Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Eksekusi kueri adaptif (AQE) adalah pengoptimalan ulang kueri yang terjadi selama eksekusi kueri.
Motivasi untuk pengoptimalan ulang runtime adalah bahwa Azure Databricks memiliki statistik akurat paling mutakhir di akhir pertukaran pengacakan dan siaran (disebut sebagai tahap kueri di AQE). Akibatnya, Azure Databricks dapat memilih strategi fisik yang lebih baik, memilih ukuran dan jumlah partisi setelah pengacakan yang optimal, atau melakukan pengoptimalan yang sebelumnya memerlukan petunjuk, misalnya, penanganan skew join.
Ini bisa sangat berguna ketika pengumpulan statistik tidak diaktifkan atau ketika statistik basi. Ini juga berguna di tempat-tempat di mana statistik turunan statis tidak akurat, seperti di tengah kueri yang rumit, atau setelah terjadinya penyimpangan data.
Kemampuan
AQE diaktifkan secara default. Ini memiliki 4 fitur utama:
- Mengubah penggabungan sort merge secara dinamis menjadi penggabungan hash broadcast.
- Menggabungkan partisi secara dinamis (menggabungkan partisi kecil menjadi partisi berukuran wajar) setelah pertukaran data secara shuffle. Tugas yang sangat kecil memiliki throughput I/O yang lebih rendah dan cenderung lebih terdampak oleh beban tambahan dari penjadwalan dan penyiapan tugas. Menggabungkan tugas kecil menghemat sumber daya dan meningkatkan throughput kluster.
- Menangani penyimpangan secara dinamis dalam gabungan gabungan sortir dan mengacak gabungan hash dengan memisahkan (dan mereplikasi jika diperlukan) tugas miring menjadi tugas berukuran kira-kira merata.
- Mendeteksi dan menyebarkan hubungan kosong secara dinamis.
Aplikasi
AQE berlaku untuk semua kueri yang:
- Tidak Mengalir
- Berisi setidaknya satu pertukaran data (biasanya ketika ada gabungan, agregat, atau jendela), satu sub-kueri, atau keduanya.
Tidak semua kueri yang menggunakan AQE perlu dioptimalkan kembali. Optimalisasi ulang mungkin akan menghasilkan rencana kueri yang berbeda dari yang dikompilasi secara statis, atau mungkin tidak demikian. Untuk menentukan apakah paket kueri telah diubah oleh AQE, lihat bagian berikut ini, Paket kueri.
Rencana pencarian
Bagian ini membahas bagaimana Anda dapat memeriksa rencana kueri dengan cara yang berbeda.
Di bagian ini:
Antarmuka pengguna Spark
simpul AdaptiveSparkPlan
Kueri yang diterapkan AQE berisi satu atau beberapa simpul AdaptiveSparkPlan, biasanya sebagai simpul akar dari setiap kueri utama atau sub-kueri.
Sebelum kueri berjalan atau saat dijalankan, bendera isFinalPlan dari simpul AdaptiveSparkPlan yang sesuai ditampilkan sebagai false; setelah eksekusi kueri selesai, bendera isFinalPlan berubah menjadi true.
Rencana yang berkembang
Diagram rencana kueri berevolusi saat eksekusi berlangsung dan mencerminkan rencana terbaru yang sedang dijalankan. Simpul yang telah dieksekusi (di mana metrik tersedia) tidak akan berubah, tetapi simpul yang belum dieksekusi dapat berubah dari waktu ke waktu sebagai hasil pengoptimalan ulang.
Berikut ini adalah contoh diagram rencana kueri:
diagram rencana kueri 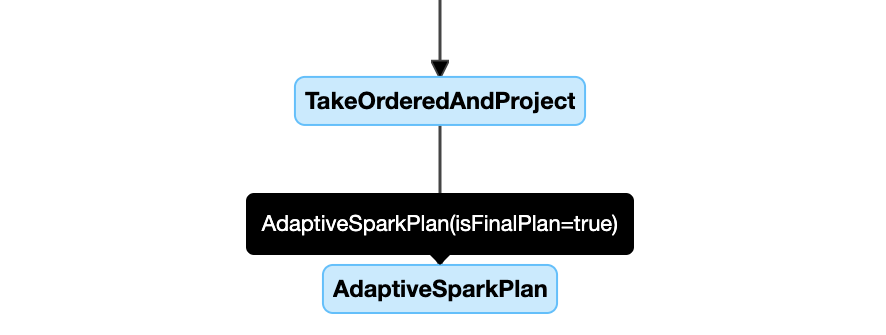
DataFrame.explain()
simpul AdaptiveSparkPlan
Kueri yang diterapkan AQE berisi satu atau beberapa simpul AdaptiveSparkPlan, biasanya sebagai simpul akar dari setiap kueri utama atau sub-kueri. Sebelum kueri berjalan atau saat dijalankan, bendera isFinalPlan dari simpul AdaptiveSparkPlan yang sesuai ditampilkan sebagai false; setelah eksekusi kueri selesai, bendera isFinalPlan berubah menjadi true.
Rencana saat ini dan awal
Di bawah setiap simpul AdaptiveSparkPlan akan ada paket awal (rencana sebelum menerapkan pengoptimalan AQE apa pun) dan paket saat ini atau akhir, tergantung pada apakah eksekusi telah selesai. Rencana saat ini akan berkembang seiring berjalannya eksekusi.
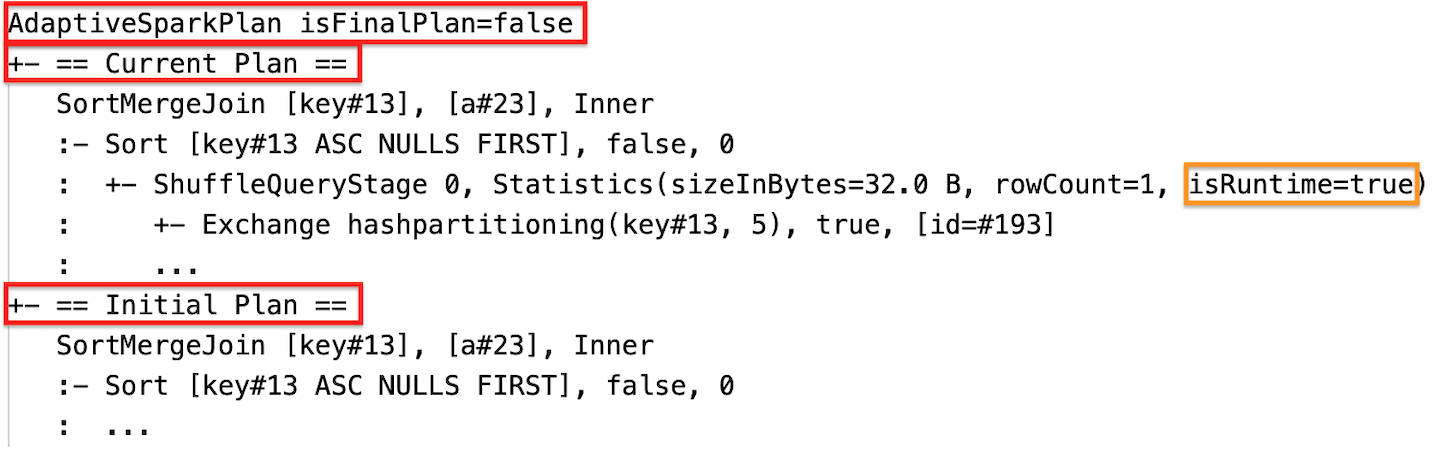
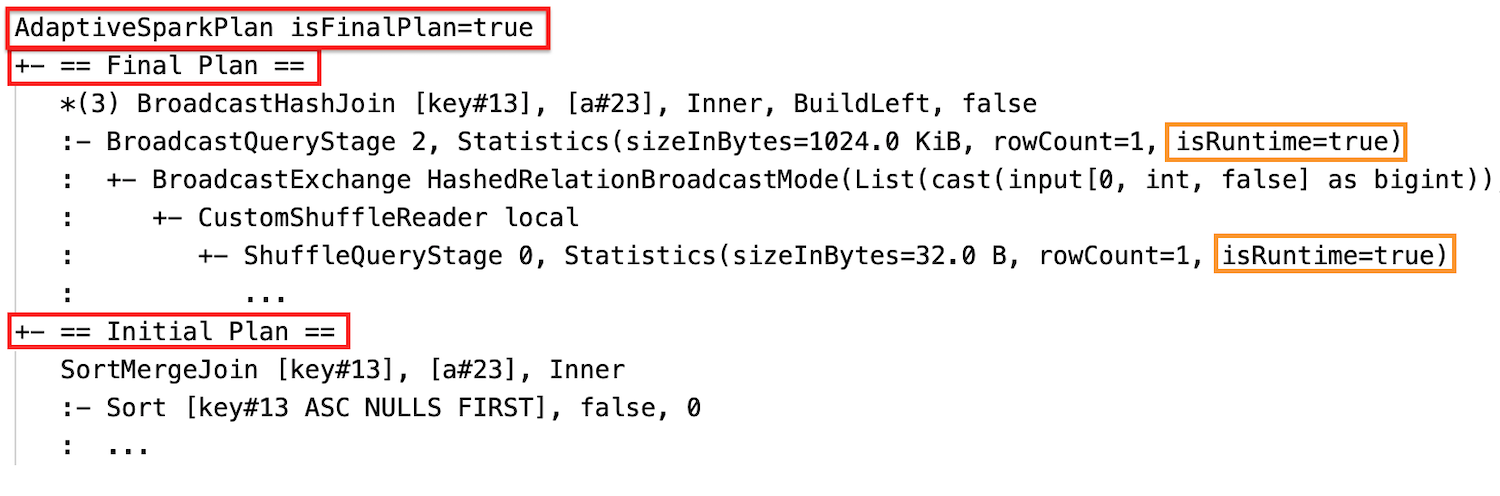
Statistik waktu proses
Setiap shuffle dan tahap penyiaran berisi statistik data.
Sebelum tahapan berjalan atau ketika tahapan berjalan, statistik adalah perkiraan waktu pengompilan, dan bendera isRuntime adalah false, misalnya: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Setelah eksekusi tahap selesai, statistiknya adalah yang dikumpulkan saat runtime, dan bendera isRuntime akan menjadi true, misalnya: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Berikut ini adalah contoh DataFrame.explain:
Sebelum eksekusi
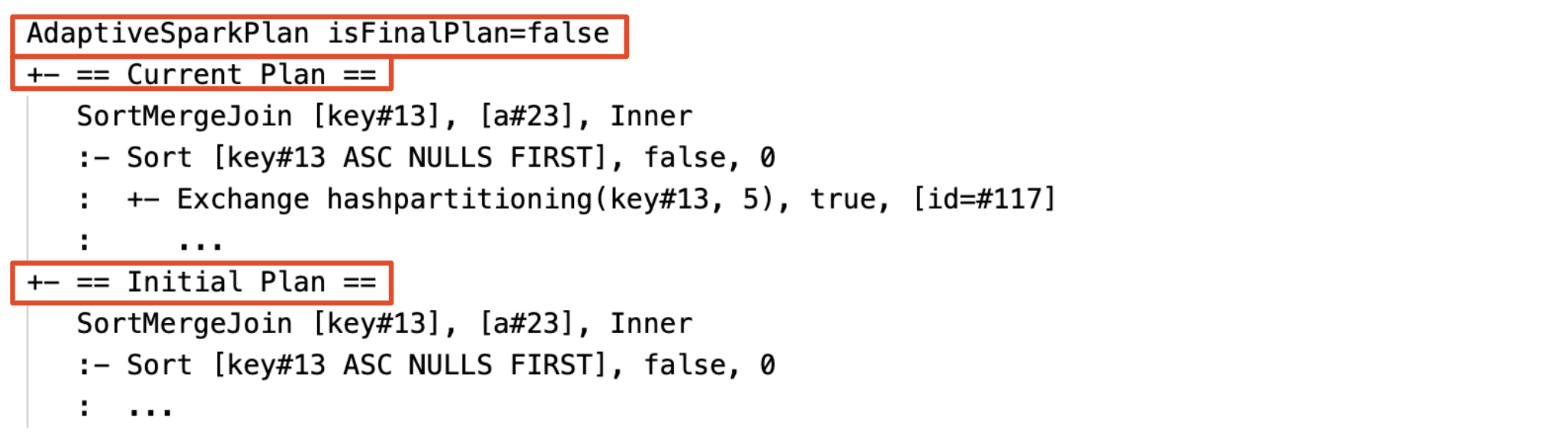
Selama eksekusi
Setelah eksekusi
SQL EXPLAIN
simpul AdaptiveSparkPlan
Kueri yang diterapkan AQE berisi satu atau beberapa simpul AdaptiveSparkPlan, biasanya sebagai simpul akar dari setiap kueri utama atau sub-kueri.
Tidak ada rencana saat ini
Karena SQL EXPLAIN tidak menjalankan kueri, rencana saat ini selalu sama dengan rencana awal dan tidak mencerminkan apa yang akhirnya dieksekusi oleh AQE.
Berikut ini adalah contoh penjelasan SQL:

Efektivitas
Rencana pemrosesan kueri akan berubah jika satu atau beberapa pengoptimalan AQE diimplementasikan. Efek pengoptimalan AQE ini ditunjukkan oleh perbedaan antara rencana saat ini dan akhir serta rencana awal dan node rencana tertentu dalam rencana saat ini dan terakhir.
Mengubah gabungan sortir secara dinamis menjadi gabungan hash siaran: simpul gabungan fisik yang berbeda antara rencana saat ini/akhir dan rencana awal
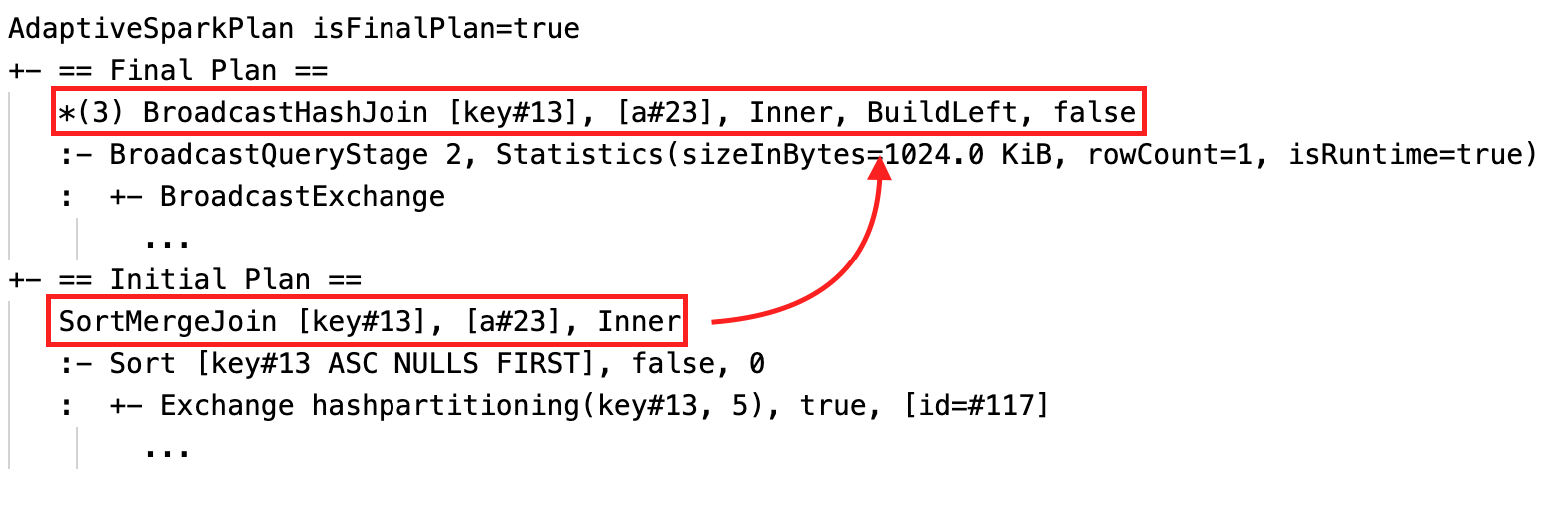
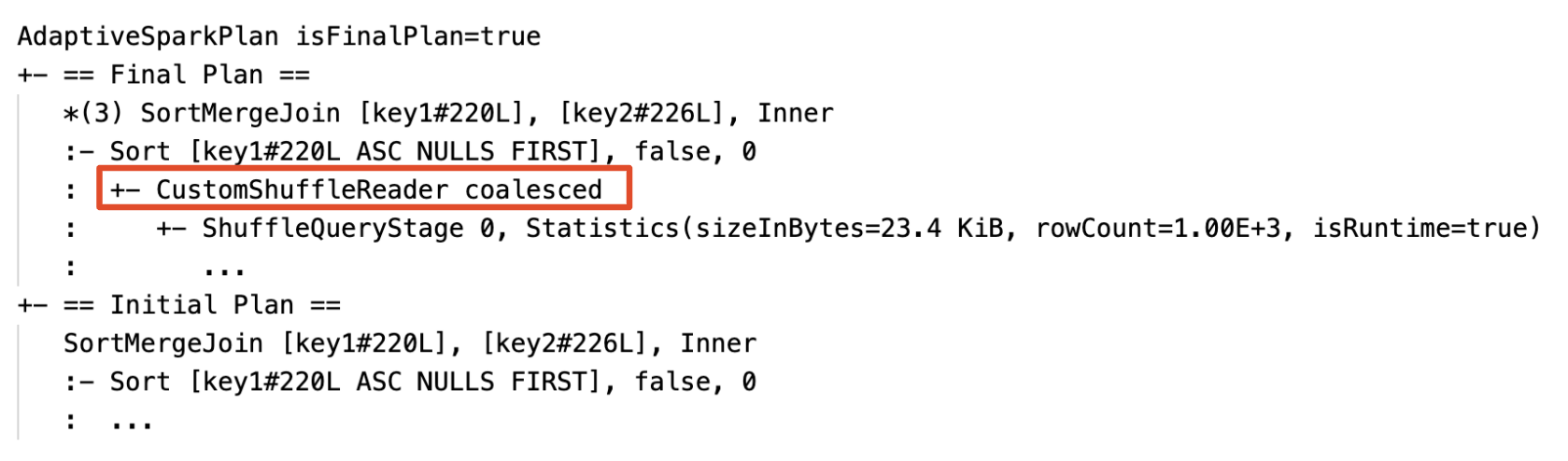
Gabungkan partisi secara dinamis: node
CustomShuffleReaderdengan propertiCoalesced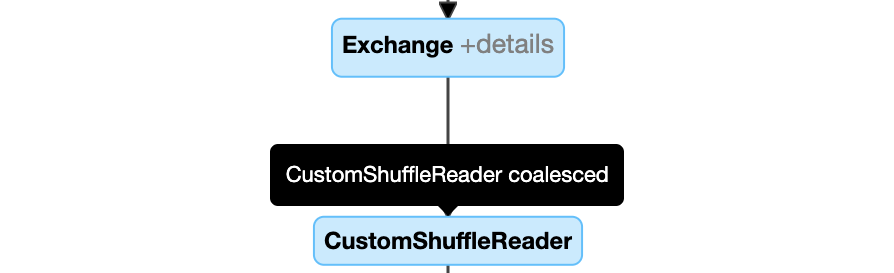
Menangani penggabungan miring secara dinamis: node
SortMergeJoindengan bidangisSkewbernilai benar.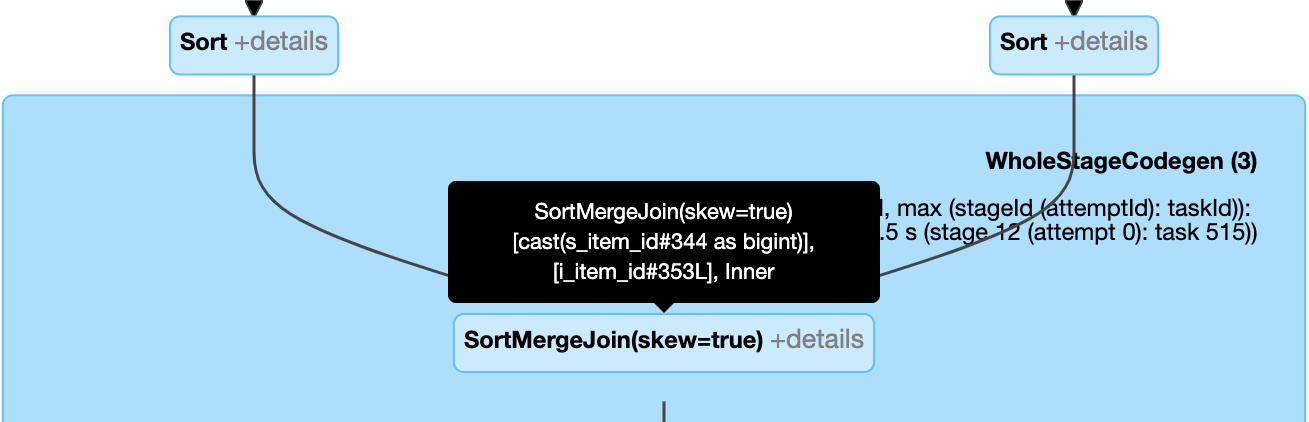
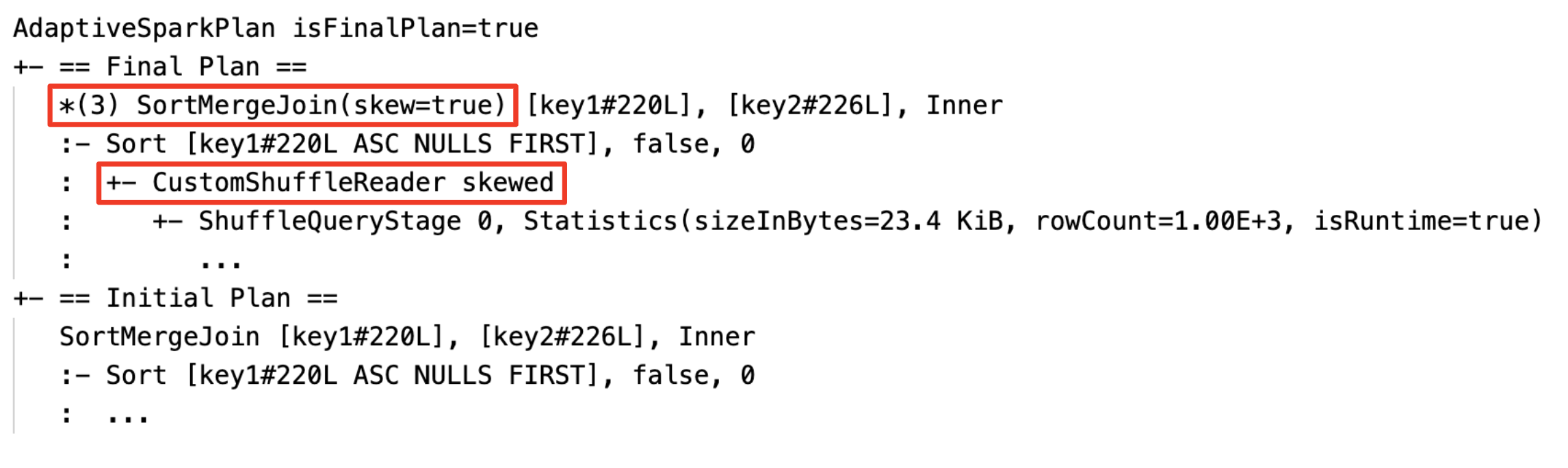
Mendeteksi dan menyebarkan hubungan kosong secara dinamis: bagian dari (atau seluruh) rencana digantikan oleh simpul LocalTableScan dengan bidang relasi yang kosong.
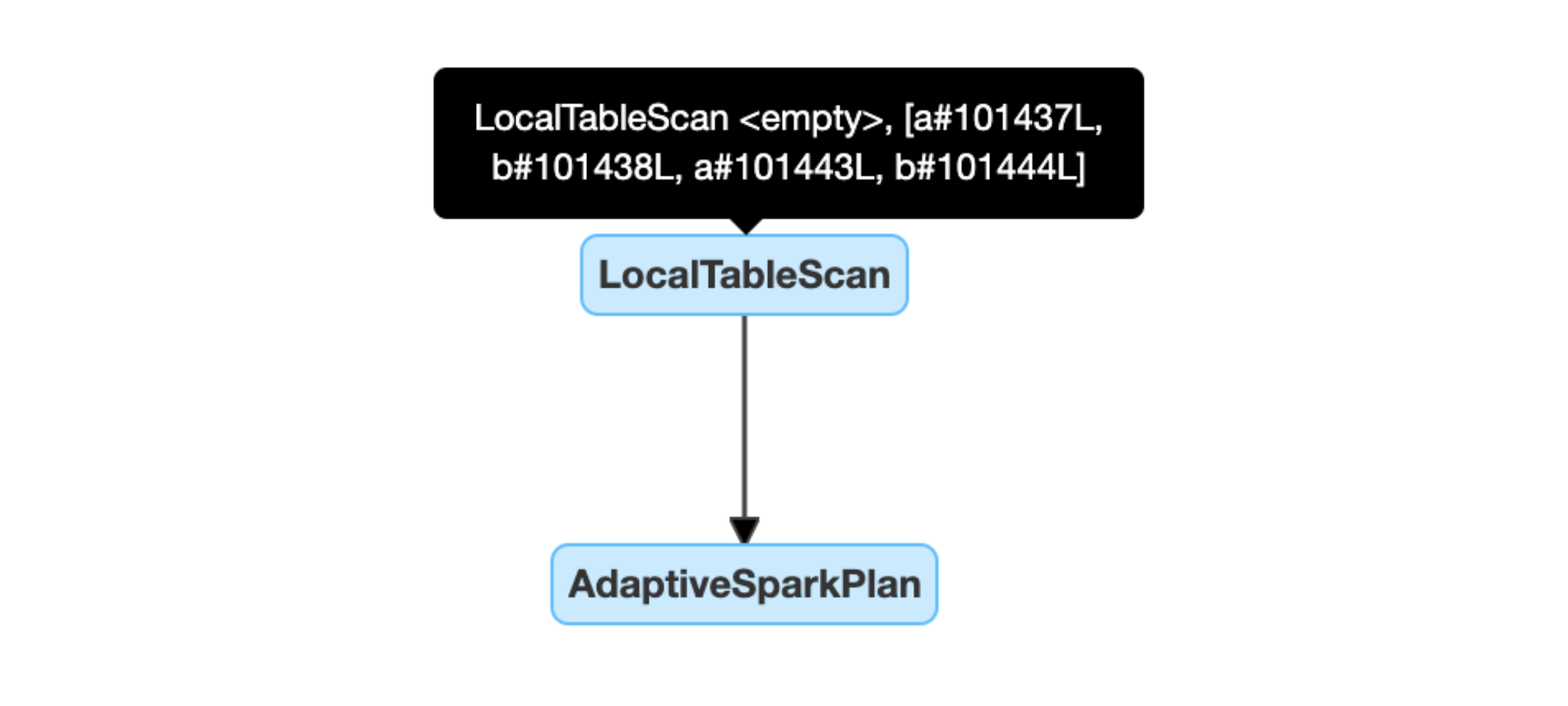
string pemindaian tabel lokal
Konfigurasi
Di bagian ini:
- Mengaktifkan dan menonaktifkan eksekusi kueri adaptif
- Aktifkan pengacakan otomatis yang dioptimalkan
- Mengubah secara dinamis gabungan pengurutan dan penyatuan menjadi penyatuan hash siaran
- Menggabungkan partisi secara dinamis
- Menangani skew join secara dinamis
- Mendeteksi dan menyebarluaskan hubungan kosong secara dinamis
Mengaktifkan dan menonaktifkan eksekusi kueri adaptif
| Harta benda |
|---|
|
spark.databricks.optimizer.adaptive.enabled Jenis: BooleanApakah akan mengaktifkan atau menonaktifkan eksekusi kueri adaptif. Nilai default: true |
Aktifkan pemutaran acak yang dioptimalkan otomatis
| Harta benda |
|---|
|
spark.sql.shuffle.partitions Jenis: IntegerJumlah default partisi yang akan digunakan saat mengatur ulang data untuk gabungan atau agregasi. Mengatur nilai auto memungkinkan pengacakan yang dioptimalkan secara otomatis, yang secara otomatis menentukan angka ini berdasarkan rencana kueri dan ukuran data input kueri.Catatan: Untuk Streaming Terstruktur, konfigurasi ini tidak dapat diubah antara pengulangan kueri dari lokasi titik pemeriksaan yang sama. Nilai default: 200 |
Mengubah gabungan sortir secara dinamis menjadi gabungan hash siaran
| Harta benda |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Jenis: Byte StringAmbang batas untuk mengaktifkan penggabungan siaran saat runtime. Nilai default: 30MB |
Gabungkan partisi secara dinamis
| Harta benda |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Jenis: BooleanApakah akan mengaktifkan atau menonaktifkan koalescing partisi. Nilai default: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Jenis: Byte StringUkuran target setelah penggabungan. Ukuran partisi yang digabung akan mendekati tetapi tidak lebih besar dari ukuran target ini. Nilai default: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Jenis: Byte StringUkuran minimum partisi setelah penggabungan. Ukuran partisi yang digabungkan tidak akan lebih kecil dari ukuran ini. Nilai default: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Jenis: IntegerJumlah minimum partisi setelah penggabungan. Tidak disarankan, karena pengaturan secara eksplisit menggantikan spark.sql.adaptive.coalescePartitions.minPartitionSize.Nilai default: 2x jumlah inti kluster |
Menangani penggabungan yang tidak seimbang secara dinamis
| Harta benda |
|---|
|
spark.sql.adaptive.skewJoin.diaktifkan Jenis: BooleanApakah akan mengaktifkan atau menonaktifkan penanganan gabungan data yang tidak seimbang. Nilai default: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Jenis: IntegerSebuah faktor yang ketika dikalikan dengan ukuran partisi median berperan dalam menentukan apakah partisi tersebut condong. Nilai default: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Jenis: Byte StringAmbang batas yang digunakan untuk menentukan apakah partisi berat sebelah. Nilai default: 256MB |
Suatu partisi tergolong condong apabila baik (partition size > skewedPartitionFactor * median partition size) maupun (partition size > skewedPartitionThresholdInBytes) merupakan true.
Mendeteksi dan menyebarkan hubungan kosong secara dinamis
| Harta benda |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Jenis: BooleanApakah akan mengaktifkan atau menonaktifkan propagasi relasi kosong dinamis. Nilai default: true |
Tanya jawab umum (FAQ)
Di bagian ini:
- Mengapa AQE tidak menyiarkan tabel gabungan kecil?
- Haruskah saya masih menggunakan petunjuk strategi siaran gabungan dengan AQE diaktifkan?
- Apa perbedaan antara petunjuk skew join dan optimalisasi skew join AQE? Mana yang harus saya gunakan?
- Mengapa AQE tidak secara otomatis menyesuaikan urutan penggabungan saya?
- Mengapa AQE tidak mendeteksi penyimpangan data saya?
Mengapa AQE tidak mendistribusikan tabel gabungan yang kecil?
Jika ukuran relasi yang diharapkan disiarkan memang berada di bawah ambang batas ini tetapi masih belum disiarkan:
- Periksa jenis penggabungan. Penyiaran tidak didukung untuk jenis penggabungan tertentu, misalnya, relasi kiri dari
LEFT OUTER JOINtidak dapat disiarkan. - Bisa juga terjadi bahwa relasi berisi banyak partisi kosong. Dalam hal ini, sebagian besar tugas dapat selesai dengan cepat menggunakan "sort merge join" atau mungkin dioptimalkan dengan penanganan "skew join". AQE menghindari mengubah gabungan sort merge menjadi gabungan hash siaran jika persentase partisi yang tidak kosong lebih rendah dari
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Haruskah saya masih menggunakan petunjuk strategi penggabungan siaran dengan AQE diaktifkan?
Ya. Gabungan siaran yang direncanakan secara statis biasanya lebih berkinerja daripada yang direncanakan secara dinamis oleh AQE karena AQE mungkin tidak beralih ke gabungan siaran sampai setelah melakukan pengacakan untuk kedua sisi gabungan (pada saat itu ukuran relasi aktual diperoleh). Jadi, menggunakan petunjuk siaran masih bisa menjadi pilihan yang baik jika Anda mengetahui kueri Anda dengan baik. AQE akan menghormati petunjuk kueri dengan cara yang sama seperti pengoptimalan statis, tetapi masih dapat menerapkan pengoptimalan dinamis yang tidak terpengaruh oleh petunjuk.
Apa perbedaan antara petunjuk skew join dan optimalisasi skew join AQE? Mana yang harus saya gunakan?
Disarankan untuk mengandalkan penanganan gabungan condong AQE daripada menggunakan petunjuk gabungan condong, karena gabungan condong AQE sepenuhnya otomatis dan secara umum berkinerja lebih baik daripada rekan petunjuk.
Mengapa AQE tidak menyesuaikan pemesanan gabungan saya secara otomatis?
Penyusunan ulang penyambungan dinamis bukan bagian dari AQE.
Mengapa AQE tidak mendeteksi penyimpangan data saya?
Ada dua kondisi ukuran yang harus dipenuhi bagi AQE untuk mendeteksi partisi sebagai partisi miring:
- Ukuran partisi lebih besar dari
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(default 256MB) - Ukuran partisi lebih besar dari ukuran median semua partisi yang dikali faktor partisi condong
spark.sql.adaptive.skewJoin.skewedPartitionFactor(default 5)
Selain itu, dukungan penanganan kemiringan terbatas untuk jenis penyambungan tertentu, misalnya, dalam LEFT OUTER JOIN, hanya kemiringan di sisi kiri yang dapat dioptimalkan.
Warisan
Istilah "Eksekusi Adaptif" telah ada sejak Spark 1.6, tetapi AQE baru di Spark 3.0 pada dasarnya berbeda. Dalam hal fungsionalitas, Spark 1.6 hanya menangani bagian "menggabungkan partisi secara dinamis". Dalam hal arsitektur teknis, AQE baru adalah kerangka perencanaan dinamis dan replanning kueri berdasarkan statistik runtime, yang mendukung berbagai pengoptimalan seperti yang telah kami jelaskan dalam artikel ini dan dapat diperluas untuk memungkinkan lebih banyak potensi pengoptimalan.