Jalankan kueri Apache Hive menggunakan alat Data Lake untuk Visual Studio
Pelajari cara menggunakan alat Data Lake untuk Visual Studio untuk mengkueri Apache Hive. Alat Data Lake memungkinkan Anda untuk dengan mudah membuat, mengirimkan, dan memantau kueri Hive ke Apache Hadoop di Azure HDInsight.
Prasyarat
Kluster Apache Hadoop di Microsoft Azure HDInsight. Untuk informasi tentang membuat item ini, lihat Membuat kluster Apache Hadoop di Azure HDInsight menggunakan templat Resource Manager.
Visual Studio. Langkah-langkah dalam dokumen ini menggunakan Visual Studio 2019.
Alat HDInsight untuk alat Visual Studio atau Azure Data Lake untuk Visual Studio. Untuk informasi tentang menginstal dan mengonfigurasi alat, lihat Menginstal Alat Data Lake untuk Visual Studio.
Menjalankan kueri Apache Hive menggunakan Visual Studio
Anda memiliki dua opsi untuk membuat dan menjalankan kueri Hive:
- Membuat kueri ad-hoc.
- Membuat aplikasi Hive.
Membuat kueri Hive ad-hoc
Kueri ad hoc dapat dieksekusi dalam mode Batch atau Interaktif.
Luncurkan Visual Studio dan pilih Lanjutkan tanpa kode.
Dari Server Explorer, klik kanan Azure, pilih Sambungkan ke Langganan Microsoft Azure..., dan selesaikan proses masuk.
Perluas HDInsight, klik kanan kluster tempat Anda ingin menjalankan kueri, lalu pilih Tulis Kueri Hive.
Masukkan kueri Hive berikut:
SELECT * FROM hivesampletable;Pilih Jalankan. Mode eksekusi default ke Interaktif.
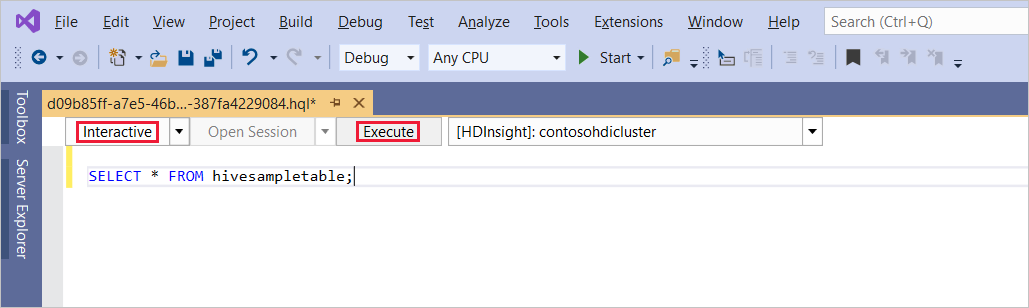
Untuk menjalankan kueri yang sama dalam mode Batch, alihkan daftar pilihan dari Interaktif ke Batch. Tombol eksekusi berubah dari Eksekusi menjadi Kirim.

Editor Apache Hive mendukung IntelliSense. Data Lake Tools untuk Visual Studio mendukung pemuatan metadata jarak jauh saat Anda mengedit skrip Apache Hive. Misalnya, jika Anda mengetik
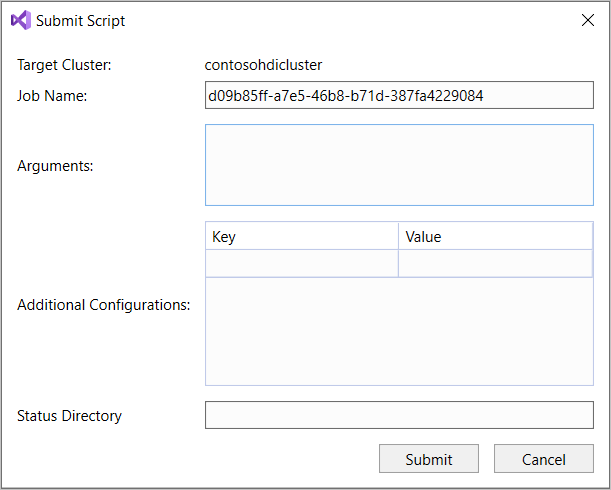
SELECT * FROM, IntelliSense mencantumkan semua nama tabel yang disarankan. Saat nama tabel ditentukan, IntelliSense mencantumkan nama kolom. Alat-alat ini mendukung sebagian besar pernyataan DML Apache Hive, subkueri, dan UDF bawaan. IntelliSense hanya menyarankan metadata kluster yang dipilih di bilah alat HDInsight.Di toolbar kueri (area di bawah tab kueri dan di atas teks kueri), pilih Kirim, atau pilih panah pilihan di samping Kirim dan pilih Tingkat Lanjut dari daftar pilihan. Jika Anda memilih opsi yang terakhir,
Jika Anda memilih opsi kirim lanjutan, konfigurasikan Nama Pekerjaan, Argumen, Konfigurasi Tambahan, dan Direktori Status dalam kotak dialog Kirim Skrip. Lalu pilih Kirim.
Buat aplikasi Hive
Untuk menjalankan kueri Hive dengan membuat aplikasi Hive, ikuti langkah-langkah berikut:
Membuka Visual Studio.
Di jendela Mulai, pilih Buat proyek baru.
Di jendela Buat proyek baru, dalam kotak Cari templat, masukkan Hive. Lalu pilih Aplikasi Hive dan pilih Berikutnya.
Di jendela Konfigurasikan proyek baru Anda, masukkan nama Proyek, pilih atau buat Lokasi untuk proyek baru, lalu pilih Buat.
Buka file Script.hql yang dibuat dengan proyek ini, dan tempelkan dalam pernyataan HiveQL berikut:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Pernyataan ini melakukan tindakan berikut:
DROP TABLE: Menghapus tabel jika ada.CREATE EXTERNAL TABLE: Membuat tabel 'eksternal' baru di Hive. Tabel eksternal hanya menyimpan definisi tabel di Apache Hive. (Data tertinggal di lokasi asli.)Catatan
Tabel eksternal harus digunakan saat Anda mengharapkan data yang mendasarinya diperbarui oleh sumber eksternal, seperti pekerjaan MapReduce atau layanan Azure.
Menjatuhkan tabel eksternal tidak menghapus data, hanya definisi tabel.
ROW FORMAT: Memberi tahu Hive bagaimana data diformat. Dalam hal ini, bidang di setiap log dipisahkan oleh spasi.STORED AS TEXTFILE LOCATION: Memberi tahu Hive bahwa data disimpan dalam direktori contoh/data, dan data disimpan sebagai teks.SELECT: Memilih hitungan semua baris di mana kolomt4berisi nilai[ERROR]. Pernyataan ini mengembalikan nilai dari3, karena tiga baris berisi nilai ini.INPUT__FILE__NAME LIKE '%.log': Memberi tahu Hive untuk hanya mengembalikan data dari file yang berakhiran .log. Klausa ini membatasi pencarian untuk file sample.log yang berisi data.
Dari toolbar file kueri (yang memiliki tampilan yang mirip dengan toolbar kueri ad-hoc), pilih kluster HDInsight yang ingin Anda gunakan untuk kueri ini. Kemudian ubah Interaktif ke Batch (jika perlu) dan pilih Kirim untuk menjalankan pernyataan sebagai Hive job.
Ringkasan Hive Job muncul dan menampilkan informasi tentang pekerjaan yang sedang berjalan. Gunakan tautan Refresh untuk merefresh informasi pekerjaan, hingga Status Pekerjaan berubah menjadi Selesai.
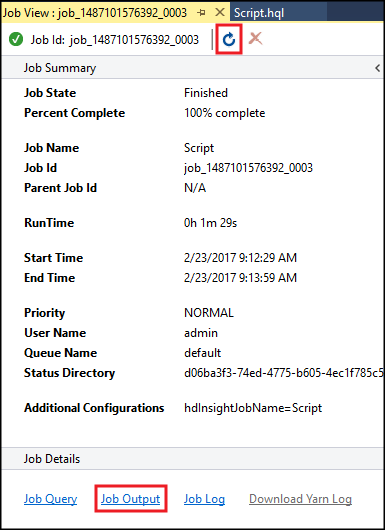
Pilih Output Pekerjaan untuk melihat keluaran dari tugas ini. Ini menampilkan
[ERROR] 3, yang merupakan nilai yang dikembalikan oleh kueri ini.
Contoh tambahan
Contoh berikut bergantung pada tabel log4jLogs yang dibuat dalam prosedur sebelumnya, Buat aplikasi Hive.
Dari Server Explorer, klik kanan kluster Anda dan pilih Tulis Kueri Hive.
Masukkan kueri Hive berikut:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Pernyataan ini melakukan tindakan berikut:
CREATE TABLE IF NOT EXISTS: Membuat tabel jika belum ada. KarenaEXTERNALkata kunci tidak digunakan, pernyataan ini membuat tabel internal. Tabel internal disimpan di gudang data Hive dan dikelola oleh Hive.Catatan
Tidak
EXTERNALseperti tabel, menjatuhkan tabel internal juga menghapus data yang mendasarinya.STORED AS ORC: Menyimpan data dalam format kolom baris (ORC) yang dioptimalkan. ORC adalah format yang sangat dioptimalkan dan efisien untuk menyimpan data Apache Hive.INSERT OVERWRITE ... SELECT: Memilih baris dari tabellog4jLogsyang berisi[ERROR], lalu menyisipkan data ke dalam tabelerrorLogs.
Ubah Interaktif ke Batch jika perlu, lalu pilih Kirim.
Untuk memverifikasi bahwa pekerjaan yang dibuat tabel, buka Server Explorer dan perluas Azure>HDInsight. Perluas kluster HDInsight Anda, lalu perluas Database Hive>default. Tabel errorLogs dan tabel log4jLogs dicantumkan.
Langkah berikutnya
Seperti yang Anda lihat, alat HDInsight untuk Visual Studio menyediakan cara mudah untuk bekerja dengan kueri Hive di HDInsight.
Untuk informasi umum tentang Hive di HDInsight, lihat Apa itu Apache Hive dan HiveQL di Azure HDInsight?
Untuk informasi tentang cara lain Anda dapat bekerja dengan Hadoop di HDInsight, lihat Menggunakan MapReduce di Apache Hadoop di HDInsight
Untuk informasi selengkapnya tentang alat HDInsight untuk Visual Studio, lihatMenggunakan Alat Data Lake untuk Visual Studio untuk menyambungkan ke Azure HDInsight dan menjalankan kueri Apache Hive