus atau DataFrame Pandas, setiap barisnya dapat mengandung kunci expectations. Nilai yang terkait dengan kunci ini diteruskan langsung ke penilai kustom Anda.
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
Contoh 3.1: Kecocokan Persis dengan Respons yang Diharapkan
Scorer ini memeriksa apakah respons asisten sama persis dengan yang expected_response disediakan di expectations.
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match]
)
Contoh 3.2: Pemeriksaan Kehadiran Kata Kunci dari Ekspektasi
Scorer ini memeriksa apakah semua expected_keywords dari expectations hadir dalam respons asisten.
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(
score=None, # Undetermined, as no keywords were expected
rationale="No 'expected_keywords' provided in expectations."
)
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
Contoh 4: Mengembalikan beberapa objek umpan balik
Seorang penilai dapat mengembalikan daftar Feedback objek, memungkinkan satu penilai menilai beberapa aspek kualitas (misalnya, PII, sentimen, keringkasan) secara bersamaan. Setiap objek Feedback sebaiknya memiliki name yang unik (yang akan menjadi nama metrik pada hasil); jika tidak, objek-objek tersebut mungkin saling menimpa jika nama-nama tersebut dibuat secara otomatis dan bertabrakan. Jika nama tidak disediakan, MLflow akan mencoba membuatnya berdasarkan nama fungsi scorer dan indeks.
Contoh ini menunjukkan sebuah penilai yang memberikan dua umpan balik yang berbeda untuk setiap penelusuran:
-
is_not_empty_check: Boolean yang menunjukkan apakah konten respons tidak kosong. -
response_char_length: Nilai numerik untuk panjang karakter respons.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
Hasilnya akan memiliki dua kolom: is_not_empty_check dan response_char_length sebagai penilaian.
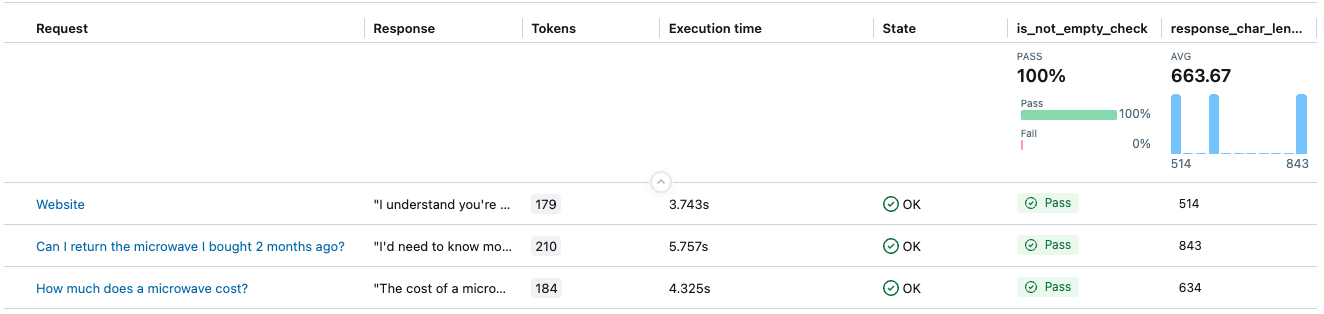
Contoh 5: Menggunakan LLM Anda sendiri untuk hakim
Integrasikan LLM kustom atau yang dihosting secara eksternal dalam sebuah penilai. Scorer menangani panggilan API, pemformatan input/output, dan menghasilkan Feedback dari respons LLM Anda, memberikan kontrol penuh atas proses penjurian.
Anda juga dapat mengatur source bidang di Feedback objek untuk menunjukkan sumber penilaian adalah hakim LLM.
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
# Assume `client` (OpenAI SDK client configured for Databricks) is available from the prerequisite block.
# client = OpenAI(...)
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-3-7-sonnet",
)
)
# Evaluate the scorer using the pre-generated traces.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
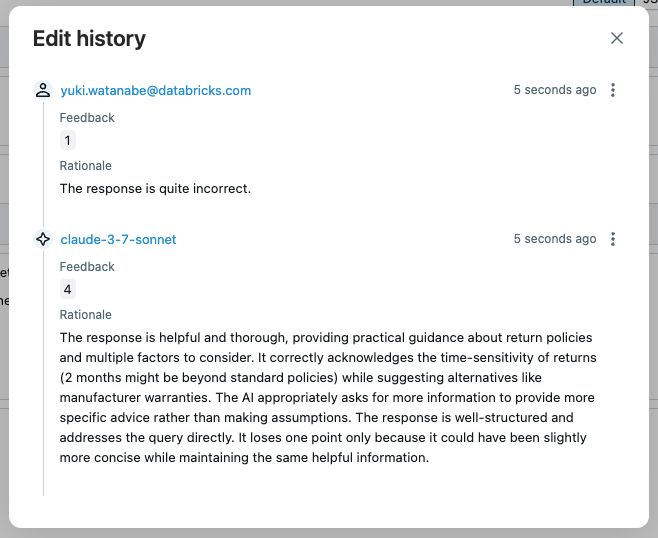
Dengan membuka jejak di UI dan mengklik penilaian answer_quality, Anda dapat melihat metadata untuk penilai, seperti alasan, cap waktu, nama model penilai, dll. Jika penilaian penilai tidak benar, Anda dapat menyetel ulang skor dengan mengklik tombol Edit.
Penilaian baru akan menggantikan penilaian hakim asli, tetapi riwayat edit akan dipertahankan untuk referensi di masa mendatang.
Langkah selanjutnya
Lanjutkan perjalanan Anda dengan tindakan dan tutorial yang direkomendasikan ini.
- Mengevaluasi dengan skor LLM kustom - Membuat evaluasi semantik menggunakan LLM
- Jalankan scorer dalam produksi - Sebarkan scorer Anda untuk pemantauan berkelanjutan
- Membangun himpunan data evaluasi - Membuat data pengujian untuk scorer Anda
Panduan referensi
Jelajahi dokumentasi terperinci untuk konsep dan fitur yang disebutkan dalam panduan ini.
- Scorer - Mendalami cara kerja scorer dan arsitektur mereka
-
Evaluation Harness - Pahami bagaimana
mlflow.genai.evaluate()menggunakan skor Anda - Hakim LLM - Pelajari fondasi untuk evaluasi bertenaga AI