Keandalan di Azure Event Grid dan namespace Event Grid
Artikel ini berisi informasi terperinci tentang ketahanan wilayah namespace Layanan Event Grid dan Event Grid dengan zona ketersediaan dan pemulihan bencana lintas wilayah dan kelangsungan bisnis.
Untuk gambaran umum arsitektur keandalan di Azure, lihat Keandalan Azure.
Dukungan zona ketersediaan
Zona ketersediaan Azure adalah setidaknya tiga grup pusat data yang terpisah secara fisik dalam setiap wilayah Azure. Pusat data dalam setiap zona dilengkapi dengan infrastruktur daya, pendinginan, dan jaringan independen. Dalam kasus kegagalan zona lokal, zona ketersediaan dirancang sehingga jika satu zona terpengaruh, layanan regional, kapasitas, dan ketersediaan tinggi didukung oleh dua zona yang tersisa.
Kegagalan dapat berkisar dari kegagalan perangkat lunak dan perangkat keras hingga peristiwa seperti gempa bumi, banjir, dan kebakaran. Toleransi terhadap kegagalan dicapai dengan redundansi dan isolasi logis layanan Azure. Untuk informasi selengkapnya tentang zona ketersediaan di Azure, lihat Wilayah dan zona ketersediaan.
Layanan berkemampuan zona ketersediaan Azure dirancang untuk memberikan tingkat keandalan dan fleksibilitas yang tepat. Mereka dapat dikonfigurasi dalam dua cara. Mereka dapat berupa zona redundan,dengan replikasi otomatis di seluruh zona, atau zonal, dengan instans yang disematkan ke zona tertentu. Anda juga dapat menggabungkan pendekatan ini. Untuk informasi selengkapnya tentang arsitektur zonal vs. zona-redundan, lihat Rekomendasi untuk menggunakan zona dan wilayah ketersediaan.
Definisi sumber daya Event Grid untuk topik, topik sistem, domain, dan langganan peristiwa dan data peristiwa secara otomatis direplikasi di tiga zona ketersediaan. Ketika ada kegagalan regional di salah satu zona ketersediaan, sumber daya Event Grid secara otomatis failover ke zona ketersediaan lain tanpa intervensi manusia. Saat ini, Anda tidak dapat mengontrol (mengaktifkan atau menonaktifkan) fitur ini. Ketika wilayah yang ada mulai mendukung zona ketersediaan, sumber daya Event Grid yang ada secara otomatis gagal untuk memanfaatkan fitur ini. Tidak perlu tindakan pelanggan.
Namespace Layanan Azure Event Grid juga mencapai ketersediaan tinggi intra-wilayah menggunakan zona ketersediaan.
Prasyarat
Untuk dukungan zona ketersediaan, sumber daya Event Grid Anda harus berada di wilayah yang mendukung zona ketersediaan. Untuk meninjau wilayah mana yang mendukung zona ketersediaan, lihat daftar wilayah yang didukung.
Harga
Karena Event Grid mendukung zona ketersediaan secara otomatis di wilayah yang mendukung zona ketersediaan, tidak ada perubahan harga.
Membuat sumber daya dengan zona ketersediaan diaktifkan
Karena Event Grid mendukung zona ketersediaan secara otomatis di wilayah yang mendukung zona ketersediaan, tidak ada konfigurasi penyiapan yang diperlukan.
Dukungan bermigrasi ke zona ketersediaan
Jika Anda merelokasi sumber daya Event Grid ke wilayah yang mendukung zona ketersediaan, Anda secara otomatis menerima dukungan zona ketersediaan. Untuk mempelajari cara merelokasi sumber daya Anda ke wilayah lain yang mendukung zona ketersediaan, lihat yang berikut ini:
- Merelokasi topik sistem Azure Event Grid ke wilayah lain
- Merelokasi topik kustom Azure Event Grid ke wilayah lain
- Merelokasi domain Azure Event Grid ke wilayah lain
Pemulihan bencana lintas wilayah dan kelangsungan bisnis
Pemulihan bencana (DR) adalah tentang pemulihan dari peristiwa berdampak tinggi, seperti bencana alam atau penyebaran gagal yang mengakibatkan waktu henti dan kehilangan data. Terlepas dari penyebabnya, obat terbaik untuk bencana adalah rencana DR yang terdefinisi dan teruji dengan baik dan desain aplikasi yang secara aktif mendukung DR. Sebelum Anda mulai berpikir tentang membuat rencana pemulihan bencana Anda, lihat Rekomendasi untuk merancang strategi pemulihan bencana.
Ketika datang ke DR, Microsoft menggunakan model tanggung jawab bersama. Dalam model tanggung jawab bersama, Microsoft memastikan bahwa infrastruktur dasar dan layanan platform tersedia. Pada saat yang sama, banyak layanan Azure tidak secara otomatis mereplikasi data atau mundur dari wilayah yang gagal untuk mereplikasi silang ke wilayah lain yang diaktifkan. Untuk layanan tersebut, Anda bertanggung jawab untuk menyiapkan rencana pemulihan bencana yang berfungsi untuk beban kerja Anda. Sebagian besar layanan yang berjalan pada penawaran platform as a service (PaaS) Azure menyediakan fitur dan panduan untuk mendukung DR dan Anda dapat menggunakan fitur khusus layanan untuk mendukung pemulihan cepat untuk membantu mengembangkan rencana DR Anda.
Pemulihan bencana biasanya melibatkan pembuatan sumber daya cadangan untuk mencegah gangguan ketika suatu wilayah menjadi tidak sehat. Selama proses ini, wilayah utama dan sekunder sumber daya Azure Event Grid akan diperlukan dalam beban kerja Anda.
Ada berbagai cara untuk pulih dari hilangnya fungsionalitas aplikasi yang parah. Di bagian ini, kami menjelaskan daftar periksa yang perlu Anda ikuti untuk mempersiapkan klien Anda pulih dari kegagalan karena sumber daya atau wilayah yang tidak sehat.
Event Grid mendukung pemulihan bencana geografis manual dan otomatis (GeoDR) di sisi server. Anda masih dapat menerapkan logika pemulihan bencana sisi klien jika Anda menginginkan kontrol yang lebih besar pada proses kegagalan. Untuk detail tentang GeoDR otomatis, lihat Pemulihan bencana geografis sisi server di Azure Event Grid. Untuk detail tentang cara menerapkan pemulihan bencana sisi klien, lihatImplementasi failover sisi klien di Azure Event Grid.
Tabel berikut mengilustrasikan failover sisi klien dan dukungan pemulihan bencana geografis di Event Grid.
| Sumber daya Azure Event Grid | Dukungan failover sisi klien | Dukungan pemulihan bencana geografis (GeoDR) |
|---|---|---|
| Topik kustom | Didukung | Lintas Geo / Regional |
| Topik Sistem | Tidak didukung | Diaktifkan secara otomatis |
| Domain | Didukung | Lintas Geo / Regional |
| Namespace Mitra | Didukung | Tidak didukung |
| Namaspace | Didukung | Tidak didukung |
Namespace layanan kisi peristiwa
Namespace Layanan Event Grid tidak mendukung DR lintas wilayah. Namun, Anda dapat mencapai ketersediaan tinggi lintas wilayah melalui implementasi failover sisi klien dengan membuat namespace layanan primer dan sekunder.
Dengan implementasi failover sisi klien, Anda dapat:
Terapkan proses kustom (manual atau otomatis) untuk mereplikasi namespace layanan, identitas klien, dan konfigurasi lainnya** termasuk sertifikat CA, grup klien, ruang topik, pengikatan izin, perutean, antara wilayah utama dan sekunder.
Terapkan layanan pramutamu yang menyediakan titik akhir primer dan sekunder kepada klien dengan melakukan pemeriksaan kesehatan pada titik akhir. Layanan pramutamu dapat menjadi aplikasi web yang direplikasi dan terus dapat dijangkau menggunakan teknik pengalihan DNS, misalnya, menggunakan Azure Traffic Manager.
Mencapai solusi DR Aktif-Aktif dengan mereplikasi metadata dan menyeimbangkan beban di seluruh namespace layanan. Solusi DR Pasif Aktif dapat dicapai dengan mereplikasi metadata agar namespace layanan sekunder tetap siap sehingga ketika namespace utama tidak tersedia, lalu lintas dapat diarahkan ke namespace sekunder.
Menyiapkan pemulihan bencana
Untuk wilayah yang dipasangkan, Event Grid menawarkan kemampuan untuk gagal atas lalu lintas penerbitan ke wilayah yang dipasangkan untuk topik kustom, topik sistem, dan domain. Di balik layar, Event Grid secara otomatis menyinkronkan definisi sumber daya topik, topik sistem, domain, dan langganan peristiwa ke wilayah yang dipasangkan. Namun, data peristiwa tidak direplikasi ke wilayah yang dipasangkan. Dalam status normal, peristiwa disimpan di wilayah yang Anda pilih untuk sumber daya tersebut. Ketika ada pemadaman wilayah dan Microsoft memulai failover, peristiwa baru mulai mengalir ke wilayah yang dipasangkan secara geografis dan dikirim dari sana tanpa intervensi dari Anda. Peristiwa yang diterbitkan dan diterima di wilayah asli dikirim dari sana setelah pemadaman dimitigasi.
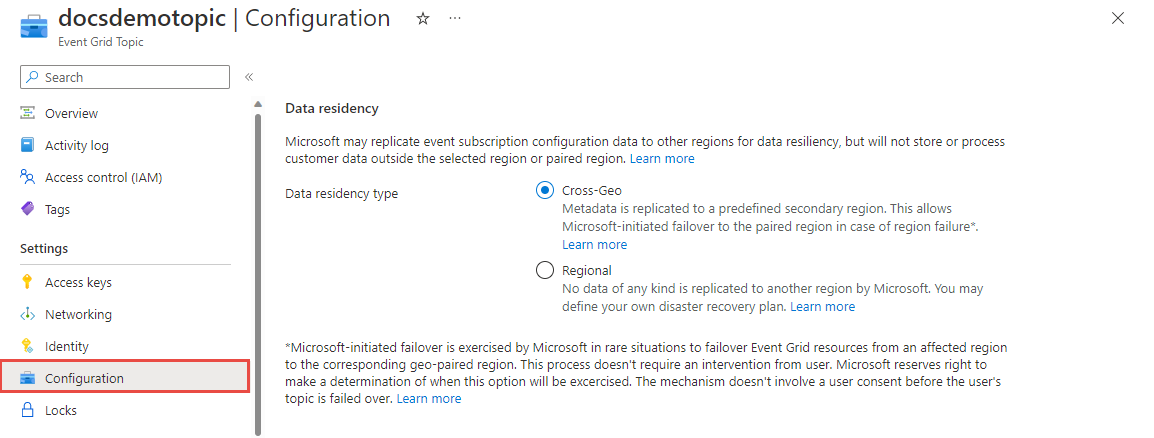
Anda dapat memilih antara dua opsi failover, failover yang dimulai Microsoft dan pelanggan dimulai. Untuk langkah-langkah terperinci tentang cara mengonfigurasi kedua pengaturan ini, lihat Mengonfigurasi residensi data.
Failover yang dimulai Microsoft dilakukan oleh Microsoft dalam situasi yang jarang terjadi untuk mengalihkan sumber daya Event Grid dari wilayah yang terpengaruh ke wilayah yang dipasangkan secara geografis yang sesuai. Microsoft berhak menentukan kapan opsi ini akan dilakukan. Mekanisme ini tidak melibatkan persetujuan pengguna sebelum lalu lintas pengguna dilakukan fail over.
Aktifkan fungsionalitas ini dengan memperbarui konfigurasi untuk topik atau domain Anda. Pilih Cross-Geo (default) untuk mengaktifkan failover yang dimulai Microsoft.
Failover yang dimulai pelanggan ditentukan oleh rencana pemulihan bencana kustom Anda untuk topik dan domain Azure Event Grid, data apa pun tidak direplikasi ke wilayah lain oleh Microsoft. Meskipun opsi failover ini membutuhkan sedikit lebih banyak upaya, opsi ini memungkinkan failover yang lebih cepat, dan Anda mengendalikan pemilihan wilayah sekunder. Jika Anda ingin menerapkan pemulihan bencana sisi klien untuk topik Azure Event Grid, lihat Membangun pemulihan bencana sisi klien Anda sendiri untuk topik Azure Event Grid.
Ada beberapa alasan mengapa Anda mungkin ingin menonaktifkan fitur failover yang dimulai Microsoft:
- Failover yang dimulai Microsoft dilakukan berdasarkan upaya terbaik.
- Beberapa pasangan geografis tidak memenuhi persyaratan residensi data organisasi Anda.
Aktifkan fungsionalitas ini dengan memperbarui konfigurasi untuk topik atau domain Anda. Pilih Regional.
Pengalaman failover pemulihan bencana
Pemulihan bencana diukur dengan dua metrik, Recovery Point Objective (RPO) dan Recovery Time Objective (RTO).
Failover otomatis Event Grid memiliki RPO dan RTO yang berbeda untuk metadata Anda (topik, domain, langganan peristiwa) dan data (peristiwa). Jika Anda memerlukan spesifikasi yang berbeda dari yang berikut ini, Anda masih dapat menerapkan failover sisi klien Anda sendiri menggunakan API kesehatan topik.
Tujuan titik pemulihan (RPO)
Metadata RPO: nol menit. Untuk sumber daya yang berlaku, saat sumber daya dibuat/diperbarui/dihapus, definisi sumber daya direplikasi secara sinkron ke pasangan geografis. Ketika failover terjadi, tidak ada metadata yang hilang.
RPO Data: Saat failover terjadi, data baru diproses dari wilayah yang dipasangkan. Segera setelah pemadaman dimitigasi untuk wilayah yang terkena dampak, peristiwa yang tidak diolah dikirim dari sana. Jika pemulihan wilayah memerlukan waktu lebih lama daripada nilai time-to-live yang ditetapkan pada peristiwa, data bisa dihilangkan. Untuk mengurangi kehilangan data ini, kami sarankan Anda menyiapkan tujuan surat mati untuk langganan peristiwa. Jika wilayah yang terpengaruh hilang dan tidak dapat dipulihkan, akan ada beberapa kehilangan data. Dalam skenario terbaik, pelanggan mengikuti tingkat penerbitan dan hanya beberapa detik data yang hilang. Skenario terburuk adalah ketika pelanggan tidak secara aktif memproses peristiwa dan dengan waktu maksimum untuk hidup 24 jam, kehilangan data bisa hingga 24 jam.
Tujuan waktu pemulihan (RTO)
Metadata RTO: Pengambilan keputusan failover didasarkan pada faktor-faktor seperti kapasitas yang tersedia di wilayah berpasangan dan dapat bertahan dalam kisaran 60 menit atau lebih. Setelah failover dimulai, dalam waktu 5 menit, Event Grid mulai menerima panggilan buat/perbarui/hapus untuk topik dan langganan.
Data RTO: Sama seperti informasi di atas.
Penting
- Jika pemulihan bencana sisi server, jika wilayah yang dipasangkan tidak memiliki kapasitas tambahan untuk mengambil lalu lintas tambahan, Event Grid tidak dapat memulai failover. Pemulihan dilakukan berdasarkan upaya terbaik.
- Tidak ada biaya untuk menggunakan fitur ini.
- Pemulihan bencana geografis tidak didukung untuk namespace mitra dan topik mitra.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk