Layanan ketersediaan tinggi yang didukung oleh Azure HDInsight
Dalam rangka memberi Anda tingkat ketersediaan yang optimal untuk komponen analitik Anda, HDInsight dikembangkan dengan arsitektur unik untuk memastikan ketersediaan tinggi (HA) layanan penting. Microsoft mengembangkan beberapa komponen arsitektur ini untuk menyediakan failover otomatis. Komponen lain merupakan komponen Apache standar yang digunakan untuk mendukung layanan tertentu. Artikel ini menjelaskan arsitektur model layanan HA di HDInsight, cara HDInsight mendukung kegagalan untuk layanan HA, dan praktik terbaik untuk pulih dari interupsi layanan lainnya.
Catatan
Artikel ini berisi referensi ke istilah slave, istilah yang tidak lagi digunakan Microsoft. Saat istilah dihapus dari perangkat lunak, kami akan menghapusnya dari artikel ini.
Infrastruktur ketersediaan tinggi
HDInsight menyediakan infrastruktur khusus untuk memastikan bahwa empat layanan utama memiliki ketersediaan tinggi dengan kemampuan failover otomatis:
- Server Apache Ambari
- Application Timeline Server untuk Apache YARN
- Server Riwayat Pekerjaan untuk Pengurangan Peta Hadoop
- Apache Livy
Infrastruktur ini terdiri dari banyak komponen layanan dan perangkat lunak, beberapa di antaranya dirancang oleh Microsoft. Komponen berikut ini bersifat unik untuk platform HDInsight:
- Pengontrol kegagalan slave
- Pengontrol kegagalan master
- Layanan ketersediaan tinggi slave
- Layanan ketersediaan tinggi master
Ada juga layanan ketersediaan tinggi lainnya, yang didukung oleh komponen keandalan Apache sumber terbuka. Komponen-komponen ini juga ada pada klaster HDInsight:
- Namenode Sistem File Hadoop (HDFS)
- YARN ResourceManager
- Master HBase
Bagian berikut ini memberikan detail selengkapnya tentang cara layanan ini bekerja sama.
Layanan ketersediaan tinggi HDInsight
Microsoft menyediakan dukungan untuk empat layanan Apache dalam tabel berikut di klaster HDInsight. Untuk membedakannya dari layanan ketersediaan tinggi yang didukung oleh komponen dari Apache, layanan ini disebut Layanan HDInsight HA.
| Layanan | Simpul kluster | Jenis kluster | Tujuan |
|---|---|---|---|
| Server Apache Ambari | Headnode aktif | Semua | Memantau dan mengelola klaster. |
| Application Timeline Server untuk Apache YARN | Headnode aktif | Semua kecuali Kafka | Mempertahankan informasi penelusuran kesalahan tentang pekerjaan YARN yang berjalan pada klaster. |
| Server Riwayat Pekerjaan untuk Pengurangan Peta Hadoop | Headnode aktif | Semua kecuali Kafka | Mempertahankan data penelusuran kesalahan untuk pekerjaan MapReduce. |
| Apache Livy | Headnode aktif | Spark | Memungkinkan interaksi mudah dengan klaster Spark melalui antarmuka REST |
Catatan
Klaster Paket Keamanan Perusahaan (ESP) HDInsight saat ini hanya menyediakan ketersediaan tinggi server Ambari. Application Timeline Server, Job History Server, dan Livy semua berjalan hanya pada headnode0 dan tidak melakukan kegagalan untuk headnode1 ketika Ambari mengalami kegagalan. Database linimasa aplikasi juga ada pada headnode0 dan bukan pada server Ambari SQL.
Sistem
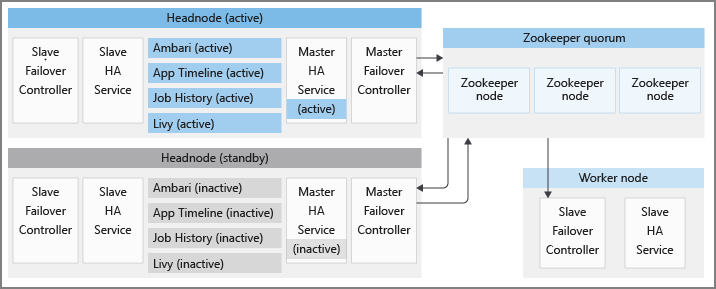
Setiap klaster HDInsight masing-masing memiliki dua headnode dalam mode aktif dan siaga. Layanan HDInsight HA hanya berjalan di headnode. Layanan-layanan ini harus selalu berjalan pada headnode aktif, dan berhenti serta dimasukkan ke dalam mode pemeliharaan pada headnode siaga.
Untuk mempertahankan status layanan HA yang benar dan memberikan kegagalan yang cepat, HDInsight menggunakan Apache ZooKeeper, yang merupakan layanan koordinasi untuk aplikasi terdistribusi, untuk melakukan pemilihan headnode aktif. HDInsight juga menyediakan beberapa proses Java latar belakang, yang mengoordinasikan prosedur kegagalan untuk layanan HDInsight HA. Layanan ini adalah: pengontrol failover master, pengontrol failover budak, master-ha-service, dan slave-ha-service.
Apache Zookeeper
Apache ZooKeeper adalah layanan koordinasi berkinerja tinggi untuk aplikasi terdistribusi. Dalam produksi, ZooKeeper biasanya berjalan dalam mode yang direplikasi di mana grup server ZooKeeper yang direplikasi membentuk kuorum. Setiap klaster HDInsight memiliki tiga node ZooKeeper yang memungkinkan tiga server ZooKeeper membentuk kuorum. HDInsight memiliki dua kuorum ZooKeeper yang berjalan secara paralel satu sama lain. Satu kuorum untuk memutuskan headnode aktif dalam klaster tempat layanan HDInsight HA harus berjalan. Kuorum lain digunakan untuk mengkoordinasikan layanan HA yang disediakan oleh Apache, sebagaimana diperinci di bagian selanjutnya.
Pengontrol kegagalan slave
Pengontrol kegagalan slave berjalan pada setiap node dalam klaster HDInsight. Pengontrol ini bertanggung jawab untuk memulai agen Ambari dan slave-ha-service pada setiap node. Ia secara berkala mengkueri kuorum ZooKeeper pertama tentang headnode aktif. Saat headnode aktif dan siaga berubah, pengontrol failover budak melakukan langkah-langkah berikut:
- Memperbarui file konfigurasi hos.
- Memulai ulang agen Ambari.
slave-ha-service bertanggung jawab untuk menghentikan layanan HDInsight HA (kecuali server Ambari) pada headnode siaga.
Pengontrol kegagalan master
Pengontrol kegagalan master berjalan pada semua headnode. Semua pengontrol kegagalan master berkomunikasi dengan kuorum ZooKeeper pertama untuk mencalonkan headnode yang dijalankan sebagai headnode aktif.
Misalnya, jika pengontrol kegagalan master pada headnode 0 memenangkan pemilihan, perubahan berikut terjadi:
- Headnode 0 menjadi aktif.
- Pengontrol kegagalan master memulai server Ambari dan master-ha-service pada headnode 0.
- Pengontrol kegagalan master lainnya menghentikan server Ambari dan master-ha-service pada headnode 1.
master-ha-service hanya berjalan pada headnode aktif, ia menghentikan layanan HDInsight HA (kecuali server Ambari) pada headnode siaga dan memulainya pada headnode aktif.
Proses kegagalan
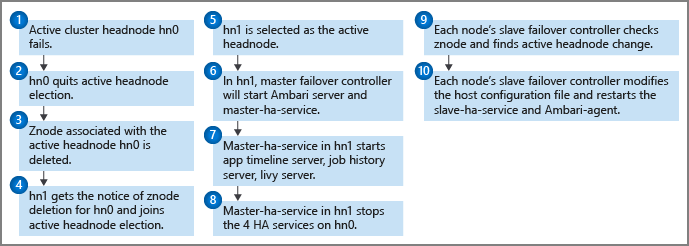
Pemantau kesehatan berjalan pada setiap headnode bersama dengan pengontrol master failover untuk mengirim pemberitahuan detak jantung ke kuorum Zookeeper. Headnode dianggap sebagai layanan HA dalam skenario ini. Pemantau kesehatan memeriksa apakah setiap layanan ketersediaan tinggi sehat dan apakah siap untuk bergabung dalam pemilihan kepemimpinan. Jika ya, headnode ini bersaing dalam pemilihan. Jika tidak, itu berhenti dari pemilu sampai menjadi siap lagi.
Jika headnode siaga pernah mencapai kepemimpinan dan menjadi aktif (seperti dalam kasus kegagalan dengan node aktif sebelumnya), pengontrol failover master-nya memulai semua layanan HDInsight HA di atasnya. Pengontrol failover master menghentikan layanan ini pada headnode lainnya.
Untuk kegagalan layanan HDInsight HA, seperti layanan yang sedang tidak berfungsi atau tidak sehat, pengontrol kegagalan master harus secara otomatis memulai ulang atau menghentikan layanan sesuai dengan status headnode. Pengguna tidak boleh secara manual memulai layanan HDInsight HA pada semua headnode. Sebaliknya, perbolehkan failover otomatis atau manual untuk membantu pemulihan layanan.
Intervensi manual yang tidak disengaja
Layanan HDInsight HA hanya boleh berjalan pada headnode aktif, dan secara otomatis dimulai ulang jika perlu. Karena layanan HA individu tidak memiliki pemantau kesehatan sendiri, kegagalan tidak dapat dipicu pada tingkat layanan individu. Kegagalan dipastikan pada tingkat node dan bukan pada tingkat layanan.
Beberapa masalah umum
Ketika secara manual memulai layanan HA pada headnode siaga, ia tidak akan berhenti sampai kegagalan berikutnya terjadi. Ketika layanan HA \ berjalan pada semua headnode, beberapa masalah potensial termasuk: Ambari UI tidak dapat diakses, Ambari melemparkan eror, serta pekerjaan YARN, Spark, dan Oozie mungkin macet.
Ketika layanan HA pada headnode aktif berhenti, ia tidak akan dimulai ulang sampai kegagalan berikutnya terjadi atau pengontrol kegagalan master/master-ha-service memulai ulang. Ketika satu atau lebih layanan HA berhenti di headnode aktif, terutama ketika server Ambari berhenti, Ambari UI tidak dapat diakses, masalah potensial lainnya mencakup kegagalan pekerjaan YARN, Spark, dan Oozie.
Layanan ketersediaan tinggi Apache
Apache menyediakan ketersediaan tinggi untuk HDFS NameNode, YARN ResourceManager, dan HBase Master, yang juga tersedia dalam klaster HDInsight. Tidak seperti layanan HDInsight HA, mereka didukung dalam klaster ESP. Layanan Apache HA berkomunikasi dengan kuorum ZooKeeper kedua (dijelaskan di bagian di atas) untuk memilih status aktif/siaga dan melakukan failover otomatis. Bagian berikut ini memerinci cara kerja layanan ini.
Sistem File Terdistribusi Hadoop (HDFS) NameNode
Klaster HDInsight berdasarkan Apache Hadoop 2.0 atau yang lebih tinggi menyediakan NameNode ketersediaan tinggi. Ada dua NameNode yang berjalan di headnode, yang dikonfigurasi untuk failover otomatis. NameNode menggunakan ZKFailoverController untuk berkomunikasi dengan Zookeeper untuk memilih status aktif/siaga. ZKFailoverController berjalan pada kedua headnode, dan bekerja dengan cara yang sama seperti pengontrol failover master.
Kuorum Zookeeper kedua bersifat independen dari kuorum pertama, sehingga NameNode aktif mungkin tidak berjalan pada headnode aktif. Ketika NameNode aktif mati atau tidak sehat, NameNode yang siaga memenangkan pemilihan dan menjadi aktif.
YARN ResourceManager
Klaster HDInsight berdasarkan Apache Hadoop 2.4 atau yang lebih tinggi, mendukung ketersediaan tinggi YARN ResourceManager. Ada dua ResourceManagers, rm1 dan rm2, masing-masing berjalan di headnode 0 dan headnode 1. Seperti NameNode, YARN ResourceManager juga dikonfigurasi untuk failover otomatis. ResourceManager lain secara otomatis dipilih untuk aktif ketika ResourceManager aktif saat ini tidak berfungsi atau tidak responsif.
YARN ResourceManager menggunakan ActiveStandbyElector yang tertanam sebagai detektor kegagalan dan pemilih pemimpin. Tidak seperti HDFS NameNode, YARN ResourceManager tidak memerlukan daemon ZKFC terpisah. ResourceManager aktif menulis statusnya ke dalam Apache Zookeeper.
Ketersediaan YARN ResourceManager yang tinggi bersifat independen dari NameNode dan layanan HDInsight HA lainnya. ResourceManager aktif mungkin tidak berjalan pada headnode aktif atau headnode tempat NameNode aktif dijalankan. Untuk informasi selengkapnya tentang ketersediaan tinggi YARN ResourceManager, lihat Ketersediaan Tinggi ResourceManager.
Master HBase
klaster HDInsight HBase mendukung ketersediaan tinggi HBase Master. Tidak seperti layanan HA lainnya, yang berjalan di headnodes, HBase Masters berjalan pada tiga node Zookeeper, di mana salah satunya adalah master aktif dan dua lainnya siaga. Seperti NameNode, HBase Master berkoordinasi dengan Apache Zookeeper untuk pemilihan pemimpin dan melakukan failover otomatis ketika master aktif saat ini memiliki masalah. Hanya ada satu HBase Master yang aktif kapan saja.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk