Mulai cepat: Jalankan kueri Apache Hive di Azure HDInsight dengan Apache Zeppelin
Di mulai cepat, Anda mempelajari cara menggunakan Apache Zeppelin untuk menjalankan kueri Apache Hive di Azure HDInsight. Kluster HDInsight Interactive Query menyertakan notebook Apache Zeppelin yang bisa Anda gunakan untuk menjalankan kueri Apache Hive interaktif.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
Kluster HDInsight Interactive Query. Lihat Membuat kluster untuk membuat kluster HDInsight. Pastikan untuk memilih jenis kluster Interactive Query.
Membuat Catatan Apache Zeppelin
Ganti
CLUSTERNAMEdengan nama kluster Anda di URL berikuthttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Kemudian, masukkan URL di browser web.Masukkan nama pengguna dan kata sandi untuk masuk kluster. Dari halaman Zeppelin, Anda dapat membuat catatan baru atau membuka catatan yang sudah ada. HiveSample berisi beberapa contoh kueri Apache Hive.
Pilih Buat catatan baru.
Dari dialog Buat catatan baru, ketik atau pilih nilai berikut ini:
- Nama Catatan: Masukkan nama untuk catatan tersebut.
- Penerjemah default: Pilih jdbc dari daftar turun bawah.
Pilih Buat baru.
Masukkan kueri Apache Hive berikut di bagian kode, lalu tekan Shift + Enter:
%jdbc(hive) show tables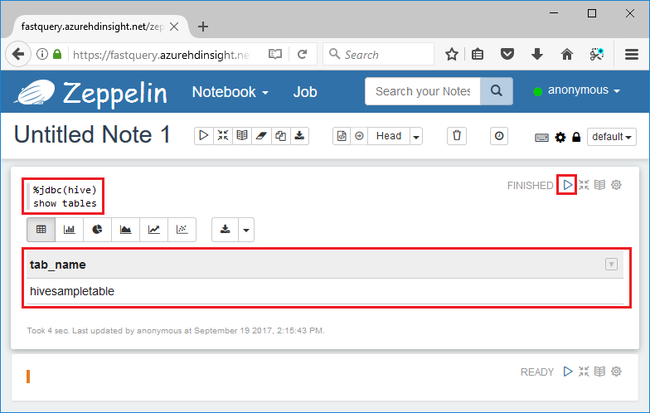
Pernyataan
%jdbc(hive)di baris pertama memberi tahu buku catatan untuk menggunakan penerjemah Apache Hive JDBC.Kueri akan mengembalikan satu tabel Apache Hive yang disebut hivesampletable.
Berikut ini adalah dua kueri Apache Hive lagi yang bisa Anda jalankan terhadap hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Dibandingkan dengan Apache Hive tradisional, hasil kueri kembali jauh lebih cepat.
Contoh lainnya
Membuat tabel. Jalankan kode di Notebook Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Muat data ke dalam tabel baru. Jalankan kode di Notebook Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Sisipkan satu rekaman. Jalankan kode di Notebook Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Tinjau manual bahasa Apache Hive untuk sintaks lainnya.
Membersihkan sumber daya
Setelah Anda menyelesaikan mulai cepat, Anda dapat menghapus kluster. Dengan HDInsight, data Anda disimpan di Azure Storage, sehingga Anda dapat menghapus kluster dengan aman saat tidak digunakan. Anda juga dikenakan biaya untuk klaster HDInsight, bahkan saat tidak digunakan. Karena biaya untuk kluster berkali-kali lebih banyak daripada biaya untuk penyimpanan, masuk akal secara ekonomis untuk menghapus kluster saat tidak digunakan.
Untuk menghapus kluster, lihat Hapus kluster HDInsight menggunakan browser, PowerShell, atau Azure CLI Anda.
Langkah berikutnya
Di mulai cepat, Anda mempelajari cara menggunakan Apache Zeppelin untuk menjalankan kueri Apache Hive di Azure HDInsight. Untuk mempelajari selengkapnya tentang kueri Apache Hive, artikel berikutnya akan memperlihatkan kepada Anda cara menjalankan kueri dengan Visual Studio.