Auto Scale HDInsight pada Kluster AKS
Penting
Fitur ini masih dalam mode pratinjau. Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure mencakup lebih banyak persyaratan hukum yang berlaku untuk fitur Azure yang dalam versi beta, dalam pratinjau, atau belum dirilis ke ketersediaan umum. Untuk informasi tentang pratinjau khusus ini, lihat Azure HDInsight pada informasi pratinjau AKS. Untuk pertanyaan atau saran fitur, kirimkan permintaan di AskHDInsight dengan detail dan ikuti kami untuk pembaruan lebih lanjut di Komunitas Azure HDInsight.
Ukuran kluster apa pun untuk memenuhi performa pekerjaan dan mengelola biaya sebelumnya selalu sulit, dan sulit ditentukan! Salah satu manfaat yang menguntungkan dalam membangun data lake house over Cloud adalah elastisitasnya, yang berarti menggunakan fitur skala otomatis untuk memaksimalkan pemanfaatan sumber daya yang ada. Skala otomatis dengan Kubernetes adalah salah satu kunci untuk membangun ekosistem yang dioptimalkan biaya. Dengan pola penggunaan yang bervariasi di perusahaan mana pun, mungkin ada variasi beban kluster dari waktu ke waktu yang dapat menyebabkan kluster kurang disediakan (performa buruk) atau kelebihan penyediaan (biaya yang tidak perlu karena sumber daya yang tidak aktif).
Fitur skala otomatis yang ditawarkan dalam HDInsight pada AKS dapat secara otomatis meningkatkan atau mengurangi jumlah simpul pekerja di kluster Anda. Skala otomatis menggunakan metrik kluster dan kebijakan penskalakan yang digunakan oleh pelanggan.
Fitur ini sangat cocok untuk beban kerja misi penting, yang mungkin memiliki
- Pola lalu lintas variabel atau tidak dapat diprediksi dan memerlukan SLA pada performa dan skala tinggi atau
- Jadwal yang telah ditentukan untuk simpul pekerja yang diperlukan tersedia agar berhasil menjalankan pekerjaan pada kluster.
Skala Otomatis dengan HDInsight pada Kluster AKS membuat kluster hemat biaya, dan elastis di Azure.
Dengan skala Otomatis, pelanggan dapat menurunkan skala kluster tanpa memengaruhi beban kerja. Ini diaktifkan dengan kemampuan tingkat lanjut seperti penonaktifan dan periode pendinginan yang anggun. Kemampuan ini memberdayakan pengguna untuk membuat pilihan berdasarkan informasi tentang penambahan dan penghapusan simpul berdasarkan beban kluster saat ini.
Cara kerjanya
Fitur ini bekerja dengan menskalakan jumlah simpul dalam batas prasetel berdasarkan metrik kluster atau jadwal operasi peningkatan dan penurunan skala yang ditentukan. Ada dua jenis kondisi untuk memicu peristiwa skala otomatis: pemicu berbasis ambang batas untuk berbagai metrik performa kluster (disebut penskalaan berbasis beban) dan pemicu berbasis waktu (disebut penskalaan berbasis jadwal).
Penskalaan berbasis beban mengubah jumlah simpul di kluster Anda, dalam rentang yang Anda tetapkan, untuk memastikan penggunaan CPU yang optimal dan meminimalkan biaya berjalan.
Penskalaan berbasis jadwal mengubah jumlah simpul di kluster Anda berdasarkan jadwal operasi penambahan dan penurunan skala.
Catatan
Skala otomatis tidak mendukung perubahan jenis SKU dari kluster yang ada.
Kompatibilitas kluster
Tabel berikut ini menjelaskan jenis kluster yang kompatibel dengan fitur Skala otomatis, dan apa yang tersedia atau direncanakan.
| Beban kerja | Berbasis Beban | Berbasis Jadwal |
|---|---|---|
| Flink | Direncanakan | Ya |
| Trino | Ya** | Ya** |
| Spark | Ya** | Ya** |
**Penonaktifan yang anggun dapat dikonfigurasi.
Metode Penskalakan
Penskalakan berbasis jadwal:
Ketika pekerjaan Anda diharapkan berjalan pada jadwal tetap dan untuk durasi yang dapat diprediksi atau ketika Anda mengantisipasi penggunaan rendah selama waktu tertentu dalam sehari Misalnya, lingkungan pengujian dan pengembangan di jam pasca-kerja, pekerjaan akhir hari.
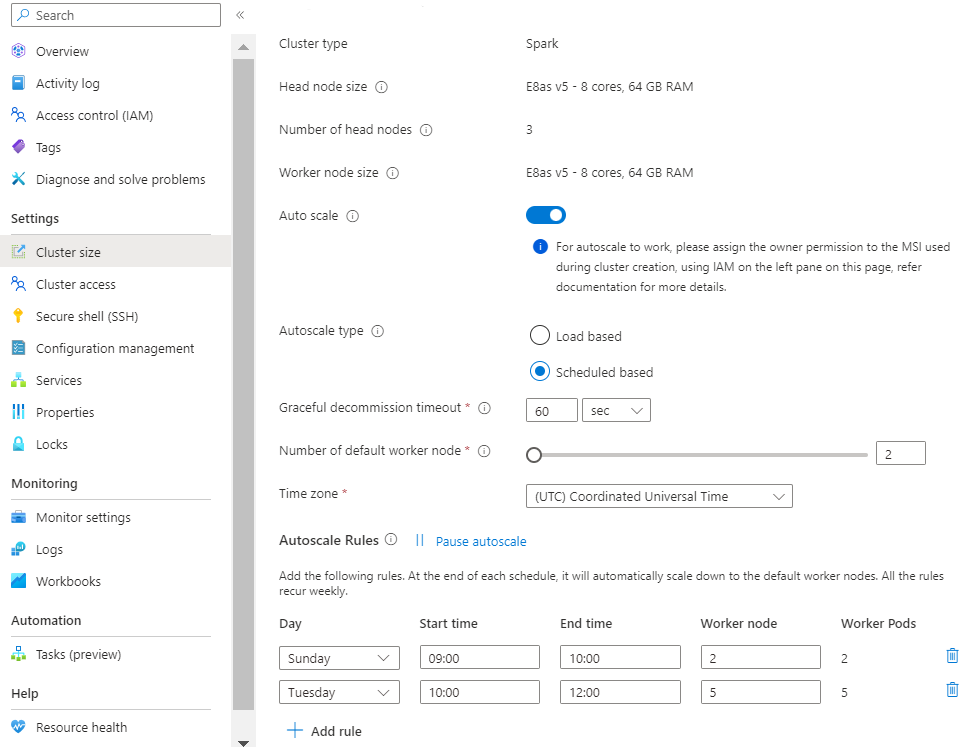
Skala berbasis beban:
Ketika pola beban berfluktuasi secara substansial dan tidak terduga pada siang hari, misalnya, Memesan pemrosesan data dengan fluktuasi acak dalam pola beban berdasarkan berbagai faktor.
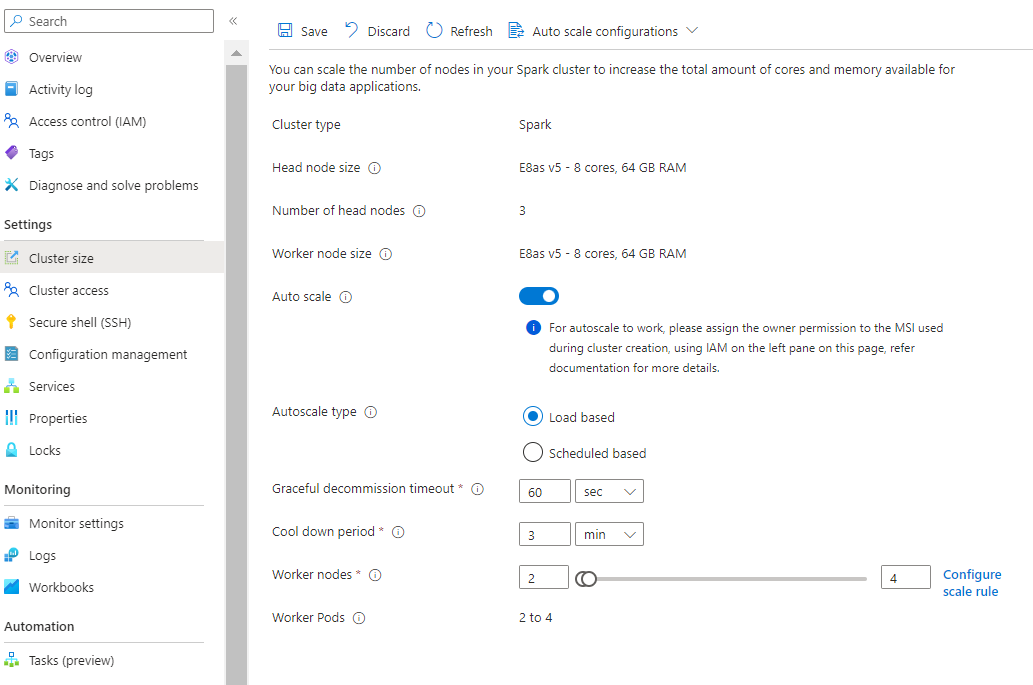
Dengan opsi aturan skala konfigurasi baru, Anda sekarang dapat menyesuaikan aturan skala.
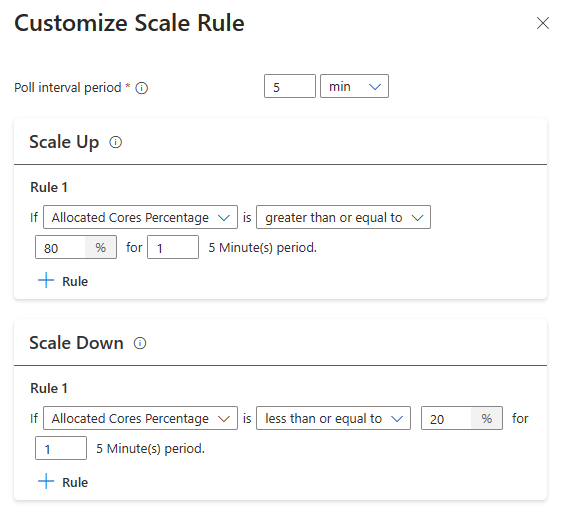
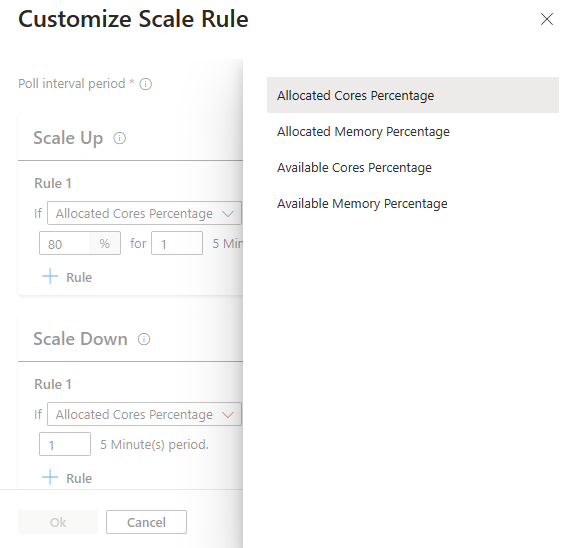
Tip
- Aturan Peningkatan Skala lebih diutamakan ketika satu atau beberapa aturan dipicu. Bahkan jika hanya salah satu aturan untuk meningkatkan skala menyarankan kluster yang kurang disediakan, kluster akan mencoba meningkatkan skala. Agar penurunan skala terjadi, tidak ada aturan peningkatan skala yang harus dipicu.


Kondisi skala berbasis beban
Ketika kondisi berikut terdeteksi, Skala otomatis mengeluarkan permintaan skala
| Penambahan skala | Penurunan Skala |
|---|---|
| Core yang dialokasikan lebih besar dari 80% untuk interval polling 5 menit (periode pemeriksaan 1 menit) | Core yang dialokasikan kurang dari atau sama dengan 20% untuk interval polling 5 menit (periode pemeriksaan 1 menit) |
Untuk peningkatan skala, Skala otomatis mengeluarkan permintaan peningkatan skala untuk menambahkan jumlah simpul yang diperlukan. Penambahan skala didasarkan pada berapa banyak simpul pekerja baru yang diperlukan untuk memenuhi persyaratan CPU dan memori saat ini. Nilai ini dibatasi ke jumlah maksimum simpul pekerja yang ditetapkan.
Untuk penurunan skala, Skala otomatis mengeluarkan permintaan untuk menghapus beberapa simpul. Pertimbangan penurunan skala termasuk jumlah pod per simpul, persyaratan CPU dan memori saat ini, dan simpul pekerja, yang merupakan kandidat untuk dihapus berdasarkan eksekusi pekerjaan saat ini. Operasi penurunan skala pertama-tama menonaktifkan simpul, lalu menghapusnya dari kluster.
Penting
Mesin Aturan Skala Otomatis secara proaktif menghapus peristiwa lama setiap 30 menit untuk mengoptimalkan memori sistem. Akibatnya, ada batas batas atas 30 menit pada interval aturan penskalaan. Untuk memastikan pemicu tindakan penskalaan yang konsisten dan andal, sangat penting untuk mengatur interval aturan penskalaan ke nilai yang lebih kecil dari batas. Dengan mematuhi pedoman ini, Anda dapat menjamin proses penskalaan yang lancar dan efisien sambil mengelola sumber daya sistem secara efektif.
Metrik kluster
Skala otomatis terus memantau kluster dan mengumpulkan metrik berikut untuk Skala otomatis berbasis beban:
Metrik Kluster Tersedia untuk Tujuan Penskalaan
| Metrik | Deskripsi |
|---|---|
| Persentase Inti yang Tersedia | Jumlah total inti yang tersedia dalam kluster dibandingkan dengan jumlah total inti dalam kluster. |
| Persentase Memori yang Tersedia | Total memori (dalam MB) yang tersedia dalam kluster dibandingkan dengan jumlah total memori dalam kluster. |
| Persentase Inti yang Dialokasikan | Jumlah total inti yang dialokasikan dalam kluster dibandingkan dengan jumlah total inti dalam kluster. |
| Persentase Memori yang Dialokasikan | Jumlah memori yang dialokasikan dalam kluster dibandingkan dengan jumlah total memori dalam kluster. |
Secara default, metrik di atas diperiksa setiap 300 detik, metrik tersebut juga dapat dikonfigurasi saat Anda menyesuaikan interval polling dengan opsi kustomisasi skala otomatis. Skala otomatis membuat keputusan peningkatan atau penurunan skala berdasarkan metrik ini.
Catatan
Secara default Skala otomatis menggunakan kalkulator sumber daya default untuk YARN untuk Apache Spark. Penskalaan berbasis beban tersedia untuk Kluster Apache Spark.
Penonaktifan Yang Anggun
Perusahaan membutuhkan cara untuk mencapai skala petabyte dengan penskalaan otomatis dan menonaktifkan sumber daya dengan anggun ketika mereka tidak lagi diperlukan. Dalam skenario seperti itu, fitur penonaktifan yang anggun berguna.
Penonaktifan yang anggun memungkinkan pekerjaan selesai bahkan setelah skala otomatis telah memicu penonaktifan simpul pekerja. Fitur ini memungkinkan simpul untuk terus diprovisikan hingga pekerjaan selesai.
Trino : Pekerja mengaktifkan Penonaktifan Yang Anggun secara default. Koordinator memungkinkan penghentian pekerja untuk menyelesaikan tugasnya untuk jumlah waktu yang dikonfigurasi sebelum menghapus pekerja dari kluster. Anda dapat mengonfigurasi batas waktu baik menggunakan parameter
shutdown.grace-periodTrino asli , atau di halaman konfigurasi layanan portal Azure.Apache Spark : Penurunan skala dapat memengaruhi/menghentikan pekerjaan yang sedang berjalan di kluster. Jika Anda mengaktifkan pengaturan Penonaktifan Anggun pada portal Azure, itu menggabungkan Penonaktifan Simpul YARN yang Anggun dan memastikan bahwa pekerjaan apa pun yang sedang berlangsung pada simpul pekerja selesai sebelum node dihapus dari HDInsight pada kluster AKS.
Periode pendinginan
Untuk menghindari operasi peningkatan skala berkelanjutan, mesin skala otomatis menunggu interval yang dapat dikonfigurasi sebelum memulai serangkaian operasi peningkatan skala lainnya. Nilai default diatur ke 180 detik
Catatan
- Dalam aturan skala kustom, tidak ada pemicu aturan yang dapat memiliki interval pemicu yang lebih besar dari 30 menit. Setelah peristiwa penskalaan otomatis terjadi, jumlah waktu untuk menunggu sebelum memberlakukan kebijakan penskalaan lain.
- Periode pendinginan harus lebih besar dari interval kebijakan, sehingga metrik kluster bisa direset.
Memulai
Agar skala otomatis berfungsi, Anda diharuskan menetapkan izin pemilik atau kontributor ke MSI (digunakan selama pembuatan kluster) di tingkat kluster, menggunakan IAM di panel kiri.
Lihat ilustrasi dan langkah-langkah berikut yang tercantum tentang cara menambahkan penetapan peran
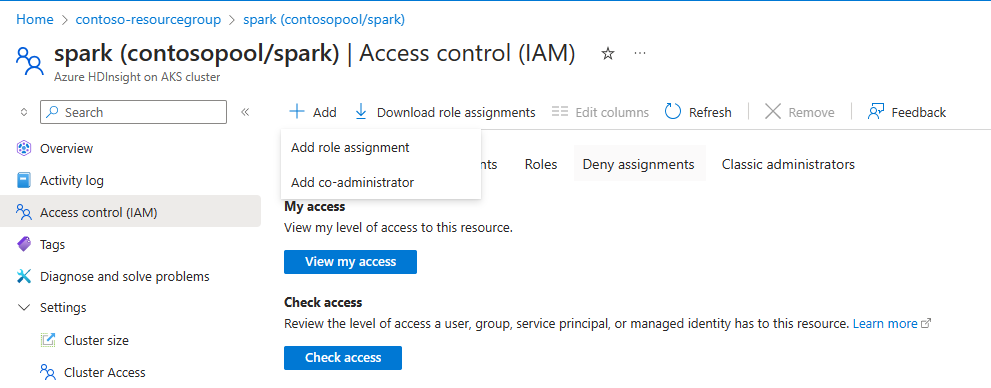
Pilih tambahkan penetapan peran,
- Jenis penugasan: Peran administrator istimewa
- Peran: Pemilik atau Kontributor
- Anggota: Pilih Identitas terkelola dan pilih Identitas terkelola yang ditetapkan pengguna, yang diberikan selama fase pembuatan kluster.
- Tetapkan peran.

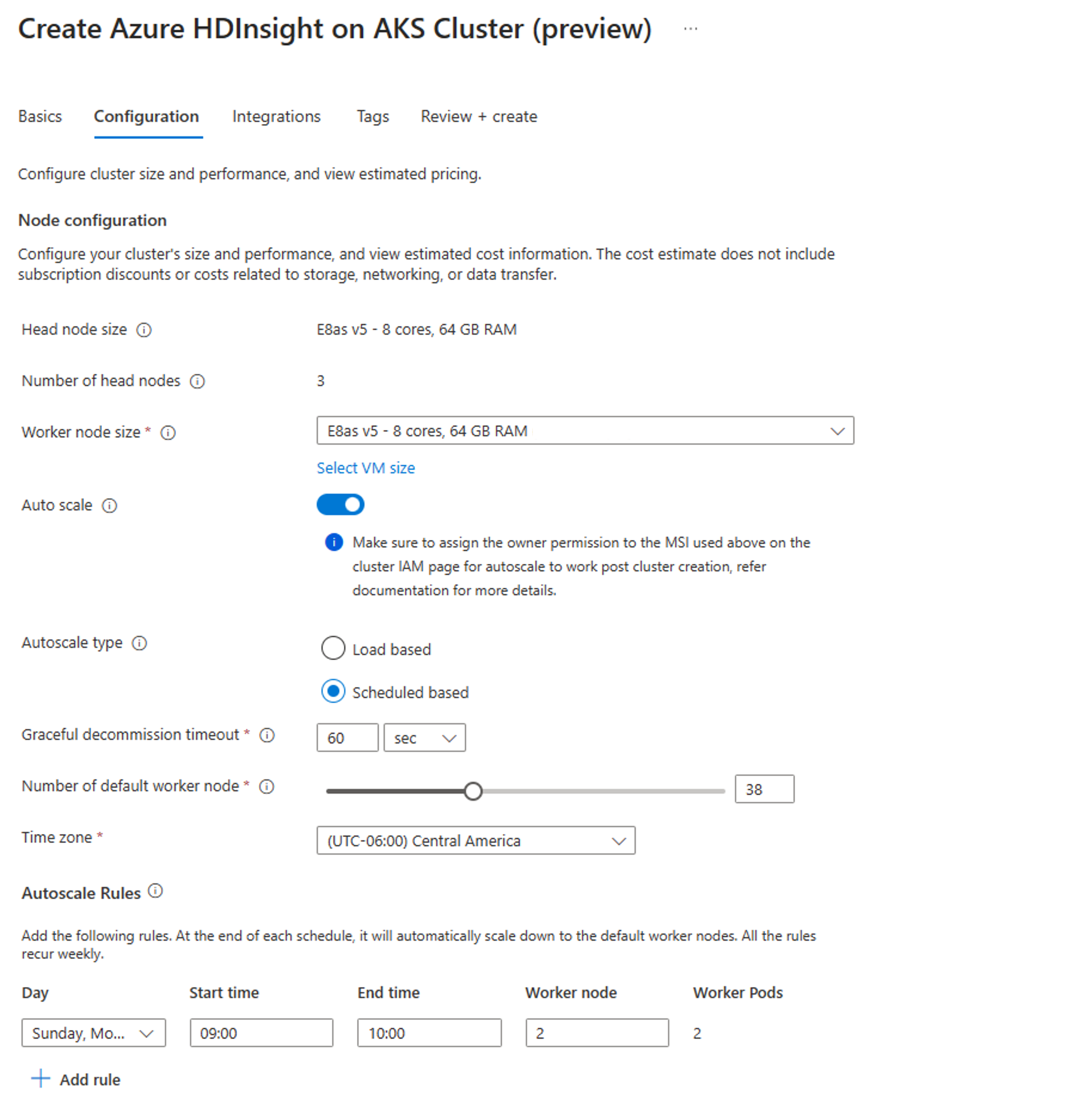
Membuat kluster dengan skala Otomatis berbasis Jadwal
Setelah kumpulan kluster Anda dibuat, buat kluster baru dengan beban kerja yang Anda inginkan (pada jenis Kluster), dan selesaikan langkah-langkah lain sebagai bagian dari proses pembuatan kluster normal.
Pada tab Konfigurasi , aktifkan Pengalih skala otomatis.
Pilih Skala otomatis berbasis jadwal
Pilih zona waktu Anda lalu klik + Tambahkan aturan
Pilih hari dalam seminggu yang harus diterapkan oleh kondisi baru.
Edit waktu kondisi harus berlaku dan jumlah simpul yang harus diskalakan kluster.
Catatan
- Pengguna harus memiliki peran "pemilik" atau "kontributor" pada kluster MSI agar skala otomatis berfungsi.
- Nilai default menentukan ukuran awal kluster saat dibuat.
- Perbedaan antara dua jadwal diatur ke default sebesar 30 menit.
- Nilai waktu mengikuti format 24 jam
- Dalam kasus jangka waktu yang berjalan secara terus-menerus melebihi 24 jam dalam sehari, Anda harus mengatur Jadwal penskalaan otomatis dalam beberapa hari, dan penskalaan otomatis mengasumsikan 23.59 sebagai 00.00 (dengan jumlah node yang sama) dalam dua hari, dari pukul 22.00 hingga 23.59, 00.00 hingga 02.00, dan pukul 22.00 hingga 02.00.
- Jadwal diatur dalam Waktu Universal Terkoordinasi (UTC), secara default. Anda selalu dapat memperbarui zona waktu yang sesuai dengan zona waktu lokal Anda di drop down yang tersedia. Ketika Anda berada di zona waktu yang mengamati Penghematan Siang Hari, jadwal tidak menyesuaikan secara otomatis, Anda diharuskan untuk mengelola pembaruan jadwal yang sesuai.

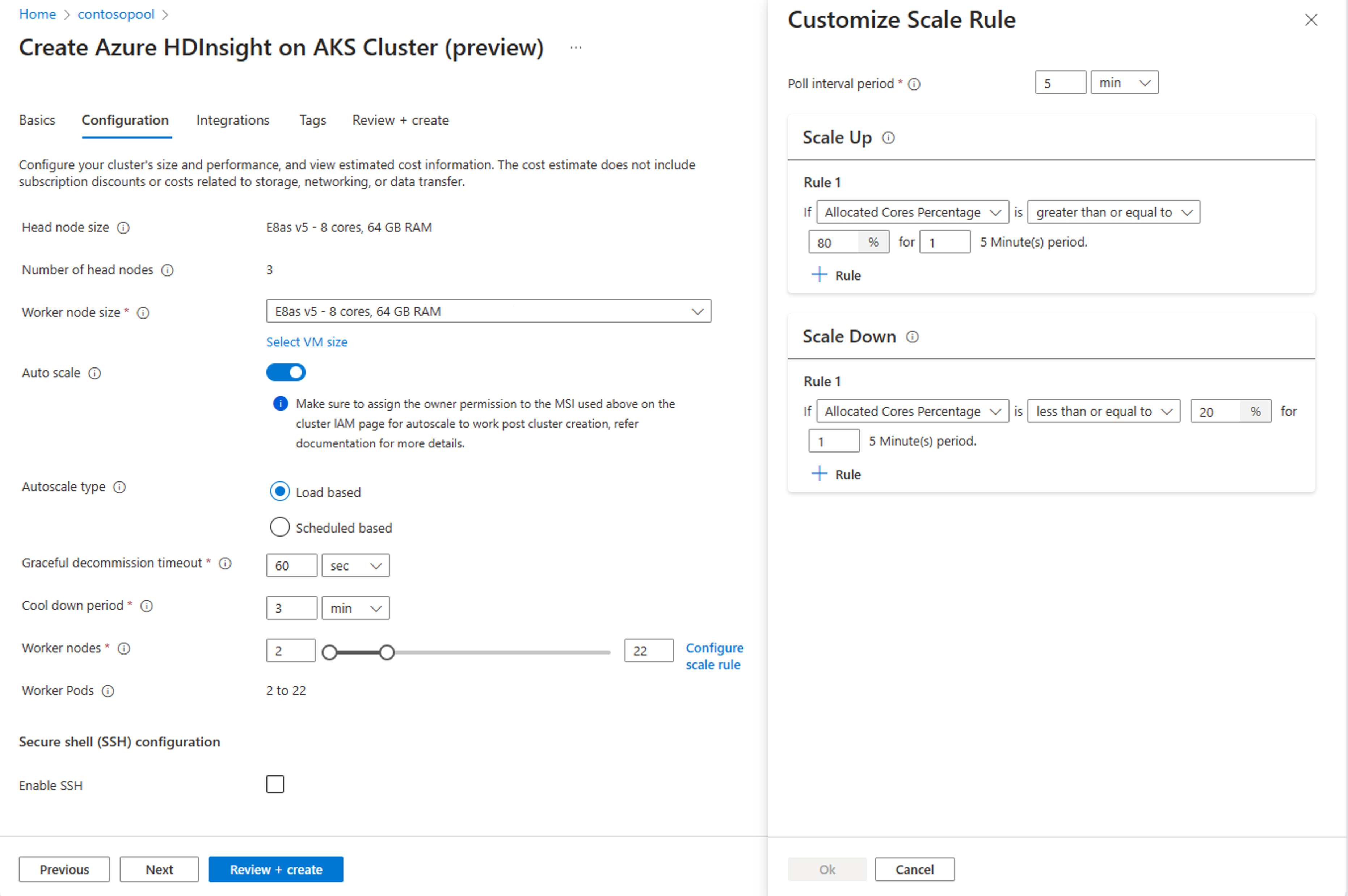
Membuat kluster dengan Skala otomatis berbasis beban
Setelah kumpulan kluster Anda dibuat, buat kluster baru dengan beban kerja yang Anda inginkan (pada jenis Kluster), dan selesaikan langkah-langkah lain sebagai bagian dari proses pembuatan kluster normal.
Pada tab Konfigurasi , aktifkan Pengalih skala otomatis.
Pilih Muat skala otomatis berbasis
Berdasarkan jenis beban kerja, Anda memiliki opsi untuk menambahkan batas waktu penonaktifan yang anggun, periode pendinginan
Pilih simpul minimum dan maksimum , dan jika perlu konfigurasikan aturan skala untuk menyesuaikan Skala otomatis dengan kebutuhan Anda.
Tip
- Langganan Anda memiliki kuota kapasitas untuk setiap wilayah. Jumlah total inti simpul head Anda dan simpul pekerja maksimum tidak dapat melebihi kuota kapasitas. Namun, kuota ini merupakan batas lunak; Anda selalu dapat membuat tiket dukungan untuk meningkatkannya dengan mudah.
- Jika Anda melebihi batas total kuota inti, Anda akan menerima pesan kesalahan yang mengatakan
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Aturan Peningkatan Skala lebih diutamakan ketika satu atau beberapa aturan dipicu. Bahkan jika hanya salah satu aturan untuk meningkatkan skala menyarankan kluster yang kurang disediakan, kluster akan mencoba meningkatkan skala. Agar penurunan skala terjadi, tidak ada aturan peningkatan skala yang harus dipicu.
- Dalam pratinjau publik, HDInsight di AKS mendukung hingga 500 simpul dalam kluster.

Buat jadwal dengan templat Resource Manager
Menjadwalkan skala otomatis berbasis jadwal
Anda dapat membuat HDInsight pada kluster AKS dengan Autoscaling berbasis jadwal menggunakan templat Azure Resource Manager, dengan menambahkan skala otomatis ke bagian clusterProfile -> autoscaleProfile.
Simpul skala otomatis berisi pengulangan yang memiliki zona waktu dan jadwal yang menjelaskan kapan perubahan terjadi. Untuk templat Resource Manager lengkap, lihat contoh JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Tip
- Anda diharuskan untuk mengatur jadwal yang tidak bertentangan menggunakan penyebaran ARM, untuk menghindari kegagalan operasi penskalakan.
Skala otomatis berbasis beban
Anda dapat membuat HDInsight pada kluster AKS dengan Autoscaling berbasis beban menggunakan templat Azure Resource Manager, dengan menambahkan skala otomatis ke bagian clusterProfile -> autoscaleProfile.
Simpul skala otomatis berisi
- interval polling, periode pendinginan,
- penonaktifan yang anggun,
- node minimum dan maksimum,
- aturan ambang batas standar,
- menskalakan metrik yang menjelaskan kapan perubahan terjadi.
Untuk templat Resource Manager lengkap, lihat contoh JSON sebagai berikut
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Menggunakan REST API
Untuk mengaktifkan atau menonaktifkan Skala otomatis pada kluster yang sedang berjalan menggunakan REST API, buat permintaan PATCH ke titik akhir Skala otomatis Anda: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Gunakan parameter yang sesuai dalam muatan permintaan. Payload json dapat digunakan untuk mengaktifkan Skala otomatis.
- Gunakan payload (autoscaleProfile: null) atau gunakan bendera (diaktifkan, false) untuk menonaktifkan Skala otomatis.
- Lihat sampel JSON yang disebutkan pada langkah di atas untuk referensi.
Jeda Skala otomatis untuk kluster yang sedang berjalan
Kami telah memperkenalkan fitur jeda dalam Skala otomatis. Sekarang, dengan menggunakan portal Azure, Anda dapat menjeda Skala otomatis pada kluster yang sedang berjalan. Diagram di bawah ini menggambarkan cara memilih jeda dan melanjutkan skala otomatis

Anda dapat melanjutkan setelah Anda ingin melanjutkan operasi skala otomatis.

Tip
Saat Anda mengonfigurasi beberapa jadwal, dan Anda menjeda skala otomatis, itu tidak memicu jadwal berikutnya. Jumlah simpul tetap sama, bahkan jika simpul dalam keadaan dinonaktifkan.
Menyalin Konfigurasi Skala Otomatis
Dengan menggunakan portal Azure, Anda sekarang dapat menyalin konfigurasi skala otomatis yang sama untuk bentuk kluster yang sama di seluruh kumpulan kluster, Anda dapat menggunakan fitur ini dan mengekspor atau mengimpor konfigurasi yang sama.

Memantau aktivitas skala otomatis
Status kluster
Status kluster yang tercantum dalam portal Azure dapat membantu Anda memantau Aktivitas skala otomatis. Semua pesan status kluster yang mungkin Anda lihat dijelaskan dalam daftar.
| Status kluster | Deskripsi |
|---|---|
| Berhasil | kluster ini beroperasi secara normal. Semua aktivitas Skala otomatis sebelumnya telah berhasil diselesaikan. |
| Diterima | Operasi kluster (misalnya: peningkatan skala) diterima, menunggu operasi selesai. |
| Gagal | Ini berarti operasi saat ini gagal karena beberapa alasan, kluster mungkin tidak berfungsi. |
| Canceled | Operasi saat ini dibatalkan. |
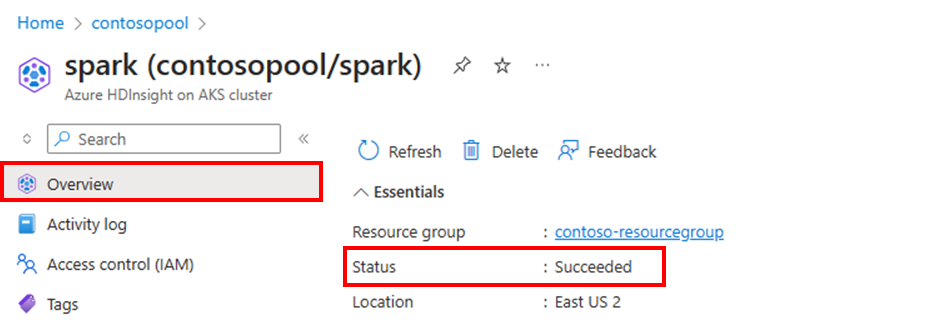
Untuk melihat jumlah simpul saat ini di kluster Anda, buka bagan Ukuran kluster pada halaman Gambaran Umum untuk kluster Anda.

Riwayat operasi
Anda dapat menampilkan penambahan skala kluster dan riwayat penurunan skala sebagai bagian dari metrik kluster. Anda juga dapat mencantumkan semua tindakan penskalakan selama hari, minggu, atau periode terakhir lainnya.

Sumber Daya Tambahan:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk