Pengantar Alur Kerja Azure Databricks
Alur Kerja Azure Databricks mengatur alur pemrosesan data, pembelajaran mesin, dan analitik pada Databricks Data Intelligence Platform. Alur kerja memiliki layanan orkestrasi yang dikelola sepenuhnya yang terintegrasi dengan platform Databricks, termasuk Pekerjaan Azure Databricks untuk menjalankan kode non-interaktif di ruang kerja Azure Databricks dan Tabel Langsung Delta untuk membangun alur ETL yang andal dan dapat dipertahankan.
Untuk mempelajari selengkapnya tentang manfaat mengatur alur kerja Anda dengan platform Databricks, lihat Alur Kerja Databricks.
Contoh alur kerja Azure Databricks
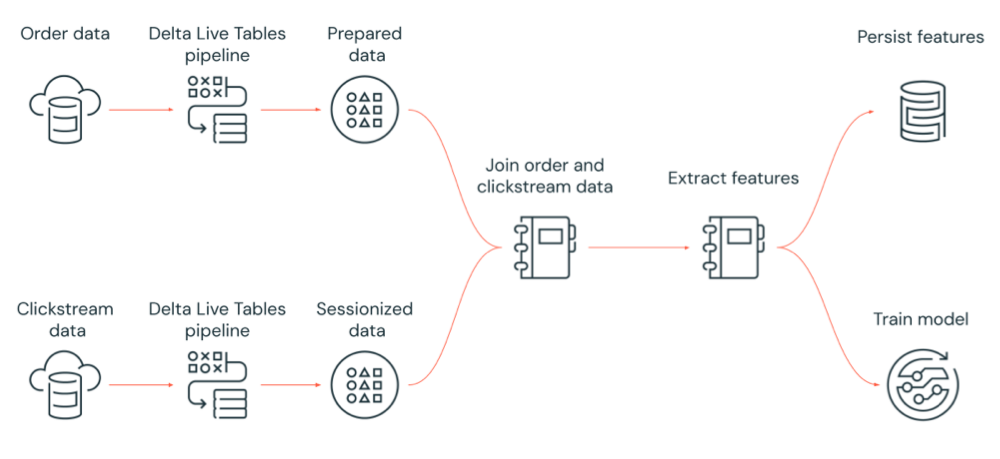
Diagram berikut mengilustrasikan alur kerja yang diorkestrasi oleh pekerjaan Azure Databricks untuk:
- Jalankan alur Delta Live Tables yang menyerap data clickstream mentah dari penyimpanan cloud, membersihkan dan menyiapkan data, melakukan sesi data, dan mempertahankan himpunan data sesi akhir ke Delta Lake.
- Jalankan alur Delta Live Tables yang menyerap data pesanan dari penyimpanan cloud, membersihkan dan mengubah data untuk diproses, dan mempertahankan himpunan data akhir ke Delta Lake.
- Gabungkan pesanan dan data clickstream sesi untuk membuat himpunan data baru untuk analisis.
- Ekstrak fitur dari data yang disiapkan.
- Lakukan tugas secara paralel untuk mempertahankan fitur dan melatih model pembelajaran mesin.
Apa itu Pekerjaan Azure Databricks?
Pekerjaan Azure Databricks adalah cara untuk menjalankan aplikasi pemrosesan dan analisis data Anda di ruang kerja Azure Databricks. Pekerjaan Anda dapat terdiri dari satu tugas atau dapat berupa alur kerja multitugas yang besar dengan ketergantungan yang kompleks. Azure Databricks mengelola orkestrasi tugas, manajemen kluster, pemantauan, dan pelaporan kesalahan untuk semua pekerjaan Anda. Anda dapat segera menjalankan pekerjaan Anda, secara berkala melalui sistem penjadwalan yang mudah digunakan, setiap kali file baru tiba di lokasi eksternal, atau terus-menerus untuk memastikan instans pekerjaan selalu berjalan. Anda juga dapat menjalankan pekerjaan secara interaktif di UI notebook.
Anda dapat membuat dan menjalankan pekerjaan menggunakan UI Pekerjaan, Databricks CLI, atau dengan memanggil JOBS API. Anda dapat memperbaiki dan menjalankan kembali pekerjaan yang gagal atau dibatalkan menggunakan UI atau API. Anda dapat memantau hasil eksekusi pekerjaan menggunakan UI, CLI, API, dan pemberitahuan (misalnya, email, tujuan webhook, atau pemberitahuan Slack).
Untuk mempelajari tentang menggunakan Databricks CLI, lihat Apa itu Databricks CLI?. Untuk mempelajari tentang menggunakan JOBS API, lihat JOBS API.
Bagian berikut mencakup fitur penting Azure Databricks Jobs.
Penting
- Ruang kerja dibatasi hingga 1000 eksekusi tugas bersamaan. Respons
429 Too Many Requestsdikembalikan saat Anda meminta eksekusi yang tidak dapat segera dimulai. - Jumlah pekerjaan yang dapat dibuat ruang kerja dalam satu jam dibatasi hingga 10000 (termasuk “pengiriman eksekusi”). Batas ini juga memengaruhi tugas yang dibuat oleh REST API dan alur kerja notebook.
Menerapkan pemrosesan dan analisis data dengan tugas pekerjaan
Anda menerapkan alur kerja pemrosesan dan analisis data menggunakan tugas. Pekerjaan terdiri dari satu atau beberapa tugas. Anda dapat membuat tugas pekerjaan yang menjalankan buku catatan, JARS, alur Delta Live Tables, atau aplikasi Python, Scala, Spark submit, dan Java. Tugas pekerjaan Anda juga dapat mengatur kueri, pemberitahuan, dan dasbor Databricks SQL untuk membuat analisis dan visualisasi, atau Anda dapat menggunakan tugas dbt untuk menjalankan transformasi dbt di alur kerja Anda. Aplikasi Legacy Spark Submit juga didukung.
Anda juga dapat menambahkan tugas ke pekerjaan yang menjalankan pekerjaan lain. Fitur ini memungkinkan Anda untuk memecah proses besar menjadi beberapa pekerjaan yang lebih kecil, atau membuat modul umum yang dapat digunakan kembali oleh beberapa pekerjaan.
Anda mengontrol urutan eksekusi tugas dengan menentukan dependensi antar tugas. Anda dapat mengonfigurasi tugas untuk dijalankan secara berurutan atau paralel.
Menjalankan pekerjaan secara interaktif, terus menerus, atau menggunakan pemicu pekerjaan
Anda dapat menjalankan pekerjaan Anda secara interaktif dari Antarmuka Pengguna Pekerjaan, API, atau CLI atau Anda dapat menjalankan pekerjaan berkelanjutan. Anda dapat membuat jadwal untuk menjalankan pekerjaan Anda secara berkala atau menjalankan pekerjaan Anda saat file baru tiba di lokasi eksternal seperti Amazon S3, penyimpanan Azure, atau penyimpanan Google Cloud.
Memantau kemajuan pekerjaan dengan pemberitahuan
Anda dapat menerima pemberitahuan saat pekerjaan atau tugas dimulai, selesai, atau gagal. Anda dapat mengirim pemberitahuan ke satu atau beberapa alamat email atau tujuan sistem (misalnya, tujuan webhook atau Slack). Lihat Menambahkan pemberitahuan email dan sistem untuk peristiwa pekerjaan.
Menjalankan pekerjaan Anda dengan sumber daya komputasi Azure Databricks
Kluster Databricks dan gudang SQL menyediakan sumber daya komputasi untuk pekerjaan Anda. Anda dapat menjalankan pekerjaan Anda dengan kluster pekerjaan, kluster tujuan semua, atau gudang SQL:
- Kluster pekerjaan adalah kluster khusus untuk tugas pekerjaan atau pekerjaan individual Anda. Pekerjaan Anda dapat menggunakan kluster pekerjaan yang dibagikan oleh semua tugas atau Anda dapat mengonfigurasi kluster untuk tugas individual saat membuat atau mengedit tugas. Kluster pekerjaan dibuat ketika pekerjaan atau tugas dimulai dan dihentikan ketika pekerjaan atau tugas berakhir.
- Kluster serba guna adalah kluster bersama yang dimulai dan dihentikan secara manual dan dapat dibagikan oleh beberapa pengguna dan pekerjaan.
Untuk mengoptimalkan penggunaan sumber daya, Databricks merekomendasikan penggunaan kluster pekerjaan untuk pekerjaan Anda. Untuk mengurangi waktu yang dihabiskan untuk menunggu startup kluster, pertimbangkan untuk menggunakan kluster serba guna. Lihat Menggunakan komputasi Azure Databricks dengan pekerjaan Anda.
Anda menggunakan gudang SQL untuk menjalankan tugas Databricks SQL seperti kueri, dasbor, atau pemberitahuan. Anda juga dapat menggunakan gudang SQL untuk menjalankan transformasi dbt dengan tugas dbt.
Langkah berikutnya
Untuk mulai menggunakan Pekerjaan Azure Databricks:
Buat pekerjaan Azure Databricks pertama Anda dengan mulai cepat.
Pelajari cara membuat dan menjalankan alur kerja dengan antarmuka pengguna Azure Databricks Jobs.
Pelajari cara menjalankan pekerjaan tanpa harus mengonfigurasi sumber daya komputasi Azure Databricks dengan alur kerja tanpa server.
Pelajari tentang memantau eksekusi pekerjaan di antarmuka pengguna Azure Databricks Jobs.
Pelajari tentang opsi konfigurasi untuk pekerjaan.
Pelajari selengkapnya tentang membangun, mengelola, dan memecahkan masalah alur kerja dengan Pekerjaan Azure Databricks:
- Pelajari cara mengomunikasikan informasi antar tugas dalam pekerjaan Azure Databricks dengan nilai tugas.
- Pelajari cara meneruskan konteks tentang pekerjaan yang dijalankan ke tugas pekerjaan dengan variabel parameter tugas.
- Pelajari cara mengonfigurasi tugas pekerjaan Anda untuk berjalan secara kondisional berdasarkan status dependensi tugas.
- Pelajari cara memecahkan masalah dan memperbaiki pekerjaan yang gagal .
- Dapatkan pemberitahuan saat pekerjaan Anda berjalan dimulai, selesai, atau gagal dengan pemberitahuan eksekusi pekerjaan.
- Picu pekerjaan Anda pada jadwal kustom atau jalankan pekerjaan berkelanjutan.
- Pelajari cara menjalankan pekerjaan Azure Databricks Anda saat data baru tiba dengan pemicu kedatangan file.
- Pelajari cara menggunakan sumber daya komputasi Databricks untuk menjalankan pekerjaan Anda.
- Pelajari tentang pembaruan pada JOBS API untuk mendukung pembuatan dan pengelolaan alur kerja dengan pekerjaan Azure Databricks.
- Gunakan panduan cara penggunaan dan tutorial untuk mempelajari selengkapnya tentang menerapkan alur kerja data dengan Azure Databricks Jobs.
Apa itu Tabel Langsung Delta?
Catatan
Tabel Langsung Delta memerlukan paket Premium. Hubungi tim akun Databricks Anda untuk informasi selengkapnya.
Delta Live Tables adalah kerangka kerja yang menyederhanakan pemrosesan data ETL dan streaming. Tabel Langsung Delta menyediakan penyerapan data yang efisien dengan dukungan bawaan untuk antarmuka Auto Loader, SQL, dan Python yang mendukung implementasi transformasi data deklaratif, dan dukungan untuk menulis data yang diubah ke Delta Lake. Anda menentukan transformasi yang akan dilakukan pada data, dan Delta Live Tables mengelola orkestrasi tugas, pengelolaan kluster, pemantauan, kualitas data, dan penanganan kesalahan.
Untuk memulai, lihat Apa itu Tabel Langsung Delta?.
Pekerjaan Azure Databricks dan Tabel Langsung Delta
Pekerjaan Azure Databricks dan Tabel Langsung Delta menyediakan kerangka kerja komprehensif untuk membangun dan menyebarkan alur kerja pemrosesan dan analisis data end-to-end.
Gunakan Tabel Langsung Delta untuk semua penyerapan dan transformasi data. Gunakan Pekerjaan Azure Databricks untuk mengatur beban kerja yang terdiri dari satu tugas atau beberapa tugas pemrosesan dan analisis data pada platform Databricks, termasuk penyerapan dan transformasi Tabel Langsung Delta.
Sebagai sistem orkestrasi alur kerja, Azure Databricks Jobs juga mendukung:
- Menjalankan pekerjaan secara terpicu, misalnya, menjalankan alur kerja sesuai jadwal.
- Analisis data melalui kueri SQL, pembelajaran mesin dan analisis data dengan notebook, skrip, atau pustaka eksternal, dan sebagainya.
- Menjalankan pekerjaan yang terdiri dari satu tugas, misalnya, menjalankan pekerjaan Apache Spark yang dikemas dalam JAR.
Orkestrasi alur kerja dengan Apache AirFlow
Meskipun Databricks merekomendasikan penggunaan Azure Databricks Jobs untuk mengatur alur kerja data, Anda juga dapat menggunakan Apache Airflow untuk mengelola dan menjadwalkan alur kerja data Anda. Dengan Airflow, Anda menentukan alur kerja Anda dalam file Python, dan Airflow mengelola penjadwalan dan menjalankan alur kerja. Lihat Mengatur pekerjaan Azure Databricks dengan Apache Airflow.
Orkestrasi alur kerja dengan Azure Data Factory
Azure Data Factory (ADF) adalah layanan integrasi data cloud yang memungkinkan Anda menyusun layanan penyimpanan, pergerakan, dan pemrosesan data ke dalam alur data otomatis. Anda dapat menggunakan ADF untuk mengatur pekerjaan Azure Databricks sebagai bagian dari alur ADF.
Untuk mempelajari cara menjalankan pekerjaan menggunakan aktivitas Web ADF, termasuk cara mengautentikasi ke Azure Databricks dari ADF, lihat Memanfaatkan orkestrasi pekerjaan Azure Databricks dari Azure Data Factory.
ADF juga menyediakan dukungan bawaan untuk menjalankan notebook Databricks, skrip Python, atau kode yang dipaketkan dalam JAR dalam alur ADF.
Untuk mempelajari cara menjalankan buku catatan Databricks di alur ADF, lihat Menjalankan buku catatan Databricks dengan aktivitas buku catatan Databricks di Azure Data Factory, diikuti dengan Mengubah data dengan menjalankan buku catatan Databricks.
Untuk mempelajari cara menjalankan skrip Python di alur ADF, lihat Mengubah data dengan menjalankan aktivitas Python di Azure Databricks.
Untuk mempelajari cara menjalankan kode yang dipaketkan dalam JAR dalam alur ADF, lihat Mengubah data dengan menjalankan aktivitas JAR di Azure Databricks.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk