Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara memproses dan menganalisis file JavaScript Object Notation (JSON) dengan menggunakan Apache Hive di Azure HDInsight. Artikel ini menggunakan dokumen JSON berikut:
{
"StudentId": "trgfg-5454-fdfdg-4346",
"Grade": 7,
"StudentDetails": [
{
"FirstName": "Peggy",
"LastName": "Williams",
"YearJoined": 2012
}
],
"StudentClassCollection": [
{
"ClassId": "89084343",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "High",
"Score": 93,
"PerformedActivity": false
},
{
"ClassId": "78547522",
"ClassParticipation": "NotSatisfied",
"ClassParticipationRank": "None",
"Score": 74,
"PerformedActivity": false
},
{
"ClassId": "78675563",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "Low",
"Score": 83,
"PerformedActivity": true
}
]
}
File dapat ditemukan di wasb://processjson@hditutorialdata.blob.core.windows.net/. Untuk informasi selengkapnya tentang cara menggunakan penyimpanan Azure Blob dengan HDInsight, lihat Menggunakan penyimpanan Azure Blob HDFS kompatibel dengan Apache Hadoop pada HDInsight. Anda dapat menyalin file ke kontainer default kluster Anda.
Dalam artikel ini, Anda menggunakan konsol Apache Hive. Untuk petunjuk tentang cara membuka konsol Hive, lihat Menggunakan Tampilan Apache Ambari Hive dengan Apache Hadoop di HDInsight.
Catatan
Tampilan Apache Hive tidak lagi tersedia di HDInsight 4.0.
Meratakan dokumen JSON
Metode yang tercantum di bagian berikutnya mengharuskan dokumen JSON terdiri dari satu baris. Jadi, Anda harus meratakan dokumen JSON ke untai (karakter). Jika dokumen JSON Anda sudah diratakan, Anda dapat melewati langkah ini dan langsung masuk ke bagian berikutnya dalam menganalisis data JSON. Untuk meratakan dokumen JSON, jalankan skrip berikut:
DROP TABLE IF EXISTS StudentsRaw;
CREATE EXTERNAL TABLE StudentsRaw (textcol string) STORED AS TEXTFILE LOCATION "wasb://processjson@hditutorialdata.blob.core.windows.net/";
DROP TABLE IF EXISTS StudentsOneLine;
CREATE EXTERNAL TABLE StudentsOneLine
(
json_body string
)
STORED AS TEXTFILE LOCATION '/json/students';
INSERT OVERWRITE TABLE StudentsOneLine
SELECT CONCAT_WS(' ',COLLECT_LIST(textcol)) AS singlelineJSON
FROM (SELECT INPUT__FILE__NAME,BLOCK__OFFSET__INSIDE__FILE, textcol FROM StudentsRaw DISTRIBUTE BY INPUT__FILE__NAME SORT BY BLOCK__OFFSET__INSIDE__FILE) x
GROUP BY INPUT__FILE__NAME;
SELECT * FROM StudentsOneLine
File JSON mentah terletak di wasb://processjson@hditutorialdata.blob.core.windows.net/. Tabel Apache Hive StudentsRaw menunjuk ke dokumen JSON mentah yang tidak diratakan.
Tabel Apache Hive StudentsOneLine menyimpan data dalam sistem file default HDInsight di bawah jalur /json/students/.
Pernyataan INSERT mengisi tabel StudentOneLine dengan data JSON yang diratakan.
Pernyataan SELECT hanya mengembalikan satu baris.
Berikut adalah output dari pernyataan SELECT :

Menganalisis dokumen JSON di Apache Hive
Apache Hive menyediakan tiga mekanisme berbeda untuk menjalankan kueri pada dokumen JSON, atau Anda dapat menulis sendiri:
- Gunakan fungsi get_json_object user-defined (UDF).
- Gunakan UDF json_tuple.
- Gunakan Penserialisasi/Pendeserialisasi (SerDe) kustom.
- Tulis UDF Anda sendiri dengan menggunakan Python atau bahasa lain. Untuk informasi lebih lanjut tentang cara menjalankan kode Python Anda sendiri dengan Hive, lihat Python UDF dengan Apache Hive dan Apache Pig.
Menggunakan UDF get_json_object
Hive menyediakan UDF bawaan yang disebut get_json_object yang mengkueri JSON selama runtime. Metode ini mengambil dua argumen: nama tabel dan nama metode. Nama metode memiliki dokumen JSON yang diratakan dan bidang JSON yang perlu diparsing. Mari kita lihat contoh untuk melihat cara kerja UDF ini.
Kueri berikut mengembalikan nama depan dan nama belakang untuk setiap siswa:
SELECT
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.FirstName'),
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.LastName')
FROM StudentsOneLine;
Berikut adalah output saat Anda menjalankan kueri ini di jendela konsol:
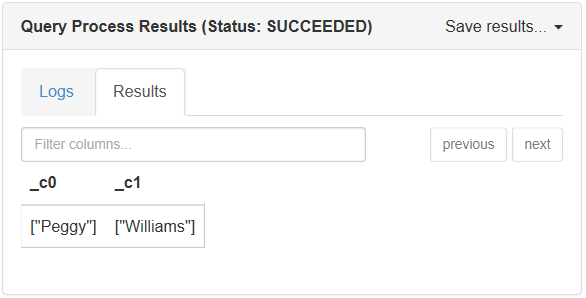
Ada batasan dari UDF get_json_object:
- Karena setiap bidang dalam kueri memerlukan parsing ulang kueri, maka mempengaruhi kinerja.
- GET_JSON_OBJECT() menampilkan representasi string dari array. Untuk mengonversi array ini menjadi array Apache Hive, Anda harus menggunakan ekspresi reguler untuk mengganti kurung siku "[" dan "]", lalu Anda juga harus memanggil pemisahan untuk mendapatkan array.
Konversi inilah yang menjadi alasan wiki Apache Hive menyarankan Anda menggunakan json_tuple.
Menggunakan UDF json_tuple
UDF lain yang disediakan oleh Apache Hive disebut json_tuple, yang lebih baik dari get_ json _object. Metode ini mengambil set kunci dan untai (karakter) JSON. Lalu mengembalikan tupel nilai. Kueri berikut mengembalikan ID siswa dan nilai dari dokumen JSON:
SELECT q1.StudentId, q1.Grade
FROM StudentsOneLine jt
LATERAL VIEW JSON_TUPLE(jt.json_body, 'StudentId', 'Grade') q1
AS StudentId, Grade;
Output dari skrip ini di konsol Apache Hive:
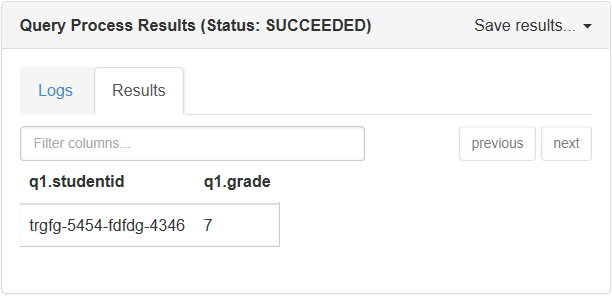
UDF json_tuple menggunakan sintaks tampilan lateral di Hive, yang memungkinkan json_tuple membuat tabel virtual dengan menerapkan fungsi UDT ke setiap baris tabel asli. JSON kompleks menjadi terlalu tidak sehat karena penggunaan TAMPILAN LATERAL yang berulang. Selain itu, JSON_TUPLE tidak dapat menangani JSON bersarang.
Menggunakan SerDe kustom
SerDe adalah pilihan terbaik untuk parsing dokumen JSON bersarang. Ini memungkinkan Anda menentukan skema JSON, kemudian Anda dapat menggunakan skema untuk memparsing dokumen. Untuk instruksi, lihat Cara menggunakan JSON SerDe kustom dengan Microsoft Azure HDInsight.
Ringkasan
Jenis operator JSON di Apache Hive yang Anda pilih tergantung pada skenario Anda. Dengan dokumen JSON sederhana dan satu bidang untuk dilihat, pilih Apache Hive UDF get_json_object. Jika Anda memiliki lebih dari satu kunci untuk dilihat, maka Anda dapat menggunakan json_tuple. Untuk dokumen bersarang, gunakan JSON SerDe.
Langkah berikutnya
Untuk artikel terkait, lihat: