Memperbaiki kesalahan kehabisan memori pada Apache Hive di Microsoft Azure HDInsight
Pelajari cara memperbaiki kesalahan kehabisan memori (OOM) pada Apache Hive saat memproses tabel besar dengan mengonfigurasikan pengaturan memori di Apache Hive.
Menjalankan kueri Apache Hive terhadap tabel besar
Konsumen menjalankan kueri Apache Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Beberapa nuansa kueri ini:
- T1 adalah alias untuk tabel besar, TABLE1, yang memiliki banyak jenis kolom STRING.
- Tabel lain tidak sebesar itu tetapi memiliki banyak kolom.
- Semua tabel saling bergabung satu sama lain, dalam beberapa kasus dengan beberapa kolom di TABLE1 dan lainnya.
Kueri Apache Hive membutuhkan waktu 26 menit untuk menyelesaikan 24 simpul A3 HDInsight kluster. Konsumen melihat pesan peringatan berikut:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Dengan menggunakan mesin eksekusi Apache Tez. Kueri yang sama berjalan selama 15 menit, lalu melemparkan kesalahan berikut:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Kesalahan akan tetap ada saat menggunakan komputer virtual yang lebih besar (misalnya, D12).
Men-debug kesalahan kehabisan memori
Tim dukungan dan teknik kami bersama-sama menemukan salah satu masalah yang menyebabkan kesalahan kehabisan memori adalah masalah umum yang dijelaskan dalam Apache JIRA:
"Ketika Apache Hive.auto.convert.join.noconditionaltask = true kita memeriksa noconditionaltask.size dan jika jumlah ukuran tabel dalam gabungan peta kurang dari noconditionaltask.size paket maka akan menghasilkan gabungan Peta, masalahnya adalah perhitungan yang tidak menilai overhead yang diperkenalkan oleh implementasi HashTable lain sebagai hasil jika jumlah ukuran input lebih kecil dari ukuran noconditionaltask dengan kueri margin kecil yang akan mengenai OOM."
Apache Hive.auto.convert.join.noconditionaltask dalam file Apache Hive-site.xml diatur ke true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Kelihatannya gabungan peta adalah penyebab Java Heap Space mendapatkan kesalahan kehabisan memori. Seperti yang dijelaskan dalam posting blog Pengaturan memori Hadoop Yarn di HDInsight, saat mesin eksekusi Tez digunakan, penggunaan ruang yang bertumpuk sebenarnya menjadi milik kontainer Tez. Lihat gambar berikut yang menjelaskan memori kontainer Tez.
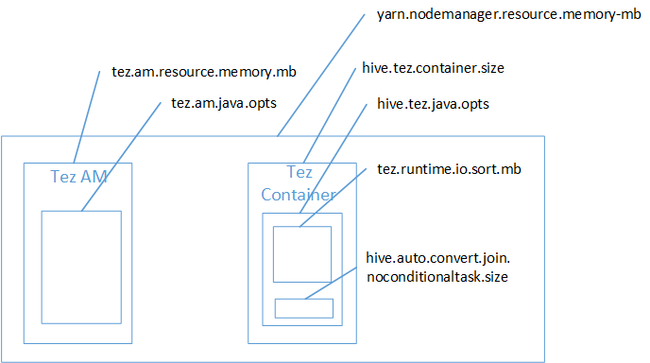
Seperti yang disarankan oleh posting blog, dua pengaturan memori berikut menentukan memori kontainer untuk tumpukan: Apache Hive.tez.container.size dan Apache Hive.tez.java.opts. Dari pengalaman kami, pengecualian kehabisan memori bukan berarti ukuran kontainer terlalu kecil. Artinya ukuran dari tumpukan Java (Apache Hive.tez.java.opts) terlalu kecil. Jadi, setiap kali Anda melihat kehabisan memori, Anda dapat mencoba untuk meningkatkan Apache Hive.tez.java.opts. Jika diperlukan, Anda mungkin harus meningkatkan Apache Hive.tez.container.size. Pengaturan java.opts harus sekitar 80% dari container.size.
Catatan
Pengaturan Apache Hive.tez.java.opts harus selalu lebih kecil dari Apache Hive.tez.container.size.
Karena mesin D12 memiliki memori 28 GB, kami memutuskan untuk menggunakan ukuran kontainer 10 GB (10240 MB) dan menetapkan 80% ke java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Dengan pengaturan baru ini, kueri berhasil berjalan dalam waktu kurang dari 10 menit.
Langkah berikutnya
Mendapatkan kesalahan OOM bukan berarti ukuran kontainer terlalu kecil. Sebagai gantinya, Anda harus mengonfigurasi pengaturan memori sehingga ukuran tumpukan ditingkatkan dan setidaknya mencapai 80% dari ukuran memori kontainer. Untuk mengoptimalkan kueri Apache Hive, lihat Mengoptimalkan kueri Apache Hive untuk Apache Hadoop di HDInsight.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk