Menggunakan Databricks SQL dalam pekerjaan Azure Databricks
Anda dapat menggunakan jenis tugas SQL dalam pekerjaan Azure Databricks, memungkinkan Anda membuat, menjadwalkan, mengoperasikan, dan memantau alur kerja yang menyertakan objek Databricks SQL seperti kueri, dasbor warisan, dan pemberitahuan. Misalnya, alur kerja Anda dapat menyerap data, menyiapkan data, melakukan analisis menggunakan kueri Databricks SQL, lalu menampilkan hasilnya di dasbor warisan.
Artikel ini menyediakan contoh alur kerja yang membuat dasbor warisan yang menampilkan metrik untuk kontribusi GitHub. Dalam contoh ini, Anda akan:
- Serap data GitHub menggunakan skrip Python dan REST API GitHub.
- Ubah data GitHub menggunakan alur Delta Live Tables.
- Memicu kueri Databricks SQL yang melakukan analisis pada data yang disiapkan.
- Tampilkan analisis di dasbor warisan.
Sebelum Anda memulai
Anda memerlukan hal berikut untuk menyelesaikan panduan ini:
- Token akses pribadi GitHub. Token ini harus memiliki izin repositori.
- Gudang SQL tanpa server atau gudang pro SQL. Lihat Jenis gudang SQL.
- Cakupan rahasia Databricks. Cakupan rahasia digunakan untuk menyimpan token GitHub dengan aman. Lihat Langkah 1: Simpan token GitHub secara rahasia.
Langkah 1: Simpan token GitHub dalam rahasia
Alih-alih kredensial hardcoding seperti token akses pribadi GitHub dalam pekerjaan, Databricks merekomendasikan penggunaan cakupan rahasia untuk menyimpan dan mengelola rahasia dengan aman. Perintah Databricks CLI berikut adalah contoh pembuatan cakupan rahasia dan menyimpan token GitHub dalam rahasia dalam cakupan tersebut:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- Ganti
<scope-namedengan nama cakupan rahasia Azure Databricks untuk menyimpan token. - Ganti
<token-key>dengan nama kunci untuk ditetapkan ke token. - Ganti
<token>dengan nilai token akses pribadi GitHub.
Langkah 2: Membuat skrip untuk mengambil data GitHub
Skrip Python berikut menggunakan GitHub REST API untuk mengambil data tentang penerapan dan kontribusi dari repositori GitHub. Argumen input menentukan repositori GitHub. Rekaman disimpan ke lokasi di DBFS yang ditentukan oleh argumen input lain.
Contoh ini menggunakan DBFS untuk menyimpan skrip Python, tetapi Anda juga dapat menggunakan folder Databricks Git atau file ruang kerja untuk menyimpan dan mengelola skrip.
Simpan skrip ini ke lokasi di disk lokal Anda:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()Unggah skrip ke DBFS:
- Buka halaman arahan Azure Databricks Anda dan klik
 Katalog di bar samping.
Katalog di bar samping. - Klik Telusuri DBFS.
- Di browser file DBFS, klik Unggah. Dialog Unggah Data ke DBFS muncul.
- Masukkan jalur di DBFS untuk menyimpan skrip, klik Letakkan file untuk diunggah, atau klik untuk menelusuri, dan pilih skrip Python.
- Klik Selesai.
- Buka halaman arahan Azure Databricks Anda dan klik
Langkah 3: Membuat alur Tabel Langsung Delta untuk memproses data GitHub
Di bagian ini, Anda membuat alur Delta Live Tables untuk mengonversi data GitHub mentah menjadi tabel yang dapat dianalisis oleh kueri Databricks SQL. Untuk membuat alur, lakukan langkah-langkah berikut:
Di bar samping, klik
 Baru dan pilih Buku Catatan dari menu. Dialog Buat Notebook muncul.
Baru dan pilih Buku Catatan dari menu. Dialog Buat Notebook muncul.Di Bahasa Default, masukkan nama dan pilih Python. Anda dapat meninggalkan Kluster diatur ke nilai default. Runtime Bahasa Umum Delta Live Tables membuat kluster sebelum menjalankan alur Anda.
Klik Buat.
Salin contoh kode Python dan tempelkan ke buku catatan baru Anda. Anda dapat menambahkan kode contoh ke satu sel buku catatan atau beberapa sel.
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )Di bar samping, klik
 Alur Kerja, klik tab Tabel Langsung Delta, dan klik Buat Alur.
Alur Kerja, klik tab Tabel Langsung Delta, dan klik Buat Alur. Beri nama alur, misalnya,
Transform GitHub data.Di bidang Pustaka buku catatan, masukkan jalur ke buku catatan Anda atau klik
 untuk memilih buku catatan.
untuk memilih buku catatan.Klik Tambahkan konfigurasi. Dalam kotak
Keyteks, masukkancommits-path. Dalam kotakValueteks, masukkan jalur DBFS tempat rekaman GitHub akan ditulis. Ini bisa menjadi jalur apa pun yang Anda pilih dan merupakan jalur yang sama dengan yang akan Anda gunakan saat mengonfigurasi tugas Python pertama saat Membuat alur kerja.Klik Tambahkan konfigurasi lagi. Dalam kotak
Keyteks, masukkancontribs-path. Dalam kotakValueteks, masukkan jalur DBFS tempat rekaman GitHub akan ditulis. Ini bisa menjadi jalur apa pun yang Anda pilih dan merupakan jalur yang sama dengan yang akan Anda gunakan saat mengonfigurasi tugas Python kedua saat Membuat alur kerja.Di bidang Target, masukkan database target, misalnya,
github_tables. Mengatur database target menerbitkan data output ke metastore dan diperlukan untuk kueri hilir yang menganalisis data yang dihasilkan oleh alur.Klik Simpan.
Langkah 4: Membuat alur kerja untuk menyerap dan mengubah data GitHub
Sebelum menganalisis dan memvisualisasikan data GitHub dengan Databricks SQL, Anda perlu menyerap dan menyiapkan data. Untuk membuat alur kerja untuk menyelesaikan tugas-tugas ini, lakukan langkah-langkah berikut:
Membuat pekerjaan Azure Databricks dan menambahkan tugas pertama
Buka halaman arahan Azure Databricks Anda dan lakukan salah satu hal berikut ini:
- Di bilah samping, klik Alur Kerja dan klik .

- Di bar samping, klik Baru dan pilih Pekerjaan dari menu.
- Di bilah samping, klik
Dalam kotak dialog tugas yang muncul di tab Tugas, ganti Tambahkan nama untuk pekerjaan Anda... dengan nama pekerjaan Anda, misalnya,
GitHub analysis workflow.Di Nama tugas, masukkan nama untuk tugas, misalnya,
get_commits.Di Jenis, pilih skrip Python.
Di Sumber, pilih DBFS / S3.
Di Jalur, masukkan jalur ke skrip di DBFS.
Di Parameter, masukkan argumen berikut untuk skrip Python:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Ganti
<owner>dengan nama pemilik repositori. Misalnya, untuk mengambil rekaman darigithub.com/databrickslabs/overwatchrepositori, masukkandatabrickslabs. - Ganti
<repo>dengan nama repositori, misalnya,overwatch. - Ganti
<DBFS-output-dir>dengan jalur di DBFS untuk menyimpan rekaman yang diambil dari GitHub. - Ganti
<scope-name>dengan nama cakupan rahasia yang Anda buat untuk menyimpan token GitHub. - Ganti
<github-token-key>dengan nama kunci yang Anda tetapkan ke token GitHub.
- Ganti
Klik Simpan tugas.
Menambahkan tugas lain
Klik
 di bawah tugas yang baru saja Anda buat.
di bawah tugas yang baru saja Anda buat.Di Nama tugas, masukkan nama untuk tugas, misalnya,
get_contributors.Di Jenis, pilih jenis tugas skrip Python.
Di Sumber, pilih DBFS / S3.
Di Jalur, masukkan jalur ke skrip di DBFS.
Di Parameter, masukkan argumen berikut untuk skrip Python:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Ganti
<owner>dengan nama pemilik repositori. Misalnya, untuk mengambil rekaman darigithub.com/databrickslabs/overwatchrepositori, masukkandatabrickslabs. - Ganti
<repo>dengan nama repositori, misalnya,overwatch. - Ganti
<DBFS-output-dir>dengan jalur di DBFS untuk menyimpan rekaman yang diambil dari GitHub. - Ganti
<scope-name>dengan nama cakupan rahasia yang Anda buat untuk menyimpan token GitHub. - Ganti
<github-token-key>dengan nama kunci yang Anda tetapkan ke token GitHub.
- Ganti
Klik Simpan tugas.
Menambahkan tugas untuk mengubah data
- Klik di bawah tugas yang baru saja Anda buat.
- Di Nama tugas, masukkan nama untuk tugas, misalnya,
transform_github_data. - Di Jenis, pilih alur Tabel Langsung Delta dan masukkan nama untuk tugas tersebut.
- Di Alur, pilih alur yang dibuat di Langkah 3: Buat alur Tabel Langsung Delta untuk memproses data GitHub.
- Klik Buat.
Langkah 5: Jalankan alur kerja transformasi data
Klik  untuk menjalankan alur kerja. Untuk melihat detail eksekusi, klik tautan di kolom Waktu mulai untuk eksekusi dalam tampilan eksekusi pekerjaan. Klik pada setiap tugas untuk melihat detail untuk tugas yang dijalankan.
untuk menjalankan alur kerja. Untuk melihat detail eksekusi, klik tautan di kolom Waktu mulai untuk eksekusi dalam tampilan eksekusi pekerjaan. Klik pada setiap tugas untuk melihat detail untuk tugas yang dijalankan.
Langkah 6: (Opsional) Untuk melihat data output setelah alur kerja selesai, lakukan langkah-langkah berikut:
- Dalam tampilan detail eksekusi, klik tugas Delta Live Tables.
- Di panel Detail eksekusi tugas, klik nama alur di bawah Alur. Halaman Detail alur ditampilkan.
commits_by_authorPilih tabel di DAG alur.- Klik nama tabel di samping Metastore di panel commits_by_author . Halaman Penjelajah Katalog terbuka.
Di Catalog Explorer, Anda bisa menampilkan skema tabel, data sampel, dan detail lainnya untuk data. Ikuti langkah-langkah yang sama untuk menampilkan data untuk github_contributors_raw tabel.
Langkah 7: Hapus data GitHub
Dalam aplikasi dunia nyata, Anda mungkin terus menyerap dan memproses data. Karena contoh ini mengunduh dan memproses seluruh himpunan data, Anda harus menghapus data GitHub yang sudah diunduh untuk mencegah kesalahan saat menjalankan kembali alur kerja. Untuk menghapus data yang diunduh, lakukan langkah-langkah berikut:
Buat buku catatan baru dan masukkan perintah berikut ini di sel pertama:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)Ganti
<commits-path>dan<contributors-path>dengan jalur DBFS yang Anda konfigurasi saat membuat tugas Python.Klik
 dan pilih Jalankan Sel.
dan pilih Jalankan Sel.
Anda juga bisa menambahkan buku catatan ini sebagai tugas dalam alur kerja.
Langkah 8: Buat kueri Databricks SQL
Setelah menjalankan alur kerja dan membuat tabel yang diperlukan, buat kueri untuk menganalisis data yang disiapkan. Untuk membuat contoh kueri dan visualisasi, lakukan langkah-langkah berikut:
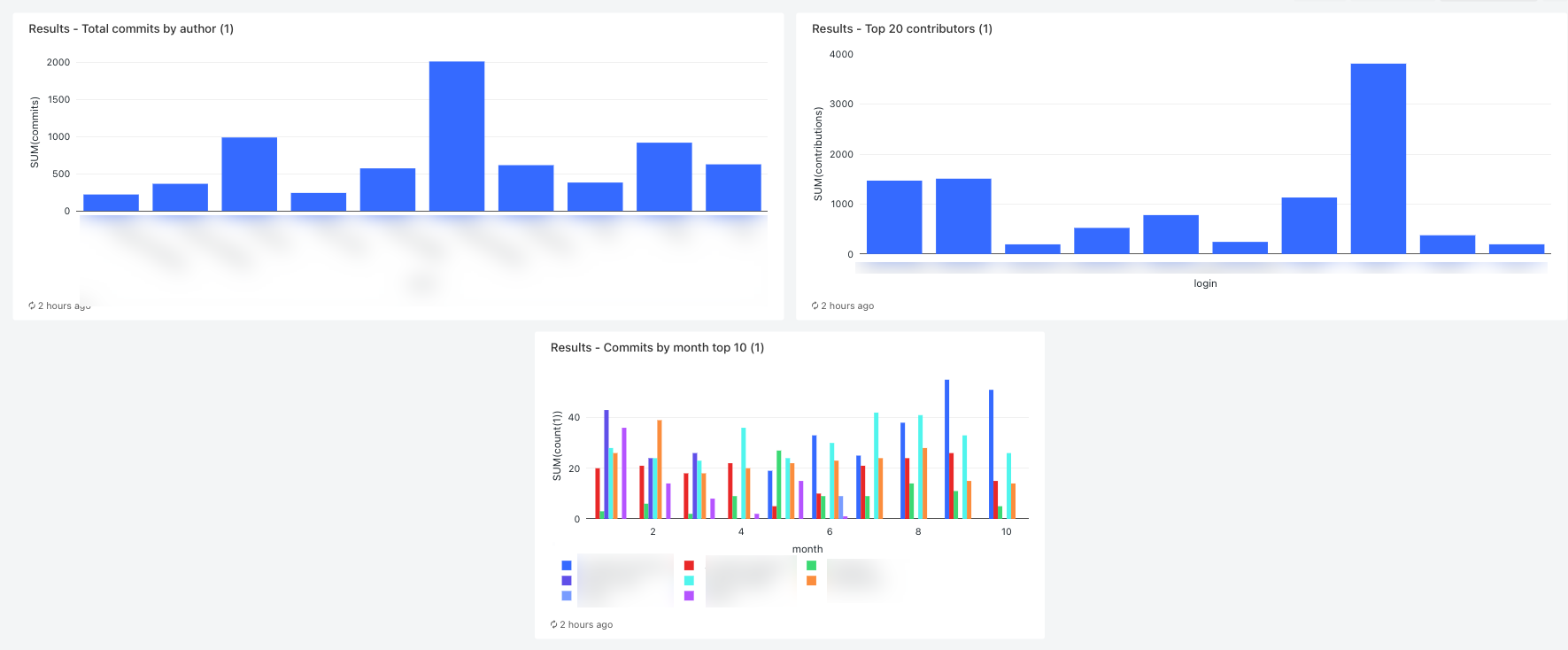
Menampilkan 10 kontributor teratas menurut bulan
Klik ikon di bawah logo
 Databricks di bar samping dan pilih SQL.
Databricks di bar samping dan pilih SQL.Klik Buat kueri untuk membuka editor kueri Databricks SQL.
Pastikan katalog diatur ke hive_metastore. Klik default di samping hive_metastore dan atur database ke nilai Target yang Anda tetapkan di alur Tabel Langsung Delta.
Di tab Kueri Baru, masukkan kueri berikut ini:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, nameKlik tab Kueri baru dan ganti nama kueri, misalnya,
Commits by month top 10 contributors.Secara bawaan, hasilnya ditampilkan sebagai tabel. Untuk mengubah cara data divisualisasikan, misalnya, menggunakan bagan batang, di panel Hasil klik
 dan klik Edit.
dan klik Edit. Di Jenis visualisasi, pilih Bilah.
Di kolom X, pilih bulan.
Di kolom Y, pilih hitungan(1).
Di Kelompokkan menurut, pilih nama.
Klik Simpan.
Menampilkan 20 kontributor teratas
Klik + > Buat kueri baru dan pastikan katalog diatur ke hive_metastore. Klik default di samping hive_metastore dan atur database ke nilai Target yang Anda tetapkan di alur Tabel Langsung Delta.
Masukkan kueri berikut:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20Klik tab Kueri baru dan ganti nama kueri, misalnya,
Top 20 contributors.Untuk mengubah visualisasi dari tabel default, di panel Hasil , klik
dan klik Edit.Di Jenis visualisasi, pilih Bilah.
Di kolom X, pilih masuk.
Di kolom Y, pilih kontribusi.
Klik Simpan.
Menampilkan total penerapan menurut penulis
Klik + > Buat kueri baru dan pastikan katalog diatur ke hive_metastore. Klik default di samping hive_metastore dan atur database ke nilai Target yang Anda tetapkan di alur Tabel Langsung Delta.
Masukkan kueri berikut:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10Klik tab Kueri baru dan ganti nama kueri, misalnya,
Total commits by author.Untuk mengubah visualisasi dari tabel default, di panel Hasil , klik
dan klik Edit.Di Jenis visualisasi, pilih Bilah.
Di kolom X, pilih nama.
Di kolom Y, pilih penerapan.
Klik Simpan.
Langkah 9: Membuat dasbor
- Di bar samping, klik
 Dasbor
Dasbor - Klik Buat dasbor.
- Masukkan nama untuk dasbor, misalnya,
GitHub analysis. - Untuk setiap kueri dan visualisasi yang dibuat di Langkah 8: Buat kueri Databricks SQL, klik Tambahkan > Visualisasi dan pilih setiap visualisasi.
Langkah 10: Tambahkan tugas SQL ke alur kerja
Untuk menambahkan tugas kueri baru ke alur kerja yang Anda buat di Membuat pekerjaan Azure Databricks dan menambahkan tugas pertama, untuk setiap kueri yang Anda buat di Langkah 8: Buat kueri Databricks SQL:
- Klik Alur Kerja di bilah samping.
- Di kolom Nama, klik nama pekerjaan.
- Klik tab Tugas.
- Klik di bawah tugas terakhir.
- Masukkan nama untuk tugas, di Ketik pilih SQL, dan di tugas SQL pilih Kueri.
- Pilih kueri dalam kueri SQL.
- Di gudang SQL, pilih gudang SQL tanpa server atau gudang pro SQL untuk menjalankan tugas.
- Klik Buat.
Langkah 11: Menambahkan tugas dasbor
- Klik di bawah tugas terakhir.
- Masukkan nama untuk tugas, di Jenis, pilih SQL, dan di tugas SQL pilih Dasbor warisan.
- Pilih dasbor yang dibuat di Langkah 9: Buat dasbor.
- Di gudang SQL, pilih gudang SQL tanpa server atau gudang pro SQL untuk menjalankan tugas.
- Klik Buat.
Langkah 12: Jalankan alur kerja lengkap
Untuk menjalankan alur kerja, klik . Untuk melihat detail eksekusi, klik tautan di kolom Waktu mulai untuk eksekusi dalam tampilan eksekusi pekerjaan.
Langkah 13: Lihat hasilnya
Untuk melihat hasil saat eksekusi selesai, klik tugas dasbor akhir dan klik nama dasbor di bawah dasbor SQL di panel kanan.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk