Gunakan Alat Spark & Apache Hive untuk Visual Studio Code
Pelajari cara menggunakan Alat Apache Spark & Apache Hive untuk Visual Studio Code. Gunakan alat untuk membuat dan mengirim tugas batch Apache Hive, kueri Apache Hive interaktif, dan skrip PySpark untuk Apache Spark. Pertama kami akan menjelaskan cara memasang Alat Spark & Apache Hive di Visual Studio Code. Kemudian kita akan membahas cara mengirimkan pekerjaan ke Alat Spark & Apache Hive.
Alat Spark & Apache Hive dapat dipasang pada platform yang didukung oleh Visual Studio Code. Perhatikan prasyarat berikut untuk platform yang berbeda.
Prasyarat
Item berikut diperlukan untuk menyelesaikan langkah-langkah dalam artikel ini:
- Kluster Microsoft Azure HDInsight. Untuk membuat klaster, lihat Mulai menggunakan Microsoft Azure HDInsight. Atau gunakan kluster Spark dan Apache Hive yang mendukung titik akhir Apache Livy.
- Visual Studio Code.
- Mono. Mono hanya diperlukan untuk Linux dan macOS.
- Lingkungan interaktif PySpark untuk Visual Studio Code.
- Direktori lokal. Artikel ini menggunakan C:\HD\HDexample.
Instal Alat Spark & Apache Hive
Setelah Anda memenuhi prasyarat, Anda dapat memasang Alat Spark & Apache Hive untuk Visual Studio Code dengan mengikuti langkah-langkah berikut:
Buka Visual Studio Code.
Dari bilah menu, navigasikan ke Lihat>Ekstensi.
Di kotak pencarian, masukkan Spark & Apache Hive.
Pilih Alat Spark & Apache Hive dari hasil pencarian, lalu pilih Instal:
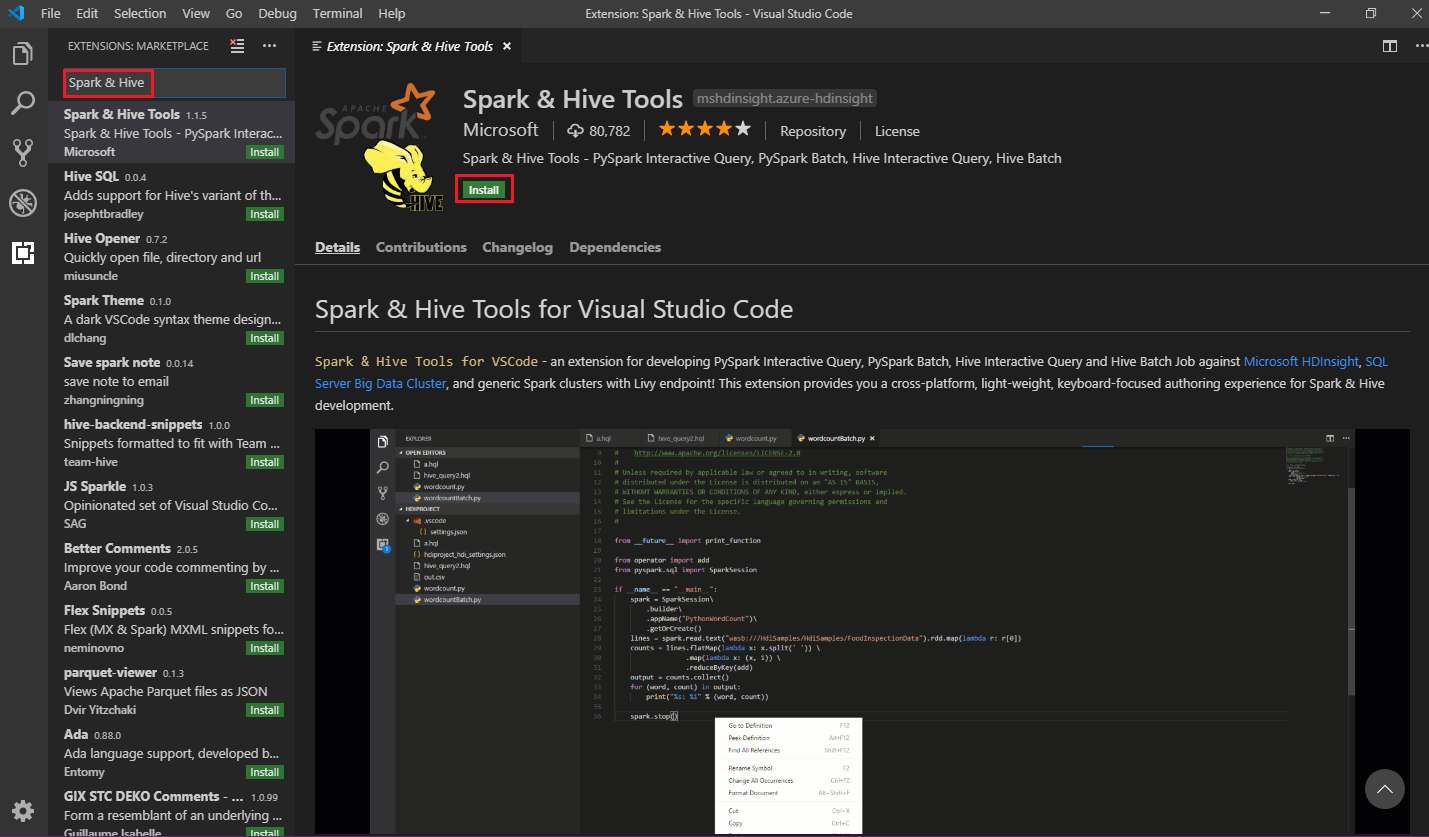
Pilih Muat ulang bila perlu.
Membuka folder kerja
Untuk membuka folder kerja dan membuat file di Visual Studio Code, ikuti langkah-langkah berikut:
Dari bilah menu, arahkan ke Folder>Buka File...>C:\HD\HDexample, lalu pilih tombol Pilih Folder. Folder muncul dalam tampilan Penjelajah di sebelah kiri.
Di tampilan Explorer, pilih folder HDexample, lalu pilih ikon File Baru di samping folder kerja:
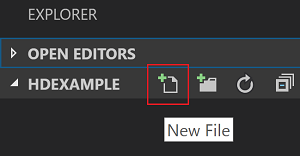
Beri nama file baru dengan menggunakan ekstensi
.hqlfile (Kueri Apache Hive) atau.py(Skrip spark). Contoh ini menggunakan HelloWorld.hql.
Set lingkungan Azure
Untuk pengguna internet nasional, ikuti langkah-langkah ini untuk mengatur lingkungan Azure terlebih dahulu, lalu gunakan perintah Azure: Masuk untuk masuk ke Azure:
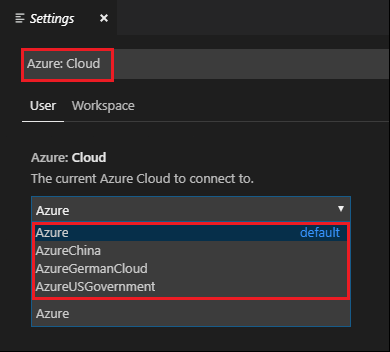
Buka File>Preferensi>Pengaturan.
Cari pada untai (karakter) berikut: Azure: Cloud.
Pilih cloud nasional dari daftar:
Menyambungkan ke akun Azure
Sebelum Anda dapat mengirimkan skrip ke kluster Anda dari Visual Studio Code, pengguna dapat masuk ke langganan Azure, atau menautkan kluster Microsoft Azure HDInsight. Gunakan nama pengguna/kata sandi Ambari atau info masuk bergabung dengan domain untuk kluster ESP untuk menyambungkan ke kluster Microsoft Azure HDInsight Anda. Ikuti langkah-langkah ini untuk menyambungkan ke Azure:
Dari bilah menu, arahkan ke Tampilkan>Palet Perintah..., dan masukkan Azure: Masuk:
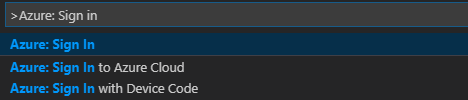
Ikuti instruksi masuk untuk masuk ke Azure. Setelah Anda tersambung, nama akun Azure Anda ditampilkan di bilah status di bagian bawah jendela Visual Studio Code.
Tautkan kluster
Tautkan: Microsoft Azure HDInsight
Anda dapat menautkan kluster normal dengan menggunakan nama pengguna apache Ambari-managed, atau Anda dapat menautkan kluster Hadoop aman Paket Enterprise Security dengan menggunakan nama pengguna domain (seperti: user1@contoso.com ).
Dari bilah menu, arahkan ke Lihat>Palet Perintah ..., dan masukkan Spark / Apache Hive: Tautkan Kluster.

Pilih jenis kluster tertaut Microsoft Azure HDInsight.
Masukkan URL kluster Microsoft Azure HDInsight.
Masukkan nama pengguna Ambari Anda; defaultnya adalah admin.
Masukkan kata sandi Ambari Anda.
Pilih jenis kluster.
Set nama tampilan kluster (opsional).
Tinjau tampilan OUTPUT untuk verifikasi.
Catatan
Nama pengguna dan kata sandi yang ditautkan digunakan jika kluster masuk ke langganan Azure dan menautkan kluster.
Tautkan: Titik akhir Generic Livy
Dari bilah menu, arahkan ke Lihat>Palet Perintah ..., dan masukkan Spark / Apache Hive: Tautkan Kluster.
Pilih jenis kluster tertaut Titik akhir Generic Livy.
Masukkan titik akhir Livy generik. Misalnya: http://10.172.41.42:18080.
Pilih jenis autorisasi Dasar atau Tidak Ada. Jika Anda memilih Dasar:
Masukkan nama pengguna Ambari Anda; defaultnya adalah admin.
Masukkan kata sandi Ambari Anda.
Tinjau tampilan OUTPUT untuk verifikasi.
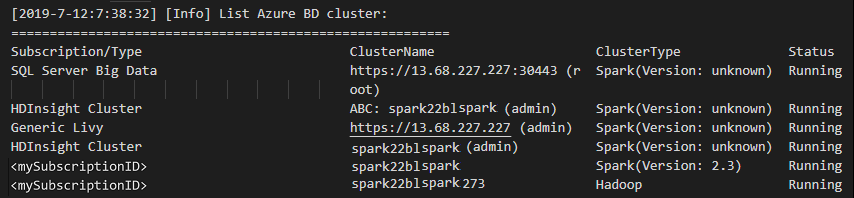
Mencantumkan klaster
Dari bilah menu, arahkan ke Lihat>Palet Perintah ..., dan masukkan Spark / Apache Hive: Tautkan Kluster.
Pilih langganan yang Anda inginkan.
Tinjau tampilan OUTPUT. Tampilan ini memperlihatkan kluster (atau kluster) tertaut Anda dan semua kluster di bawah langganan Azure Anda:
Set kluster default
Buka kembali folder HDexample yang dibahas sebelumnya,jika ditutup.
Pilih file HelloWorld.hql yang dibuat sebelumnya. File ini terbuka di editor skrip.
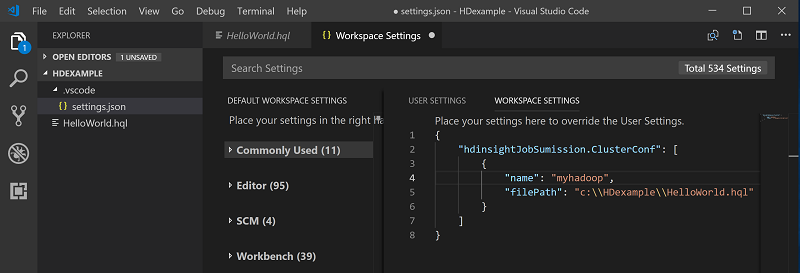
Klik kanan editor skrip, lalu pilih Spark / Apache Hive: Set Kluster Default.
Sambungkan ke akun Azure Anda, atau tautkan kluster jika Anda belum melakukannya.
Pilih kluster sebagai kluster default untuk file skrip saat ini. Alat secara otomatis memperbarui .VSCode\settings.jspada file konfigurasi:
Kirim kueri Apache Hive interaktif dan skrip batch Apache Hive
Dengan Alat Spark & Apache Hive for Visual Studio Code, Anda dapat mengirimkan kueri Apache Hive interaktif dan skrip batch Apache Hive ke kluster Anda.
Buka kembali folder HDexample yang dibahas sebelumnya,jika ditutup.
Pilih file HelloWorld.hql yang dibuat sebelumnya. File ini terbuka di editor skrip.
Salin dan tempel kode berikut ke dalam file Apache Hive Anda, lalu simpan:
SELECT * FROM hivesampletable;Sambungkan ke akun Azure Anda, atau tautkan kluster jika Anda belum melakukannya.
Klik kanan editor skrip dan pilih Apache Hive: Interaktif untuk mengirimkan kueri, atau gunakan pintasan papan ketik Ctrl+Alt+I. Pilih Apache Hive: Batch untuk mengirimkan skrip, atau gunakan pintasan papan ketik Ctrl+Alt+H.
Jika Anda belum menentukan kluster default, pilih kluster. Alat ini juga memungkinkan Anda mengirimkan blok kode, bukan seluruh file skrip dengan menggunakan menu konteks. Setelah beberapa saat, hasil kueri muncul di tab baru:
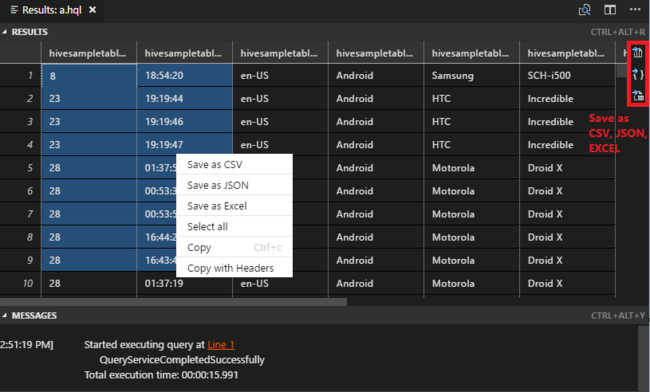
Panel HASIL: Anda dapat menyimpan seluruh hasil sebagai file CSV, JSON, atau Excel ke jalur lokal atau hanya memilih beberapa baris.
Panel PESAN: Saat Anda memilih nomor Baris, panel akan melompat ke baris pertama skrip yang sedang berjalan.
Kirim kueri PySpark interaktif
Prasyarat untuk interaktif Pyspark
Perhatikan di sini bahwa versi Ekstensi Jupyter (ms-jupyter): v2022.1.1001614873 dan versi Ekstensi Python (ms-python): v2021.12.1559732655, Python 3.6.x dan 3.7.x diperlukan untuk kueri PySpark interaktif HDInsight.
Pengguna dapat melakukan interaktif PySpark dengan cara berikut.
Menggunakan perintah interaktif PySpark dalam file PY
Menggunakan perintah interaktif PySpark untuk mengirimkan kueri, ikuti langkah-langkah berikut:
Buka kembali folder HDexample yang dibahas sebelumnya,jika ditutup.
Buat file HelloWorld.py baru, dengan mengikuti langkah sebelumnya.
Salin dan tempel kode berikut ke dalam file skrip:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Perintah untuk memasang kernel PySpark/Pyspark Synapse ditampilkan di sudut kanan bawah jendela. Anda dapat mengklik tombol Instal untuk melanjutkan instalasi PySpark / Synapse Pyspark; atau klik tombol Lewati untuk melewati langkah ini.
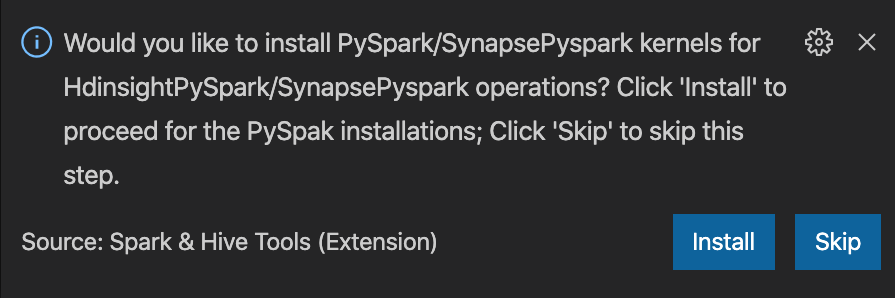
Jika Anda perlu menginstalnya nanti, Anda dapat mengarahkan ke Pengaturan Preferensi File, lalu menghapus centang >>Microsoft Azure HDInsight: Aktifkan Instalasi Pyspark Lewati di pengaturan.
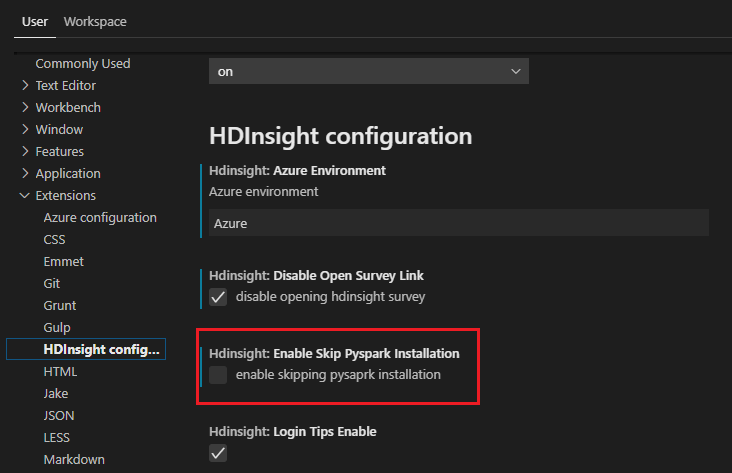
Jika instalasi berhasil di langkah 4, kotak pesan "PySpark berhasil diinstal" ditampilkan di sudut kanan bawah jendela. Klik tombol Muat Ulang untuk memuat ulang jendela.
Dari bilah menu, navigasikan ke Lihat>Palet Perintah... atau gunakan pintasan papan tombol Shift + Ctrl + P, dan masukkan Python: Pilih Juru Bahasa untuk memulai Server Jupyter.

Pilih opsi Python di bawah ini.

Dari bilah menu, arahkan ke Tampilkan>Palet Perintah... atau gunakan pintasan papan ketikShift + Ctrl + P, dan masukkan Pengembang: Muat Ulang Jendela.

Sambungkan ke akun Azure Anda, atau tautkan kluster jika Anda belum melakukannya.
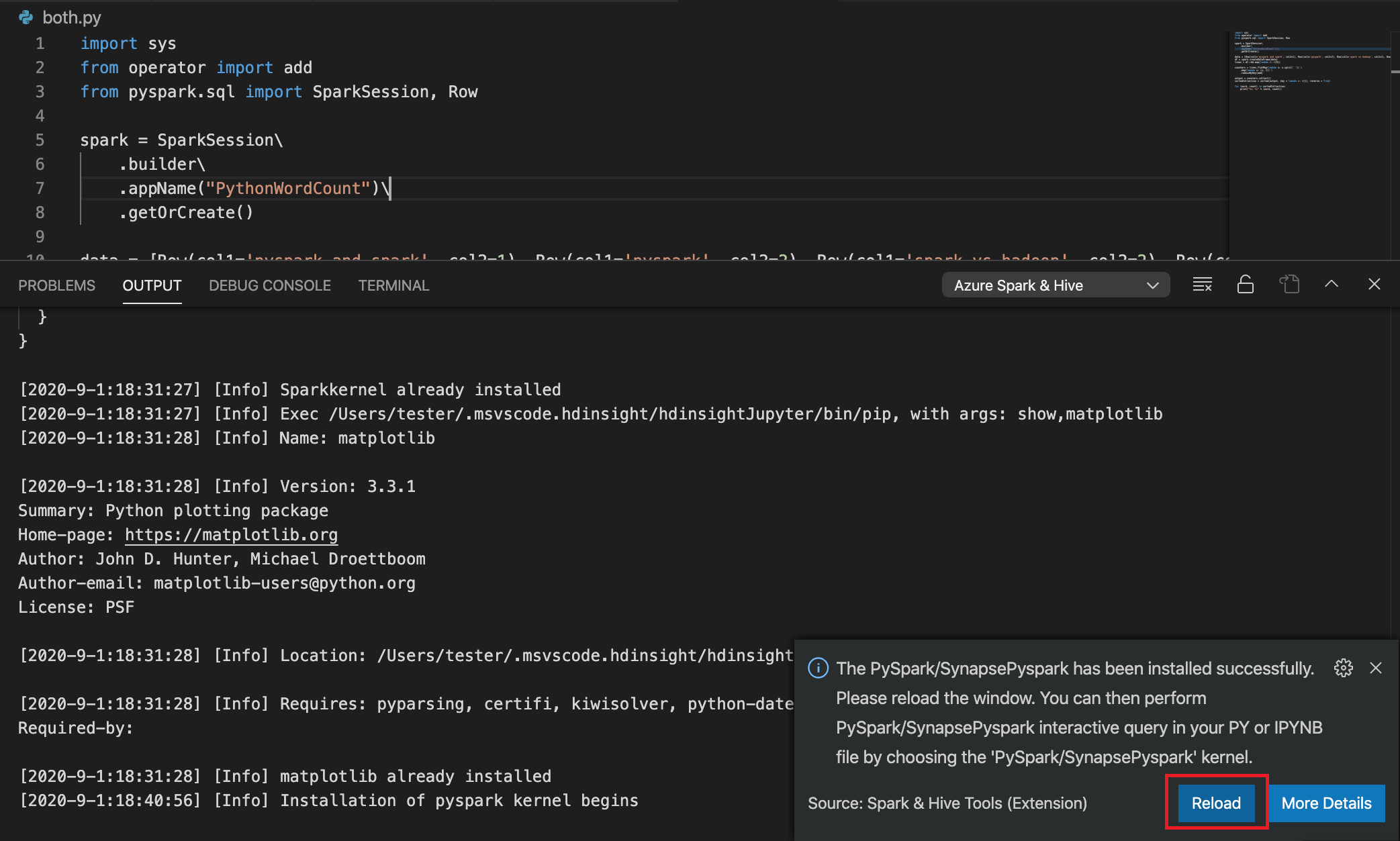
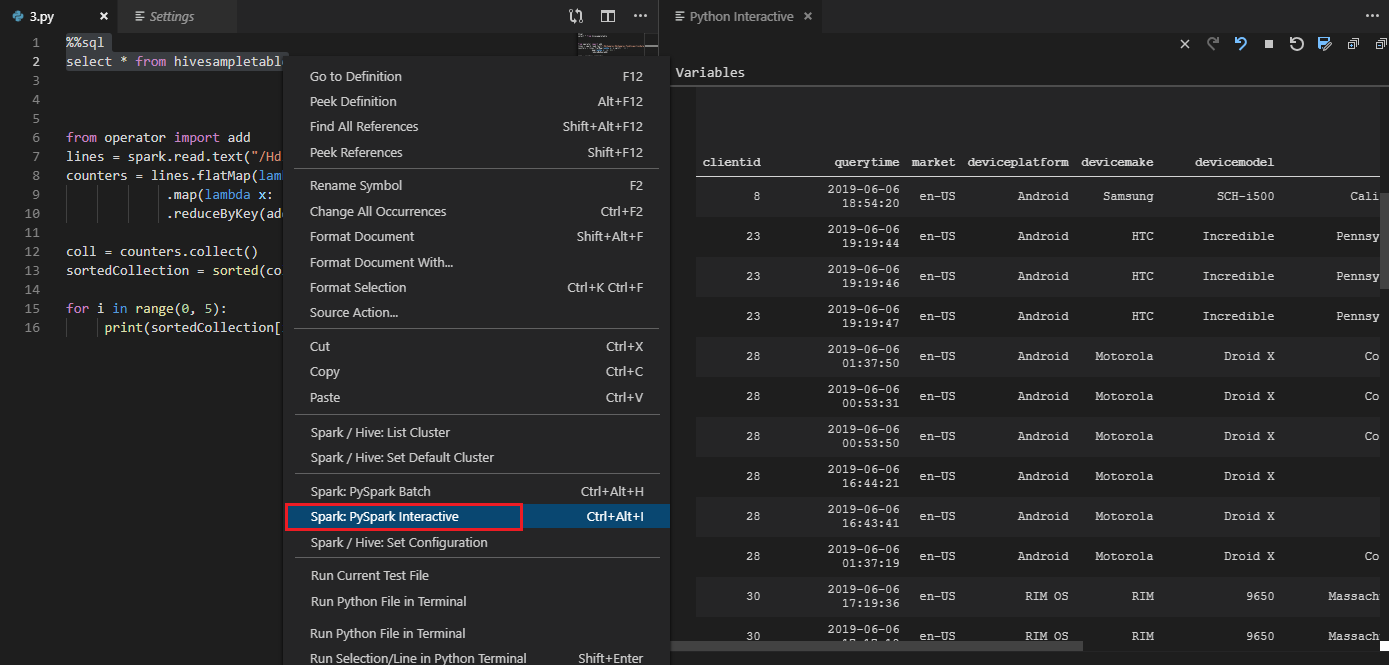
Pilih semua kode, klik kanan editor skrip, dan pilih Spark: PySpark Interactive / Synapse: Pyspark Interactive untuk mengirimkan kueri.
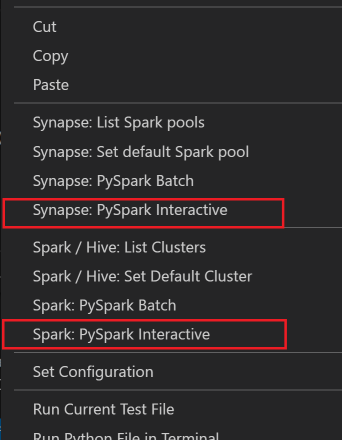
Jika Anda belum menentukan kluster default, pilih kluster. Setelah beberapa saat, hasil Python Interactive muncul di tab baru. Klik PySpark untuk mengalihkan kernel ke PySpark / Synapse Pyspark,dan kode akan berjalan dengan sukses. Jika Anda ingin beralih ke kernel Synapse Pyspark, menonaktifkan pengaturan otomatis di portal Microsoft Azure akan didorong. Jika tidak, mungkin perlu waktu lama untuk mengaktifkan kluster dan mengatur kernel synapse untuk penggunaan pertama kali. Alat ini juga memungkinkan Anda mengirimkan blok kode, bukan seluruh file skrip dengan menggunakan menu konteks:
Masukkan %%info, lalu tekan Shift+Enter untuk melihat informasi pekerjaan (opsional):
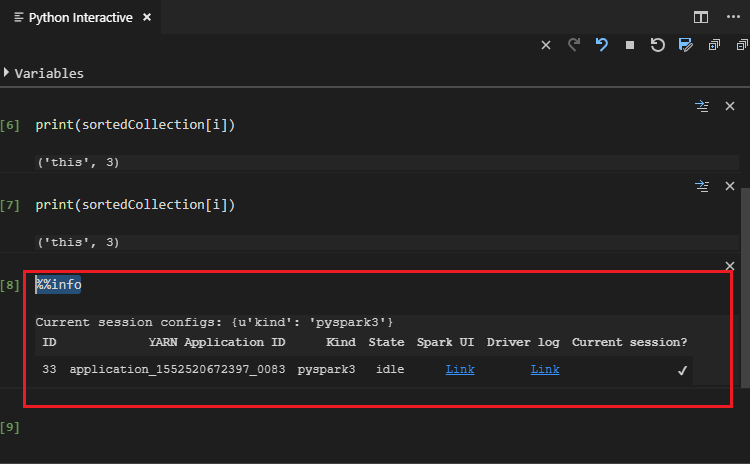
Alat ini juga mendukung kueri Spark SQL:
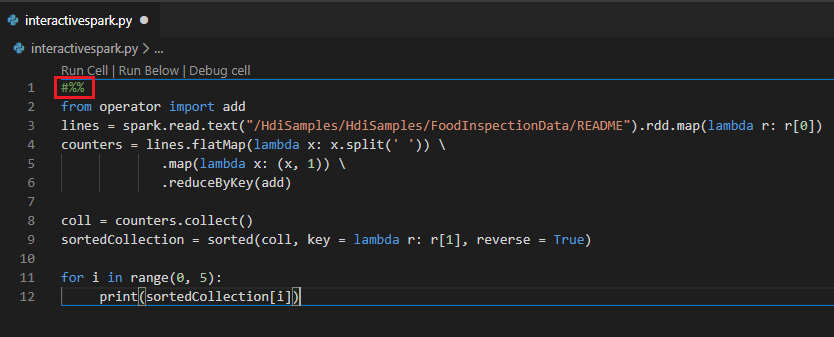
Melakukan kueri interaktif dalam file PY menggunakan komentar #%%
Tambahkan #%% sebelum kode Py untuk mendapatkan pengalaman buku catatan.
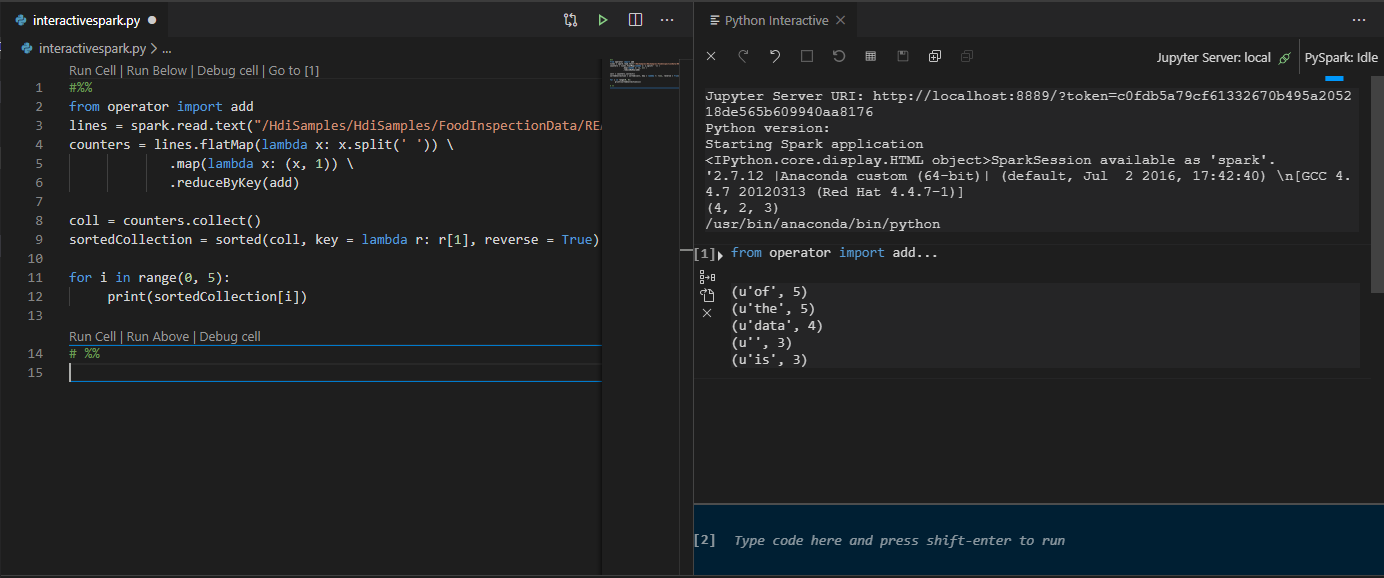
Klik Jalankan Sel. Setelah beberapa saat, hasil Interaktif Python muncul di tab baru. Klik PySpark untuk mengalihkan kernel ke PySpark / Synapse Pyspark, lalu klik pada Jalankan Sel kembali dan kode akan berjalan dengan sukses.
Manfaatkan dukungan IPYNB dari ekstensi Python
Anda dapat membuat Buku Catatan Jupyter dengan perintah dari Palet Perintah atau dengan membuat file .ipynb baru di ruang kerja. Untuk informasi selengkapnya, lihat Bekerja dengan Buku Catatan Jupyter di Visual Studio Code
Klik tombol Jalankan sel, ikuti perintah untuk Mengatur kumpulan percikan default (sangat mendorong untuk mengatur kluster/kumpulan default setiap kali sebelum membuka buku catatan) lalu, muat ulang jendela.
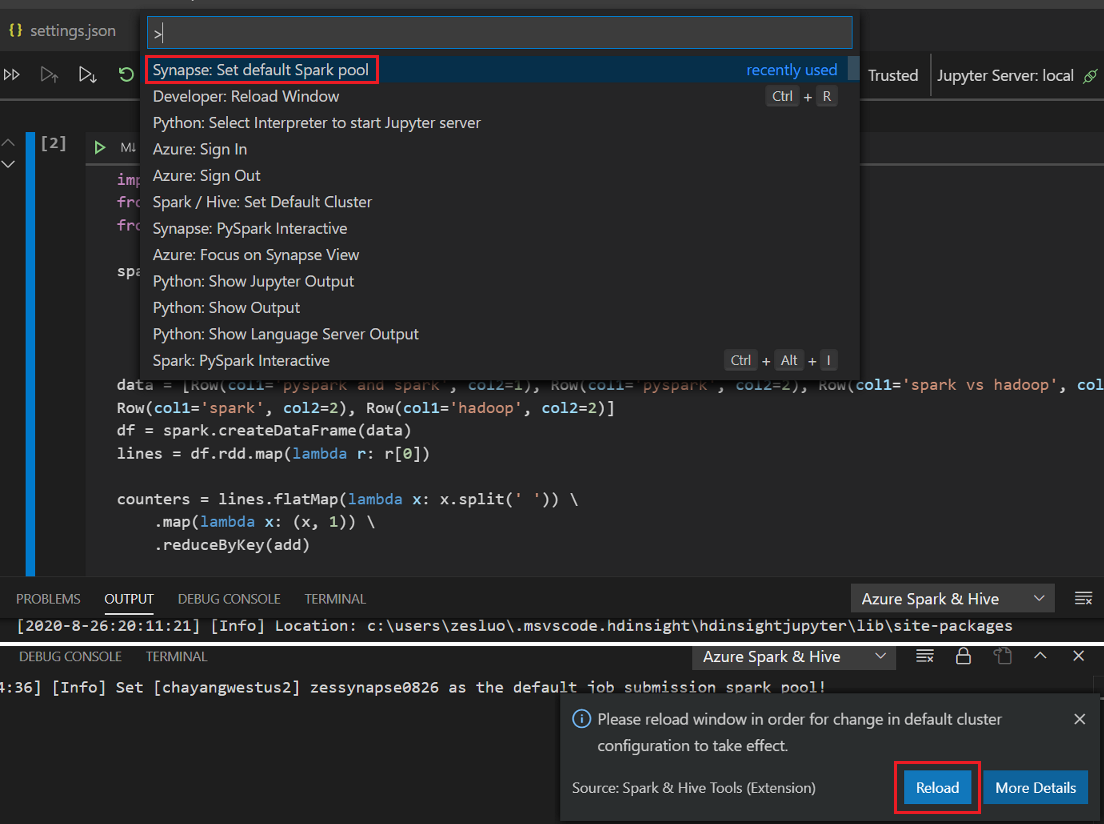
Klik PySpark untuk beralih kernel ke PySpark / Synapse Pyspark,dan kemudian klik Jalankan Sel,setelah beberapa saat, hasilnya akan ditampilkan.
Catatan
Untuk kesalahan penginstalan Synapse PySpark, karena dependensinya tidak akan dipertahankan lagi oleh tim lain, Synapse PySpark juga tidak akan dipertahankan lagi. Jika Anda mencoba menggunakan interaktif Synapse Pyspark, harap beralih menggunakan Azure Synapse Analytics sebagai gantinya. Dan perubahan ini bersifat jangka panjang.
Kirim pekerjaan batch PySpark
Buka kembali folder HDexample yang dibahas sebelumnya,jika ditutup.
Buat file BatchFile.py dengan mengikuti langkah-langkah sebelumnya.
Salin dan tempel kode berikut ke dalam file skrip:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Sambungkan ke akun Azure Anda, atau tautkan kluster jika Anda belum melakukannya.
Klik kanan editor skrip, lalu pilih Spark: PySpark Batch,atau Synapse: PySpark Batch*.
Pilih kumpulan kluster/spark untuk mengirimkan pekerjaan PySpark Anda ke:
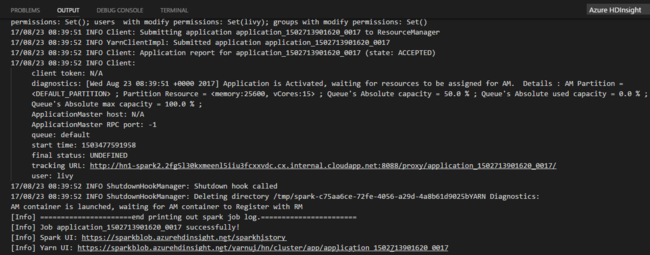
Setelah Anda mengirimkan pekerjaan Python, log pengiriman muncul di jendela OUTPUT di Visual Studio Code. URL Spark UI dan URL UI YARN juga ditampilkan. Jika Anda mengirimkan pekerjaan batch ke kumpulan Apache Spark, URL UI riwayat Spark dan URL UI Aplikasi Pekerjaan Spark juga ditampilkan. Anda dapat membuka URL di browser web untuk melacak status pekerjaan.
Integrasikan dengan Perantara Identitas Microsoft Azure HDInsight (HIB)
Sambungkan ke kluster Microsoft Azure HDInsight ESP Anda dengan Perantara ID (HIB)
Anda dapat mengikuti langkah-langkah normal untuk masuk ke langganan Azure untuk menyambungkan ke kluster Microsoft Azure HDInsight ESP Anda dengan Perantara ID (HIB). Setelah masuk, Anda akan melihat daftar kluster di Azure Explorer. Untuk petunjuk selengkapnya, lihat Sambungkan ke kluster Microsoft Azure HDInsight Anda.
Jalankan pekerjaan Apache Hive /PySpark pada kluster Microsoft Azure HDInsight ESP dengan Perantara ID (HIB)
Untuk menjalankan pekerjaan hive, Anda dapat mengikuti langkah-langkah normal untuk mengirimkan pekerjaan ke kluster Microsoft Azure HDInsight ESP dengan Perantara ID (HIB). Lihat Kirimkan kueri Apache Hive interaktif dan skrip batch Apache Hive untuk instruksi lebih lanjut.
Untuk menjalankan pekerjaan PySpark interaktif, Anda dapat mengikuti langkah-langkah normal untuk mengirimkan pekerjaan ke kluster HDInsight ESP dengan ID Broker (HIB). Liht Mengirim kueri PySpark interaktif.
Untuk menjalankan pekerjaan hive, Anda dapat mengikuti langkah-langkah normal untuk mengirimkan pekerjaan ke kluster Microsoft Azure HDInsight ESP dengan Perantara ID (HIB). Lihat untuk mengirimkan Pekerjaan batch PySpark untuk petunjuk lebih lanjut.
Konfigurasi Apache Livy
Konfigurasi Apache Livy didukung. Anda dapat mengonfigurasinya di .VSCode\settings.jspada file di folder ruang kerja. Saat ini, konfigurasi Livy hanya mendukung skrip Python. Untuk informasi selengkapnya, lihat livy README.
Bagaimana memicu konfigurasi Livy
Metode 1
- Dari bilah menu, arahkan ke >Pengaturan Preferensi>File.
- Di kotak Pengaturan pencarian, masukkan Pengiriman Pekerjaan Microsoft Azure HDInsight: Livy Conf.
- Pilih Edit di settings.json untuk hasil pencarian yang relevan.
Metode 2
Kirim file, dan perhatikan bahwa .vscode folder secara otomatis ditambahkan ke folder kerja. Anda dapat melihat konfigurasi Livy dengan memilih .vscode\settings.jspada.
Pengaturan proyek:
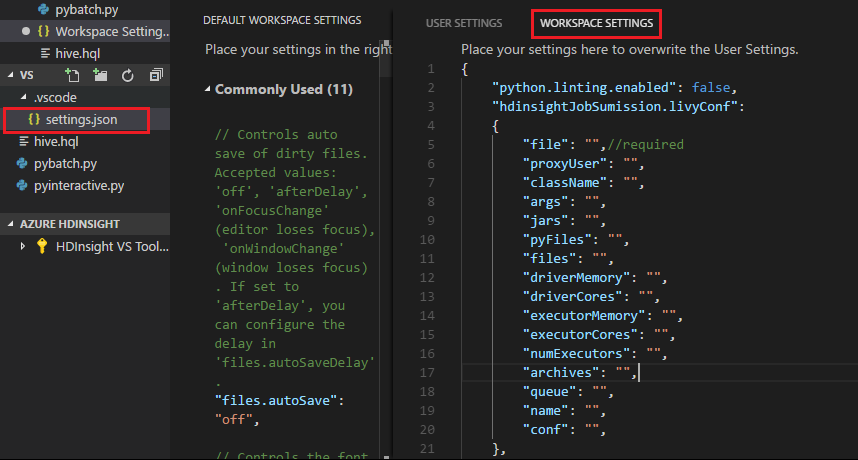
Catatan
Untuk pengaturan driverMemorydan executorMemory, set nilai dan unit. Misalnya: 1g atau 1024m.
Konfigurasi Livy yang didukung:
POST /batch
Badan permintaan
nama description jenis file File yang berisi aplikasi yang akan dijalankan Jalur (diperlukan) proxyUser Pengguna untuk meniru ketika menjalankan pekerjaan String className Kelas utama Java/Spark aplikasi String argumen Argumen baris perintah untuk aplikasi Daftar untai(karakter) jar Jar yang akan digunakan dalam sesi ini Daftar untai(karakter) pyFile File Python yang akan digunakan dalam sesi ini Daftar untai(karakter) file File yang akan digunakan dalam sesi ini Daftar untai(karakter) driverMemory Jumlah memori yang digunakan untuk proses driver String driverCores Jumlah inti yang digunakan untuk proses driver Int executorMemory Jumlah memori yang digunakan per proses pelaksana String executorCores Jumlah inti yang digunakan untuk setiap pelaksana Int NumExecutors Jumlah pelaksana yang akan diluncurkan untuk sesi ini Int arsip Arsip yang akan digunakan dalam sesi ini Daftar untai(karakter) queue Nama antrean YARN yang akan diserahkan ke String nama Nama sesi ini String conf Properti konfigurasi spark Peta key=val Badan respons Objek Batch yang dibuat.
nama description jenis ID ID Sesi Int appId ID aplikasi sesi ini String appInfo Info aplikasi terperinci Peta key=val log Log baris Daftar untai(karakter) state Status batch String Catatan
Konfigurasi Livy yang ditetapkan ditampilkan di panel output saat Anda mengirimkan skrip.
Integrasikan dengan Microsoft Azure HDInsight dari Explorer
Anda dapat melihat pratinjau Tabel Apache Hive di kluster Anda secara langsung melalui explorer Microsoft Azure HDInsight:
Sambungkan ke akun Azure Anda jika belum melakukannya.
Pilih ikon Azure dari kolom paling kiri.
Dari panel kiri, perluas AZURE: HDINSIGHT. Langganan dan kluster yang tersedia dicantumkan.
Perluas kluster untuk menampilkan database metadata Apache Hive dan skema tabel.
Klik kanan tabel Apache Hive. Misalnya: hivesampletable. pilih Pratinjau.
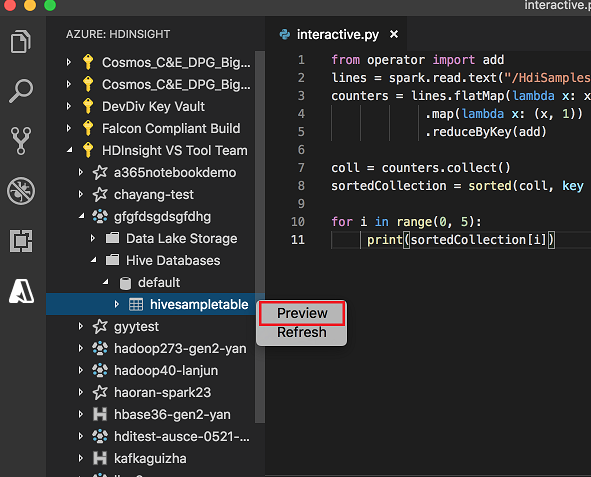
Jendela Hasil Pratinjau terbuka:
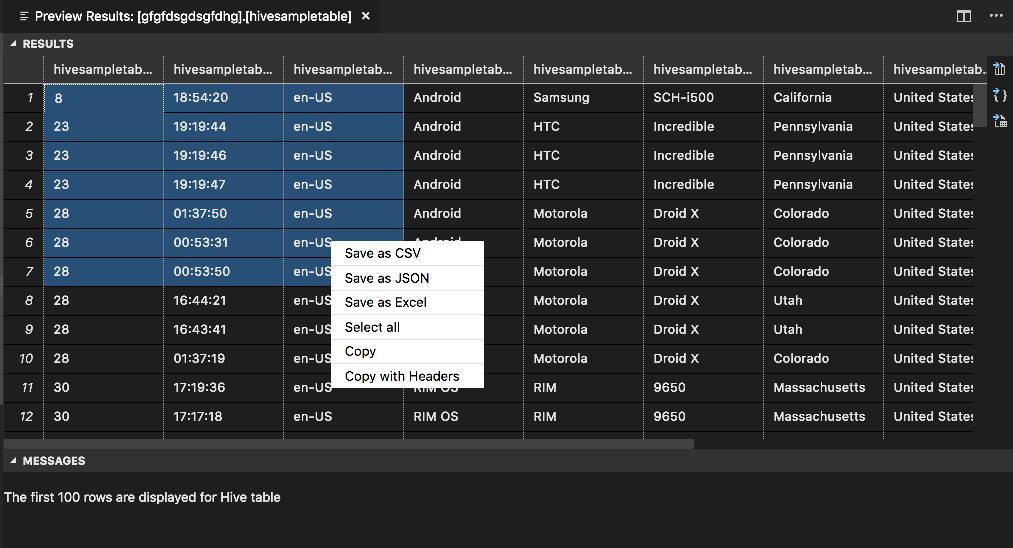
Panel HASIL
Anda dapat menyimpan seluruh hasil sebagai file CSV, JSON, atau Excel ke jalur lokal atau hanya memilih beberapa baris.
Panel PESAN
Saat jumlah baris dalam tabel lebih besar dari 100, Anda akan melihat pesan berikut: "100 baris pertama ditampilkan untuk tabel Apache Hive."
Saat jumlah baris dalam tabel lebih besar dari 100, Anda akan melihat pesan berikut: "60 baris pertama ditampilkan untuk tabel Apache Hive."
Saat tidak ada konten dalam tabel, Anda akan melihat pesan berikut:
0 rows are displayed for Hive table."Catatan
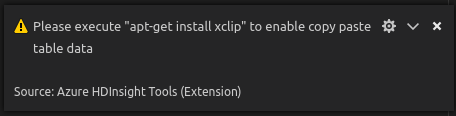
Di Linux, instal xclip untuk mengaktifkan data salin-table.
Fitur tambahan
Spark & Apache Hive untuk Visual Studio Code juga mendukung fitur berikut:
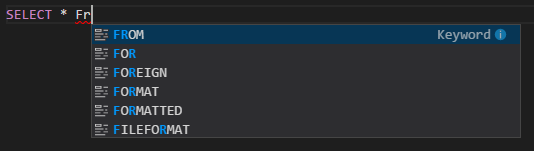
IntelliSense lengkapi otomatis. Saran muncul untuk kata kunci, metode, variabel, dan elemen pemrograman lainnya. Ikon yang berbeda mewakili berbagai jenis objek:
Penanda kesalahan IntelliSense. Layanan bahasa menggarisbawahi kesalahan pengeditan dalam skrip Apache Hive.
Sorotan sintaks. Layanan bahasa menggunakan warna yang berbeda untuk membedakan variabel, kata kunci, jenis data, fungsi, dan elemen pemrograman lainnya:
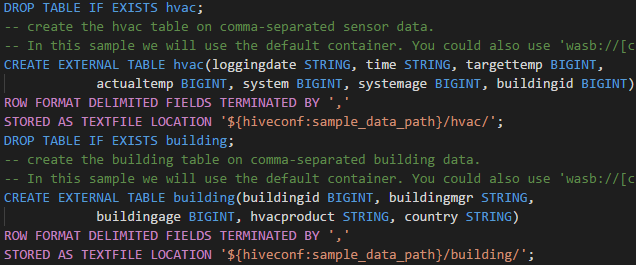
Peran khusus pembaca
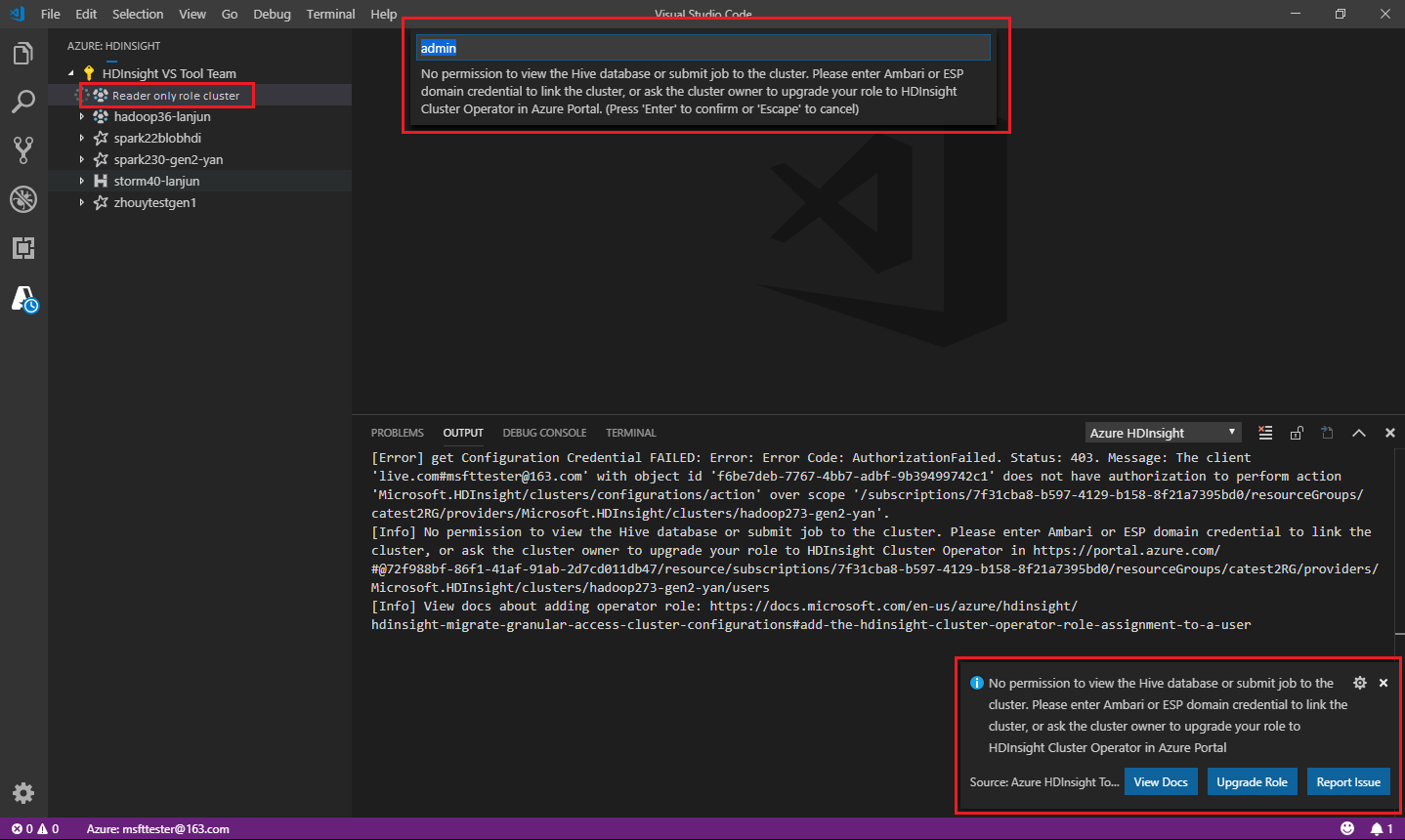
Pengguna yang diberi peran khusus pembaca untuk kluster tidak dapat mengirimkan pekerjaan ke kluster Microsoft Azure HDInsight, atau melihat database Apache Hive. Hubungi administrator kluster untuk memutakhirkan peran Anda ke Operator Kluster Microsoft Azure HDInsight di portal Microsoft Azure. Jika Anda memiliki info masuk Ambari yang valid, Anda dapat menautkan kluster secara manual dengan menggunakan panduan berikut.
Telusur Microsoft Azure HDInsight
Saat Anda memilih penjelajah Azure HDInsight untuk memperluas kluster Microsoft Azure HDInsight, Anda akan diminta untuk menautkan kluster jika Anda memiliki peran khusus pembaca untuk kluster tersebut. Gunakan metode berikut untuk menautkan ke kluster dengan menggunakan info masuk Ambari Anda.
Kirim pekerjaan ke kluster Microsoft Azure HDInsight
Saat mengirimkan tugas ke kluster Microsoft Azure HDInsight, Anda diminta untuk menautkan kluster jika Anda berada dalam peran pembaca saja untuk kluster. Gunakan metode berikut untuk menautkan ke kluster dengan menggunakan info masuk Ambari Anda.
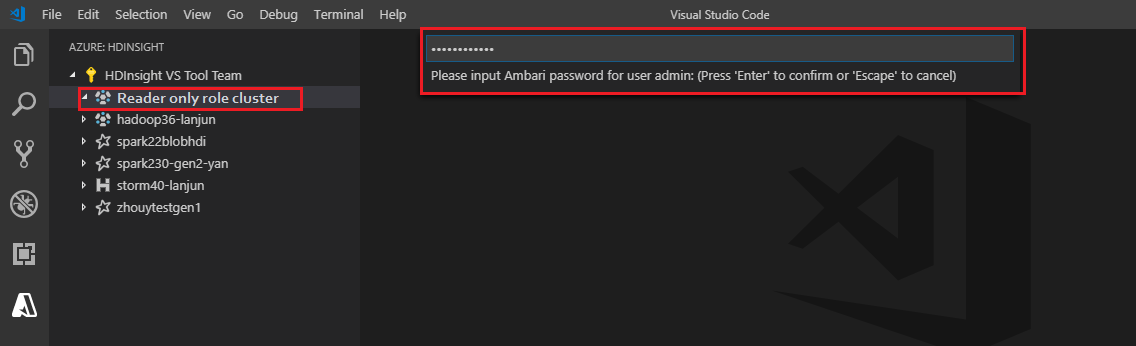
Tautkan ke kluster
Masukkan nama pengguna Ambari yang valid.
Masukkan kata Sandi yang valid.
Catatan
Anda dapat menggunakan untuk
Spark / Hive: List Clustermemeriksa kluster tertaut:
Azure Data Lake Storage Gen2
Telusur Akun Azure Data Lake Storage Gen2
Pilih penjelajah Microsoft Azure HDInsight untuk memperluas akun Data Lake Storage Gen2. Anda diminta untuk memasukkan kunci akses penyimpanan jika akun Azure Anda tidak memiliki akses ke penyimpanan Gen2. Setelah kunci akses divalidasi, akun Data Lake Storage Gen2 diperluas secara otomatis.
Kirim pekerjaan ke kluster Microsoft Azure HDInsight dengan Data Lake Storage Gen2
Kirim pekerjaan ke kluster Microsoft Azure HDInsight menggunakan Data Lake Storage Gen2. Anda diminta untuk memasukkan kunci akses penyimpanan jika akun Azure Anda tidak memiliki akses ke penyimpanan Gen2. Setelah kunci akses divalidasi, pekerjaan akan berhasil dikirimkan.

Catatan
Anda bisa mendapatkan kunci akses untuk akun penyimpanan dari portal Microsoft Azure. Untuk informasi selengkapnya, lihat Mengelola kunci akses akun penyimpanan.
Batalkan tautan kluster
Dari bilah menu, arahkan ke Lihat>Palet Perintah , dan masukkan Spark / Apache Hive: Tautkan Kluster.
Pilih kluster untuk membatalkan tautan.
Lihat tampilan OUTPUT untuk verifikasi.
Keluar
Dari bilah menu, buka Lihat>Palet Perintah, lalu masukkan Azure: Keluar.
Masalah Umum
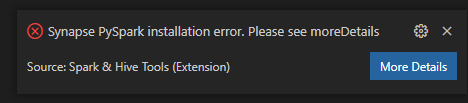
Kesalahan instalasi Synapse PySpark.
Untuk kesalahan penginstalan Synapse PySpark, karena dependensinya tidak akan dipertahankan lagi oleh tim lain, Synapse PySpark tidak akan dipertahankan lagi. Jika Anda mencoba menggunakan interaktif Synapse Pyspark, harap gunakan Azure Synapse Analytics sebagai gantinya. Dan perubahan ini bersifat jangka panjang.
Langkah berikutnya
Untuk video yang menunjukkan penggunaan Spark & Hive untuk Visual Studio Code, lihat Spark & Hive untuk Visual Studio Code.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk