Menggunakan Apache Kafka® di HDInsight dengan Apache Flink® di HDInsight di AKS
Penting
Fitur ini masih dalam mode pratinjau. Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure mencakup lebih banyak persyaratan hukum yang berlaku untuk fitur Azure yang dalam versi beta, dalam pratinjau, atau belum dirilis ke ketersediaan umum. Untuk informasi tentang pratinjau khusus ini, lihat Azure HDInsight pada informasi pratinjau AKS. Untuk pertanyaan atau saran fitur, kirimkan permintaan di AskHDInsight dengan detail dan ikuti kami untuk pembaruan lebih lanjut di Komunitas Azure HDInsight.
Kasus penggunaan terkenal untuk Apache Flink adalah analisis aliran. Pilihan populer oleh banyak pengguna untuk menggunakan aliran data, yang diserap menggunakan Apache Kafka. Penginstalan umum Flink dan Kafka dimulai dengan aliran peristiwa yang didorong ke Kafka, yang dapat dikonsumsi oleh pekerjaan Flink.
Contoh ini menggunakan HDInsight pada kluster AKS yang menjalankan Flink 1.17.0 untuk memproses penggunaan data streaming dan menghasilkan topik Kafka.
Catatan
FlinkKafkaConsumer tidak digunakan lagi dan akan dihapus dengan Flink 1.17, silakan gunakan KafkaSource sebagai gantinya. FlinkKafkaProducer tidak digunakan lagi dan akan dihapus dengan Flink 1.15, silakan gunakan KafkaSink sebagai gantinya.
Prasyarat
Kafka dan Flink harus berada di VNet yang sama atau harus ada vnet-peering antara kedua kluster.
Buat kluster Kafka di VNet yang sama. Anda dapat memilih Kafka 3.2 atau 2.4 pada HDInsight berdasarkan penggunaan Anda saat ini.
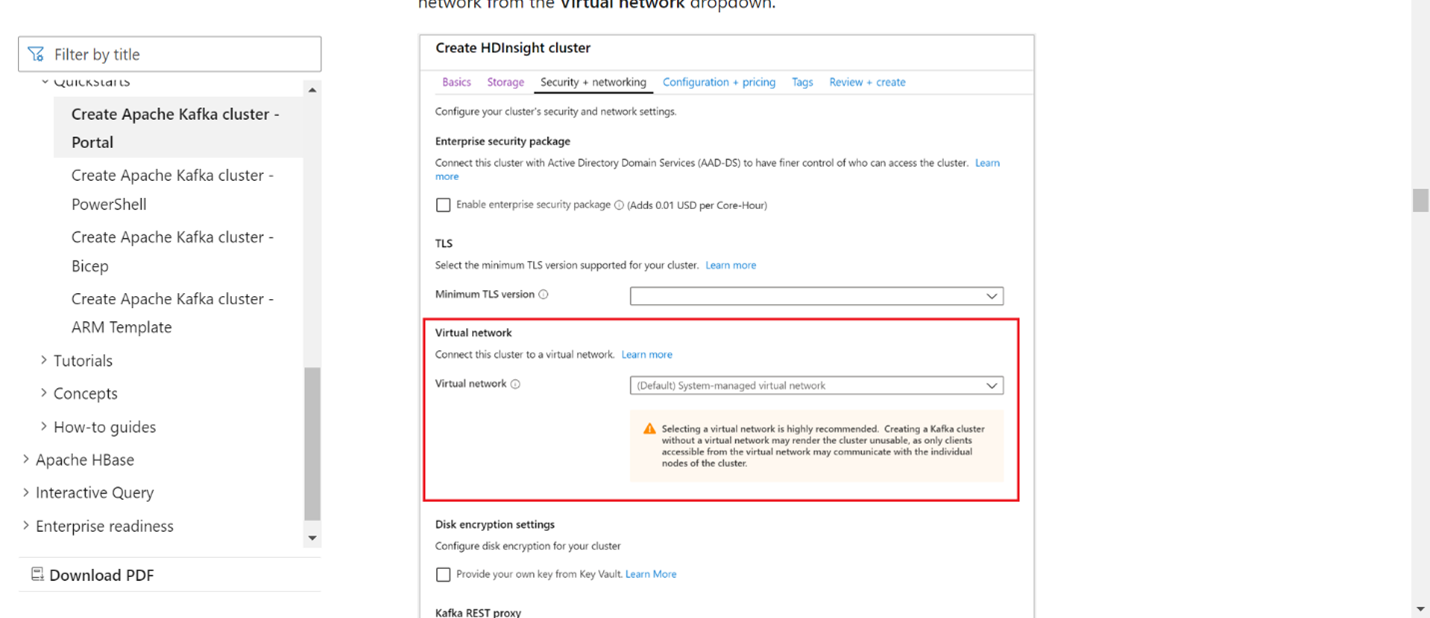
Tambahkan detail VNet di bagian jaringan virtual.
Buat HDInsight di kumpulan Kluster AKS dengan VNet yang sama.
Buat kluster Flink ke kumpulan kluster yang dibuat.

Koneksi or Apache Kafka
Flink menyediakan Koneksi or Apache Kafka untuk membaca data dari dan menulis data ke topik Kafka dengan jaminan tepat sekali.
Dependensi Maven
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Membangun Kafka Sink
Sink Kafka menyediakan kelas pembangun untuk membuat instans KafkaSink. Kami menggunakan hal yang sama untuk membangun Sink kami dan menggunakannya bersama dengan kluster Flink yang berjalan di HDInsight di AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Menulis Event.java program Java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Mengemas jar dan mengirimkan pekerjaan ke Flink
Di Webssh, unggah jar dan kirimkan jar

Pada UI Dasbor Flink

Menghasilkan topik - klik pada Kafka

Mengonsumsi topik - peristiwa di Kafka

Referensi
- Koneksi or Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, dan nama proyek sumber terbuka terkait adalah merek dagang dari Apache Software Foundation (ASF).
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk