Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling berada di Beta di wilayah berikut: eastus2, , westeuropewestus.
Lakebase Autoscaling adalah versi terbaru Lakebase dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk perbandingan fitur dengan Lakebase Provisioned, lihat memilih antar versi.
Dasbor Metrik di UI Lakebase menyediakan grafik untuk memantau metrik sistem dan database. Anda dapat mengakses dasbor Metrik dari bar samping di Aplikasi Lakebase. Metrik yang dapat diamati termasuk penggunaan RAM, penggunaan CPU, jumlah koneksi, ukuran database, kebuntuan, operasi baris, penundaan replikasi, performa cache, dan ukuran set kerja.
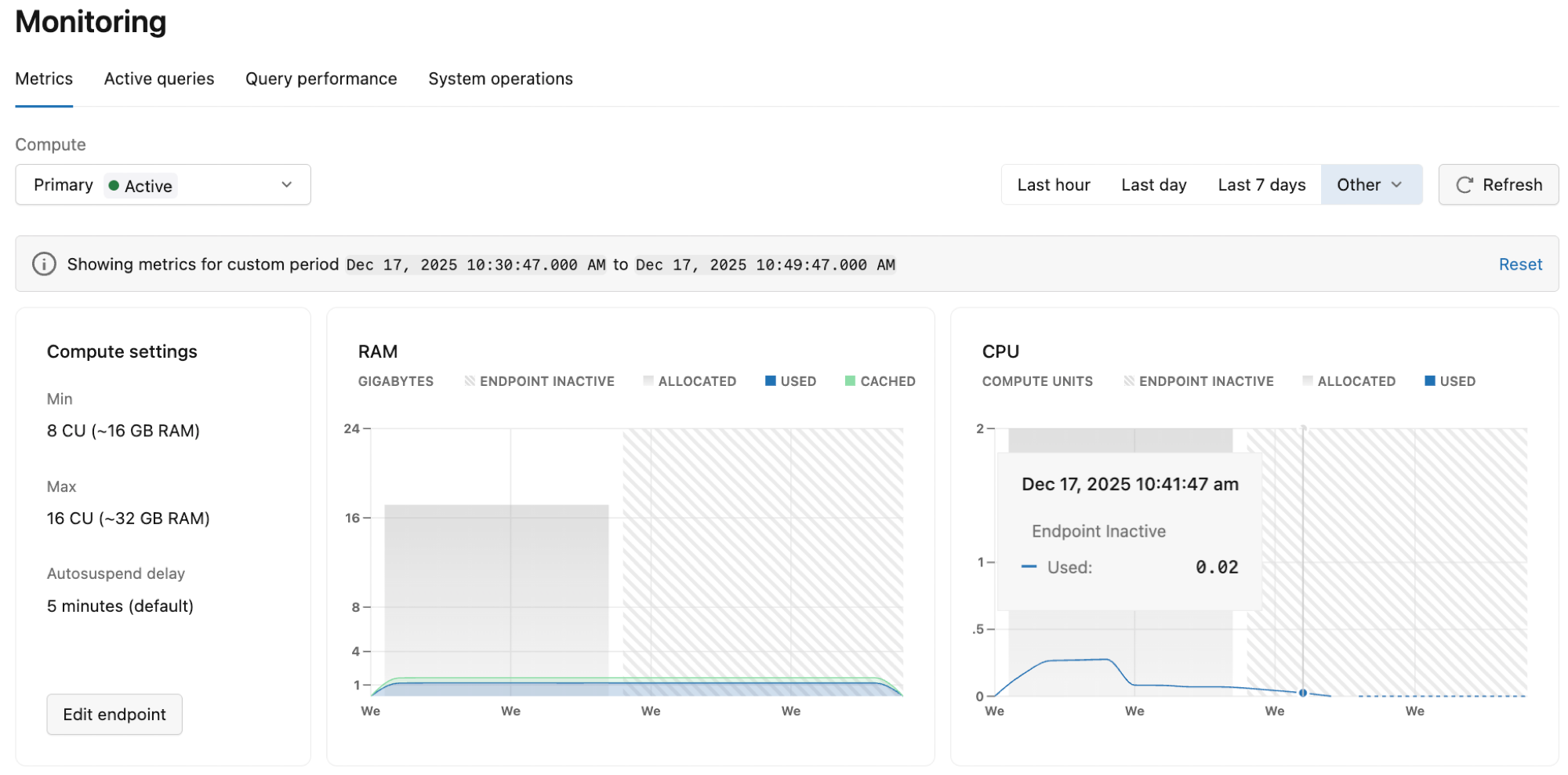
Dasbor menampilkan metrik untuk cabang dan komputasi yang dipilih. Gunakan menu drop-down untuk melihat metrik untuk cabang atau komputasi yang berbeda. Anda dapat memilih dari periode waktu yang telah ditentukan sebelumnya (Jam terakhir, Hari terakhir, 7 hari terakhir) atau memilih Lainnya untuk opsi tambahan (3 jam terakhir, 6 jam terakhir, 12 jam terakhir, 2 hari terakhir, atau Kustom). Gunakan tombol Refresh untuk memperbarui metrik yang ditampilkan.
Memahami komputasi yang tidak aktif
Jika grafik tidak menampilkan data apa pun, komputasi Anda mungkin tidak aktif karena skala ke nol.
Saat komputasi tidak aktif, nilai metrik turun ke 0 karena komputasi aktif diperlukan untuk melaporkan data. Periode tidak aktif muncul sebagai pola garis diagonal dalam grafik.
Jika grafik tidak menampilkan data, coba pilih periode waktu yang berbeda atau kembalikan nanti setelah lebih banyak data penggunaan dikumpulkan.
MAA
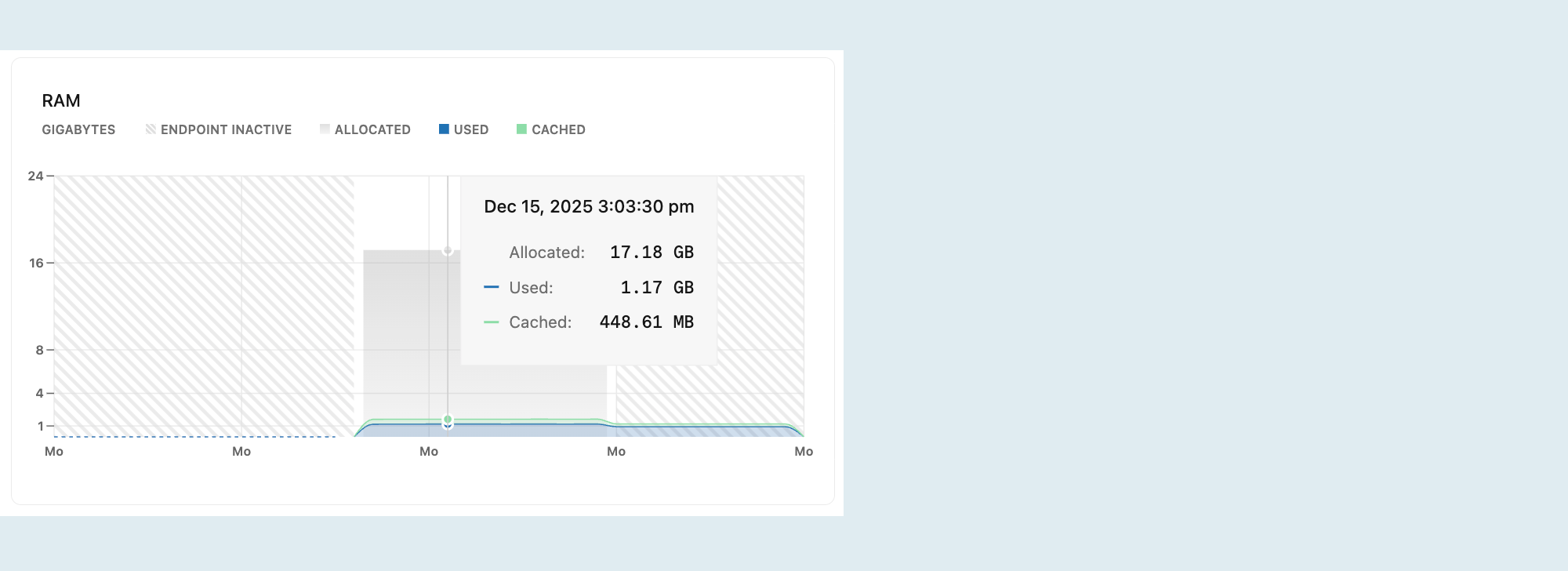
Grafik ini menunjukkan RAM dan penggunaan yang dialokasikan dari waktu ke waktu untuk komputasi yang dipilih.
Ini termasuk metrik berikut:
Dialokasikan: Jumlah RAM yang dialokasikan.
RAM dialokasikan sesuai dengan ukuran komputasi atau konfigurasi penskalaan otomatis Anda. Dengan penskalaan otomatis, RAM yang dialokasikan meningkat dan menurun saat komputasi Anda meningkat dan turun sebagai respons terhadap beban. Jika skala ke nol diaktifkan dan komputasi Anda beralih ke status menganggur setelah tidak aktif, RAM yang dialokasikan turun ke 0.
Digunakan: Jumlah RAM yang digunakan.
Grafik memplot baris yang menunjukkan penggunaan RAM. Jika beban kerja secara teratur mencapai batas maksimum RAM yang dialokasikan, pertimbangkan untuk meningkatkan kapasitas komputasi Anda. Untuk opsi ukuran komputasi, lihat Ukuran komputasi.
Di-cache: Jumlah data yang di-cache dalam memori oleh kueri dan operasi sebelumnya.
CPU
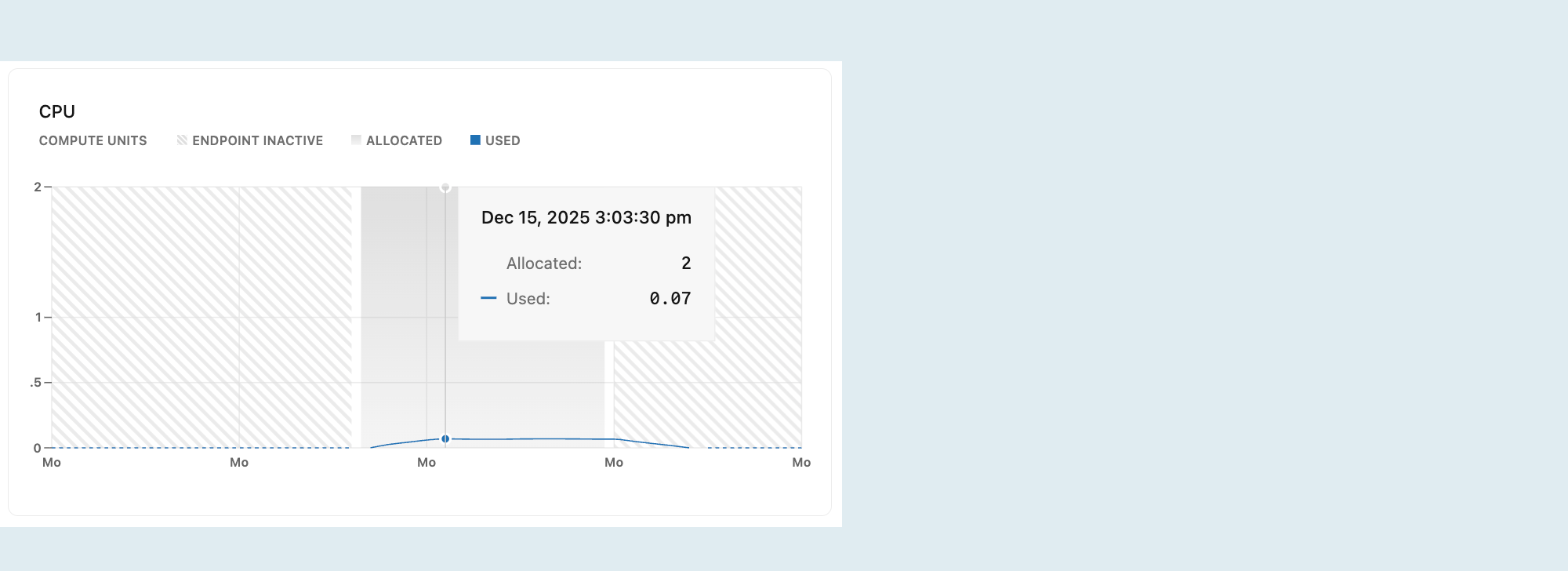
Grafik ini menunjukkan CPU dan penggunaan yang dialokasikan dari waktu ke waktu untuk komputasi yang dipilih.
Dialokasikan: Jumlah CPU yang dialokasikan.
CPU dialokasikan sesuai dengan ukuran komputasi atau konfigurasi penskalaan otomatis Anda. Dengan penskalaan otomatis, CPU yang dialokasikan meningkat dan menurun saat komputasi Anda meningkat dan turun sebagai respons terhadap beban. Jika skala ke nol diaktifkan dan komputasi Anda beralih ke status menganggur setelah tidak aktif, CPU yang dialokasikan turun ke 0.
Digunakan: Jumlah CPU yang digunakan, dalam Unit Komputasi (CU).
Jika baris yang diplot secara teratur mencapai CPU maksimum yang dialokasikan, pertimbangkan untuk meningkatkan ukuran komputasi Anda. Untuk opsi ukuran komputasi, lihat Ukuran komputasi.
Jumlah koneksi
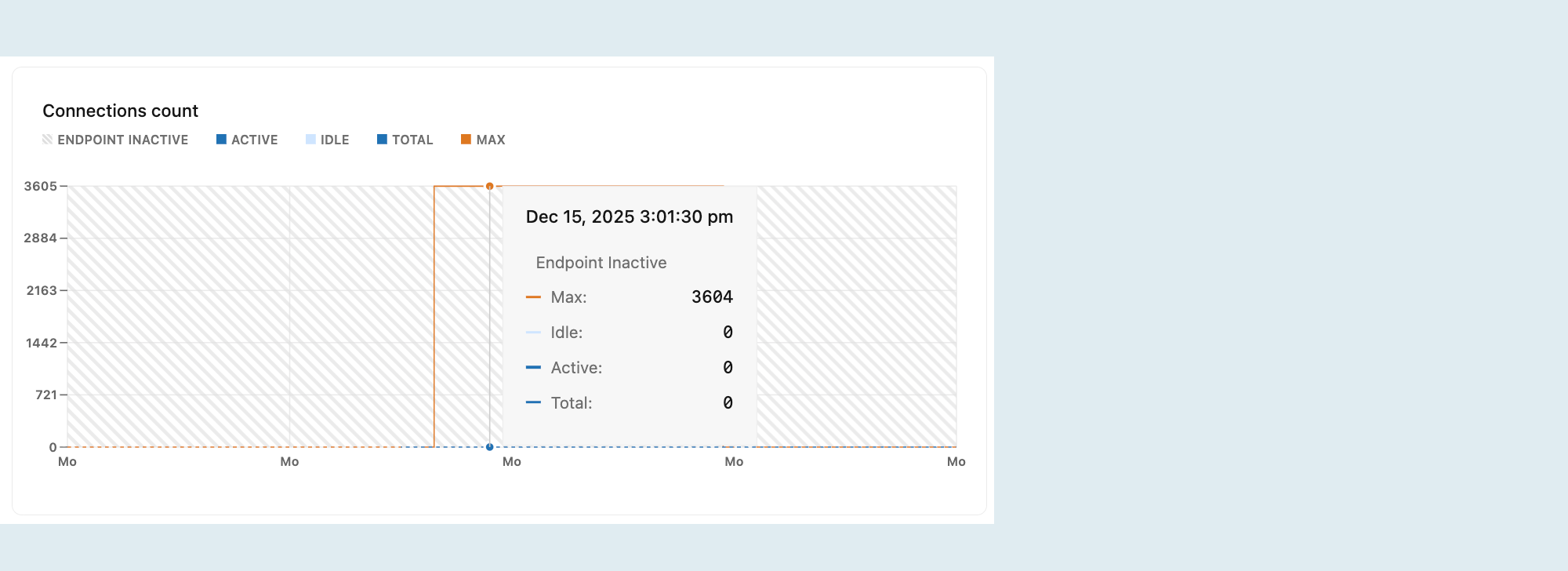
Grafik Jumlah koneksi menunjukkan jumlah maksimum koneksi, jumlah koneksi diam, jumlah koneksi aktif, dan jumlah total koneksi dari waktu ke waktu untuk komputasi yang dipilih.
Aktif: Jumlah koneksi aktif untuk komputasi yang dipilih.
Memantau koneksi aktif membantu Anda memahami beban kerja database Anda. Jika jumlah koneksi aktif secara konsisten tinggi, database Anda mungkin berada di bawah beban berat, yang dapat menyebabkan masalah performa seperti waktu respons kueri yang lambat.
Menganggur: Jumlah koneksi diam untuk komputasi yang dipilih.
Koneksi idle terbuka tetapi tidak digunakan. Meskipun beberapa koneksi diam umumnya tidak berbahaya, sejumlah besar dapat mengonsumsi sumber daya yang tidak perlu, menyisakan lebih sedikit ruang untuk koneksi aktif dan berpotensi memengaruhi performa. Mengidentifikasi dan menutup koneksi tidak aktif yang tidak perlu dapat membantu membebaskan sumber daya.
Total: Jumlah koneksi aktif dan diam untuk komputasi yang dipilih.
Maks: Jumlah maksimum koneksi simultan yang diizinkan untuk ukuran komputasi Anda.
Baris Maks membantu Anda memvisualisasikan seberapa dekat Anda mencapai batas koneksi Anda. Saat Total koneksi Anda mendekati garis Maks, pertimbangkan:
- Meningkatkan ukuran komputasi Anda untuk memungkinkan lebih banyak koneksi
- Mengoptimalkan manajemen koneksi aplikasi Anda (menggunakan pengumpulan koneksi, segera menutup koneksi yang tidak digunakan, dan menghindari koneksi diam berumur panjang)
Batas koneksi ditentukan oleh pengaturan Postgres max_connections dan ditentukan oleh konfigurasi ukuran komputasi Anda. Untuk daftar lengkap koneksi maks menurut ukuran komputasi, lihat Spesifikasi komputasi.
Ukuran database
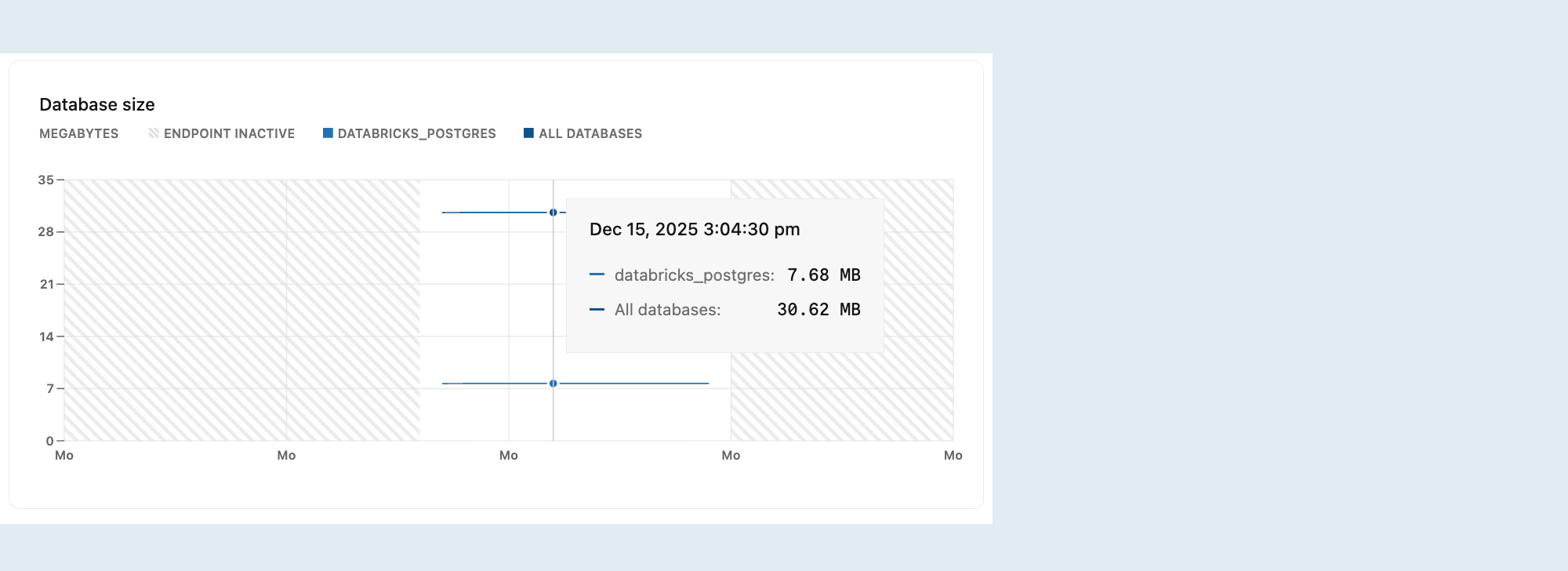
Grafik Ukuran database memperlihatkan ukuran data logis (ukuran data aktual Anda) untuk database yang dipilih atau semua database pada cabang yang dipilih.
Nota
Ukuran logis mewakili ukuran data Anda seperti yang dilaporkan oleh Postgres, termasuk tabel dan indeks.
Nota
Metrik ukuran database hanya ditampilkan saat komputasi Anda aktif. Saat komputasi Anda diam, nilai ukuran database tidak dilaporkan, dan grafik menunjukkan nol meskipun data mungkin ada.
Kebuntuan
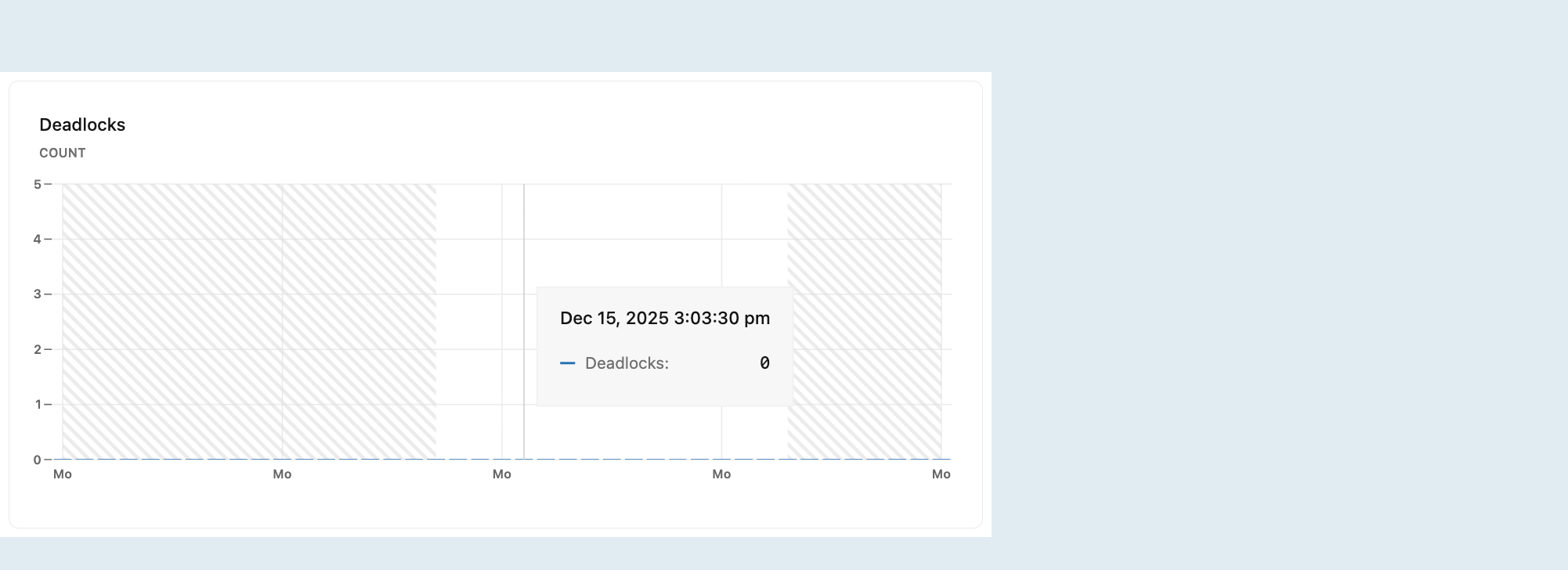
Grafik Deadlocks menunjukkan jumlah deadlock seiring waktu.
Kebuntuan terjadi ketika dua transaksi atau lebih secara bersamaan memblokir satu sama lain dengan menahan sumber daya yang dibutuhkan transaksi lain, menciptakan siklus dependensi yang mencegah transaksi apa pun dilanjutkan. Ini dapat menyebabkan masalah performa atau kesalahan aplikasi. Untuk mempelajari selengkapnya tentang kebuntuan di Postgres, lihat dokumentasi PostgreSQL tentang kebuntuan.
Rows
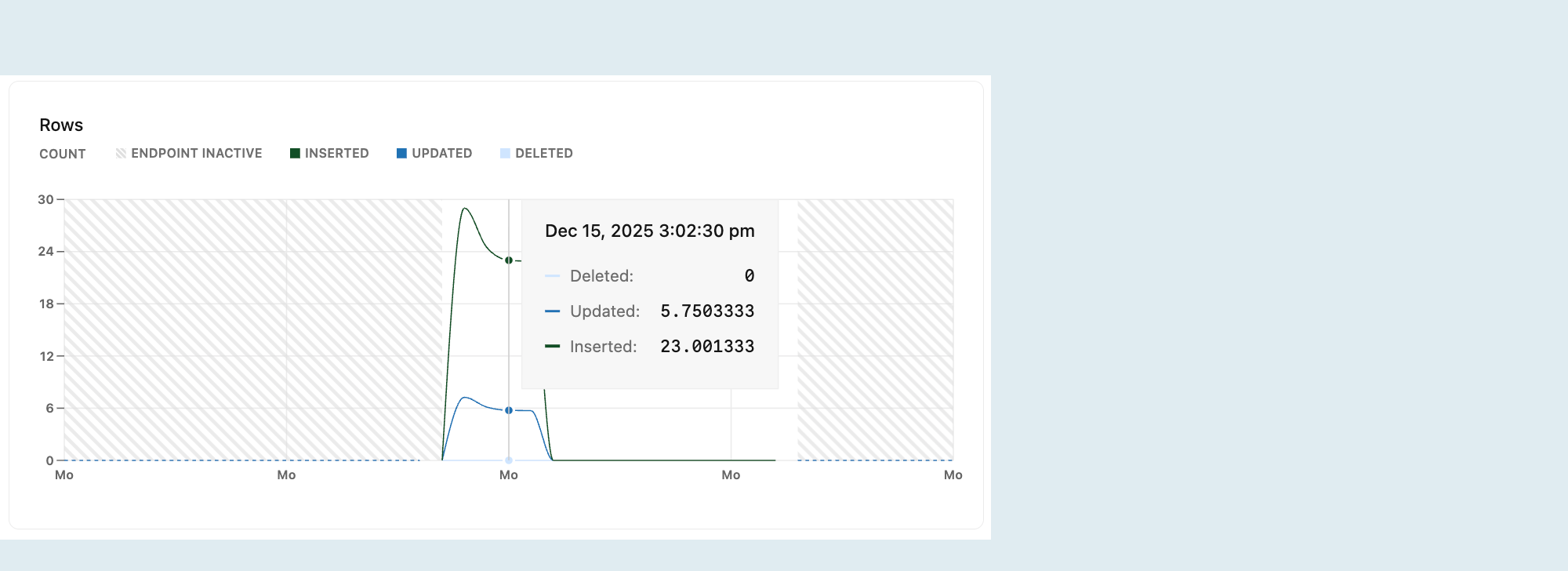
Grafik Baris memperlihatkan jumlah baris yang dihapus, diperbarui, dan disisipkan dari waktu ke waktu. Metrik baris diatur ulang ke nol setiap kali komputasi Anda dimulai ulang.
Melacak baris yang disisipkan, diperbarui, dan dihapus dari waktu ke waktu memberikan wawasan tentang pola aktivitas database Anda. Anda dapat menggunakan data ini untuk mengidentifikasi tren atau penyimpangan, seperti lonjakan sisipan atau jumlah penghapusan yang tidak biasa.
Nota
Metrik baris hanya mengambil perubahan tingkat baris (INSERT, UPDATE, DELETE) dan mengecualikan operasi tingkat tabel seperti TRUNCATE.
Byte penundaan replikasi
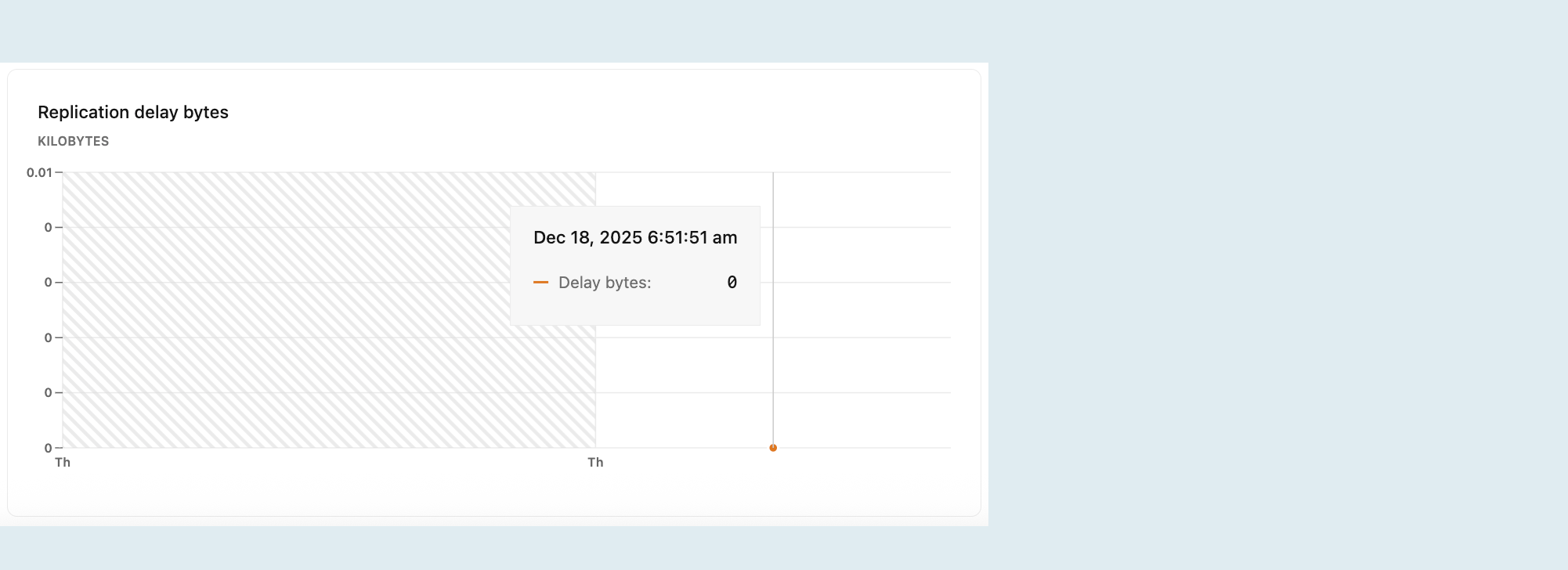
Grafik byte penundaan replikasi menunjukkan ukuran total data dalam byte, yang dikirim dari sistem utama tetapi belum diterapkan pada replika. Nilai yang lebih besar menunjukkan backlog data yang lebih tinggi yang menunggu untuk direplikasi, yang dapat menyarankan masalah dengan throughput replikasi atau ketersediaan sumber daya pada replika.
Nota
Grafik ini hanya terlihat saat memilih komputasi replika baca dari menu drop-down Komputasi. Untuk informasi selengkapnya tentang replika pembacaan, lihat Replika Pembacaan.
Penundaan replikasi dalam detik
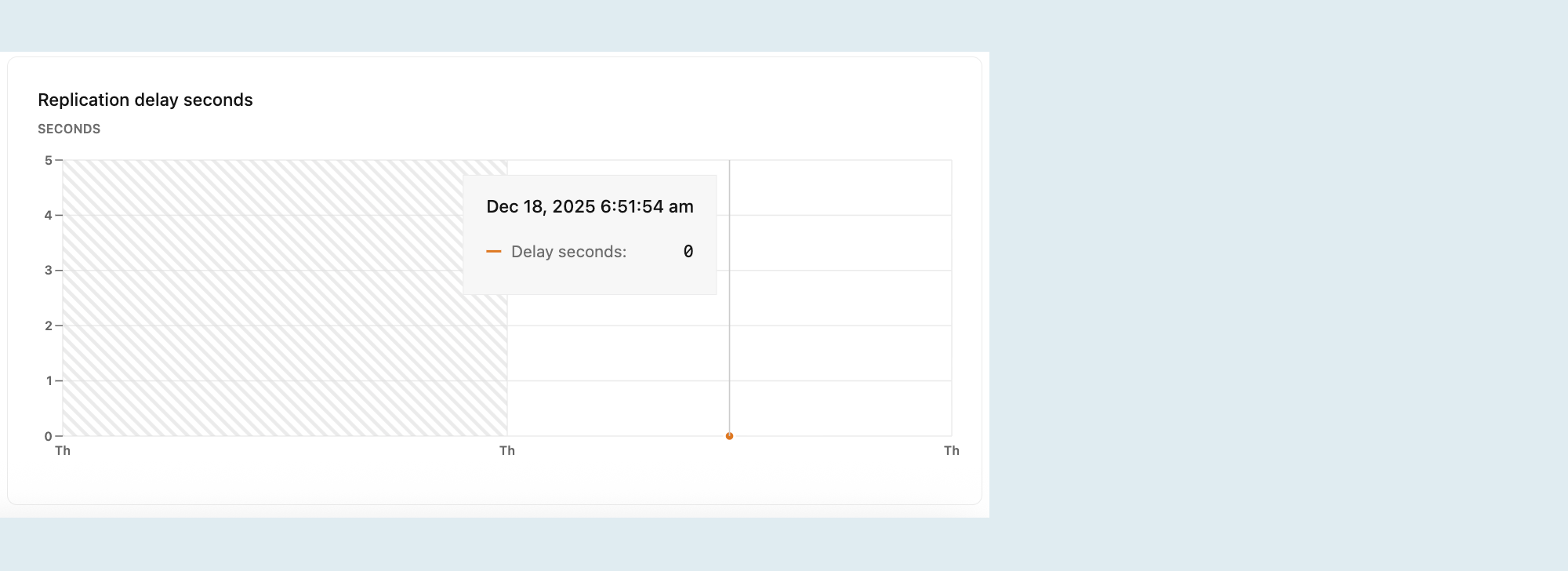
Grafik Detik penundaan Replikasi menunjukkan penundaan waktu, dalam detik, antara transaksi terakhir yang dilakukan pada komputasi utama dan penerapan transaksi tersebut pada replika. Nilai yang lebih tinggi menunjukkan bahwa replika berada di belakang replika utama, berpotensi karena latensi jaringan, beban replikasi tinggi, atau batasan sumber daya pada replika.
Nota
Grafik ini hanya terlihat saat memilih komputasi replika baca dari menu drop-down Komputasi. Untuk informasi selengkapnya tentang read replicas, lihat Read replicas.
Tingkat pencapaian cache berkas lokal
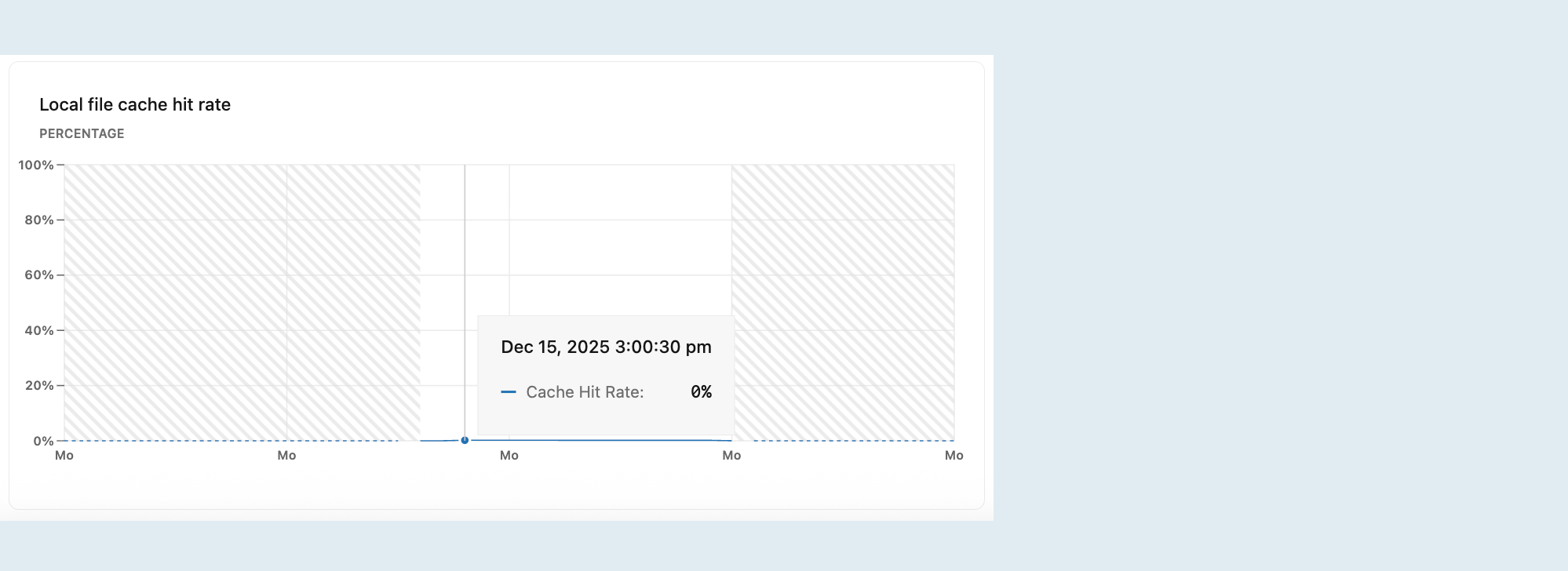
Grafik Laju hit cache file lokal menunjukkan persentase permintaan baca yang dilayani dari cache file lokal. Kueri yang tidak dilayani dari buffer bersama Postgres atau cache file lokal mengakses data dari penyimpanan, yang lebih mahal sehingga dapat mengakibatkan performa kueri yang lebih lambat.
Untuk beban kerja OLTP, bertujulah mencapai persentase tingkat keberhasilan cache sebesar 99% atau lebih baik. Jika tingkat Anda di bawah 99%, set kerja Anda mungkin tidak muat dalam memori, menyebabkan performa yang lebih lambat. Untuk meningkatkan laju hit cache, tingkatkan ukuran komputasi Anda untuk memperluas cache file lokal. Rasio ideal tergantung pada beban kerja yang Anda miliki—beban kerja dengan pemindaian berurutan tabel besar mungkin dapat berkinerja secara memadai dengan rasio yang sedikit lebih rendah.
Tentang cache file lokal
Cache file lokal (LFC) adalah lapisan cache yang menyimpan data yang sering diakses di memori lokal komputer Anda. Ketika data diminta, Postgres memeriksa buffer bersama terlebih dahulu, lalu LFC, dan akhirnya mengambil dari penyimpanan jika diperlukan. Ukuran LFC diskalakan dengan komputasi Anda—dapat menggunakan hingga 75% RAM komputasi Anda. Misalnya, komputasi dengan RAM 8 GB memiliki cache file lokal 6 GB. Untuk performa optimal, ukur komputasi Anda sehingga set kerja Anda sesuai dalam cache file lokal.
:::
Ukuran set kerja
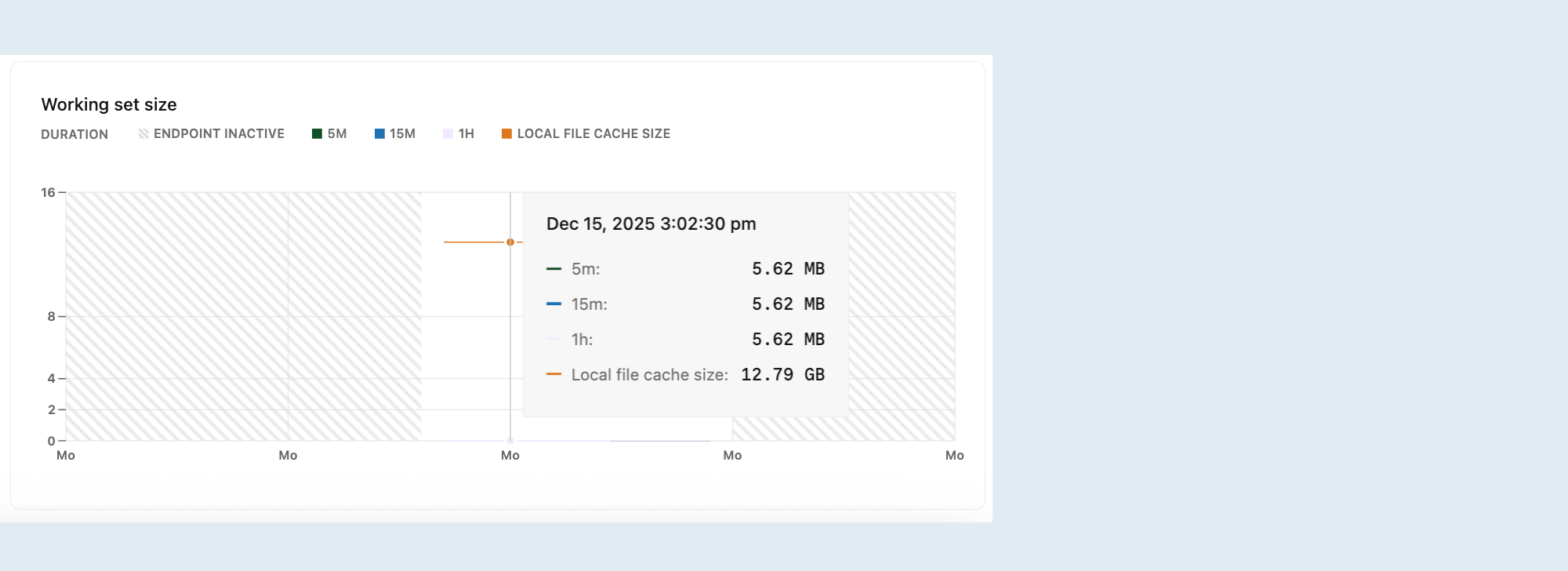
Set kerja Anda adalah ukuran kumpulan halaman Postgres yang berbeda (data relasi dan indeks) yang diakses dalam interval waktu tertentu. Untuk performa optimal dan latensi yang konsisten, ukur komputasi Anda sehingga set kerja sesuai dengan cache file lokal untuk akses cepat.
Grafik Ukuran set kerja memvisualisasikan jumlah data yang diakses (dihitung sebagai halaman unik yang diakses × ukuran halaman) selama interval tertentu. Grafik menampilkan:
5m (5 menit): Data yang diakses dalam 5 menit terakhir.
15m (15 menit): Data yang diakses dalam 15 menit terakhir.
1 jam (1 jam): Data yang diakses dalam satu jam terakhir.
Ukuran cache file lokal: Ukuran cache file lokal, ditentukan oleh ukuran komputasi Anda. Komputasi yang lebih besar memiliki cache yang lebih besar.
Untuk performa optimal, cache file lokal harus lebih besar dari ukuran set kerja Anda untuk interval waktu tertentu. Jika ukuran set kerja Anda lebih besar dari ukuran cache file lokal, tingkatkan ukuran maksimum komputasi Anda untuk meningkatkan laju hit cache dan mencapai performa yang lebih baik. Untuk opsi dan spesifikasi ukuran komputasi, lihat Spesifikasi komputasi.
Jika pola beban kerja Anda tidak banyak berubah dari waktu ke waktu, bandingkan ukuran set kerja 1 jam dengan ukuran cache file lokal dan pastikan bahwa ukuran set kerja lebih kecil dari ukuran cache file lokal.