Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Databricks Runtime mendukung sumber data file biner, yang membaca file biner dan mengonversi setiap file menjadi satu catatan yang berisi konten mentah dan metadata file. Sumber data file biner menghasilkan DataFrame dengan kolom berikut dan mungkin kolom partisi:
-
path (StringType): Jalur lokasi file. -
modificationTime (TimestampType): Waktu modifikasi file. Dalam beberapa implementasi Hadoop FileSystem, parameter ini mungkin tidak tersedia dan nilainya akan diatur ke nilai default. -
length (LongType): Panjang file dalam byte. -
content (BinaryType): Isi dari file tersebut.
Untuk membaca file biner, tentukan sumber data format sebagai binaryFile.
Gambar
Databricks merekomendasikan agar Anda menggunakan sumber data file biner untuk memuat data gambar.
Fungsi Databricks display mendukung tampilan data gambar yang dimuat menggunakan sumber data biner.
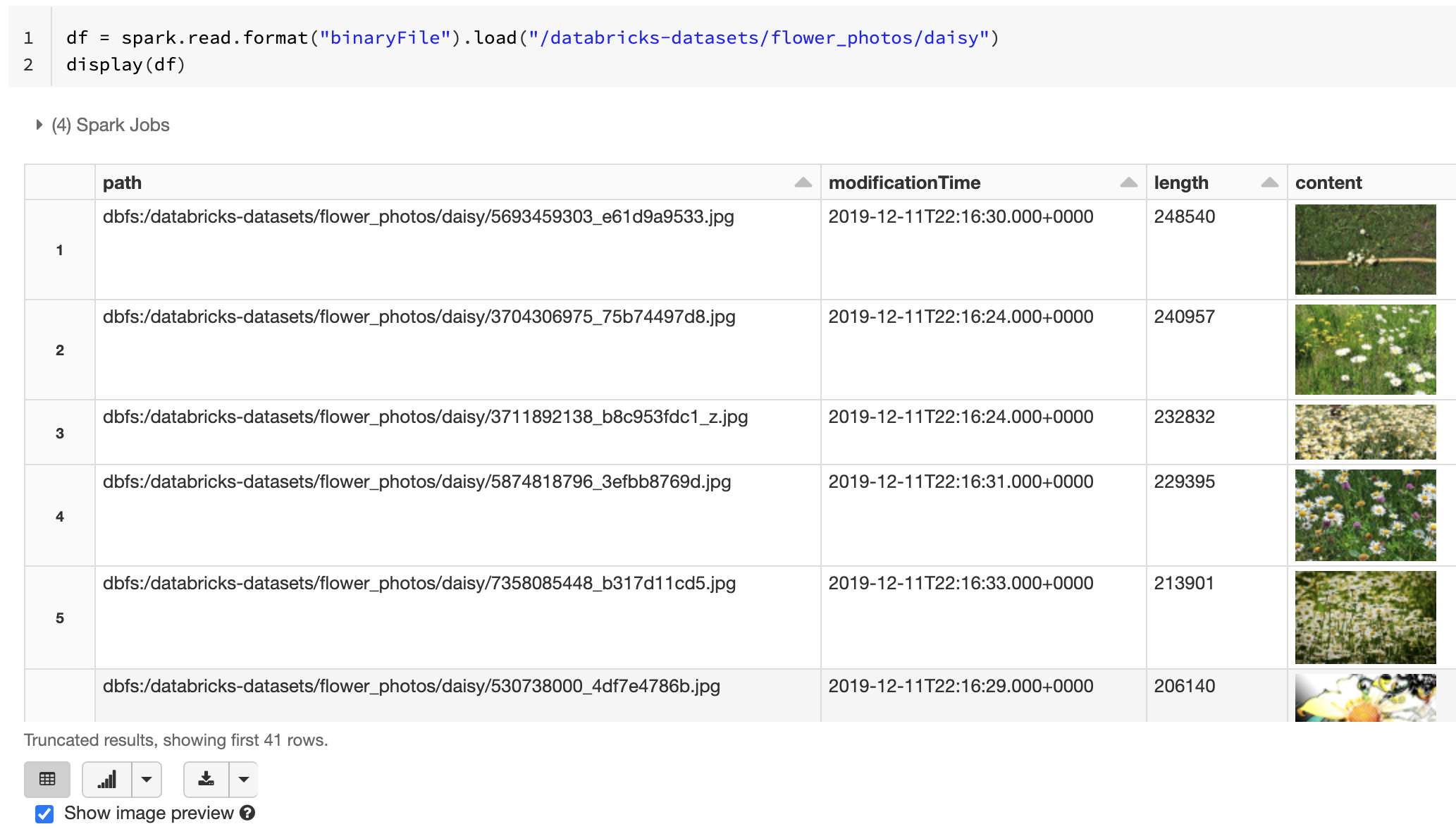
Jika semua file yang dimuat memiliki nama file dengan ekstensi gambar, pratinjau gambar diaktifkan secara otomatis:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
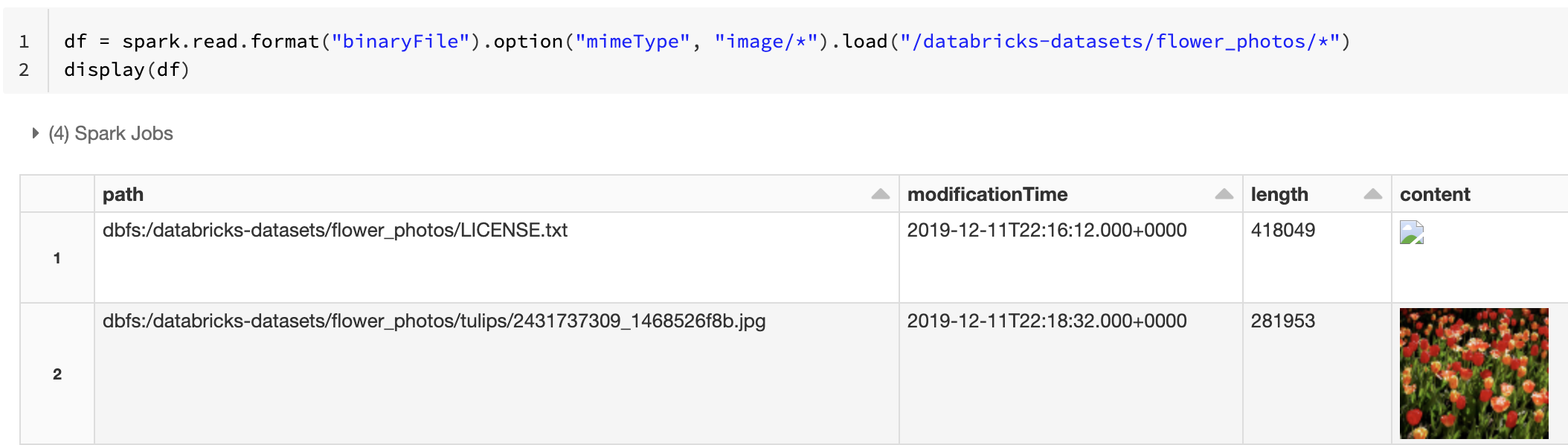
Atau, Anda dapat memaksa fungsionalitas pratinjau gambar dengan menggunakan opsi mimeType dengan nilai string "image/*" untuk membuat anotasi kolom biner. Gambar diterjemahkan berdasarkan informasi formatnya dalam konten biner. Jenis gambar yang didukung adalah bmp, gif, jpeg, dan png. File yang tidak didukung muncul sebagai ikon gambar yang rusak.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Lihat Solusi referensi untuk aplikasi gambar untuk alur kerja yang direkomendasikan untuk menangani data gambar.
Opsi
Untuk memuat file dengan jalur yang cocok dengan pola glob tertentu sambil menjaga perilaku penemuan partisi, Anda dapat menggunakan opsi pathGlobFilter. Kode berikut membaca semua file JPG dari direktori input dengan penemuan partisi:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Jika Anda ingin mengabaikan penemuan partisi dan mencari file secara rekursif di bawah direktori input, gunakan opsi recursiveFileLookup. Opsi ini mencari melalui direktori berlapis bahkan jika nama mereka tidak mengikuti skema penamaan partisi seperti date=2019-07-01.
Kode berikut membaca semua file JPG secara rekursif dari direktori input dan mengabaikan penemuan partisi:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
API serupa ada untuk Scala, Java, dan R.
Catatan
Untuk meningkatkan performa baca saat Anda memuat data kembali, Azure Databricks merekomendasikan untuk menyimpan data yang dimuat dari file biner menggunakan tabel Delta:
df.write.save("<path-to-table>")