Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menunjukkan kepada Anda cara mengevaluasi jawaban aplikasi obrolan terhadap serangkaian jawaban yang benar atau ideal (dikenal sebagai kebenaran dasar). Setiap kali Anda mengubah aplikasi obrolan dengan cara yang memengaruhi jawaban, jalankan evaluasi untuk membandingkan perubahan. Aplikasi demo ini menawarkan alat yang dapat Anda gunakan saat ini untuk mempermudah menjalankan evaluasi.
Dengan mengikuti instruksi dalam artikel ini, Anda:
- Gunakan permintaan sampel yang disediakan yang disesuaikan dengan domain subjek. Perintah ini sudah ada di repositori.
- Hasilkan contoh pertanyaan pengguna dan jawaban kebenaran dasar dari dokumen Anda sendiri.
- Jalankan evaluasi dengan menggunakan permintaan sampel dengan pertanyaan pengguna yang dihasilkan.
- Tinjau analisis jawaban.
Catatan
Artikel ini menggunakan satu atau beberapa templat aplikasi AI sebagai dasar untuk contoh dan panduan dalam artikel. Templat aplikasi AI memberi Anda implementasi referensi yang terawat dengan baik yang mudah disebarkan. Ini membantu memastikan titik awal berkualitas tinggi untuk aplikasi AI Anda.
Ikhtisar arsitektur
Komponen utama arsitektur meliputi:
- Aplikasi obrolan yang dihosting Azure: Aplikasi obrolan berjalan di Azure App Service.
- Protokol Obrolan Microsoft AI: Protokol ini menyediakan kontrak API standar di seluruh solusi dan bahasa AI. Aplikasi chat mematuhi Protokol Chat AI Microsoft, yang memungkinkan aplikasi evaluasi dijalankan pada aplikasi chat apa pun yang mematuhi protokol tersebut.
- Pencarian Azure AI: Aplikasi chat menggunakan Pencarian Azure AI untuk menyimpan data dari dokumen Anda sendiri.
- Contoh generator pertanyaan: Alat ini dapat menghasilkan banyak pertanyaan untuk setiap dokumen bersama dengan jawaban kebenaran dasar. Semakin banyak pertanyaan, semakin lama evaluasinya.
- Evaluator: Alat ini menjalankan contoh pertanyaan dan permintaan terhadap aplikasi obrolan dan mengembalikan hasilnya.
- Alat ulasan: Alat ini meninjau hasil evaluasi.
- Alat Pembanding: Alat ini membandingkan jawaban antar penilaian.
Saat Anda menyebarkan evaluasi ini ke Azure, endpoint Azure OpenAI Service dibuat untuk model GPT-4 dengan kapasitas tersendiri. Saat Anda mengevaluasi aplikasi obrolan, penting bahwa evaluator memiliki sumber daya Azure OpenAI sendiri dengan menggunakan GPT-4 dengan kapasitasnya sendiri.
Prasyarat
Langganan Azure. Buat satu secara gratis
Meluncurkan aplikasi obrolan.
Aplikasi obrolan ini memuat data ke sumber daya Pencarian Azure AI. Sumber daya ini diperlukan agar aplikasi evaluasi berfungsi. Jangan selesaikan bagian Bersihkan sumber daya dari prosedur sebelumnya.
Anda memerlukan informasi sumber daya Azure berikut dari penyebaran tersebut, yang disebut sebagai aplikasi obrolan dalam artikel ini:
- URI API Chat: Endpoint backend layanan yang ditampilkan di akhir proses
azd up. - Pencarian Azure AI Nilai berikut diperlukan:
- Nama sumber daya: Nama sumber daya Pencarian Azure AI, ditampilkan sebagai
Search serviceselama prosesazd up. - Nama indeks: Nama indeks Pencarian Azure AI tempat dokumen Anda disimpan. Anda dapat menemukan nama indeks di portal Microsoft Azure untuk layanan Pencarian.
- Nama sumber daya: Nama sumber daya Pencarian Azure AI, ditampilkan sebagai
URL API Obrolan memungkinkan evaluasi mengirim permintaan melalui aplikasi backend Anda. Informasi Pencarian Azure AI memungkinkan skrip evaluasi menggunakan deployment yang sama dengan backend Anda, yang telah dimuat dengan dokumen.
Setelah mengumpulkan informasi ini, Anda tidak perlu menggunakan lingkungan pengembangan aplikasi obrolan lagi. Artikel ini merujuk ke aplikasi obrolan beberapa kali untuk menunjukkan cara aplikasi Evaluasi menggunakannya. Jangan hapus sumber daya aplikasi obrolan hingga Anda menyelesaikan semua langkah dalam artikel ini.
- URI API Chat: Endpoint backend layanan yang ditampilkan di akhir proses
Lingkungan kontainer pengembangan tersedia dengan semua dependensi yang diperlukan untuk menyelesaikan artikel ini. Anda dapat menjalankan kontainer pengembangan di GitHub Codespaces (di browser) atau secara lokal menggunakan Visual Studio Code.
- Akun GitHub
Membuka lingkungan pengembangan
Ikuti petunjuk ini untuk menyiapkan lingkungan pengembangan yang telah dikonfigurasi sebelumnya dengan semua dependensi yang diperlukan untuk menyelesaikan artikel ini. Atur ruang kerja monitor Anda sehingga Anda dapat melihat dokumentasi ini dan lingkungan pengembangan secara bersamaan.
Artikel ini diuji menggunakan wilayah switzerlandnorth untuk penerapan evaluasi.
GitHub Codespaces menjalankan kontainer pengembangan yang dikelola oleh GitHub dengan Visual Studio Code untuk Web sebagai antarmuka pengguna. Gunakan GitHub Codespaces untuk lingkungan pengembangan termudah. Dilengkapi dengan alat pengembang dan dependensi yang tepat yang telah diinstal sebelumnya untuk menyelesaikan artikel ini.
Penting
Semua akun GitHub dapat menggunakan GitHub Codespaces hingga 60 jam gratis setiap bulan dengan dua instans inti. Untuk informasi selengkapnya, lihat penyimpanan bulanan yang disertakan dan jam inti GitHub Codespaces.
Mulai proses untuk membuat ruang kode GitHub baru di
maincabang repositori GitHub Azure-Samples/ai-rag-chat-evaluator .Untuk menampilkan lingkungan pengembangan dan dokumentasi yang tersedia secara bersamaan, klik kanan tombol berikut, dan pilih Buka tautan di jendela baru.

Pada halaman Buat codespace , tinjau pengaturan konfigurasi codespace, lalu pilih Buat codespace baru.
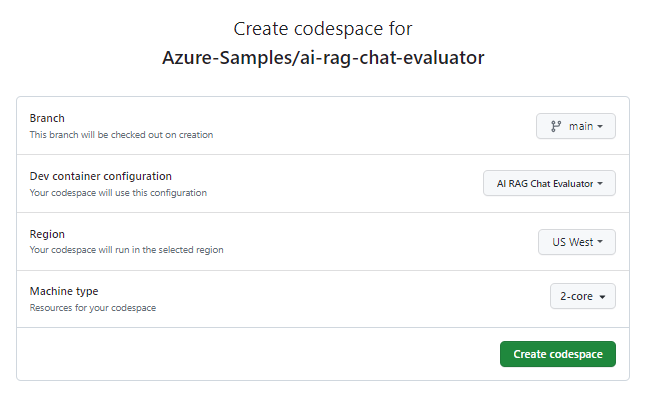
Tunggu hingga Codespace berjalan. Proses startup ini dapat memakan waktu beberapa menit.
Di terminal di bagian bawah layar, masuk ke Azure dengan Azure Developer CLI:
azd auth login --use-device-codeSalin kode dari terminal lalu tempelkan ke browser. Ikuti instruksi untuk mengautentikasi dengan akun Azure Anda.
Provisikan sumber daya Azure yang diperlukan, Azure OpenAI Service, untuk aplikasi evaluasi:
azd upPerintah ini
AZDtidak menyebarkan aplikasi evaluasi, tetapi membuat sumber daya Azure OpenAI dengan penyebaran yang diperlukanGPT-4untuk menjalankan evaluasi di lingkungan pengembangan lokal.
Tugas yang tersisa dalam artikel ini berlangsung dalam konteks kontainer pengembangan ini.
Nama repositori GitHub muncul di bilah pencarian. Indikator visual ini membantu Anda membedakan aplikasi evaluasi dari aplikasi obrolan. Repositori ini ai-rag-chat-evaluator disebut sebagai aplikasi evaluasi dalam artikel ini.

Menyiapkan nilai lingkungan dan informasi konfigurasi
Perbarui nilai lingkungan dan informasi konfigurasi dengan informasi yang Anda kumpulkan selama Prasyarat untuk aplikasi evaluasi.
Buat
.envfile berdasarkan.env.sample.cp .env.sample .envJalankan perintah ini untuk mendapatkan nilai yang diperlukan untuk
AZURE_OPENAI_EVAL_DEPLOYMENTdanAZURE_OPENAI_SERVICEdari grup sumber daya yang Anda sebarkan. Tempelkan nilai-nilai tersebut ke.envdalam file.azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICETambahkan nilai-nilai berikut dari aplikasi obrolan ke dalam file
.envuntuk instance Pencarian Azure AI, yang Anda kumpulkan di bagian Prasyarat.AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Menggunakan Protokol Obrolan Microsoft AI untuk informasi konfigurasi
Aplikasi obrolan dan aplikasi evaluasi sama-sama menerapkan spesifikasi Protokol Obrolan Microsoft AI, sebuah kontrak API antarmuka AI yang bersifat open-source, berbasis cloud, dan tidak bergantung pada bahasa, yang digunakan untuk konsumsi dan evaluasi. Saat klien dan titik akhir tingkat menengah mematuhi spesifikasi API ini, Anda dapat secara konsisten menggunakan dan menjalankan evaluasi pada backend AI Anda.
Buat file baru bernama
my_config.jsondan salin konten berikut ke dalamnya:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Skrip evaluasi membuat
my_resultsfolder.Objek
overridesberisi pengaturan konfigurasi apa pun yang diperlukan untuk aplikasi. Setiap aplikasi menentukan sekumpulan properti pengaturannya sendiri.Gunakan tabel berikut untuk memahami arti properti pengaturan yang dikirim ke aplikasi obrolan.
Pengaturan properti Deskripsi semantic_rankerApakah akan menggunakan pemeringkat semantik, model yang memberi peringkat ulang pada hasil pencarian berdasarkan kesamaan semantik dengan kueri pengguna. Kami menonaktifkannya untuk tutorial ini untuk mengurangi biaya. retrieval_modeMode pengambilan yang akan digunakan. Default adalah hybrid.temperaturePengaturan suhu untuk model. Default adalah 0.3.topJumlah hasil pencarian yang akan dikembalikan. Default adalah 3.prompt_templatePenggantian prompt yang digunakan untuk menghasilkan jawaban berdasarkan pertanyaan dan hasil pencarian. seedNilai seed untuk setiap panggilan ke model GPT. Mengatur benih menghasilkan hasil yang lebih konsisten di seluruh evaluasi. target_urlUbah nilai menjadi nilai URI aplikasi obrolan Anda, yang Anda kumpulkan di bagian Prasyarat. Aplikasi obrolan harus sesuai dengan protokol obrolan. URI memiliki format berikut:https://CHAT-APP-URL/chat. Pastikan protokol danchatrute adalah bagian dari URI.
Hasilkan data sampel
Untuk mengevaluasi jawaban baru, jawaban tersebut harus dibandingkan dengan jawaban kebenaran dasar , yang merupakan jawaban ideal untuk pertanyaan tertentu. Hasilkan pertanyaan dan jawaban dari dokumen yang disimpan di Pencarian Azure AI untuk aplikasi obrolan.
example_inputSalin folder ke folder baru bernamamy_input.Di terminal, jalankan perintah berikut untuk menghasilkan data sampel:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Pasangan tanya jawab dihasilkan dan disimpan dalam (dalam my_input/qa.jsonlformat JSONL) sebagai input ke evaluator yang digunakan pada langkah berikutnya. Untuk evaluasi produksi, Anda akan menciptakan lebih banyak pasangan tanya jawab. Lebih dari 200 dihasilkan untuk himpunan data ini.
Catatan
Hanya beberapa pertanyaan dan jawaban yang dihasilkan per sumber sehingga Anda dapat dengan cepat menyelesaikan prosedur ini. Ini tidak dimaksudkan untuk menjadi evaluasi produksi, yang seharusnya memiliki lebih banyak pertanyaan dan jawaban per sumber.
Jalankan evaluasi pertama dengan perintah yang disempurnakan
Edit properti file konfigurasi
my_config.json.Properti Nilai baru results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txtPrompt yang disempurnakan secara spesifik terkait bidang subjek.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].Di terminal, jalankan perintah berikut untuk menjalankan evaluasi:
python -m evaltools evaluate --config=my_config.json --numquestions=14Skrip ini membuat folder eksperimen baru di
my_results/untuk evaluasi. Folder berisi hasil evaluasi.Nama file Deskripsi config.jsonSalinan file konfigurasi yang digunakan untuk evaluasi. evaluate_parameters.jsonParameter yang digunakan untuk evaluasi. Mirip config.jsondengan tetapi menyertakan metadata lain seperti stempel waktu.eval_results.jsonlSetiap pertanyaan dan jawaban, bersama dengan metrik GPT untuk setiap pasangan pertanyaan dan jawaban. summary.jsonHasil keseluruhan, seperti metrik GPT rata-rata.
Jalankan evaluasi kedua dengan prompt lemah
Edit properti file konfigurasi
my_config.json.Properti Nilai baru results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txtPerintah yang lemah itu tidak memiliki konteks tentang bidang subjek.
You are a helpful assistant.Di terminal, jalankan perintah berikut untuk menjalankan evaluasi:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Jalankan evaluasi ketiga dengan suhu tertentu
Gunakan perintah yang memungkinkan lebih banyak kreativitas.
Edit properti file konfigurasi
my_config.json.Yang Sudah Ada Properti Nilai baru Yang Sudah Ada results_dirmy_results/experiment_ignoresources_temp09Tersedia prompt_template<READFILE>my_input/prompt_ignoresources.txtBaru temperature0.9Nilai default
temperatureadalah 0,7. Semakin tinggi suhu, semakin kreatif jawabannya.Teks perintah
ignoresingkat.Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!Objek konfigurasi akan terlihat seperti contoh berikut, kecuali Anda mengganti
results_dirdengan jalur Anda:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }Di terminal, jalankan perintah berikut untuk menjalankan evaluasi:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Tinjau hasil evaluasi
Anda melakukan tiga evaluasi berdasarkan perintah dan pengaturan aplikasi yang berbeda. Hasilnya disimpan di my_results folder . Tinjau bagaimana hasilnya berbeda berdasarkan pengaturan.
Gunakan alat peninjauan untuk melihat hasil evaluasi.
python -m evaltools summary my_resultsHasilnya terlihat seperti:

Setiap nilai dikembalikan sebagai angka dan persentase.
Gunakan tabel berikut untuk memahami arti nilai.
Nilai Deskripsi Keterhubungan dengan kenyataan Memeriksa seberapa baik respons model didasarkan pada informasi yang faktual dan dapat diverifikasi. Respons dianggap membumi jika akurat secara faktual dan mencerminkan realitas. Relevansi Mengukur seberapa dekat respons model selaras dengan konteks atau perintah. Respons yang relevan secara langsung membahas kueri atau pernyataan pengguna. Koherensi Memeriksa seberapa konsisten secara logis respons model. Respons koheren mempertahankan aliran logis dan tidak bertentangan dengan dirinya sendiri. Sitasi Menunjukkan apakah jawaban dikembalikan dalam format yang diminta dalam perintah. Panjang Mengukur panjang respons. Hasilnya harus menunjukkan bahwa ketiga evaluasi memiliki relevansi tinggi sementara
experiment_ignoresources_temp09memiliki relevansi terendah.Pilih folder untuk melihat konfigurasi evaluasi.
Masukkan Ctrl + C untuk keluar dari aplikasi dan kembali ke terminal.
Bandingkan jawabannya
Bandingkan jawaban yang dikembalikan dari evaluasi.
Pilih dua evaluasi yang akan dibandingkan, lalu gunakan alat tinjauan yang sama untuk membandingkan jawabannya.
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Tinjau hasilnya. Hasil Anda mungkin bervariasi.

Masukkan Ctrl + C untuk keluar dari aplikasi dan kembali ke terminal.
Saran untuk evaluasi lebih lanjut
- Edit perintah
my_inputuntuk menyesuaikan jawaban seperti domain subjek, panjang, dan faktor lainnya. - Edit file
my_config.jsonuntuk mengubah parameter sepertitemperaturedansemantic_ranker, lalu jalankan ulang eksperimen. - Bandingkan jawaban yang berbeda untuk memahami bagaimana perintah dan pertanyaan memengaruhi kualitas jawaban.
- Hasilkan serangkaian pertanyaan terpisah dan jawaban kebenaran dasar untuk setiap dokumen dalam indeks Pencarian Azure AI. Kemudian jalankan kembali evaluasi untuk melihat perbedaan jawabannya.
- Ubah perintah untuk menunjukkan jawaban yang lebih pendek atau lebih panjang dengan menambahkan persyaratan ke akhir perintah. Contohnya adalah
Please answer in about 3 sentences.
Membersihkan sumber daya dan dependensi
Langkah-langkah berikut memandu Anda melalui proses membersihkan sumber daya yang telah Anda gunakan.
Membersihkan sumber daya Azure
Sumber daya Azure yang dibuat dalam artikel ini ditagihkan ke langganan Azure Anda. Jika Anda tidak mengharapkan untuk membutuhkan sumber daya ini di masa mendatang, hapus sumber daya tersebut untuk menghindari dikenakan lebih banyak biaya.
Untuk menghapus sumber daya Azure dan menghapus kode sumber, jalankan perintah Azure Developer CLI berikut:
azd down --purge
Membersihkan GitHub Codespaces dan Visual Studio Code
Menghapus lingkungan GitHub Codespaces memastikan bahwa Anda dapat memaksimalkan kuota jam penggunaan inti gratis yang Anda dapatkan untuk akun Anda.
Penting
Untuk informasi lebih lanjut tentang hak akun GitHub Anda, lihat Penyimpanan bulanan yang disertakan dan jam inti GitHub Codespaces.
Masuk ke dasbor GitHub Codespaces.
Temukan codespace yang saat ini berjalan dan bersumber dari GitHub repositori Azure-Samples/ai-rag-chat-evaluator.
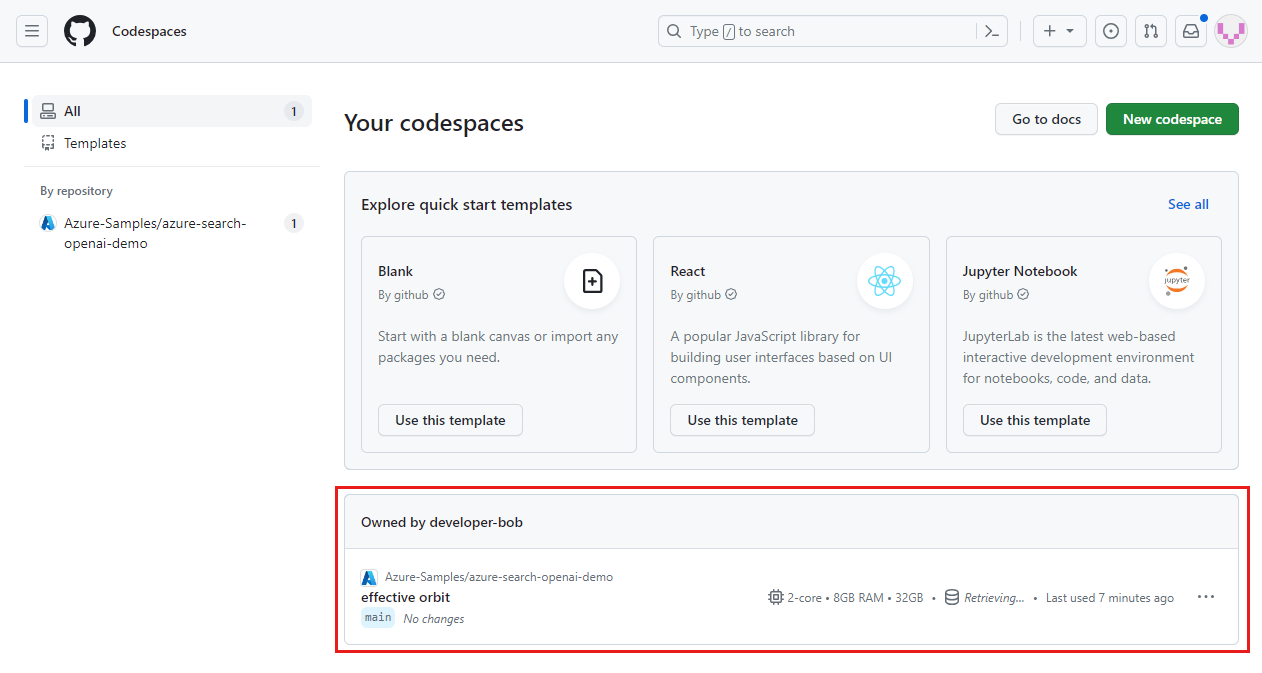
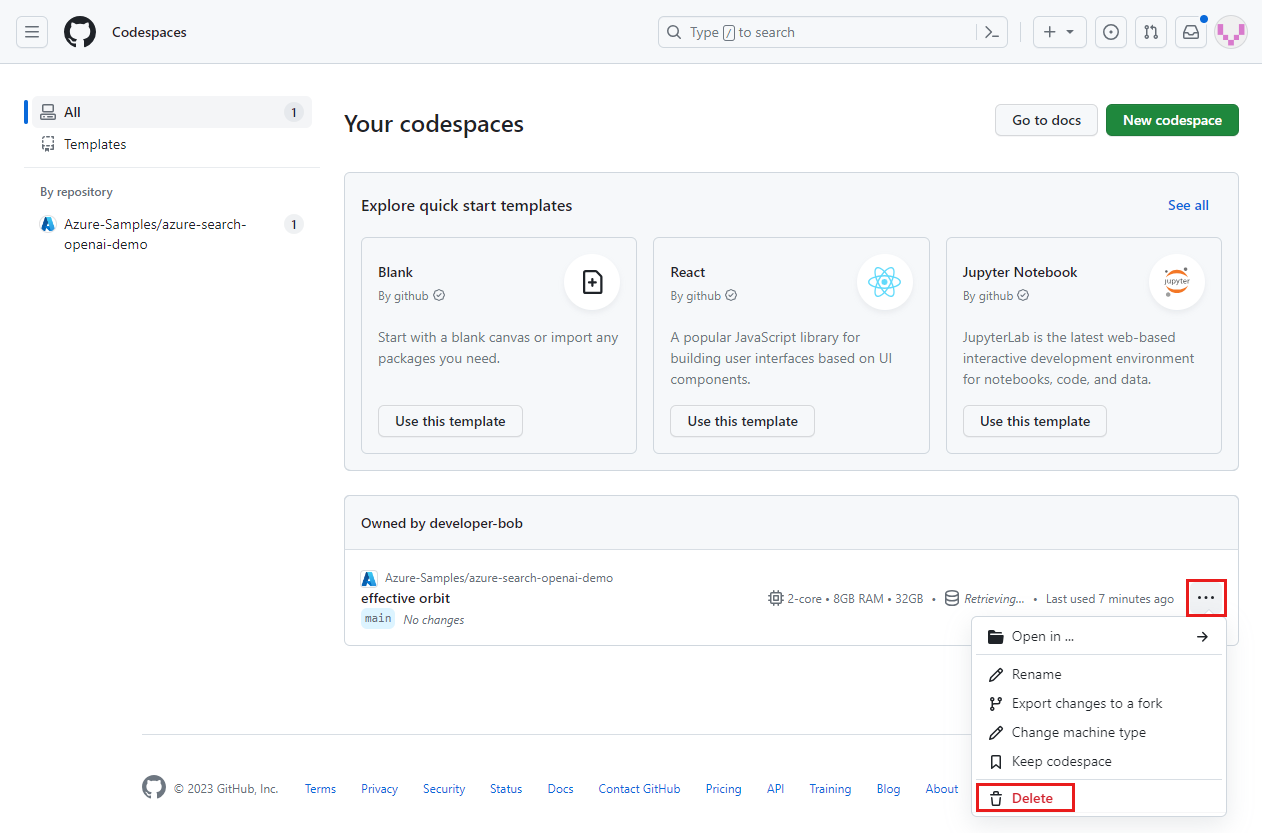
Buka menu konteks untuk codespace, lalu pilih Hapus.
Kembali ke artikel tentang aplikasi obrolan untuk membersihkan sumber daya tersebut.
Konten terkait
- Lihat repositori evaluasi.
- Lihat repositori GitHub aplikasi obrolan perusahaan .
- Buat aplikasi obrolan dengan arsitektur solusi praktik terbaik Azure OpenAI.
- Pelajari tentang kontrol akses di aplikasi AI generatif dengan Pencarian Azure AI.
- Bangun solusi Azure OpenAI yang siap untuk perusahaan dengan Azure API Management.
- Lihat Pencarian Azure AI: Mengungguli pencarian vektor dengan kemampuan pengambilan dan peringkat hibrid.