Mengirimkan dan mengelola pekerjaan pada kluster Apache Spark™ di HDInsight di AKS
Penting
Fitur ini masih dalam mode pratinjau. Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure mencakup lebih banyak persyaratan hukum yang berlaku untuk fitur Azure yang dalam versi beta, dalam pratinjau, atau belum dirilis ke ketersediaan umum. Untuk informasi tentang pratinjau khusus ini, lihat Azure HDInsight pada informasi pratinjau AKS. Untuk pertanyaan atau saran fitur, kirimkan permintaan di AskHDInsight dengan detail dan ikuti kami untuk pembaruan lebih lanjut di Komunitas Azure HDInsight.
Setelah kluster dibuat, pengguna dapat menggunakan berbagai antarmuka untuk mengirimkan dan mengelola pekerjaan dengan
- menggunakan Jupyter
- menggunakan Zeppelin
- menggunakan ssh (spark-submit)
Menggunakan Jupyter
Prasyarat
Kluster Apache Spark™ pada HDInsight di AKS. Untuk informasi selengkapnya, lihat Membuat kluster Apache Spark.
Jupyter Notebook merupakan lingkungan buku catatan interaktif yang mendukung berbagai bahasa pemrogram.
Membuat file Jupyter Notebook
Navigasi ke halaman kluster Apache Spark™ dan buka tab Gambaran Umum . Klik Jupyter, ini meminta Anda untuk mengautentikasi dan membuka halaman web Jupyter.

Dari halaman web Jupyter, Pilih PySpark Baru > untuk membuat buku catatan.
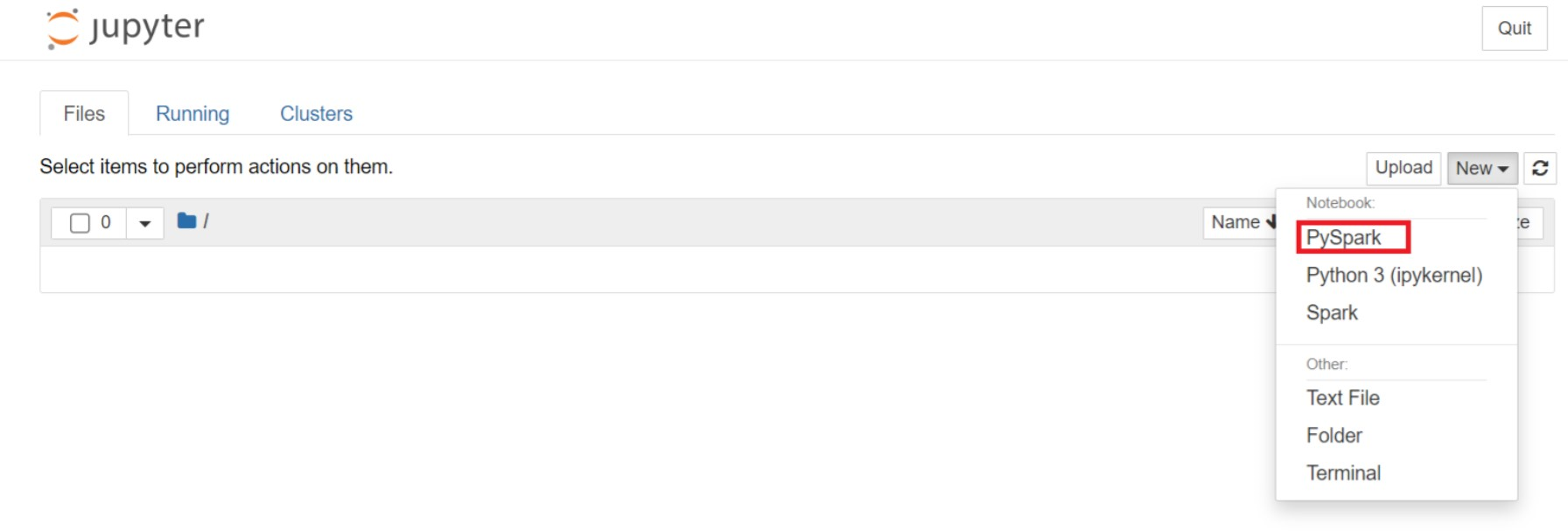
Buku catatan baru dibuat dan dibuka dengan nama
Untitled(Untitled.ipynb).Catatan
Dengan menggunakan kernel PySpark atau Python 3 untuk membuat buku catatan, sesi spark secara otomatis dibuat untuk Anda saat Anda menjalankan sel kode pertama. Anda tidak perlu secara eksplisit membuat sesi.
Tempelkan kode berikut dalam sel kosong Jupyter Netbook, lalu tekan SHIFT + ENTER untuk menjalankan kode. Lihat di sini untuk kontrol lebih lanjut di Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Plot grafik dengan Gaji dan usia sebagai sumbu X dan Y
Di buku catatan yang sama, tempelkan kode berikut di sel kosong Jupyter Notebook, lalu tekan SHIFT + ENTER untuk menjalankan kode.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()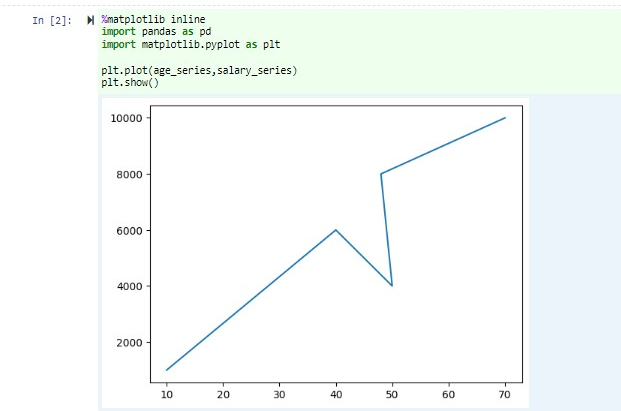




Simpan Buku Catatan
Dari bilah menu buku catatan, navigasikan ke Simpan File > dan Titik Pemeriksaan.
Matikan buku catatan untuk merilis sumber daya kluster: dari bilah menu buku catatan, navigasikan ke Tutup File > dan Hentikan. Anda juga bisa menjalankan salah satu buku catatan di bawah folder contoh.


Menggunakan notebook Apache Zeppelin
Kluster Apache Spark di HDInsight di AKS menyertakan notebook Apache Zeppelin. Gunakan notebook untuk menjalankan pekerjaan Apache Spark. Dalam artikel ini, Anda mempelajari cara menggunakan notebook Zeppelin pada HDInsight pada kluster AKS.
Prasyarat
Kluster Apache Spark pada HDInsight di AKS. Untuk petunjuknya, lihat Membuat kluster Apache Spark.
Meluncurkan notebook Apache Zeppelin
Navigasi ke halaman Gambaran Umum kluster Apache Spark dan pilih notebook Zeppelin dari dasbor Kluster. Ini meminta untuk mengautentikasi dan membuka halaman Zeppelin.
Buat notebook baru. Dari panel header, navigasikan ke Buku Catatan > Buat catatan baru. Pastikan header notebook menampilkan status tersambung. Ini menunjukkan titik hijau di sudut kanan atas.
Jalankan kode berikut di Zeppelin Notebook:
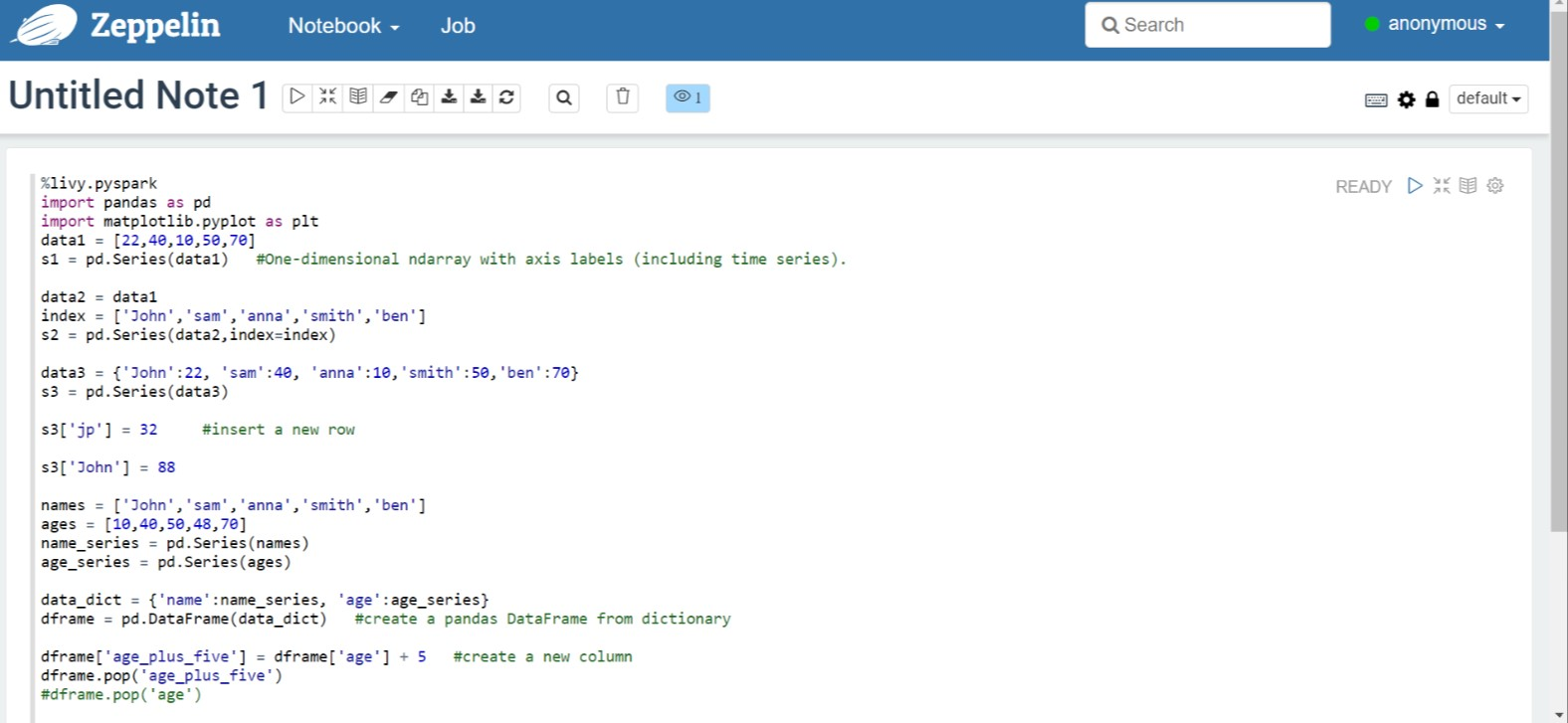
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Pilih tombol Putar untuk paragraf untuk menjalankan cuplikan. Status di sudut kanan paragraf harus berlangsung dari SIAP, DITUNDA, BERJALAN hingga SELESAI. Output muncul di bagian bawah paragraf yang sama. Cuplikan layar terlihat seperti gambar berikut:
Output:





Menggunakan pekerjaan pengiriman Spark
Buat file menggunakan perintah berikut '#vim samplefile.py'
Perintah ini membuka file vim
Tempelkan kode berikut ke dalam file vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Simpan file dengan metode berikut.
- Tekan tombol Escape
- Masukkan perintah
:wq
Jalankan perintah berikut untuk menjalankan pekerjaan.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Memantau kueri pada kluster Apache Spark di HDInsight di AKS
UI Riwayat Spark
Klik antarmuka pengguna Spark History Server dari Tab gambaran umum.

Pilih eksekusi terbaru dari UI menggunakan ID aplikasi yang sama.
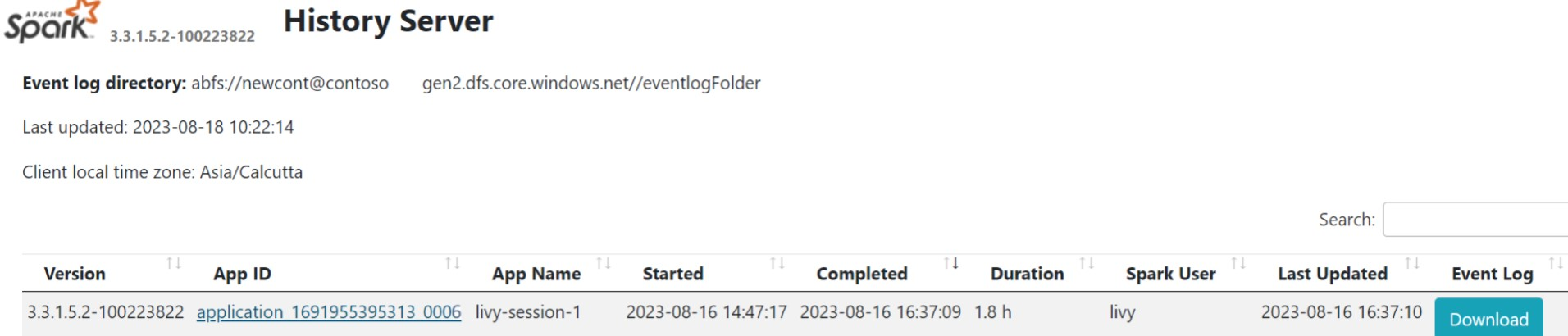
Lihat siklus Grafik Siklik Terarah dan tahapan pekerjaan di antarmuka pengguna server Riwayat Spark.
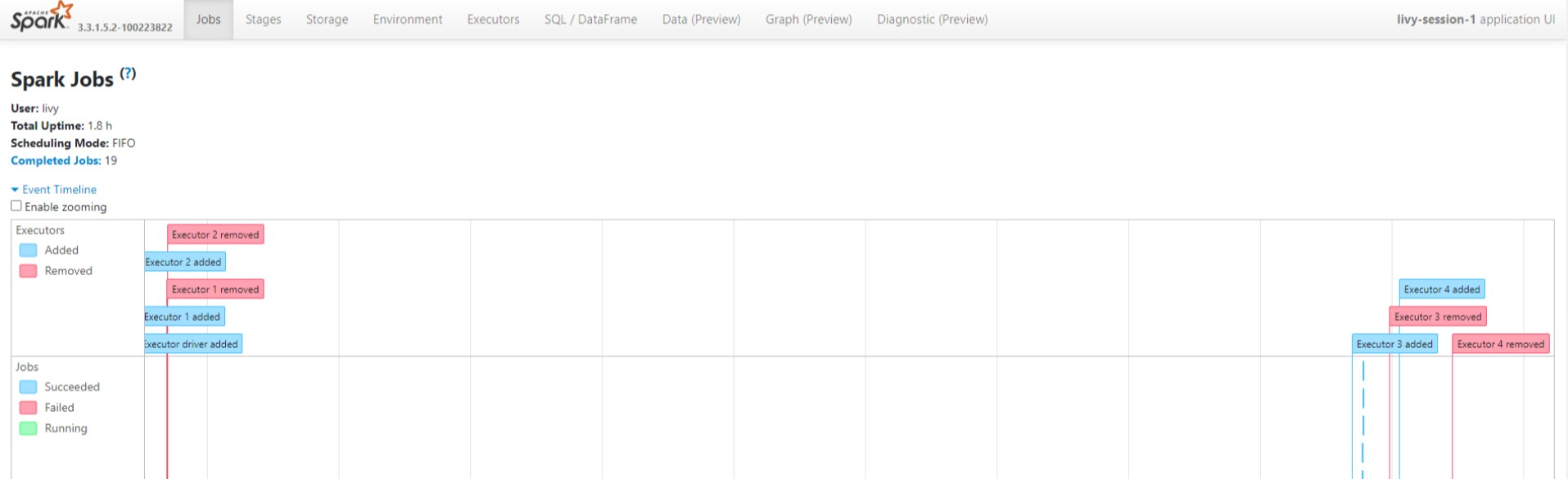



UI sesi Livy
Untuk membuka UI sesi Livy, ketik perintah berikut ke browser Anda
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui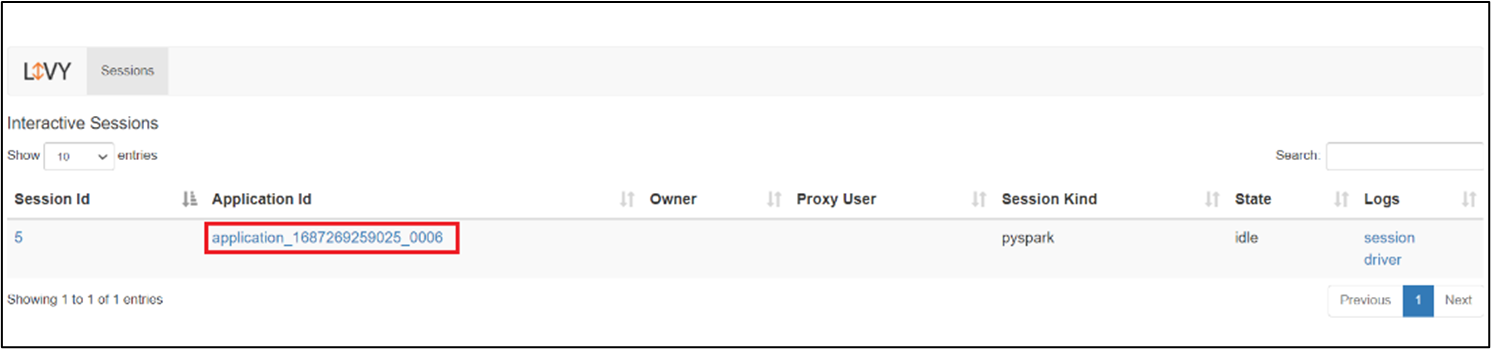
Lihat log driver dengan mengklik opsi driver di bawah log.

Yarn UI
Dari Tab Gambaran Umum klik Yarn dan, buka UI Yarn.
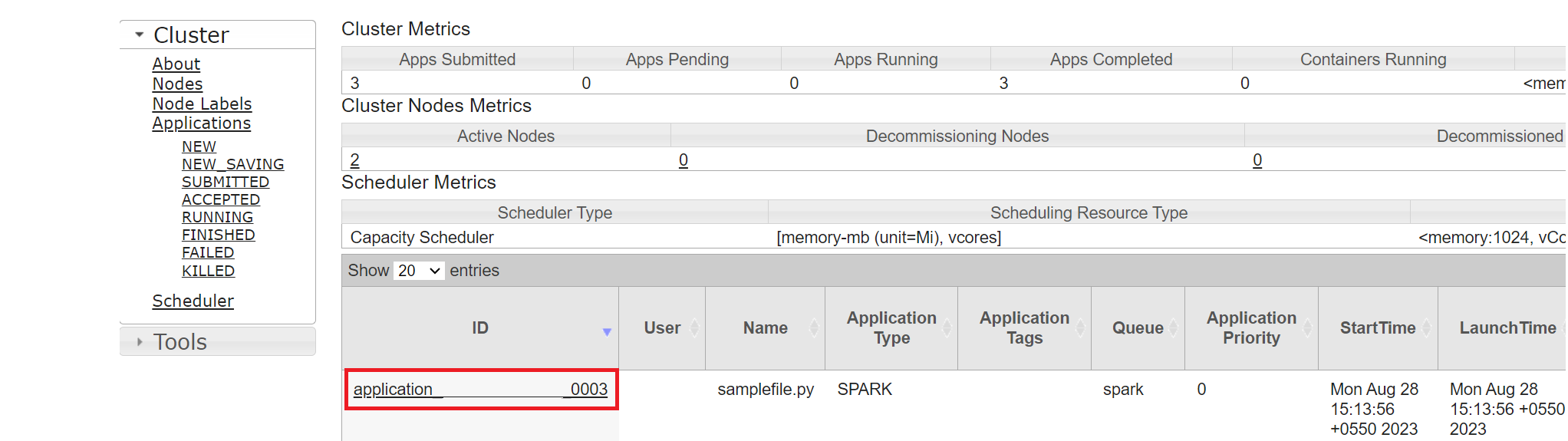
Anda dapat melacak pekerjaan yang baru-baru ini Anda jalankan dengan ID aplikasi yang sama.
Klik ID Aplikasi di Yarn untuk melihat log pekerjaan terperinci.


Referensi
- Apache, Apache Spark, Spark, dan nama proyek sumber terbuka terkait adalah merek dagang dari Apache Software Foundation (ASF).
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk